文件压缩(基于LZ77的压缩)
LZ77压缩原理
初始LZ77
LZ77是基于字节的通用压缩算法,它的原理就是将源文件中的重复字节(即在前文中出现的重复字节)使用(offset,length,nextchar)的三元组进行替换
这里的
长度–offset,距离—length,先行缓冲匹配串的下一个字符
总共三个字节
初始LZ77的缺陷
只是距离按照一个字节的长度,那么只能在先行缓冲区找256个以内的字符,所以压缩率不是很高
改进后的LZ77
<长度,距离>,长度是一个字节,距离占2个字节
两个字节:无符号类型来定义----->范围为65535
但是真正匹配的时候并不用匹配这么远,匹配的长度是一个WSIZE:32K-------32768
为什么太远不匹配
为了提高0.1%的压缩率,程序压缩的性能可能会急剧下降
为什么匹配距离越远性能会下降
因为LZ77是基于重复语句的压缩,如果为了找重复语句,而扩大匹配的范围,比较的次数增多,压缩一个文件的时间变成不划算
LZ77的原理
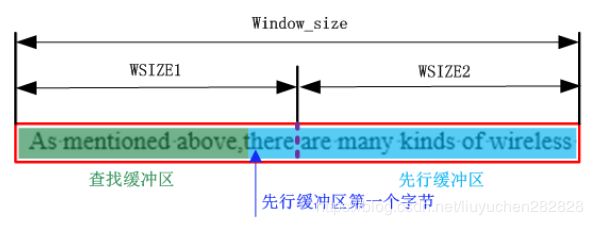
滑动窗口的设计
<长度,距离>对总共占三个字节
-
最小的匹配长度:匹配的字符串最小为多少个字节
MIN_MATCH:- 1个字节肯定不匹配
- 2个字节,<长度,距离>占3个字节,如果进行替换,无疑会使压缩文件变大
- 3个字节及以上开始匹配
-
最大的匹配长度:字符串出现重复最多匹配多大
MAX_MATCH:- <长度,距离>对中的长度只是一个字节,一个字节范围:[0,255]
- 因为字符串小于3个不进行匹配,所以范围为[3,258]
-
window:缓冲区,作用:在压缩时,用来保存从待压缩文件中读取文件信息
-
整个窗口的大小为64K。而整个文件分为一个已压缩过区域,和未压缩区域
WSIZE1 = WSIZE2 = WSIZE = 32K -
已压缩过的区域我们选择刚刚压缩过的一部分数据作为查找缓冲区,未压缩过的称为先行缓冲区,先行缓冲区第一个字节,也就是压缩的起始位置定义为start
//为了书写方便
typedef unsigned char UCH;
typedef unsigned short USH;
typedef unsigned long long ULL; //文件比较大
//最小匹配的字符串长度,从3个字符开始匹配
const USH MIN_MATCH = 3;
//最大的匹配,0代表3个字符匹配,255可以代表258个字符匹配
const USH MAX_MATCH = 258;
const USH WSIZE = 32 * 1024;
滑动窗口的移动
不断压缩的时候,start肯定在往后移动,假设:待压缩文件大小超过64K,不能一次性将源文件中的数据全部读取到窗口中,start如果往后移动到一个位置,什么位置?就是start到窗口末尾中剩余的字符比较少(比如剩余10个字符,还有一部分匹配数据还在源文件中,没读到缓冲区中),本次匹配暂时不进行
先行缓冲区中的待压缩数据剩余到一定数量,则不进行匹配,所以定义一个MIN_LOOKAHEAD来表示最小先行缓冲区MIN_LOOKAHEAD=MAX_NATCH +MIN_MATCH+ 1;即:保证待压缩区域至少有一个字节以及该字节的一个匹配长度。
MIN_LOOKAHEAD:表示先行缓冲区剩余字符最小的个数:
- MAX_MATCH可以保证:本次匹配达到最大,
- MIN_MATCH+1可以保证:还可以进行下一次匹配
移动处理
- 将WSIZE2窗口中的数据导入到WSIZE1窗口中 start-=WSIZE
- 从待压缩文件中再重新读取一个WISIZE的数据到WSIZE2中
- 必须更新哈希表
真正的匹配距离并不是WSIZE,而是:MAX_DIST = WSIZE-LOOKAHEAD
也就是查找缓冲区就是WSIZE减去先行缓冲区剩余字符最小的个数,MAX_DIST = 查找缓冲区
LZ77高效的查找最长匹配串
哈希的设计
哈希桶大小
每次拿三个字节在前文中找匹配三个字节组合的可能性情况:224的可能性,哈希表应该要能容纳224个哈希地址
用三个字节在查找缓冲区中找匹配
- 三个字节在哈希表中直接查询
- 先计算哈希地址
