java并发笔记之栅栏源码解读
目录
1、CyclicBarrier
1.1、大致介绍
1.2、构造器
1.3、await()方法
2、Exchange
2.1、大体介绍
2.2、类关系
2.3、构造器
2.4、exchange()方法
2.4.1、slotExchange方法
2.4.2、arenaExchange方法
1、CyclicBarrier
1.1、大致介绍
CyclicBarrier作为栅栏的代表,它满足栅栏的特性,他的关键方法只有一个await()方法。并且有一个内部类Generation,Generation没有太多变量和方法,固定了broken为false

1.2、构造器
必须传入一个容量,线程的传入可选。parties和count可见是两个重要的变量,他们初始相等,且有构造器传入参数决定


1.3、await()方法
await主要捕获error,真正的处理是在dowait之中,await有两个方法,另一个则是传入时间,单位千分之毫秒,表示多长之后阻塞

再来看看doawait()方法,他用的是this的全局重入锁锁定的,直到方法结束。可见每次都只有一个线程执行内部代码。



主要内容主要分为两个部分,第一部分是正常一次性代码,第二部分是自旋,
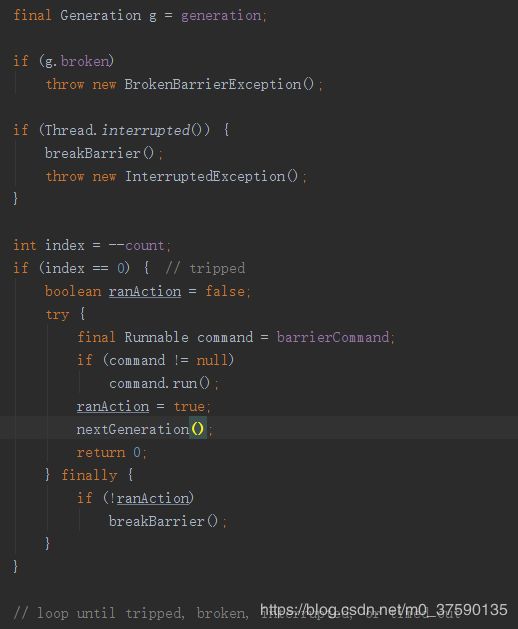
第一部分如下,如果中断了,那么执行全局重入锁的唯一全局Condition,让其Condition唤醒全部阻塞的线程,随后把构造器传入的count减一,由于代码块是单线程执行的,所以也不用CAS去保证,知道统计的线程数量达到指定值时,我们获取构造器传入后来的线程,让其运行。ranAction是用来保证外来线程执行中的未知错误,而使我们所有到达栅栏的线程全部阻塞动不了,而启动breakBarrier来唤醒
 r
r
有关breakBarrier()方法如下,broken表示该栅栏对象曾发生过不可预知的情况记录,重置count并且唤醒,其他到达当前栅栏阻塞的线程。


而在我们一定数量的线程到达以后,使得我们运行条件满足的线程之后,会运行一个nextGeneration()方法
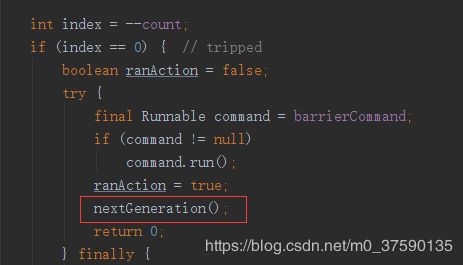
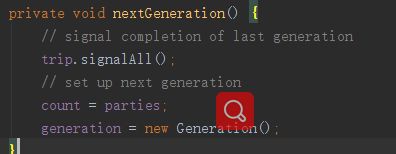
该方法如下,唤醒所有阻塞线程,让他们各干各的事,重置count以及generation。以便下一次运行,注意这里如果像上面breakBarrier方法中标记了该栅栏曾发生过未知错误,也可能在这个地方修复。
然后就是第二部分的自旋了,有很多time判断,表示阻塞线程多久,初始timed为固定false,所以一般线程到了timed的时候就已经阻塞了。还有Generation记录当前栅栏发生过异常的时候返回还剩多少容量才能触发统一性线程。

