Win7下用virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己搭一个玩玩,也熟悉一下整体架构。
整体环境:
主机Win7 i5 4核 8G内存 笔记本;
虚拟机(客户机)采用Centos5.9 ( 用这个的原因是不想用图形界面,并且以后还想试着装一下ICE)
3台互联的虚拟机搭建Hadoop集群:
1. 选用virtualbox V4.2.18 + Centos 5.9
virtualbox V4.2.18 下载地址:http://dlc.sun.com.edgesuite.net/virtualbox/4.2.18/VirtualBox-4.2.18-88781-Win.exe
Centos 5.9 下载地址(共9个iso文件):http://mirror.bit.edu.cn/centos/5.9/isos/x86_64/
2. 安装virtualbox 和 Centos5.9
3. hadoop集群用3台机器,拓扑如下:
master: ip:192.168.56.120
机器名: master
启动NameNode
启动JobTracker
slave1: ip: 192.168.56.121
机器名:slave1
启动SecondaryNameNode
启动DataNode
启动TaskTracker
slave2: ip: 192.168.56.122
机器名:slave2
启动DataNode
启动TaskTracker
4. 配置Centos5.9
要求: 在任何环境下主机和客户机都要能够联通,正常工作。包括:笔记本插网线;笔记本不插网线;笔记本联通无线网络;笔记本完全没有网络等情况。
最复杂的情况是笔记本既没有有线网也没有无线网络且没有插网线的情况,这种情况下必须采用host-only的方式。具体原因不细说,因为我也不清楚这四种网络设置的区别到底有哪些 -_-!!!
配置方式参考:http://www.douban.com/group/topic/15558388/ 也可以google搜索 "virtualbox host-only unplug cable"
还是要说一下我对host-only 方式配置的理解:virtualbox安装好之后在windows的”网络和共享中心“ (XP系统叫做网上邻居)中会出现一个新的虚拟网卡"VirtualBox Host-Only Network"。当虚拟机配置为host-only方式的时候,主机和虚拟机通过这个虚拟网卡进行通讯,因此无论主机的外部网络如何,都能和虚拟机联通。因此需要将虚拟机的ip设置到此虚拟网卡的网段内。
我的配置:
VirtualBox Host-Only Network ipv4设置: ip地址: 192.168.56.1
子网掩码:255.255.255.0
centos ip设置: 参考:http://os.51cto.com/art/201001/177909.htm
执行:【vi /etc/sysconfig/network】
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=master
GATEWAY=192.168.56.1执行:【vi /etc/sysconfig/network-scripts/ifcfg-eth0】
DEVICE=eth0
BOOTPROTO=static
NM_CONTROLLED=yes
TYPE=Ethernet
IPADDR=192.168.56.120
HWADDR=08:00:27:XX:XX:XX
NETMASK=255.255.255.0
NETWORK=192.168.56.0
ONBOOT=yes执行:【vi /etc/resolv.conf】添加dns
nameserver 192.168.56.1执行:【vi /etc/hosts】 设置本机名和静态域名解析
127.0.0.1 master localhost
::1 master6 localhost6
#hadoop
192.168.56.120 master
192.168.56.121 slave1
192.168.56.122 slave2执行:【vi /etc/hostname】 设置本机名
master设置完成后运行:【service network restart】 重启网络服务以使设置生效。
测试设置是否成功: a) 从主机ping虚拟机 和 从虚拟机ping主机都要通。如果不通则需要关闭主机和虚拟机的防火墙。
b) 如果还不通则检查virtualbox设置,如下图红圈的地方需要特别注意。
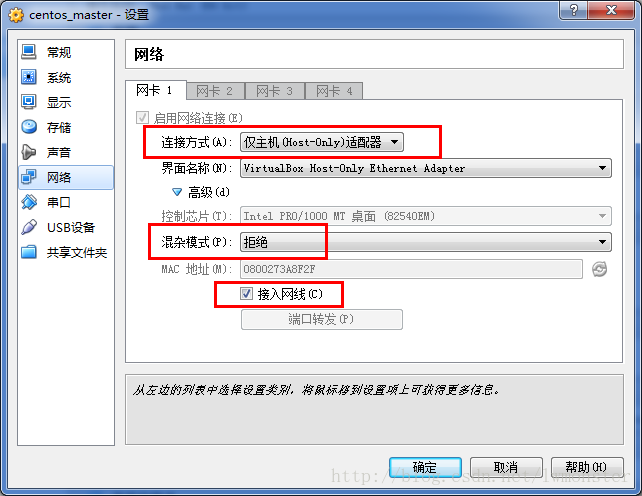
注意: 上面对机器的ip和机器名设置非常重要,因为hadoop的master与slave的连接是通过机器名来做的
5. 安装ssh服务(比较简单,google)
6. 为虚拟机添加hadoop账户
7. 安装jdk1.6 (据说1.7有些问题)
(此步如果centos自带了1.6的jdk的话,可以省略,但是要找到java的安装路径,因为后面配置环境变量要用)
8. 安装hadoop
9. 配置hadoop
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
/home/hadoop/hadoop_tmp/
mapred.job.tracker
master:9001
dfs.replication
3
slave1slave1
slave210. 配置环境变量
$HADOOP_HOME/bin加入PATH
#配置java相关的环境变量
export JAVA_HOME=/usr/java/jdk1.6.0_35
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
#配置hadoop相关环境变量
export HADOOP_HOME=/home/hadoop/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/hadoop-core-1.2.1.jar 11. 克隆两台虚拟机(使用链接复制即可)并设置主机名和ip
执行:【vi /etc/sysconfig/network】
修改:HOSTNAME=slave1 和 HOSTNAME=slave2)
::1 master6 localhost6 --> ::1 slave16 localhost6 )
(对slave2修改:127.0.0.1 master localhost --> 127.0.0.1 slave2 localhost
::1 master6 localhost6 --> ::1 slave26 localhost6 )
12. 配置master ssh无密码登陆到所有机器(包括本机)
13. 测试
8192 Jps
6438 NameNode
6614 JobTracker执行:【ssh hadoop@slave1】
4606 DataNode
4692 SecondaryNameNode
5980 Jps
4784 TaskTracker
执行:【ssh hadoop@slave1】
执行:【jps】
4283 TaskTracker
5437 Jps
4190 DataNodedrwxr-xr-x - hadoop supergroup 0 2013-10-07 22:14 /home14. 错误检查

检查datanode:
浏览器中输入:http://192.168.56.120:50070 打开datanode监控页,正常情况会看到下图:
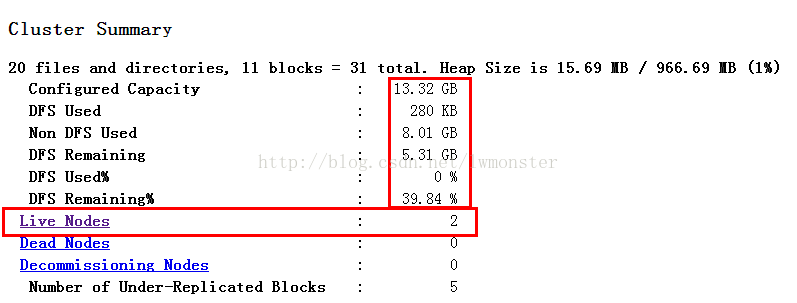
ok,上面都是正常情况,万一遇到不正常的情况改如何查呢? 每个人可能遇到不同的问题,或者同样的错误的原因不一样,所以并没有通用的解决办法,但是万变不离其宗。 这个宗就是hadoop的日志。
在hadoop的安装路径下有一个logs文件夹,里面有很多log,比如:hadoop-hadoop-jobtracker-master.log 一般hadoop出现问题的时候日志都在这里。
如果出现问题,比如上面两张图中显示的Nodes数为0, 那么就可以到master 和 slave1 slave2上的日志里找问题,找到报错信息后再google就可以了。
举例:
我碰到过live nodes 数为0的情况, 查日志发现slave节点找不到master,但是在slave上ping master还能ping通,也可以ssh成功,然后google了一下,说hosts配置有问题,于是把hosts配置改成如下:
#hadoop
192.168.56.120 master
192.168.56.121 slave1
192.168.56.122 slave2其余全部注释掉,就ok啦。