本文基于对Nagios代码的初步分析和网上搜集的资料整理而成,介绍了运维monitor软件的基本功能,nagios的基本配置,nagios的代码结构的轮廓。Nagios的插件开发方法。
成文仓促,许多内容或有错误,随着对nagios日渐深入的了解,我将不断的补充本文。希望最终可以形成一个对Nagios全面和深入的文档。
1 Monitor软件概述
市场上有许多种的 monitor 软件。由于侧重点不同,它们各有差异。但核心功能却都是相同的。对一个 monitor 软件,它要完成或是支持:
n 增加被监视设备
n 数据采集
n 基于时间轴的数据存储
n 通知或是报警
n 报表生成
1.1 增加被监视设备
被监视设备可包括远端的主机,用户的移动终端,专用网中的工业机器等等。只要是 monitor 能从该设备采集到数据,就意味着这个设备被监视了。
1.2 数据采集
Monitor 可以采用各种方法从设备中取得用户需要运行数据。运行数据也可以是五花八门。可以是开关量,连续量。可以是音频数据,也可以是视频数据。采集视频数据通常被看作是另一类软件。
1.3 基于时间轴的数据存储
采集到的历史数据必须被存储在数据库中,才可以支持报表功能。另一方面,monitor 行业也提出了预警的新需求。预警需要建立数学模型,计算时需要历史数据做支撑。
1.4 通知或是报警
Email, SMS, Call on site,
1.5 报表生成
这个是非专业用户最看重的功能。技术部门在采购 monitor 设备后,只有能生成出让相应职能部门看的懂的报表,才能证明 monitor 设备的价值。
2 Nagios 介绍
Nagios 在安装后,会在系统中建立一个名为 nagios 的服务。通过命令 service nagios start 可以启动它。
2.1 设备配置和数据采集
在 nagios 的配置文件中,我们可以增加被监视主机。也可以增加要采集的数据。比如:PING, HTTP,这两者是开关量。也可采集 Disk Usage,这个算是连续量。
可采集的数据并不是可以随意指定的。Nagios 使用 plugin 来支持各种被采集的数据类型。例如,一个名为check_ping的插件就是用来获取PING数据的。而 check_local_disk则是用来采集 root 分区的使用情况。
对于特殊的设备,比如大气自动监测气象仪,就需要为其开发相应的plugin。
当前,在Nagios采用的采集方式有:
n SNMP
n NRPE 代理方式
n SSH 通过SSH连接被监视设备,运行一些命令,如TOP, FREE, DF获得设备运行信息。
n 其它方式需要用户开发相应的插件。
Nagios不支持 auto scan。
2.2 基于时间轴的数据存储
通过配置,Nagios可以将采集的数据写入到/var/nagios/perfdata.log文件中,一行是一次的采集结果。
缺省情况下,nagios并不存储数据。详细情况参考4.2节。
2.3 通知或是报警
N/A
2.4 报表生成
Nagios不支持任何报表的生成。需要安装第三方扩展软件。
3 Nagios的配置
Nagios的配置文件包括主配置文件、资源配置文件、对象配置文件和CGI配置文件。如下图所示:
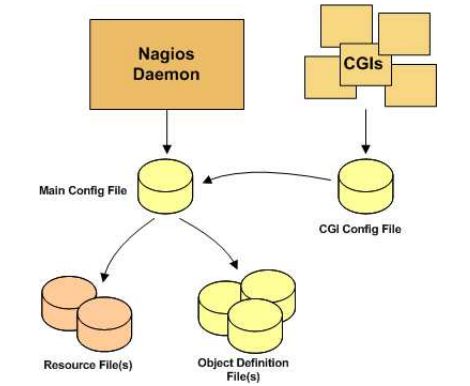
如果是通过源代码包安装的话,配置文件的路径: /usr/local/nagios/etc。
主配置文件是nagios.cfg。
资源配置文件是 resource.cfg
对象配置文件位于 /usr/local/nagios/etc/objects。对象配置文件会有多个。用户增加被监视主机时,相应增加新的对象文件。check命令,联系人也都属于对象配置。
CGI配置文件(侍补充)。
3.1 增加被监视主机
假设用户需要增加新的被监视主机,首先在objects目录中增加一个对象文件。本例中名为tdahost.cfg。
在这个文件中首先定义主机。
define host{
use linux-server ; Name of host template to use
; This host definition will inherit all variables that are defined
; in (or inherited by) the linux-server host template definition.
