TCP/IP协议栈之LwIP(六)---网络传输管理之TCP协议
文章目录
- 一、TCP协议简介
- 1.1 正面确认与超时重传
- 1.2 连接管理与保活机制
- 1.3 滑动窗口与缓冲机制
- 1.4 流量控制与拥塞控制
- 1.5 提高网络利用率的其他机制
- 二、TCP协议实现
- 2.1 TCP报文格式
- 2.2 TCP数据报描述
- 2.3 TCP状态机
- 2.4 TCP数据报操作
- 2.4.1 TCP报文段输出处理
- 2.4.2 TCP报文段输入处理
- 2.4.3 TCP定时器
- 2.5 SYN攻击
- 更多文章
一、TCP协议简介
在传输层协议中,UDP是一种没有复杂控制,提供面向无连接通信服务的一种协议,它将部分控制转移给应用程序去处理,自己却只提供作为传输层协议的最基本功能。与UDP不同,TCP则是对传输、发送、通信等进行控制的协议。
TCP(Transmission Control Protocol)与UDP(User Datagram Protocol)的区别相当大,它充分实现了数据传输时各种控制功能,可以进行丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制,而这些在UDP中都没有。此外,TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,从而可以控制通信流量的浪费。根据TCP的这些机制,在IP这种无连接的网络上也能够实现高可靠的通信。
为了通过IP数据报实现可靠性传输,需要考虑很多问题,例如数据的破坏、丢包、重复以及分片顺序混乱等问题。TCP通过校验和、序列号、确认应答、重发控制、连接管理、窗口控制等机制实现可靠性传输。
1.1 正面确认与超时重传
在TCP中,当发送端的数据到达接收主机时,接收端主机会返回一个已收到消息的通知,这个消息叫做确认应答(ACK)。TCP通过肯定的确认应答实现可靠的数据传输,当发送端将数据发出之后会等待对端的确认应答,如果有确认应答说明数据已经成功到达对端,反之则说明数据丢失的可能性很大。在一定时间内没有等到确认应答,发送端就可以认为数据已经丢失并进行重发,由此即使产生了丢包仍能保证数据能够到达对端,实现可靠传输。
未收到确认应答并不意味着数据一定丢失,也有可能是数据对方已经收到,只是返回的确认应答在途中丢失,这种情况也会导致发送到因没有收到确认应答而认为数据没有到达目的地,从而进行重新发送。也有可能因为一些其他原因导致确认应答延迟到达,在源主机重发数据以后才到达的情况也屡见不鲜。此时,源发送主机只要按照机制重发数据即可,但目标主机会反复收到相同的数据,为了对上层应用提供可靠的传输必须放弃重复的数据。为此,就必须引入一种机制,它能够识别是否已经接收数据,又能够判断是否需要接收。
上述这些确认应答处理、重传控制以及重复控制等功能都可以通过序列号实现。序列号是按顺序给发送数据的每一个字节都标上号码的编号。接收端查询接收数据TCP首部中的序列号和数据的长度,将自己下一步应该接收的序号作为确认应答返送回去,这样通过序列号和确认应答号,TCP可以实现可靠传输,整个过程如下图所示:
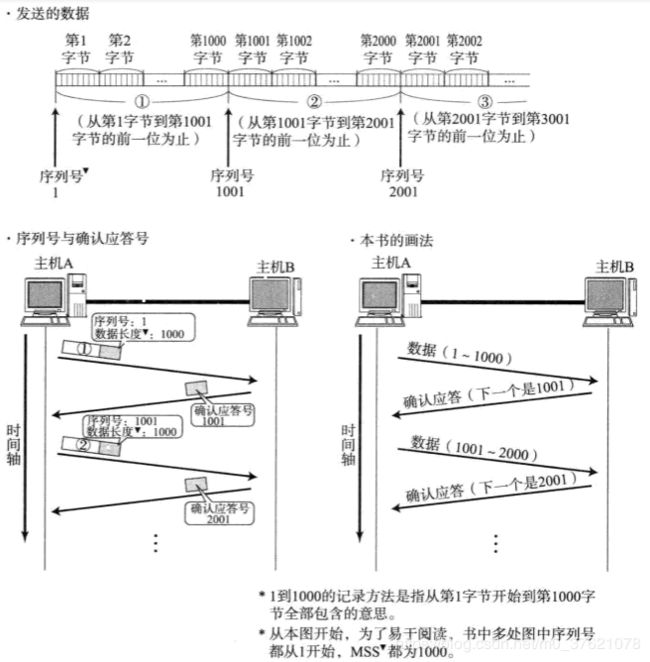
前面说到发送端在一定时间内没有等到确认应答就会进行数据重发,在重发数据之前等待确认应答到来的特定时间间隔就叫重发超时。那么这个重发超时的具体时间长度又是如何确定的呢?