2、Exchange
2.1、大体介绍
Exchange是用来在两个线程间交换对象的,需要注意的是两个线程需要持有同一个Exchange引用。它对外提供的方法只有一个,exchange()内部会尝试两种交换方式slotExchange和areneExchange。
2.2、类关系
Exchange无任何继承实现的类或接口

只是由两个内部类有点文章

其中,Node节点类如下,记录需要交换的对象信息

而,Participant有点文章,他是继承自ThreadLocal的,不难猜到他的作用

并且两个内部类,均是默认构造器
2.3、构造器
只有一个,比较简单,就是把继承了ThreadLocal的Participant给初始化一下。

2.4、exchange()方法
exchange方法有两个,带参与不带参的,带参TimeUtil,根据之前juc其他类的经验,无法就是延迟执行,延迟激活之类的,功能并不会改变,所以这两个方法殊途同归。
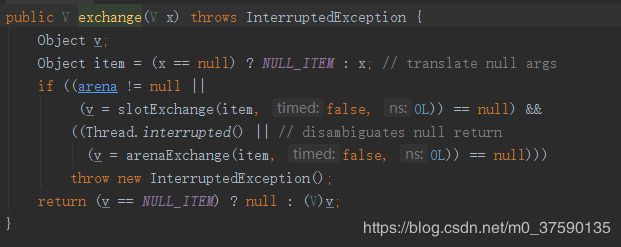

但无论是哪个exchange方法都离不开两个方法:slotExchange槽位交换与arenaExchange点台交换,这两种交换在两个Exchange中都是一样的逻辑,arena为空时,进行slot交换,如果成功,再进行判定,线程未中断就去做arena交换,整个过程如果成功,那么中断,不成功才能返回值。后面既对两种交换做解释
2.4.1、slotExchange方法
比较长,逐段截图。
简单校验后,开始自旋,用到cas不难理解,两个线程可能并发执行该栈帧,而由于Exchange公用一个,则ThreadLocal的子类,公用一个。
首先,槽位slot不为空,原子置空,唤醒之前存放在这的阻塞节点。这点应该是两线程阻塞在某一点的交换成功了,才走到这一步,而槽位不为空的同时,交换不成功,说明发生slot竞争关系,多个线程争用slot,那么就会创建竞技场arena的node数组,也不难想到是用来存高于两个线程的竞争资源的。关于match的解释是,有一个线程进来后,发现slot有东西,拿走后,留下一个放在Match,主要是为了后续多线程争用资源做铺垫。
槽位slot为空,arena不为空,则说明虽然曾有过竞争,但资源都交换完了,没东西给你了,算是一种不健康状态。
而slot和arena同时为空,则更简单了,说明你这个线程是第一个来到该交换点的,东西我帮你存了,存入item,随后Slot记录偏移量
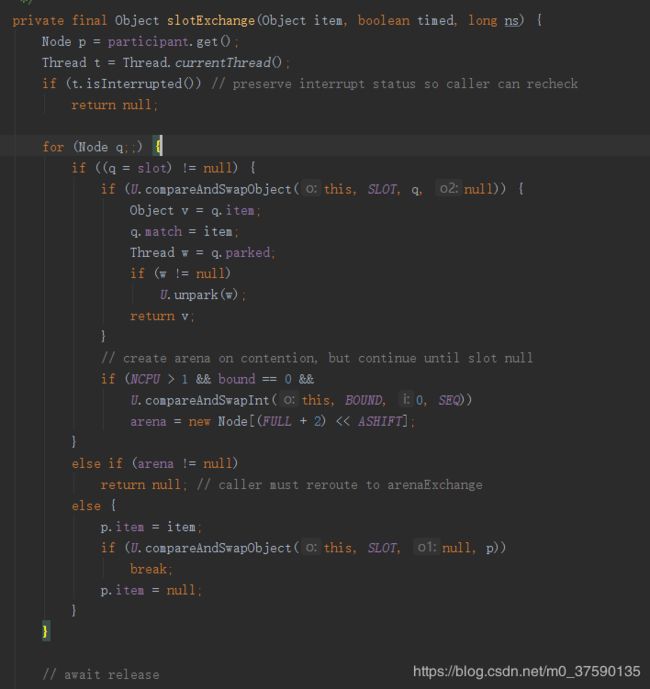
然后一些初始化栈内部变量,h为threadLocal的hash,end为结束时间,spins呢,由于NCPN常量时初始之处Runtime得到的有效线程数量,所以,大多情况下为SPINS:2的十次方,1024,要么极少数情况下为1