- 哈希表个中将来要存储的是三个字符的下标—哈希表中每个位置给出2个字节,哈希表的空间224*2 = 32M
- 空间太大
- 随着压缩不断进行,哈希表要不断的更新,维护的成本太大了
- LZ77算法在1977年提出,当时的硬件环境可能受限
- 本项目哈希桶的个数设置为215
哈希表结构

如果prev和head中某个位置存储的数据大于WSIZE,就给该位置的数据减去WSIZE
- prev作用
- 用来解决哈希冲突
- head作用
- 保存本次新插入的字符串中首字符在window中的位置

insert(matchHead,ch,pos,hashAddr)
{
//1.计算字符的哈希地址
hashAddr = HashFunc(hashAddr,ch);
//2.保存匹配链的头
matchHead = head[hashAddr];
//3. 链接
prev[pos&HASH_MASK] = matchHead;
head[hashAddr] = pos;
}
可以通过该种链接方式将相同字符的在window中的位置记录下来查找最长匹配时,只需要顺着链的方向依次取出对应字符在window中的位置即可进行匹配
pos有可能大于WSIZE,那么prev插入时会导致越界而引起程序崩溃,解决:pos&MASK:可以保证地址不越界,但有可能导致匹配链成环,解决方式:在找最长匹配时,限定匹配次数即可,限定次数为255.
为什么prev和head一样大
- 和窗口对应起来,方便运算
- 考虑16位系统
&MASK存在的问题
- 可能会将某些链破坏
- 可能会造成链成环
解决方式:设置一个最大的匹配次数255
哈希函数
三个字符的每个比特位都参与运算
A(4,5) + A(6,7,8) ^ B(1,2,3) + B(4,5) + B(6,7,8) ^ C(1,2,3) + C(4,5,6,7,8)
说明:A 指 3 个字节中的第 1 个字节,B 指第 2 个字节,C 指第 3 个字节,
A(4,5) 指第一个字节的第 4,5 位二进制码,“^”是二进制位的异或操作,
“+”是“连接”而不是“加”,“^”优先于“+”)
这样使 3 个字节都尽量“参与”到最后的结果中来,而且每个结果值 h 都等于 ((前1个h << 5) ^ c)取右 15位
// hashAddr: 上一个字符串计算出的哈希地址
// ch:当前字符
// 本次的哈希地址是在前一次哈希地址基础上,再结合当前字符ch计算出来的
// HASH_MASK为WSIZE-1,&上掩码主要是为了防止哈希地址越界
void HashTable::HashFunc(USH& hashAddr, UCH ch)
{
hashAddr = (((hashAddr) << H_SHIFT()) ^ (ch)) & HASH_MASK;
}
USH HashTable::H_SHIFT()
{
return (HASH_BITS + MIN_MATCH - 1) / MIN_MATCH;
}
USH LZHashTable::GetNext(USH& matchHead)
{
return _prev[matchHead&HASH_MASK];
}
void LZHashTable::Update()
{
for (USH i = 0; i < WSIZE; ++i)
{
//先更新head
if (_head[i] >= WSIZE) //右窗
_head[i] -= WSIZE; //下标变到左窗
else //左窗
_head[i] = 0; //清零
//更新prev
if (_prev[i] >= WSIZE)
_prev[i] -= WSIZE;
else
_prev[i] = 0;
}
}
高效的查找匹配串实现
//在找的过程中,需要将每次找到的匹配结果进行比对,保存最长匹配
USH LZ77:: LongetMatch(USH matchHead, USH& MatchDist,USH start)
{
USH curMatchLen = 0; //一次匹配的长度
USH maxMatchLen = 0; //最大的匹配长度
UCH maxMatchCount = 255;//最大的匹配次数,解决环状链
USH curMatchStart = 0; //当前匹配在查找缓冲区的起始位置