最理想的是,找到一个最小时间,它能保证确认应答一定能在这个时间内返回,然而这个时间长短随着数据包途经的网络环境的不同而有所变化,例如跟网络的距离、带宽、拥堵程度等都有关系。TCP要求不论处在何种网络环境下都要提供高性能通信,并且不论网络拥堵情况发生何种变化,都必须保持这一特性。为此,它在每次发包时都会计算往返时间及其偏差(往返时间RTT估计)。将这个往返时间和偏差相加,重发超时时间就是比这个总和要稍大一点的值。往返时间的计算与重发超时的时间推移过程如下图所示:
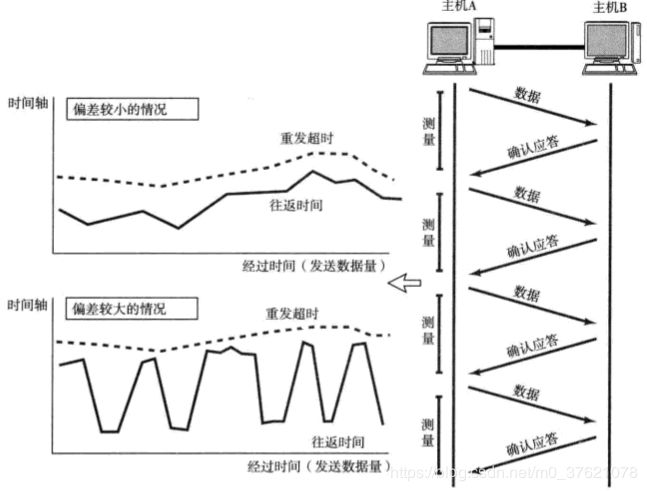
在BSD的Unix以及Windows系统中,超时都以0.5秒为单位进行控制,因此重发超时都是0.5秒的整数倍。不过由于最初的数据包还不知道往返时间,所以其重发超时一般设置为6秒左右。
数据被重发之后若还收不到确认应答,则进行再次发送,此时等待确认应答的时间将会以2倍、4倍的指数函数延长。但数据也不会无限、反复的重发,达到一定重发次数后,如果仍没有任何确认应答返回,就会判断为网络或对端主机发生了异常,强制关闭连接,并通知应用通信异常强行终止。
1.2 连接管理与保活机制
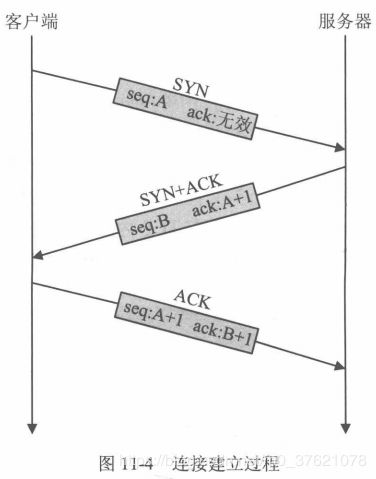
TCP提供面向有连接的通信传输,通信双方在有效数据交互之前,必须建立稳定的连接,同时初始化与连接相关的数据交互、控制信息。UDP是一种面向无连接的通信协议,因此不检查对端是否可以通信,直接将UDP数据包发送出去。TCP与此相反,它会在数据通信之前通过TCP首部发送一个SYN包作为建立连接的请求等待确认应答。如果对端发来确认应答,则认为可以进行数据通信,如果对端的确认应答未能到达,就不会进行数据通信。在TCP中,通信双方按照客户端–服务器模型建立连接的过程称为“三次握手”过程,图示如下:
TCP提供全双工的连接服务,连接的任何一方都可以关闭某个方向上的数据传输,当一个方向上的连接被终止时,另一个方向还可以继续发送数据。当发送数据的一方完成数据发送任务后,它就可以发送一个FIN标志置1的握手包来终止这个方向上的连接,当另一端收到这个FIN包时,它必须通知应用层另一端已经终止了该方向的数据传输。发送FIN通常是应用层进行关闭的结果,收到一个FIN意味着在这个方向上已经没有数据流动,但在另一个方向上仍能发送数据,此时的连接处于半关闭状态。要完全关闭一条连接,需要四次报文交互的过程,称连接断开过程为“四次握手”过程,图示如下:

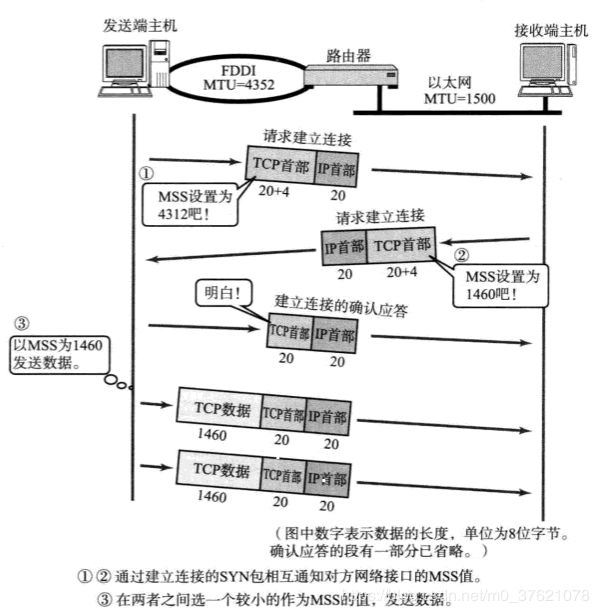
