python+locust性能测试(二)之locust深入使用
目录
- 一、Locust类详细说明
- 二、TaskSet类详细说明
- 2.1 TaskSet类详细说明--@task装饰器
- 2.2 TaskSet类详细说明--tasks属性
- 2.3 TaskSet类详细说明--on_start函数
- 2.4 TaskSet类详细说明--控制任务的执行顺序
- 2.5 TaskSet类详细说明--休眠等待(wait)
- 2.6 TaskSet类详细说明--TaskSets 嵌套
- 2.7 TaskSet类详细说明--中断控制(interrupt)
- 三、Locust中实现参数化
- 情景一
- 情景二
- 四、Locust中实现关联
- 方法一:使用正则表达式
- 方法二:采用lxml库来定位获取需要的参数
- 五、Locust中实现断言
Locust中有两个非常重要的类:Locust类和Taskset类。了解这两个类的使用对于Locust工具的使用是非常有必要的;
一、Locust类详细说明
Locust类中的属性有:
client属性:
task_set: 指向一个TaskSet类,TaskSet类定义了用户的任务信息,该属性为必填;
max_wait/min_wait: 每个用户执行两个任务间隔时间的上下限(毫秒),具体数值在上下限中随机取值,若不指定则默认间隔时间固定为1秒;
host:被测系统的host,当在终端中启动locust时没有指定--host参数时才会用到;
weight:同时运行多个Locust类时会用到,用于控制不同类型任务的执行权重。


在运行结果中发现job2是job1事件执行频率的2倍;
如果希望让某个 locust 类经常被执行,可以在这些类上设置一个 weight 属性。
二、TaskSet类详细说明
TaskSet类:实现了虚拟用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)、中断控制(interrupt)等等。
在此基础上,我们就可以在TaskSet子类中采用非常简洁的方式来描述虚拟用户的业务测试场景,对虚拟用户的所有行为(任务)进行组织和描述,并可以对不同任务的权重进行配置。
在TaskSet子类中定义任务信息时,可以采取两种方式,@task装饰器和tasks属性。
2.1 TaskSet类详细说明–@task装饰器
采用@task装饰器定义任务:
代码演示:
from locust import TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def test_job1(self):
self.client.get('/job1')
@task(2)
def test_job2(self):
self.client.get('/job2')
@task(1)中的数字表示任务的执行频率,数值越大表示执行的频率越高
2.2 TaskSet类详细说明–tasks属性
采用tasks属性定义任务:
代码演示:
from locust import TaskSet
def test_job1(obj):
obj.client.get('/job1')
def test_job2(obj):
obj.client.get('/job2')
class UserBehavior(TaskSet):
tasks = {test_job1:1, test_job2:2}
说明:
tasks = {test_job1:1, test_job2:2}中,test_job1:1,test_job2:2表示事件执行的频率,即test_job2的执行频率是test_job1的两倍
2.3 TaskSet类详细说明–on_start函数
on_start函数是在Taskset子类中使用比较频繁的函数。在正式执行测试前执行一次,主要用于完成一些初始化的工作。
例如,当测试某个搜索功能,而该搜索功能又要求必须为登录态的时候,就可以先在on_start中进行登录操作,HttpLocust使用到了requests.Session,因此后续所有任务执行过程中就都具有登录态了

2.4 TaskSet类详细说明–控制任务的执行顺序
在TaskSequence类中,使用装饰器@seq_task()可以用来控制任务的执行顺序;里面的数值越小执行越靠前;
代码举例:

2.5 TaskSet类详细说明–休眠等待(wait)
在Taskset类中,内置WAIT_TIME功能,它用于确定模拟用户在执行任务之间将等待多长时间。Locust提供了一些内置的函数,返回一些常用的wait_time方法。
1、between(min,max)函数:用得比较多的函数
wait_time = between(3.0, 10.5):任务之间等待的时间是3到10.5秒之间的任意时间
2、constant(number)函数:
wait_time=constant(3):任务之间等待的时候是3秒钟,且等待的时候不能超过任务运行的总时间,也就是在执行py文件时设置的时间
3、constant_pacing(number)函数:
wait_time=constant_pacing(3):所以任务每隔3秒执行,但是当到达运行的总时间时,任务运行结束;