//在先行缓冲区中查找匹配时,不能太远即不能超过MAX_DIST
USH limit = start > MAX_DIST ? start - MAX_DIST : 0;
do
{
// 匹配范围
// 先行缓冲区的起始位置
UCH* pstart = _pWin + start;
// 先行缓冲区末尾位置
UCH* pend = pstart + MAX_MATCH;
//查找缓冲区匹配串的起始位置
UCH* pMatchStart = _pWin + matchHead;
//当前匹配长度每回都要重置为0,要不然所有匹配长度都加到一块了
curMatchLen = 0;
//可以进行匹配
//先行缓冲区每到末尾并且字符相等
while (pstart < pend && *pstart == *pMatchStart)
{
curMatchLen++;
pstart++;
pMatchStart++;
}//一次匹配结束
//匹配长度超过最长匹配长度
if (curMatchLen>maxMatchLen)
{
//更新最长匹配长度
maxMatchLen = curMatchLen;
//更新起始位置
curMatchStart = matchHead;
}
} while ((matchHead = _ht.GetNext(matchHead)) > limit && maxMatchCount--); //每设置一次,最大的匹配次数--
//start-当前匹配的起始位置
MatchDist = start - curMatchStart;
return maxMatchLen;
}
LZ77实现
压缩实现
1.打开待压缩文件
//获取文件大小
FILE* fIn = fopen(strFilePath.c_str(), "rb");
if (nullptr == fIn)
{
cout << "打开文件失败" << endl;
return;
}
2. 获取文件大小
1. 用fseek()把文件指针移动到末尾
2. 用ftell()计算文件指针偏移的位置
//获取文件大小
fseek(fIn, 0, SEEK_END);
ULL fileSize = ftell(fIn);
3.源文件大小小于最小的匹配字符串MIN_MATCH,就不进行匹配
//1.如果源文件的大小小于MIN_MATCH一个匹配长度,则不进行处理
if (fileSize <= MIN_MATCH)
{
cout << "文件太小,不压缩" << endl;
return;
}
先把文件指针移动到起始位置,再从压缩文件中读取一个缓冲区的数据到窗口中
fseek(fIn,SEEK_SET)fread(_pWin, 1, 2 * WSIZE, fIn);
//从压缩文件中读取一个缓冲区的数据到窗口中
fseek(fIn, 0, SEEK_SET);
size_t lookAhead = fread(_pWin, 1, 2 * WSIZE, fIn);
USH hashAddr = 0;
5. 设置起始哈希地址
//处理前两个字节...设置hashAddr
for (USH i = 0; i < MIN_MATCH - 1; ++i)
{
_ht.HashFunc(hashAddr, _pWin[i]);
}
6. 压缩
1. 用一个变量lookAhead来表示先行缓冲区剩余的个数
//查找最长匹配相关的变量
USH matchHead = 0;
USH curMatchLength = 0; //当前匹配长度
USH curMatchDist = 0;
//写标记相关的变量
UCH chFlag = 0;
USH bitCount = 0;
bool IsLen = false;
2. 打开压缩文件和写标记的文件,保存压缩数据
//压缩数据的文件
FILE* fOUT = fopen("2.lzp", "wb");
assert(fOUT);
USH start = 0;
//写标记的文件
FILE* fOutF = fopen("3.txt", "wb");
assert(fOutF);
3. 获取匹配头
//1.将当前三个字符(start,start+1,start+2)插入到哈希表中,获取匹配头