在建立TCP连接的同时,也可以确定发送数据包的单位,也即最大报文段长度(MSS:Maximum Segment Size),最理想的情况是,MSS正好是IP中不会被分片处理的最大数据长度。
TCP在传送大量数据时,是以MSS的大小将数据进行分割传送的,进行重发时也是以MSS为单位的。MSS是在三次握手的时候,在两端主机之间被计算得出的,两端的主机在发送建立连接的请求时,会在TCP首部中写入MSS选项,告诉对方自己的接口能够适应的MSS的大小,然后会在两者之间选择一个较小的值投入使用,整个过程图示如下:
如果一个TCP连接已处于稳定状态,而同时双方都没有数据需要发送,则在这个连接之间不会再有任何信息交互。然而在很多情况下,连接双方都希望知道对方是否仍处于活动状态,TCP提供了保活定时器来实现这种检测功能。
TCP必须为服务器应用程序提供保活功能,服务器通常希望知道客户主机的运行状况,从而可以合理分配客户占用的资源。如果某条连接在两个小时内没有任何动作,则服务器就向客户端发送一个保活探查报文,若客户主机依然正常运行且从服务器仍可达,则服务器应用程序并不能感觉到保活探查的发生,TCP负责的保活探查工作对应用程序不可见;若客户主机崩溃或从服务器不可达等情况,服务器应用程序将收到来自TCP层的差错报文(比如连接超时、连接被对方复位、路由超时等),服务器将终止该连接并释放资源。
1.3 滑动窗口与缓冲机制
TCP以1个段为单位,每发一个段进行一次确认应答处理,这种传输方式有个缺点,包的往返时间越长通信性能就越低。为解决这个问题,TCP引入了窗口的概念,即使在往返时间较长的情况下,它也能控制网络性能的下降。引入了发送接收窗口后,确认应答不再以每个分段而是以更大的单位进行确认,转发时间将会被大幅度将会被大幅度的缩短。
窗口大小就是指无需等待确认应答而可以继续发送数据的最大值,这个机制实现了使用大量的缓冲区,通过对多个段同时进行确认应答的功能。在整个窗口的确定应答没有到达之前,如果其中部分数据出现丢包,那么发送端仍然要负责重传,为此发送端主机得设置缓存保留这些待被重传的数据,直到收到它们的确认应答。滑动窗口的结构如下图示:
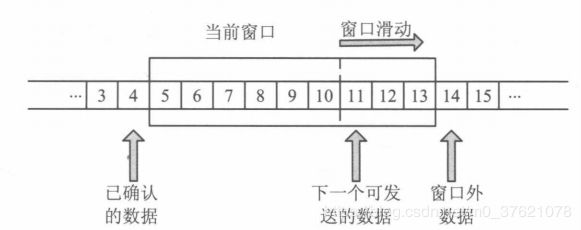
滑动窗口可以看成定义在数据缓冲上的一个窗口,缓冲中存放了从应用程序传递过来的待发送数据。在滑动窗口以外的部分包括尚未发送的数据以及已经确认对端已收到的数据。当数据发出后若如期收到确认应答就可以不用再进行重发,此时数据就可以从缓存区清除。收到确认应答的情况下,将窗口滑动到确认应答中的序列号位置,这样可以顺序的将多个段同时发送提高通信性能,这种机制被称为滑动窗口控制。