host_name robertTDA2.58
alias robertTDA2.58
address 10.64.70.239
}
然后,定义我们要监视这个主机的服务。
define service{
use local-service ; Name of service template to use
host_name robertTDA2.58
service_description Total Processes
check_command check_local_procs!250!400!RSZDT
}
最后,将对象文件加入到主配置文件中
cfg_file=/usr/local/nagios/etc/objects/tdahost.cfg
这样一个新设备就被添加到nagios中了。
3.2 数据采集
Nagios提供了一些命令来完成数据采集。所有的命令在commands.cfg中加以定义。
define command{
command_name check-host-alive
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 5
}
上面的命令是用来完成ping check,用于检测host live。
但是,当用户需要nagios监视特殊设备时,我们就需要开发相应的plug-in充当监视用的命令。
每个Plug-in就是一个独立的程序。nagios 每次在查询一个服务的状态时,调用plug-in做为一个子进程,并且它使用来自该命令的输出和退出代码来确定具体的状态。退出状态代码的含义如下所示:
OK—退出代码 0—表示服务正常地工作。
WARNING—退出代码 1—表示服务处于警告状态。
CRITICAL—退出代码 2—表示服务处于危险状态。
UNKNOWN —退出代码 3—表示服务处于未知状态。
最后一种状态通常表示该插件无法确定服务的状态。例如,可能出现了内部错误。
Plug-ins可以使用任何一种语言来开发。Python, tcl, perl, C都可以。
3.3 基于时间轴的数据存储
Nagios不提供数据存储功能。但是它可以把采集的数据存存储到LOG文件中。通过在nagios.cfg中做下列的设置:
process_performance_data=1
service_perfdata_file=/var/opt/nagios/perfdata.log
service_perfdata_file_template=$LASTSERVICECHECK$||$HOSTNAME$||$SERVICEDESC$||$SERVICEOUTPUT$||SERVICEPERFDATA$
service_perfdata_file_mode=a
采集到的数据被写入到/var/opt/nagios/perfdata.log文件中。
3.4 通知或是报警
N/A
3.5 报表生成
Nagios不支持报表生成。为了提供报表生成功能,需要安装第三方软件或自行开发。
为了获表报表功能,首先我们需要得到趋势图。官方推荐nagiosgraph。安装nagiosgragh之前要前安装rrdtool。Rrdtool是一个作图工具,它可以根据时间轴数据生成出趋势图。如下图所示:
通过配置,nagios将所有的数据写入到perfdata.log文件中,我们再做下面的配置,使得数据写到了rrdtool数据库中。
Nagios.cfg
service_perfdata_file_processing_interval=30
service_perfdata_file_processing_command=process-service-perfdata
objects/commands.cfg
define command {
command_name process-service-perfdata
command_line /opt/nagiosgraph/insert.pl
}
定义一个新命令process-service-perfdata。它对应于insert.pl脚本。Nagios每30秒调用一次。这个脚本读取perfdata.log文件,解析读出的第一行,存储到rrdtool数据库中。
Nagiosgraph提供了一次CGI程序,可嵌入到nagios web service中,为用户提供趋势图。
但是,对于用户来说,nagiosgraph提供的趋势图仍很简陋。通常我们需要结合nagiosgraph自行开发。
Nagios是否合适
代码量小。由于Nagios只专注于提供一个平台来整合前端WEB,后端的监视命令。并不提供复杂的UI,结点管理,拓扑和数据存储。因此它的代码量小,易于掌握
结构清晰。由于它的专注,其结构简单。
稳定就不用多说。
Plug-ins易于开发。
缺点
1. 功能不全面。缺乏自动扫描,报表生成,这个是好事,也是坏事。报表生成本就要针对用户定制,少了也不重要。但自动扫描需要重新开发。
2. 前端UI太简陋了。如果为中国用户开发,这个UI要推倒重来。
3. 没有拓扑图的支持。这个也需要前端UI来完成。
4. 集成的plug-in太少了。只有很少的几种。这个问题一方面要进一步的寻找第三方开发的,一方面也可以自已定制。
4 Nagios 代码框架