2.6 TaskSet类详细说明–TaskSets 嵌套
现实中有很多任务其实也是有嵌套结构的,比如用户打开一个网页首页后,用户可能会不喜欢这个网页直接离开,或者喜欢就留下来,留下来的话,可以选择看书、听音乐、或者离开;
代码举例:

2.7 TaskSet类详细说明–中断控制(interrupt)
在有Taskset嵌套的情况下,执行子任务时, 通过 self.interrupt() 来终止子任务的执行, 来回到父任务类中执行, 否则子任务会一直执行;
在上一页的案例中,在stay这个类中,对interrupt()方法的调用是非常重要的,这可以让一个用户跳出stay这个类有机会执行leave这个任务,否则他一旦进入stay任务就会一直在看书或者听音乐而难以自拔。
三、Locust中实现参数化
在进行接口多用户并发测试时,数据的重复使用可能会造成脚本的失败,那么需要对用户数据进行参数化来使脚本运行成功。
情景一
在此我们举出百度搜索的例子,假设每个人搜索的内容是不相同的;那么我们可以假设把数据放到队列中,然后从队列中依次把数据取出来;
可以利用python中Queue队列来进行处理;
Queue的种类:
Queue.Queue(maxsize=0):先进先出队列
Queue.LifoQueue(maxsize=0):后进先出队列
Queue.PriorityQueue(maxsize=0):构造一个优先队列
参数maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制
Queue的基本方法:
Queue.Queue(maxsize=0) 如果maxsize小于1就表示队列长度无限
Queue.LifoQueue(maxsize=0) 如果maxsize小于1就表示队列长度无限
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 读队列,timeout等待时间
Queue.put(item, [block[, timeout]]) 写队列,timeout等待时间
Queue.queue.clear() 清空队列

情景二
个别情况下测试数据可重复使用,因此我们可以把参数化数据定义为一个列表,在列表中取出数据;

四、Locust中实现关联
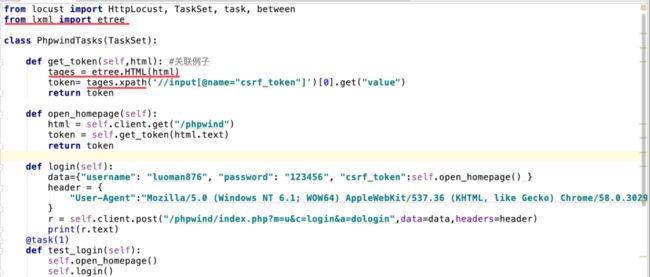
在某些请求中,需要携带之前response中提取的参数,常见场景就是session_id。Python中可用通过re正则匹配,对于返回的html页面,可用采用lxml库来定位获取需要的参数;
我们以Phpwind登陆的来进行举例,在登陆的接口中需要把token参数传给服务器,token的值由页的接口返回;
方法一:使用正则表达式

方法二:采用lxml库来定位获取需要的参数
技术点:
1、导模块:lxml模块
2、etree.HTML() 从返回html页面获取html文件的dom结构
3、xpath() 获取token的xpath路径
五、Locust中实现断言
在进行性能测试时,断言是必须的。比如你在请求一个页面时,就可以通过状态来判断返回的 HTTP 状态码是不是 200。
在locust中通过with self.client.get("url地址",catch_response=True) as response的形式;
通过 client.get() 方法发送请求,将整个请求的给 response, 通过 response.status_code 得请求响应的 HTTP 状态码。如果不为 200 则通过 response.failure('Failed!') 打印失败!如果断言失败后会加到统计错误表中