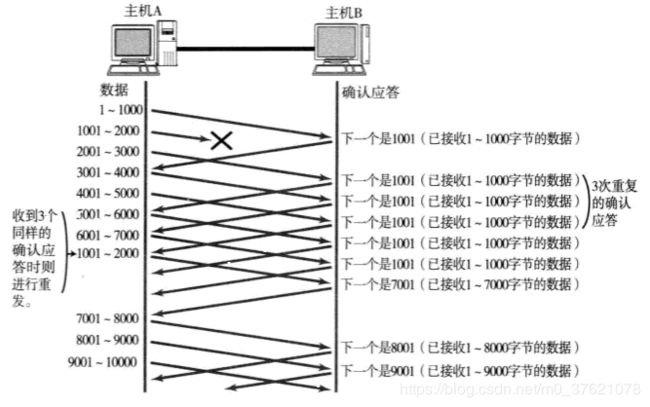
滑动窗口控制可以到达很好的流量控制效果和拥塞控制效果,实际上流量控制与拥塞控制的本质在于对发送窗口的合理调节。由于每个分段都会有确认应答,而滑动窗口的已确认序列号表示该序列号之前的所有数据都已收到确认应答,即便某些确认应答丢失也无需重发。如果某个报文段确实丢失了,同一个序列号的确认应答将会被重复不断的返回(接收端在没有收到自己所期望序列号的数据时,会对之前收到的数据进行确认应答),发送端主机如果连续3次收到同一个确认应答,就会将其所对应的数据进行重发。这种机制比前面介绍的超时重传更高效,因此也被称为快速重传控制。快速重传过程如下图示:
接收方为了接收数据,也必须在接收缓存上维护一个接收窗口,接收方需要将数据填入缓冲区、对数据进行顺序组织(因底层的报文可能是无序到达的,需要把无序报文组织为有序数据流并删除重复报文)等操作,并向发送方通告自己的接收窗口大小,它告诉发送方:我还能接收多少字节的数据。发送方应根据这个窗口通告值适当地调整发送窗口的大小,以调整数据的发送速度。
需要指出的是,TCP是全双工通信,两个方向上的数据传送是独立的,任何一方既可以作为发送端也可以作为接收端,因此任何一方都将为每个TCP连接维护两个窗口,一个用于数据接收,另一个用于数据发送,在一条完整的TCP连接上应该同时存在四个窗口。
1.4 流量控制与拥塞控制
发送端根据自己的实际情况发送数据,接收端可能因缓存耗尽或忙于处理其他任务而来不及处理到来的数据包,如果接收端将本应该接收的数据丢弃的话,就又会触发重传机制,从而导致网络流量的无端浪费。为了防止这种现象的发生,TCP提供了一种机制可以让发送端根据接收端的实际接收能力控制发送的数据量,这就是所谓的流量控制机制。
在TCP首部中,专门有一个字段用来通知接收窗口的大小,接收端主机将自己可以接收的缓存区大小放入这个字段中通知给发送端,发送端会发送不超过这个窗口限度的数据,这个字段的值越大说明网络的吞吐量越高。接收端这个缓冲区一旦面临数据溢出时,窗口大小的值也会随之被设置为一个更小的值通知给发送端,从而控制数据发送量。发送端主机根据接收端主机的指示,对发送数据的量进行控制的过程如下图示:
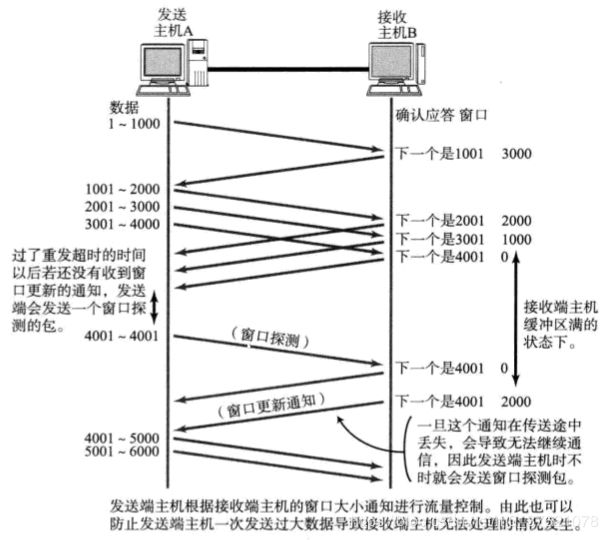
当接收端缓冲区用完后,不得不停止接收数据(此时接收窗口大小为0),在收到发送窗口更新通知后通信才能继续进行。如果这个窗口的更新通知在传送途中丢失,可能会导致无法继续通信,为避免此类问题的发生,发送端主机会定时(由坚持定时器persist timer管理该定时周期)的发送一个叫做窗口探测的数据段,次数据段仅含一个字节以获取最新的窗口大小信息。
有了TCP的窗口控制,收发主机之间即使不再以一个数据段为单位发送确认应答,也能够连续发送大量数据包。计算机网络都处于一个共享环境中,可能会因为其他主机之间的通信使得网络拥堵,如果在通信刚开始时就突然发送大量数据,可能会导致整个网络的瘫痪。TCP为了防止该问题的出现,在通信一开始时就会通过一个叫慢启动的算法得出的数值对发送数据量进行控制。
首先,为了在发送端调节所要发送数据的量,定义了一个叫做拥塞窗口的概念,在慢启动的时候将这个拥塞窗口大小设置为1个数据段(1 MSS)发送数据,之后每收到一次确认应答拥塞窗口的值就加1。在发送数据包时,将拥塞窗口的大小与接收端主机通知的窗口大小做比较,取其中较小的值作为实际发送窗口的大小。有了上述这些机制,就可以有效减少通信开始时连续发包导致的网络拥塞情况的发生。
不过,随着包的每次往返,拥塞窗口也会以1、2、4、8等指数函数增长(每收到一次确认应答拥塞窗口值加1,收到一个窗口大小数量的确认应答则拥塞窗口大小翻倍),拥堵情况激增甚至导致网络拥塞情况的发生。为了防止这些,TCP又引入了慢启动阈值的概念,只要拥塞窗口的值超过这个阈值,在每收到一次确认应答时,只允许以拥塞窗口大小的倒数为单位增加,即收到一个窗口大小数量的确认应答后拥塞窗口大小增加一个数据段,这是拥塞窗口大小是线性增长的,该变化过程如下图所示:
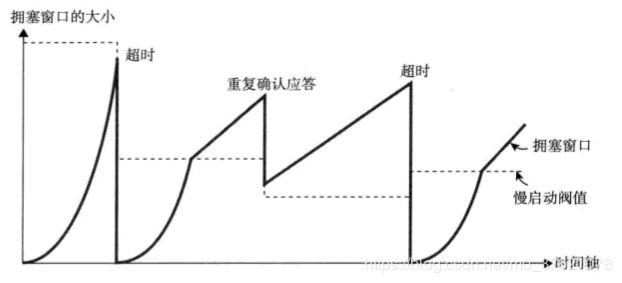
TCP的通信开始时,并没有设置相应的慢启动阈值,而是在超时重传时,才会设置为当时拥塞窗口一半的大小。
由重复确认应答而触发的快速重传与普通的超时重传机制的处理多少有些不同,因为前者要求至少3次的确认应答数据段到达对方主机后才会触发,相比后者网络的拥堵要轻一些。所以由重复确认应答进行快速重传控制时,慢启动阈值的大小被设置为当时窗口大小的一半,然后将发送窗口的大小设置为该慢启动阈值 + 3个数据段的大小,相当于直接跨国慢启动阶段进入拥塞避免阶段,这种机制也称为快速恢复机制。
1.5 提高网络利用率的其他机制
- Nagle算法
TCP中为了提高网络利用率,经常使用一个叫做Nagle的算法,该算法是指发送端即使还有应该发送的数据,但如果这部分数据很少的话,则进行延迟发送的一种处理机制。具体来说就是仅在已发送的数据都已收到确认应答或可以发送最大段长度的数据时才能发送数据,如果两个条件都不满足则暂时等待一段时间后再进行数据发送。