_ht.Insert(matchHead, _pWin[start + 2],start,hashAddr);
4.验证再查找缓冲区中是否匹配,如果匹配找最长匹配
- 如果
matchHead != 0代表匹配找到了,顺着链找最长匹配,把<长度,距离>对返回来
if (matchHead)
{
//顺着匹配链找最长匹配,最终带出<长度,距离>对
curMatchLength =LongetMatch(matchHead,curMatchDist,start);
}
5.验证是否找到最长匹配
- 如果没有找到,将start位置的字符写入到压缩文件中,并写对应字符的标记,start往后移动,先行缓冲区个数减1
if (curMatchLength < MIN_MATCH)
{
//在查找缓冲区中未找到重复字符串
// 将start 位置的字符写入到压缩文件中
fputc(_pWin[start], fOUT);
//写当前字符原字符对应的标记
WriteFlage(fOutF,chFlag,bitCount,false );
++start;
lookAhead--;
}
- 如果找到匹配,将<长度,距离>对写入到压缩文件中
- 找到匹配,将匹配字符串插入到哈希表格中
//写长度
UCH chLen = curMatchLength - 3;
fputc(chLen, fOUT);
//写距离
fwrite(&curMatchDist, sizeof(curMatchDist), 1, fOUT);
//写当前对应的标记
WriteFlage(fOutF, chFlag, bitCount, true);
//更新先行缓冲区中剩余的字节数,curMatchLength已经处理过了,就减去
lookAhead -= curMatchLength;
//将已经匹配的字符串按照三个一组将其插入到哈希表中
--curMatchLength;//当前字符串已经插入过了
while (curMatchLength)
{
start++;
_ht.Insert(matchHead, _pWin[start+2], start, hashAddr);
curMatchLength--;
}
++start; //循环中start少加了一次
6.如果文件大于64K要更新窗口
- 压缩文件大于64K,将window中字符压缩到小于等于MIN_LOOKAHEAD 正确
- 压缩文件小于64K||现在已经处理到文件末尾,不需要填充
if (lookAhead <= MIN_LOOKAHEAD)
FillWindow(fIn,lookAhead,start);
7. 查找匹配完成后,最后一个不够8个比特位也要写入压缩文件
if (bitCount > 0 && bitCount < 8)
{
chFlag <<= (8 - bitCount);
fputc(chFlag, fOutF);
}
8.合并压缩文件
//先将文件关闭,清空缓冲区
fclose(fOutF);
//合并压缩文件
MergeFile(fOUT, fileSize);
fclose(fIn);
fclose(fOUT);
压缩完整流程
void LZ77::CompressFile(const std::string& strFilePath)
{
//获取文件大小
FILE* fIn = fopen(strFilePath.c_str(), "rb");
if (nullptr == fIn)
{
cout << "打开文件失败" << endl;
return;
}
//获取文件大小
fseek(fIn, 0, SEEK_END);
ULL fileSize = ftell(fIn);
//1.如果源文件的大小小于MIN_MATCH一个匹配长度,则不进行处理
if (fileSize <= MIN_MATCH)
{
cout << "文件太小,不压缩" << endl;
return;
}
//从压缩文件中读取一个缓冲区的数据到窗口中
fseek(fIn, 0, SEEK_SET);
size_t lookAhead = fread(_pWin, 1, 2 * WSIZE, fIn);
