(考研)数据结构中的重难点算法
转载自原文博客,感谢原博主~ https://blog.csdn.net/sinat_33871437/article/details/51425241
本文会把复习中所遇到的所有算法记录并分析,以供以后查阅,【并在原博主基础上进行了修正和补充】
KMP
KMP算法在考研中主要考察Next NextVal数组
KMP算法的名字是三个发明者名字所命名的,没有别的特殊含义
KMP类似动态规划思想,利用已知信息,让已经计算过的值或者无意义的值不再计算
KMP的思路是,创建一个字典保存模板串中共有元素长度
如A B C D A B D中,只有倒数第三个值开始,A B与开头匹配
则保存字典值为0 0 0 0 1 2 0
最终的计算方法为:移动位数 = 已匹配的字符数 - 对应的部分匹配值
void makeNext(const char P[],int next[])
{
int q,k;//q:模版字符串下标;k:最大前后缀长度
int m = strlen(P);//模版字符串长度
next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
///for循环,从第二个字符开始,依次计算每一个字符对应的next值
for (q = 1,k = 0; q < ml; ++q){
while(k > 0 && P[q] != P[k])
k = next[k-1];
if (P[q] == P[k]){
k++;
}
next[q] = k;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面为代码,较难理解部分为while部分,实际上,当匹配共有元素时,假如我们匹配到A B C D A B C D时,最后一个D的值不匹配(P[q] != P[k]),则查找之前匹配值是否包含此,如模板开头为A B C D A B C E,当匹配到E时候与D不匹配,则返回查找之前是否有存在其它局部匹配,如模板开头的ABCD,可能会不理解为什么是k=next(k-1),next保存的是匹配长度,则查找E上个字符C的匹配长度,也就是C的next的值代表开头从0至此值长度的字符串是匹配的,则就跳到此值长度字符串的下一个字符进行匹配,因为我们是从0开始下标,所以不用加1
A B C D A B C D
A B C D A B C E
A B C D A B C E
二叉树
二叉树的性质
1、在二叉树的第 i 层上至多有 2i+1(i≥1)2i+1(i≥1) 有
1.如果 i=1i=1
代码实现
c版本
//二叉树结点
typedef struct BiTNode{
//数据
char data;
//左右孩子指针
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
c# 版本(面向对象)
public class BinNode
{
public int Element;
public BinNode Left;
public BinNode Right;
public BinNode(int element, BinNode left, BinNode right)
{
this.Element = element;
this.Left = left;
this.Right = right;
}
public bool IsLeaf()
{
return this.Left == null && this.Right == null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
遍历方法
遍历递归版本
//先序遍历
void PreOrder(BiTree T){
if(T != NULL){
//访问根节点 即是访问T本身
Visit(T);
//访问左子结点
PreOrder(T->lchild);
//访问右子结点
PreOrder(T->rchild);
}
}
//中序遍历
void InOrder(BiTree T){
if(T != NULL){
//访问左子结点
InOrder(T->lchild);
//访问根节点
Visit(T);
//访问右子结点
InOrder(T->rchild);
}
}
//后序遍历
void PostOrder(BiTree T){
if(T != NULL){
//访问左子结点
PostOrder(T->lchild);
//访问右子结点
PostOrder(T->rchild);
//访问根节点
Visit(T);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
遍历非递归版本
/* 先序遍历(非递归)
思路:访问T->data后,将T入栈,遍历左子树;遍历完左子树返回时,栈顶元素应为T,出栈,再先序遍历T的右子树。
*/
void PreOrder2(BiTree T){