Nagios.c 是 nagios 的入口。Main函数在这个文件中。Nagios 从这里开始,读取了config 文件,建立了EVENT队列,并且利用这个队列进行自我驱动。每个EVENT又驱动nagios调用相应的plug-in去检查远程服务器或是完成本地的某个功能。
4.1 配置文件读取
read_main_config_file()
主配置文件的读取非常简单,因为主配置文件都是“变量名=值”的形式。只要一行一行的读取即可。从配置文件中读取的数据存入了全局变量中。在nagios.c文件的开头部分,可以看到大量了全局变量的定义。
read_all_object_data()
objects配置文件结构复杂,最终是由xodtemplate.c来完成解析。所读出的数据保存在obejct.c文件中定义的全局变量:
host host_list=NULL,host_list_tail=NULL;
service service_list=NULL,service_list_tail=NULL;
contact contact_list=NULL,contact_list_tail=NULL;
contactgroup contactgroup_list=NULL,contactgroup_list_tail=NULL;
hostgroup hostgroup_list=NULL,hostgroup_list_tail=NULL;
servicegroup servicegroup_list=NULL,servicegroup_list_tail=NULL;
command command_list=NULL,command_list_tail=NULL;
timeperiod timeperiod_list=NULL,timeperiod_list_tail=NULL;
4.2 自我驱动的EVENT LOOP
在main(),将调用init_timing_loop()来建立scheduling_info表,并在EVENT队列中放入EVENT,做好驱动check loop的准备。
1、建立scheduling_info表,表的内容有:
总service数
已经在表中的service数
总host数
在列表中的host数
单个host平均service数(总service数/总host数)
列表中单个host的service数(列表中service数/列表中host数)
平均service检查时间间隔(service检查总间隔/列表中service数)
service检查总间隔
平均service检查延时
host检查总间隔
平均host检查延时
2、计算最优service检查间隔
人工设定(主配置文件中service_inter_check_delay_method选项)
智能计算(平均service检查间隔/列表中总service数)
3、将service检测插入event队列
4、计算最优host检查间隔(同2)
5、将host检测插入event队列
6、插入misc事件
a、重新排列列表
b、收集检测结果
c、检查孤儿service和host
d、检查service新鲜度(针对被动检测)
e、检查host新鲜度(针对被动检测)
f、回收检查结果到status文件
g、检查cmd文件
h、日志滚动事件
i、检查结果保存
第三和第四步非常重要。在init函数中插入event后,将直接驱动nagios运转下去。
nagios在进入守护状态以后,会一直运行一个循环event_execution_loop,nagios所有的操作全部在这个循环中得到实现。
循环会不断检查两个event队列,一个是高优先级event_list_high,包括nagios的除了检查之外的所有任务,另外一个是低优先级event_list_low,包括host和service的检测。循环会先检测高优先级的event队列,然后一个一个执行完毕,最后再判断下host和service的检测是不是有必要,然后再对其进行检测。在执行event队列的时候,用的函数都是一样的,名字是handle_timed_event,当每个handle_timed_event执行完以后返回,然后再执行下一个事件任务。
handle_timed_event函数的开始是个case语句,对事件进行分类处理,具体event_type如下:
1、event_service_check(检查service)
2、event_host_check(检查host)
3、event_command_check(检查cmd文件,被动监控,cgi发送的命令都会送到cmd文件中)
4、event_log_rotation(日志滚动)
5、event_program_shutdown(nagios关闭)
6、event_program_restart(nagios重启)
7、event_check_reaper(检查结果回收)
8、event_orphan_check(检查孤儿host和service)
9、event_retention_save(保存检查结果到retention.dat,关闭nagios不删除此文件)
10、event_status_save(保存检查结果到status.dat,关闭nagios会删除)
11、event_scheduled_downtime
12、event_sfreshness_check(检查service新鲜度?)
13、event_hfreshness_check(检查host新鲜度?)