根据这个算法虽然网络利用率可以提高,但可能会发生某种程度的延迟。在某些对响应实时性要求比较高的应用场景中使用TCP时,往往会关闭对该算法的启用。
- 延迟确认应答
接收数据的主机如果每次都立刻回复确认应答的话,可能会返回一个较小的窗口,发送端主机收到这个小窗口通知后会以它为上限发送数据,从而又降低了网络利用率。为此引入了一个方法,在收到数据后不立即返回确认应答,而是延迟一段时间(直到收到2 MSS数据时为止,最大延迟0.5秒)发送确认应答。
TCP采用滑动窗口机制,通常确认应答少一些也不无妨,TCP文件传输时,绝大多数都是每两个数据段返回一次确认应答。
- 捎带应答
根据应用层协议,发送出去的数据到达对端,对端处理后会返回一个回执,在双方通信过程中,为提高网络利用率,TCP的确认应答和回执数据可以通过一个包发送,这种方式叫做捎带应答。
接收数据传给应用处理生成回执数据需要一段时间,如果要实现捎带应答,需要确认应答等待回执数据的生成,如果没有启用延迟确认应答就无法实现捎带应答。延迟确认应答是能够提高网络利用率从而降低计算机处理负荷的一种较优的处理机制。
二、TCP协议实现
2.1 TCP报文格式
TCP协议有着自己的数据报组织格式,这里把TCP的数据包称为报文段(Segment),TCP报文段封装在IP数据报中发送。TCP报文段由TCP首部和TCP数据区组成,首部区域包含了连接建立与断开、数据确认、窗口大小通告、数据发送相关的所有标志与控制信息,TCP报文结构如下图所示:
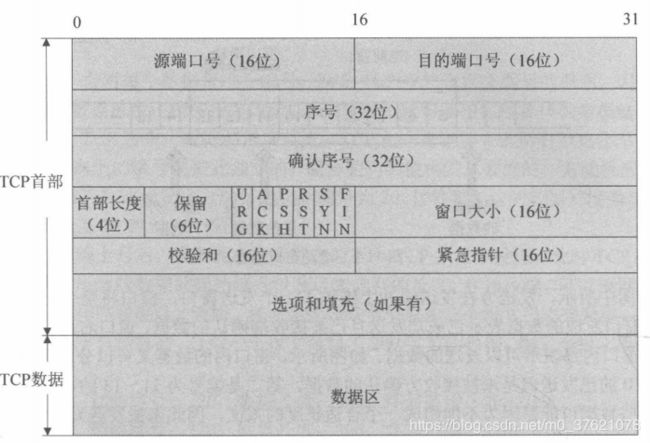
TCP首部相比UDP首部要复杂得多,TCP中没有表示包长度和数据长度的字段,可由IP层获知TCP的包长再由TCP的包长可知数据的长度。TCP首部的大小为20~60字节,在没有任何选项的情况下,首部大小为20字节,与不含选项字段的IP报首部大小相同,TCP数据部分可以为空(比如建立或断开连接时)。
与UDP报文相同,源端口号和目的端口号两个字段用来标识发送端和接收端应用进程分别绑定的端口号。32位序号字段标识了从TCP发送端到TCP接收端的数据字节编号,它的值为当前报文段中第一个数据的字节序号。32位确认序号只有ACK标志置1时才有效,它包含了本机所期望收到的下一个数据序号(即上次已成功收到数据字节序号加1),确认常常和反向数据一起捎带发送。序列号与确认应答号共同为TCP的正面确认、超时重传、有序重组等可靠通信提供支持。
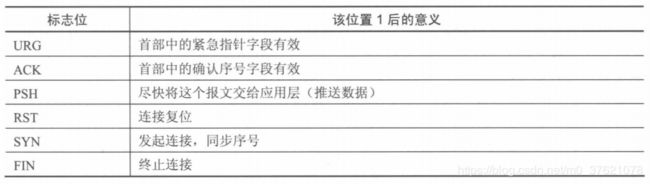