一系列循环,从spins的值不难看出,这一过程大多数情况下要经过很多次,由于这里是很复杂的数学原理,博主没法详细解释,只能粗略让人能看懂,h是和threadLocal的hash值有关,而该hash值是一个斐波那契数列,满足一个很晦涩的数学原理后,会暂时不去争用cpu执行权。很有可能是多次,可以简单理解为,低功率消耗的自旋,给别的线程资源。
槽位与ThreadLocal中的不同,那么spins置为1024,这里意欲何为,也无从猜测,继续往下看
随后忽略时间的看,arena为空,既是没有多竞争关系时,把进来存入槽位的线程阻塞掉,CAS park。同时也有内存屏障的put操作,手动置锁,作为一个状态变量,倘若他日唤醒后,状态变量恢复原状。再加上时间看看,不过是延迟多少时间阻塞罢了
而最后又是发现多线程争用资源时候,又给置空槽位一遍。
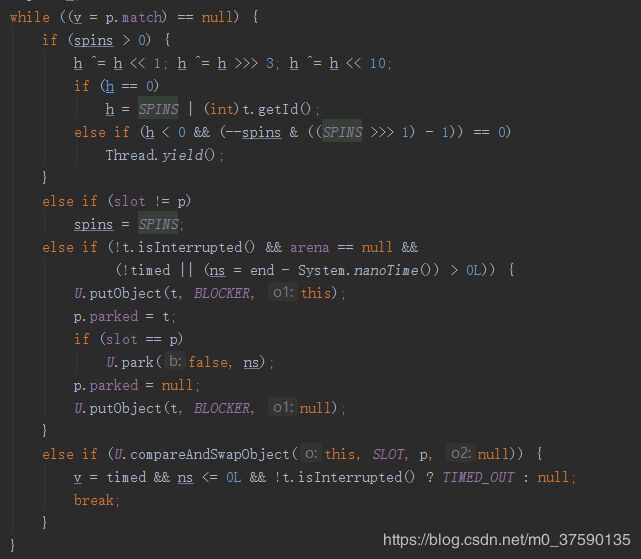
最后一块了,若是其他情况,都早已由返回或者阻塞住了,能到这里的情况,都是争用状态的了,并且再争用状态中已经结束了,之前能把槽位置空的只有一个线程,出来后把通过while中的最后一个if中的Break推出关上开关后,其他线程纷纷出来,至此slot交换结束。
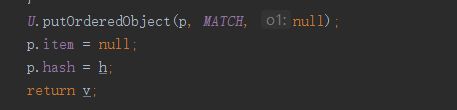
总结:slotexchange是主要考虑只有两个线程发生资源交换时的场景。并且当高于两个线程竞争时,slot存储节点和arena存数组的交换转换
当两个线程交换时,第一个线程将要交换的数据存入slot,随后阻塞,第二线程进来取走slot,并留下钥交换的数据再match中,唤醒第一个线程离去,第一个线程被唤醒后也从match内拿出自己想要的东西离去,exchange复原到最初
当多线程争用时,四个线程同时进来存入slot,那么只有一个成功,然后阻塞,此时恰好第四个线程p=slot时,第二个线程此时已经与第1个线程完成交换,恰好第三个线程此时也存入了slot,那么此时,第四个线程发现slot不是咱自己之前看到的那个,随后发现过来,咱这东西,原来还有其他人在用。开始设置arena了,然后此时,第三个线程已经阻塞,第四个线程已经走到while处。第三个线程依然阻塞着,第四个线程却已经出来了,并且把slot置空了。此时便该考虑下面的了arena交换了。
2.4.2、arenaExchange方法
这个也很长,分段截图来分析
上面方法提到,slot交换主要针对两个线程交换的,再多就没办法了,只能给多余两个的线程交换做准备,这里,会得到arena的node数组,根据偏移量得到实际的node最后原子的将数组中那个node引用置空,某线程得到后,也是将自身的值放入match的套路