14、event_expire_downtime
15、event_reschedule_checks(重新编排event列表,与上文说的初始化循环类似)
16、event_expire_comment
17、event_user_function
对于普通的nagios来说,最常用的只有以下几个:1,2,7,10。
如果设置的是被动监控,那会频繁用到3。
handle_timed_event()函数会调用run_async_service_check()函数根据用户定义的command去创建子进程来检查相应的服务状态。检查结果被写到文件中。
检查的命令发出去后,检查的结果需要回收。回收也是用EVENT来触发的。事件名为EVENT_CHECK_REAPER。当这个事件发生时,reap_check_results()被调用。检查结果从文件中读取出来,然后,存放到service_list和host_list上。
最后,event_status_save将host_list和service_list中的数据同步到status.dat中,而且是全部同步。Status.dat中的内容就是这样:
servicestatus {
host_name=robertTDA2.58
service_description=Total Processes
modified_attributes=0
check_command=check_local_procs!250!400!RSZDT
check_period=24x7
notification_period=24x7
check_interval=5.000000
retry_interval=1.000000
event_handler=
has_been_checked=1
should_be_scheduled=1
check_execution_time=0.082
……
这个文件保存的只是某个时间点检查的结果。如果开关打开,nagios会将数据以添加的方式写入到perfdata.log中。
到此,我们可以总结一个结构图。
但仍有一些问题没有解决:
1. Nagios的cache机制
2. 检查时间timeout,如何处理?
3. Rrtool工具的原理和数据库结构。
4.3 CGI接口
Nagios提供了一个简单的WEB UI。带有帐户管理,主机和服务状态显示。但不能在WEB UI上添加主机和服务。这些需要在后台的配置文件中手工配置。
主机和服务状态是由CGI程序从status.dat文件读取的。这个文件保存了上一次状态查询的结果。它是被定时更新的。由于Nagios不生成趋势图,所以,CGI程序只需要读取status.dat来显示当前主机和服务状态就足够了。
Nagios的CGI程序是用C编写的。WEB页面的HTML代码由CGI重组生成。
综上所述,Nagios并无实时连接的CGI接口。前端的WEB UI直接读取配置文件和状态数据。而不需与后台的Nagios通信。
Nagios WEB UI提供了主动查询的功能。这个功能是指,第三方开发者可以为WEB UI增加某些链接,用户通过这些链接主动发起一次状态查询。CGI调用后台的程序来获取状态。结果将被CGI显示在WEB UI上。
遗留的问题:
1. 被动查询方式实现方式?
4.4 Plug-in接口
如上所述,nagios的plug-in可以使用任何语言开发。只要在执行结束时,返回特定的值来表示查询结果即可。如果需要输出一些描述文件,直接使用printf向stdout输出。注意,只能输出一行。输出的文字会被Nagios捕捉到,存入LOG文件中。
Plug-in的开发可参见参考材料。
5 结论
对于特殊设备的状态检查,通过开发plug-in,nagios能够被扩展,以支持新的设备。
Nagios自带的WEB UI完全不满足一般用户的需要。它的WEB UI是为专业的运维人员开发的。所以,WEB UI需要重新的开发。Nagios的用户管理部分可以保留使用。Nagios的CGI实现方式太难移值和重构(将C与HTML混合),恐怕需要废弃。
Nagios运行期间,采集的数据需要利用rrdtool工具来保存。这是一个很优秀的时间数据分析工具。被各个monitor开源软件所采用,包括zenoss。Nagios与rrdtool的整合很容易,也是现成的。Rrdtool采集的数据,经过我们重新开发WEB UI来呈示,相信会更符合用户的需求。
在官方的网站上,自动扫描(auto-discovery)有数款第三方插件,可供选择。因时间关系,未做深入分析。但从网站上的描述来看,这个部分可以借鉴第三方的工作成果。
拓朴图应该也能找到第三方的组件来进行事例。这部分,因时间关系,还没有整理好。
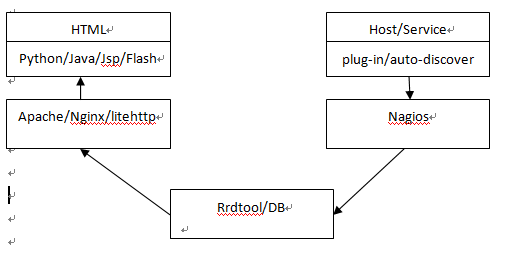
整个系统的架构建议如下: