基于随机梯度下降的SVD原理分享及Python代码实现
传统的SVD方法需要将rating分解成用户向量p和物品向量q,通常大型系统中p和q的维数都比较高,例如电商系统中,用户的维数甚至达到上亿维,进行这样的大矩阵分解还是比较困难的。另外,通常rating中包含大量的缺失值,一般采用平均值等方法来填充,但是这些填充值本身就不一定准确,因此会一定程度上影响后续的矩阵分解结果的准确性。所以一般采用近似的方法来构造用户向量p和物品向量q,常用的方法包括随机梯度下降sgd、交叉最小二乘ALS等,本文主要介绍随机梯度下降法。
随机梯度下降法,首先需要构造损失函数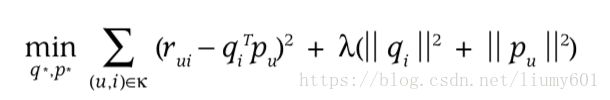 ,其中rui表示实际的rating,qTp表示预测值,损失函数前半部分表示rating的平方损失,后半部分为p、q向量的惩罚项,加上这部分是为了防止过拟合。接着需要求出p和q的导数,用于梯度下降。
,其中rui表示实际的rating,qTp表示预测值,损失函数前半部分表示rating的平方损失,后半部分为p、q向量的惩罚项,加上这部分是为了防止过拟合。接着需要求出p和q的导数,用于梯度下降。
 (1)
(1)
 (2)
(2)
上面公式(1)表示rating的预测误差,公式(2)表示q和p梯度下降后的值,只需要对存在的rating项进行逐个迭代,不需要填充缺失值。另外可以通过多轮迭代至误差收敛为止,这样可以找到合适的p和q。
import numpy as np
import pandas as pd
class SVD:
"""
ratings: 训练数据, n*3维数组 (user, item, rating)
K: 隐向量维数
Lambda: 惩罚系数
gamma: 学习率
steps: 迭代次数
"""
def __init__(self, ratings, logger=None, normalize=False, K=40, Lambda=0.005, gamma=0.02, steps=40):
# 字符串数组转换成数字数组
# user, item字符串映射为数字
self.ratings = []
self.user2id = {}
self.item2id = {}
# user已推荐过的items
self.userRecItems = {}
user_id = 0
item_id = 0
if normalize:
ratings[:,2] = self.minMaxScaler(ratings[:,2])
for user, item, r in ratings:
if user not in self.userRecItems:
self.userRecItems[user] = set()
new_tup = []
if user not in self.user2id:
self.user2id[user] = user_id
new_tup.append(user_id)
user_id += 1
else:
new_tup.append(self.user2id[user])
if item not in self.item2id:
self.item2id[item] = item_id
self.userRecItems[user].add(item_id)
new_tup.append(item_id)
item_id += 1
else:
self.userRecItems[user].add(self.item2id[item])
new_tup.append(self.item2id[item])
new_tup.append(r)
self.ratings.append(new_tup)
self.ratings = np.array(self.ratings)
user_num = len(self.user2id.keys())
item_num = len(self.item2id.keys())
self.user_mat = 0.1 * np.random.randn(user_num, K) / np.sqrt(K)
self.item_mat = 0.1 * np.random.randn(K, item_num) / np.sqrt(K)
self.bias_user = np.array([0.0] * user_num)
self.bias_item = np.array([0.0] * item_num)
self.global_mean = np.mean(ratings[:, 2])
self.Lambda = Lambda
self.gamma = gamma
self.steps = steps
self.logger = logger
def train(self):
losses = []
for step in range(self.steps):
loss = 0
np.random.shuffle(self.ratings)
for i, j, r in self.ratings:
i = int(i)
j = int(j)
Err = r - (np.dot(self.user_mat[i, :], self.item_mat[:, j]) + self.global_mean + self.bias_user[i] + self.bias_item[j])
loss += Err**2
self.user_mat[i, :] += self.gamma * (Err * self.item_mat[:, j] - self.Lambda * self.user_mat[i, :])
self.item_mat[:, j] += self.gamma * (Err * self.user_mat[i, :] - self.Lambda * self.item_mat[:, j])
self.bias_user[i] += self.gamma * (Err - self.Lambda * self.bias_user[i])
self.bias_item[j] += self.gamma * (Err - self.Lambda * self.bias_item[j])
self.gamma *= 0.9
loss += self.Lambda * ((self.user_mat*self.user_mat).sum() + (self.item_mat*self.item_mat).sum()
+ (self.bias_user*self.bias_user).sum() + (self.bias_item*self.bias_item).sum())
losses.append(loss)
#print('step '+str(step)+' loss '+str(loss))
if self.logger is not None:
self.logger.info('step '+str(step)+' loss: '+str(loss))
if self.isConverged(losses):
break
"""
test_users: 要预测的user列表
topN: 每个user返回的推荐item个数
format: dict或者dataframe, 默认返回dict
coldEmpty: 未知用户是否返回结果 True/False, 默认True
"""
def predict(self, test_users, topN=100, format='dict', coldEmpty=True):
user_ids = []
exist_users = []
non_exist_users = []
for user in test_users:
if user in self.user2id:
user_ids.append(self.user2id[user])
exist_users.append(user)
else:
non_exist_users.append(user)
self.bias_user = self.bias_user.reshape(self.bias_user.shape[0], 1)
batch_size = 20000
if len(user_ids) > batch_size:
user_item_mat = None
batch_num = int(np.ceil(len(user_ids) / batch_size))
for batch in range(batch_num):
batch_user_ids = user_ids[batch*batch_size:(batch+1)*batch_size]