然后是很长一段if,一句话概括,是对node数组的一些增链操作减链操作,不难想到,譬如当match为空时,增加交换链表,并且线程阻塞。自旋过程中,也有会slot交换的套路,放弃争用cpu,以最大化资源分配
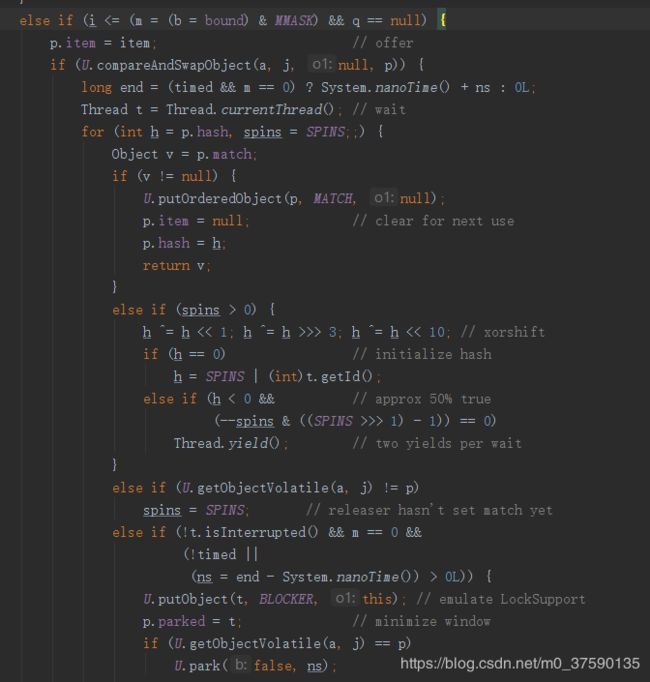
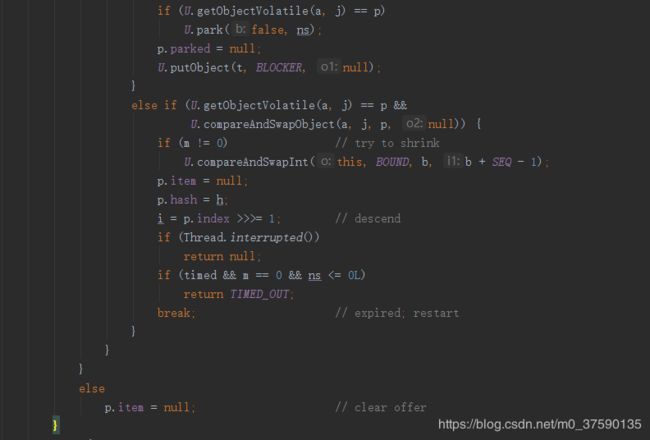
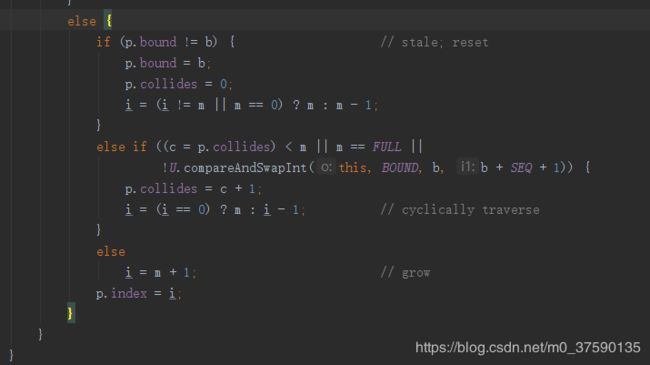
最后,设置一下目前到的偏移量,可以看到最初的index是根据bound决定的,而一开始bound是没有值的,也就是类加载准备阶段的0,随后SEQ为0xff,255+1为256,位运算详情请看hackes delight。m是bound值,i = (i != m || m ==0) ? m : m-1,一开始的i从0启动,一直往数组后面找,直到找不到,就开始一直-1找到又有数据那一块的头node,继续+1的循环查找。