USH hashAddr = 0;
//处理前两个字节...设置hashAddr
for (USH i = 0; i < MIN_MATCH - 1; ++i)
{
_ht.HashFunc(hashAddr, _pWin[i]);
}
//压缩
FILE* fOUT = fopen("2.lzp", "wb");
assert(fOUT);
USH start = 0;
//与查找最长匹配相关的变量
USH matchHead = 0;
USH curMatchLength = 0; //当前匹配长度
USH curMatchDist = 0;
//与写标记相关的变量
UCH chFlag = 0;
USH bitCount = 0;
bool IsLen = false;
//写标记的文件
FILE* fOutF = fopen("3.txt", "wb");
assert(fOutF);
//lookAhead表示先行缓冲区中剩余字节的个数
while (lookAhead)
{
//1.将当前三个字符(start,start+1,start+2)插入到哈希表中,获取匹配头
_ht.Insert(matchHead, _pWin[start + 2],start,hashAddr);
curMatchLength = 0;
curMatchDist = 0;
//2. 验证在查找缓冲区中是否找到匹配,如果有匹配,找最长匹配
if (matchHead)
{
//顺着匹配链找最长匹配,最终带出<长度,距离>对
curMatchLength = LongetMatch(matchHead, curMatchDist,start);
}
//3.验证是否找到匹配
if (curMatchLength < MIN_MATCH)
{
//在查找缓冲区中未找到重复字符串
// 将start 位置的字符写入到压缩文件中
fputc(_pWin[start], fOUT);
//写当前字符原字符对应的标记
WriteFlage(fOutF,chFlag,bitCount,false );
++start;
lookAhead--;
}
else
{
//找到匹配
//将<长度,距离>对写入到压缩文件中
//写长度
UCH chLen = curMatchLength - 3;
fputc(chLen, fOUT);
//写距离
fwrite(&curMatchDist, sizeof(curMatchDist), 1, fOUT);
//写当前对应的标记
WriteFlage(fOutF, chFlag, bitCount, true);
//更新先行缓冲区中剩余的字节数,curMatchLength已经处理过了,就减去
lookAhead -= curMatchLength;
//将已经匹配的字符串按照三个一组将其插入到哈希表中
--curMatchLength;//当前字符串已经插入过了
while (curMatchLength)
{
start++;
_ht.Insert(matchHead, _pWin[start+2], start, hashAddr);
curMatchLength--;
}
++start; //循环中start少加了一次
}
//检测先行缓冲区中剩余字符的个数
// 1.压缩文件大于64K,将window中字符压缩到小于等于MIN_LOOKAHEAD 正确
// 2.压缩文件小于64K||现在已经处理到文件末尾,不需要填充
// 情况1. start>=WSIZE
// 情况2. start < WSIZE
if (lookAhead <= MIN_LOOKAHEAD)
FillWindow(fIn,lookAhead,start);
}
//标记位数如果不够8个比特位:
if (bitCount > 0 && bitCount < 8)
{
chFlag <<= (8 - bitCount);
fputc(chFlag, fOutF);
}
fclose(fOutF);
//合并压缩文件
MergeFile(fOUT, fileSize);
fclose(fIn);
fclose(fOUT);
}
解压缩时,如何判断该字节是原字符还是长度距离对?
