FlowNet: Learning Optical Flow with Convolutional Networks
摘&介
CNN一直在识别领域大放异彩,是时候在立体匹配部分展示自己能力了。立体匹配是精确的全像素定位。需要找到两个输入图片之间的关系。不光要学习图像的特征表达,还要学习两图之间的匹配位置关系。光流估计与以往的CNN不同。
我们也不确定CNN能否解决这样的问题,因此格外的引入链接层,这个连接层是具有匹配的能力的。算法是训练成端到端的。思路是详尽的利用卷积网络的在不同尺度和抽象层面的强大的特征表示能力,最终找到这些特征的现实关联。关联层之上的层可预测这些匹配的光流。令人惊奇的是,这种网络没必要且甚至原始网络能够以高精度的预测光流。
训练这样预测光流的网络需要大量的训练集,尽管数据增益有了一定的效果,现存的光流数据集仍旧很小不足以训练出这样的网络。
从现实的视屏中获取光流真值样本是极度困难的,因此我们舍去了样本真实性而保证了样本充足性,生成了所谓的FC数据集。这些数据与真实世界有一定的相关性,然而我们生成了大量的具有浓浓定制色彩的样本。CNN基于这些数据生成了甚至比真实数据集更优的性能,甚至不需要fine-tuning。
2.相关工作-光流
近期的焦点是大规模替换和组合匹配的合并使用。termed DeepMatching与本文工作的联系就是特征信息以稀疏卷积和最大池化由精到粗的聚合。然并软,所有参数人工设置也并没有表现出任何学习性。EpicFlow告诉我们应当把精力主要放在稀疏匹配的质量上,因为当涉及到图像的边界时,匹配只与密度光流领域有关。我们只使用可选的光流优化域的变种方案,这些域由卷积网络构成并不需要任何聚合,匹配和插值的手工艺方法。
有些人以前采用了机器学习方式检测过光流。有人用高斯混合,有人用主成分分析等等。他们估算基础光流的线性组合参数。其他方法从不同的惯性估计中选择训练分类器或者得到闭合可能性。
视频中帧之间的差异和变化可以采用非监督的神经网络模型方式去学习,这些方法大体上都使用乘法插值来获取图像对之间的差异。差异和光流可由潜在的变种所推断。以往的方法效果不行。
3.网络架构
卷积网络
bp卷积网络近些年来在大尺度图像识别领域中获得了较好的效果。这开启了cnn处理计算机视觉任务的大门。虽然用CNN估计光流并没有进展,还有有些其他的神经网络匹配。
最简单的方案就是以滑动窗口的方式去进行CNN,因此,单纯的计算每个输入图片块的预测。这个工作在很多场合都很有效,但有缺点:高计算损耗(即使中间特征最优化计算)和逐块特征,这并不能对全局输出特性做出解释,比如边界。另外一个简单的方法就是上采样所有必要像素的特征映射。这导致连接的逐像素特征矩阵能够用来预测感兴趣的值。
这些方法有的叫做反卷积,尽管技术上来说,这些方法依旧是卷积而不是反卷积。连接上卷积的特征结果值从网络的聚合部分。
众所周知,当给定充足的打上标签的数据样本之后,CNN网络的表现性能是极其好的。因此采用端到端的方式来预测光流:给定图像对和真值框流的数据集,直接从图像中预测光流,不过,什么样的网络才合适呢?
最简单的选择就是堆叠输入图片同时以一个通用的网络来测测它们,让这个网络自己去自动的处理图片对提取运动信息。这就在2图中显示,我们称之为“FlowNetSimple”
原则上说,如果网络足够大,是可以学习预测到光流的。然而,我们不确定SGD能够使得网络收敛。因此,最好还是手动设计网络比较好并且非通用型,对于给定的数据和优化技术还是自己手动的好。
有一个最直接的步骤是创造两个分离,在更后的阶段组合两幅图的识别处理流。这个网络结构呢,先分别产生有效的代表两幅图片的代表,然后在更高层将他们合起来。这就像经典匹配网络中先提取每个图片的特征然后比较这个特征向量。然而,给定两幅图片的特征表示,网络怎么才能找到它们的相关性呢?
为了在匹配阶段中帮助网络的运行,我们引入了“correlation层”来表示两个特征映射之间块的对比连接。包含这一层的“FlowNetCorr”结构显示如上。w,h,c表示管道的宽度,高度和数量。我们correlation层让网络匹配f1的每一块与f2的每一块。
现在,我们只需要考虑两小块的单纯的匹配。两个块的关系定义如下:这是一个长度为2k+1的正方形。注意到这一步与神经网络中的卷积相类似。并非以一个滤波器来对数据进行卷积而是通过数据来卷积数据,因此,这不需要训练的权重。
以c.K_2的乘法量来计算c(x1,x2)。这产生的结果量非常大使得前向后向有效性。因此,出于计算的原因,我们限制了对比的最大替换同时介绍了两幅特征映射的步长。
给定一个最大的替换d,
理论上说,融合之后的结果是四维的。对于由两个2D坐标组合。可以得到一个相关值。两个向量的尺度分别包含剪裁块。实际上,我们在通道上组织相关的替换。这意味着得到尺度(w×h)的输出、对于后向传播,我们可以相应的进行梯度运算到了各自管道的底部。
优化
CNN具有较好的高层提取特征的特性。通过卷基层和池化层,空间上降低了特征映射尺寸。池化是一个必要的使得网络训练有效的策略。更重要的是,为了对于输入图像引入更大面积的聚合。池化导致分辨率的降低,为了提供逐像素的预测,我们需要改善粗池化代表的优化方法。
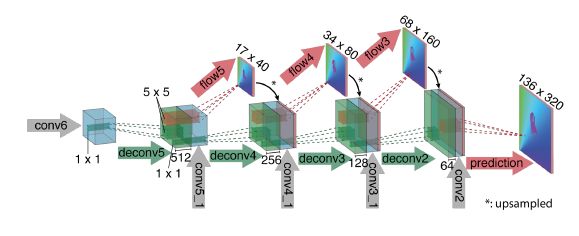
方案就是如上图所示,主要组成部分是上卷积层,由上池化构成(扩大特征映射,与池化对立)。我们对特征映射进行上卷积,联合来自收缩区域对应的特征映射还有来自粗层光流预测,这样的方式可以较好的保留来自底层获取的局部精确信息和高层所提供的粗特征信息。每个步骤都可以增加两倍的分辨率。重复四次。导致输出分辨率是输入图像分辨率的四分之一。我们发现,进一步的对于分辨率的修复并没有很大的提升结果。与全图像分辨率相比,二次插值上采样法的计算损耗更小。双线性上采样的结果就是最终网络预测的光流。可选计划,不采用双线性上采样而是这样的可变方案:先进行四倍的分辨率下采样,接着进行20次迭代使用由粗到精策略将光流域到全分辨率。
(以前写的啥啊????)
Correlation 层 作用就是比对两个特征向量。定义如下,
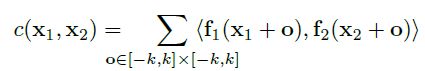
这个公式就是简单的比对两块的。一个中心是第一个特征的x1,另外一个中心是x2。