batch_mat = np.dot(self.user_mat[batch_user_ids, :], self.item_mat) + + self.global_mean \
+ self.bias_user[batch_user_ids] + self.bias_item
if user_item_mat is None:
user_item_mat = batch_mat
else:
user_item_mat = np.vstack((user_item_mat, batch_mat))
else:
user_item_mat = np.dot(self.user_mat[user_ids, :], self.item_mat) + + self.global_mean\
+ self.bias_user[user_ids] + self.bias_item
id2item = dict(zip(self.item2id.values(), self.item2id.keys()))
max_exist_rec_num = 0
for user in exist_users:
rec_num = len(self.userRecItems[user])
if rec_num > max_exist_rec_num:
max_exist_rec_num = rec_num
if format == 'dict':
topN_items = {}
for user_index, user in enumerate(exist_users):
# 找到最大的topN个item, 然后排序
max_sort_num = topN + max_exist_rec_num
topN_indexes = np.argpartition(user_item_mat[user_index,:], -max_sort_num)[-max_sort_num:]
top_indexes = list(topN_indexes[np.argsort(-user_item_mat[user_index,:][topN_indexes])])
# 过滤掉已推荐item
rec_item_indexes = self.userRecItems[user]
for rec_index in rec_item_indexes:
if rec_index in top_indexes:
top_indexes.remove(rec_index)
to_rec_item_indexes = top_indexes[:topN]
topN_items[user] = [id2item[index] for index in to_rec_item_indexes]
for user in non_exist_users:
if coldEmpty:
topN_items[user] = []
else:
to_rec_item_indexes = np.random.randint(user_item_mat.shape[1], size=topN)
topN_items[user] = [id2item[index] for index in to_rec_item_indexes]
else :
topN_items = {}
for user_index, user in enumerate(exist_users):
# 找到最大的topN个item, 然后排序
max_sort_num = topN + max_exist_rec_num
topN_indexes = np.argpartition(user_item_mat[user_index, :], -max_sort_num)[-max_sort_num:]
top_indexes = list(topN_indexes[np.argsort(-user_item_mat[user_index, :][topN_indexes])])
# 过滤掉已推荐item
rec_item_indexes = self.userRecItems[user]
for rec_index in rec_item_indexes:
if rec_index in top_indexes:
top_indexes.remove(rec_index)
to_rec_item_indexes = top_indexes[:topN]
for rank, rec_index in enumerate(to_rec_item_indexes):
topN_items[user+'_'+str(rank)] = [user, id2item[rec_index], rank+1]
if not coldEmpty:
for user in non_exist_users:
to_rec_item_indexes = np.random.randint(user_item_mat.shape[1], size=topN)
for rank, rec_index in enumerate(to_rec_item_indexes):
topN_items[user + '_' + str(rank)] = [user, id2item[rec_index], rank+1]
topN_items = pd.DataFrame.from_dict(topN_items, orient='index', columns=['token','b_token','rank'])
return topN_items
def minMaxScaler(self, ratings):
new_ratings = []
min_r = np.min(ratings)
max_r = np.max(ratings)
for r in ratings:
new_ratings.append((r-min_r)/(max_r-min_r))
return np.array(new_ratings)
def normalize(self, ratings):
mean = np.mean(ratings)
std = np.std(ratings)
new_ratings = []
for r in ratings:
new_ratings.append((r-mean)/std)
return np.array(new_ratings)
def isConverged(self, losses, last_n_steps=30):
last_losses = losses[-last_n_steps:]
is_descending = False
if len(last_losses) >= last_n_steps and np.std(last_losses) < 0.001:
is_descending = True
return is_descending
def early_stopping(self, losses):
# use early stopping
early_stopping_rounds = int(self.steps / 10)
is_descending = True
last_losses = losses[-early_stopping_rounds:]
if len(last_losses) >= early_stopping_rounds:
for i in range(len(last_losses)-1):
if losses[i+1] - losses[i] > 0.001:
is_descending = False
break
else:
is_descending = False
return is_descending代码中__init__方法设置了gamma、lambda、K、steps的值,分别表示学习率、惩罚系数、隐藏变量维数、迭代步数,另外输入样本通常为三维数组。train方法为模型训练过程,按照上面介绍的方法进行迭代,user_mat和item_mat分别表示用户向量p和物品向量q,另外多个step中通常将gamma值缩小,以便缩小梯度搜索的范围,尽快找到最优解。predict方法用于对用户的推荐物品预测,topN表示每个用户返回的物品个数,format表示返回的用户物品格式,支持字典和dataframe方式,考虑用户维数很高的时候矩阵会比较大,可能会引起MemoryError,改成了按批预测,每批20000个用户。
这份代码是现在公司系统中正在使用的代码,按照注释里的方法传参应该就能跑,另外代码中对用户物品预测排序topN进行了优化,速度相比常用的大数组排序要快3倍,有错误的地方,欢迎指正。