解决方式
对压缩文件中的数据进行标记
- 0比特:标记源字符
- 1比特:标记长度
距离不需要标记,因为:如果检测到某个比特位是1,说明该位置对应字节一定是长度,长度后紧跟着的两个字节一定是距离
//chFlag:该字节中的每个比特位是用来区分当前字符是原字符还是长度
//0:代表原字符
//1:代表长度
//bitCount:该字节中的多少比特位已经被设置
//isLen:代表该字节是原字符还是长度
//问题---- 标 记文件没内容
//解决---参数要用引用传参,把修改后的值带出去
void LZ77::WriteFlage(FILE* fOut, UCH& chFalg, USH& bitCount, bool isLen)
{
chFalg <<= 1;
if (isLen)
chFalg |= 1;
bitCount++;
//当前这个字节中的8个比特位已经用完了,写入,重新置为0
if (bitCount == 8)
{
//将该标记写入到压缩文件中
fputc(chFalg, fOut);
chFalg = 0;
bitCount = 0;
}
}
压缩之后压缩文件的格式
解码:
- 用于解码的信息
- 压缩结果:原字符+长度距离对
不能直接将压缩结果保存到压缩文件中,无法区分原字符与长度距离对中的长度,如果不能区分,则无法进行解压缩
解决方式,对写入压缩文件中的每个字节,用一个比特位来进行标记
- 0比特:标记原字符
- 比特:标记长度距离对中的长度,距离不用管,因为距离跟在长度后面
要将用来标记比特位信息+压缩结果 全部保存到压缩文件中
不能先写标记信息,在压缩开始之前,不能知道压缩信息到底是多少,因为标记信息是随着压缩不断进行而构造出来
如何保存:
文件1:压缩结果
文件2:标记信息
压缩完成之后有两个文件,但是解压缩时,如果提供给用户两个文件太麻烦
最终的压缩文件格式:

void LZ77::MergeFile(FILE* fOut,ULL fileSize)
{
//将压缩数据文件和标记信息合并
//1.读取标记信息文件中内容,然后将结果写入到压缩文件中
FILE* fInF = fopen("3.txt", "rb");
size_t flagSize = 0;
UCH* pReadbuff = new UCH[1024];
while (true)
{
size_t rdSize = fread(pReadbuff, 1, 1024, fInF);
if (0 == rdSize)
break;
fwrite(pReadbuff, 1, rdSize,fOut);
flagSize += rdSize;
}
//2. 保存标记信息字节数
//标记字节数
fwrite(&flagSize, sizeof(flagSize), 1, fOut);
//文件大小
fwrite(&fileSize, sizeof(fileSize), 1, fOut);
fclose(fInF);
delete[]pReadbuff;
}
解压缩
1. 先从打开压缩文件
- 打开压缩文件
- 用一个指针读取,标记信息和标记信息大小
//打开压缩文件
FILE* fInD = fopen(strFilePath.c_str(), "rb");
if (fInD == nullptr)
{
cout << "压缩文件打开失败" << endl;
return;
}
// 操作标记的文件指针
FILE* fInF = fopen(strFilePath.c_str(), "rb");
if (fInF == nullptr)
{
cout << "标记打开失败" << endl;
return;
}
2. 从压缩文件末尾往前偏移文件大小字节数,读取标记信息总的字节数
//获取源文件的大小
ULL fileSize = 0;
fseek(fInF, 0 - sizeof(fileSize), SEEK_END);
fread(&fileSize, sizeof(fileSize), 1, fInF);
//获取标记信息大小
size_t flagSize = 0;
fseek(fInF,0-sizeof(fileSize)-sizeof(flagSize), SEEK_END);
fread(&flagSize, sizeof(flagSize), 1, fInF);
3.移动指针到压缩文件起始位置
//将读取标记信息的文件指针移动到保存标记数据的起始位置
//上面已经读取了标记信息的大小,所以得再往前偏移标记信息大小得字节
//然后再偏移标记信息的大小,移动到标记信息的起始位置
fseek(fInF, 0 - sizeof(flagSize)-sizeof(fileSize)-flagSize, SEEK_END);
4. 开始解压缩
- 读取压缩数据,用该字节对应的标记来还原源文件