4位首部长度指出了TCP首部的长度,以4字节为单位,若没有任何选项字段则首部长度为5(5*4 = 20字节)。接下来的6bit保留字段暂未使用,为将来保留。再接下来是6个标志比特,它们告诉了接收端应该如何解释报文的内容,比如一些报文段携带了确认信息、一些报文段携带了紧急数据、一些报文段包含建立或关闭连接的请求等,6个标志位的意义如下表示:
在TCP发送一个报文时,可在窗口字段中填写相应值以通知对方自己的可用缓冲区大小(以字节为单位),报文接收方需要根据这个值来调整发送窗口的大小。窗口字段是实现流量控制的关键字段,当接收方向发送方通知一个大小为0的窗口时,将完全阻止发送方的数据发送。
16位校验和字段的计算和上一章中UDP校验和计算过程与原理都相同,在UDP首部中校验和的计算是可选的,但在TCP中校验和的计算是必须的、强制的。TCP中校验和包含了伪首部、TCP首部和TCP数据区三部分,伪首部的概念与UDP中完全一样,只是伪首部中的协议字段值为6,与TCP相对应。
16位的紧急指针只有当紧急标志位URG置位时才有效,此时报文中包含紧急数据,紧急数据始终放到报文段数据开始的地方,而紧急指针定义出了紧急数据在数据区中的结束处,用这个值加上序号字段值就得到了最后一个紧急数据的序号。URG位置1的报文段将告诉接收方:这里面的数据是紧急的,你可以优先直接读取,不必把它们放在接收缓冲里面(即该报文段不使用普通的数据流形式被处理)。
TCP首部可包含0个或多个选项信息,选项总长度可达40字节,用来把附加信息传递给对方。每条TCP选项由三部分组成:1字节的选项类型 + 1字节的选项总长度 + 选项数据,具有代表性的选项如下表所示:
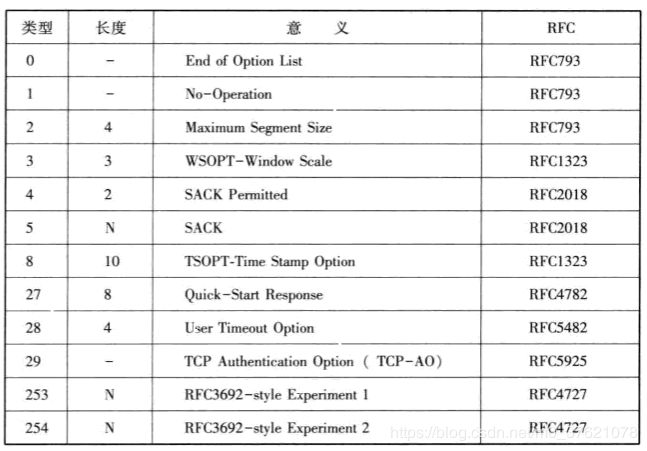
其中类型代码为2的选项是最大报文段长度(MSS),每个连接通常都在通信的第一个报文段(包含SYN标志的连接握手报文)中指明这个选项,用来向对方指明自己所能接受的最大报文段,如果没有指明则使用默认MSS为536,前面提到的客户端与服务器协商确定MSS的功能就是通过该选项实现的。
类型代码为3的选项是窗口扩大因子选项,可以让通信双方声明更大的窗口,首部中的窗口字段长度16bit,即接收窗口最大值为65535字节,在许多高速场合下,这样的窗口还是太小,会影响发送端的发送速度。使用该选项可以向对方通告更大的窗口,此时通告窗口大小值(假设为N)为首部中窗口大小字段值(假设为W)乘以2的窗口扩大因子值(假设为A)次幂(即N = W * 2^A)。
2.2 TCP数据报描述
TCP数据报首部比UDP复杂些,描述TCP的数据结构自然更复杂,在LwIP中用于描述TCP首部的数据结构如下:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\tcp_impl.h