stack
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
前序遍历是深度优先遍历的一种
但二叉树深度优先遍历还包括中序遍历、后续遍历
两者并不是一个概念
哈夫曼树
路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径
路径长度:路径上的分枝数目称作路径长度。
树的路径长度:从树根到每一个结点的路径长度之和
结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值之积称为该结点的带权路径长度(weighted path length)
树的带权路径长度:如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带权路径长度
带权路径长度最小的二叉树就称为哈夫曼树或最优二叉树
步骤
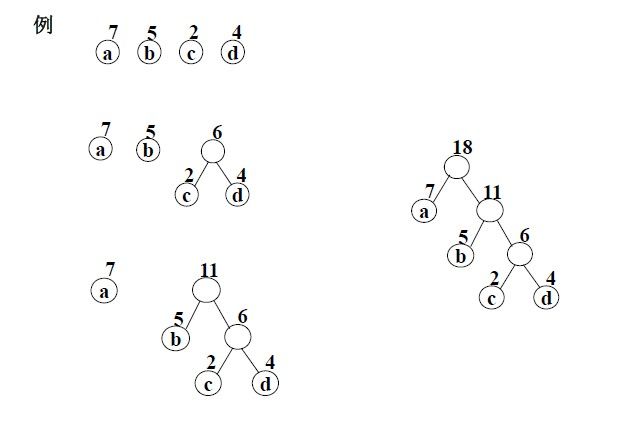
应用
在电文传输中,需要将电文中出现的每个字符进行二进制编码。在设计编码时需要遵守两个原则:
(1)发送方传输的二进制编码,到接收方解码后必须具有唯一性,即解码结果与发送方发送的电文完全一样;
(2)发送的二进制编码尽可能地短。下面我们介绍两种编码的方式。
等长编码
这种编码方式的特点是每个字符的编码长度相同(编码长度就是每个编码所含的二进制位数)。假设字符集只含有4个字符A,B,C,D,用二进制两位表示的编码分别为00,01,10,11。若现在有一段电文为:ABACCDA,则应发送二进制序列:00010010101100,总长度为14位。当接收方接收到这段电文后,将按两位一段进行译码。这种编码的特点是译码简单且具有唯一性,但编码长度并不是最短的。不等长编码
在传送电文时,为了使其二进制位数尽可能地少,可以将每个字符的编码设计为不等长的,使用频度较高的字符分配一个相对比较短的编码,使用频度较低的字符分配一个比较长的编码。例如,可以为A,B,C,D四个字符分别分配0,00,1,01,并可将上述电文用二进制序列:000011010发送,其长度只有9个二进制位,但随之带来了一个问题,接收方接到这段电文后无法进行译码,因为无法断定前面4个0是4个A,1个B、2个A,还是2个B,即译码不唯一,因此这种编码方法不可使用。
因此,为了设计长短不等的编码,以便减少电文的总长,还必须考虑编码的唯一性,即在建立不等长编码时必须使任何一个字符的编码都不是另一个字符的前缀,这宗编码称为前缀编码(prefix code)
(1)利用字符集中每个字符的使用频率作为权值构造一个哈夫曼树;
(2)从根结点开始,为到每个叶子结点路径上的左分支赋予0,右分支赋予1,并从根到叶子方向形成该叶子结点的编码
AVL&RB Tree
AVL树又称高度平衡的二叉搜索树
红黑树是一种很有意思的平衡检索树,它的统计性能要好于平衡二叉树
红黑树和AVL树的区别在于它使用颜色来标识结点的高度,它所追求的是局部平衡而不是AVL树中的非常严格的平衡
C++ STL中,很多部分(目前包括 set, multiset, map, multimap)应用了红黑树的变体(SGI STL中的红黑树有一些变化,这些修改提供了更好的性能,以及对set操作的支持)
红黑树是真正的变态级数据结构
// TODO
二叉搜索树
二叉排序树(Binary Sort Tree)又称二叉查找树(Binary Search Tree),亦称二叉搜索树
图
有 12n(n−1)12n(n−1) 条弧的有向图成为有向完全图
Prim算法
1、输入:一个加权连通图,其中顶点集合为V,边集合为E;
2、初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3、重复下列操作,直到Vnew = V:
(1). 在集合E中选取权值最小的边 < u, v >,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
(2). 将v加入集合Vnew中,将< u, v >边加入集合Enew中;
4、 输出:使用集合Vnew和Enew来描述所得到的最小生成树。
复杂度:邻接矩阵:O(v2) 邻接表:O(elog2v)
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Kruskal算法
1、记Graph中有v个顶点,e个边
2、新建图Graphnew,Graphnew中拥有原图中相同的e个顶点,但没有边
3、将原图Graph中所有e个边按权值从小到大排序
4、循环:从权值最小的边开始遍历每条边 直至图Graph中所有的节点都在同一个连通分量中
如果 这条边连接的两个节点于图Graphnew中不在同一个连通分量中
则 添加这条边到图Graphnew中
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48