- 如果该字节的比特位标记0,说明该字节是原字符,将其直接输出到解压缩文件中
- 如果该字节的比特位标记1,说明该字节是长度距离对中的长度
- 从压缩文件中读取长度
- 从压缩文件中读取距离
- 根据长度距离对,从前文已经解压缩成功的部分还原长度距离对部分
//开始解压缩
//写解压缩的数据
FILE* fOut = fopen("4.txt", "wb");
assert(fOut);
//用来匹配前文
FILE* fR = fopen("4.txt", "rb");
UCH bitCount = 0;
UCH chFalg = 0;
ULL encodeCount = 0;//已经解压缩完的字节
while (encodeCount < fileSize)
{
if (0 == bitCount)
{
//先读取一个字节
chFalg = fgetc(fInF);
bitCount = 8;
}
if (chFalg & 0x80)
{
//是距离长度对
//读取长度
USH matchLen = fgetc(fInD) + 3;
//读取距离
USH matchDist = 0;
fread(&matchDist, sizeof(matchDist), 1, fInD);
//清空缓冲区,系统把缓冲区中的数据放到文件中
fflush(fOut);
//更新已经解码的长度
encodeCount += matchLen;
//去前文中找匹配
//fR:读取匹配串中的内容
//从末尾往前偏移0-matchDist
fseek(fR, 0-matchDist, SEEK_END);
UCH ch;
while (matchLen)
{
ch = fgetc(fR);
fputc(ch,fOut);
matchLen--;
fflush(fOut);
}
}
else
{
//是原字符
UCH ch = fgetc(fInD);
fputc(ch, fOut);
encodeCount += 1;
}
chFalg <<= 1;
bitCount--;
}
fclose(fInD);
fclose(fInF);
fclose(fOut);
fclose(fR);
}
注意: 操作系统为了提高IO的效率,并不会直接将数据写到文件中,一般先是将数据保存在缓冲区中,直到缓冲区满或者用户调用fflush函数清空缓冲区或者在关闭文件时,系统会自动清空缓冲区,此时数据才会真正的写入到文件中
所以在用长度距离对还原该部分字节时,必须先清空缓冲区,让系统已经解压缩的部分写入到解压缩文件中,否则还原长度距离对时可能会出错
大于64K的文件的处理
随着压缩的不断进行,查找缓冲区不断的增大,先行缓冲区不断的缩小,如果先行缓冲区中剩余数据到达MIN_LOOKAHEAD时,就需要重新从待压缩文件中读取待压缩数据
怎么填充数据
- 将右窗口中的数据搬移到左窗口
- 必须要更新哈希表
- 如果head,prev中保存的下标:
- 大于WSIZE:减去WSIZE。因为window中右窗的数据已经搬移到左窗中,每个字符的下标都减少WSIZE,哈希表中存储的右窗的下标需要全部更新:减去WSIZE
- 小于WSIZE:置为0。window中左窗的数据距离当前压缩位置太远了,因此不进行匹配,因此需要将哈希表中保存左窗的下标全部清空:将下标置为0
- 如果head,prev中保存的下标:
- 读取一个WSIZE个压缩数据放置到右窗口
void LZ77::FillWindow(FILE* fIn, size_t& lookAhead, USH& start)
{
//压缩已经进行到右窗,先行缓冲区剩余数据不够MIN_LOOKAHEAD
if (start >= WSIZE)
{
//1.将右窗的数据搬移到左窗
memcpy(_pWin, _pWin + WSIZE, WSIZE);
memset(_pWin + WSIZE, 0, WSIZE);
start -= WSIZE;
//2.更新哈希表
_ht.Update();
//3.向右窗中补充一个WSIZE个待压缩数据
if (!feof(fIn)) // 文件指针没走到末尾
lookAhead = fread(_pWin + WSIZE, 1, WSIZE, fIn);
}
}
问题
窗口越界
读取大文件时,窗口越界。
lookAhead类型换成size_t
汉字问题
解压缩的时候,遇到长度距离对还原,需要清空缓冲区,对于文本文件,文件末尾是FF,所以需要清空缓冲区
abcabcabcdef
- 第二个abc没有参与匹配,因为第一个abc首字符的下标再window中的下标是0,因此再head中保存的就是0,第二个abc再匹配时,从哈希表中拿到的匹配链起始就是0,而0将其作为匹配链的结尾标记,因此第二个abc没有参与匹配
- 对bca的匹配过程,查找范围和待压缩的范围重叠----解压缩的时候要及时清空缓冲区