/* Fields are (of course) in network byte order.
* Some fields are converted to host byte order in tcp_input().
*/
PACK_STRUCT_BEGIN
struct tcp_hdr {
PACK_STRUCT_FIELD(u16_t src);
PACK_STRUCT_FIELD(u16_t dest);
PACK_STRUCT_FIELD(u32_t seqno);
PACK_STRUCT_FIELD(u32_t ackno);
PACK_STRUCT_FIELD(u16_t _hdrlen_rsvd_flags);
PACK_STRUCT_FIELD(u16_t wnd);
PACK_STRUCT_FIELD(u16_t chksum);
PACK_STRUCT_FIELD(u16_t urgp);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
#define TCP_FIN 0x01U
#define TCP_SYN 0x02U
#define TCP_RST 0x04U
#define TCP_PSH 0x08U
#define TCP_ACK 0x10U
#define TCP_URG 0x20U
#define TCP_ECE 0x40U
#define TCP_CWR 0x80U
#define TCPH_HDRLEN(phdr) (ntohs((phdr)->_hdrlen_rsvd_flags) >> 12)
#define TCPH_FLAGS(phdr) (ntohs((phdr)->_hdrlen_rsvd_flags) & TCP_FLAGS)
#define TCPH_HDRLEN_SET(phdr, len) (phdr)->_hdrlen_rsvd_flags = htons(((len) << 12) | TCPH_FLAGS(phdr))
#define TCPH_FLAGS_SET(phdr, flags) (phdr)->_hdrlen_rsvd_flags = (((phdr)->_hdrlen_rsvd_flags & PP_HTONS((u16_t)(~(u16_t)(TCP_FLAGS)))) | htons(flags))
#define TCPH_HDRLEN_FLAGS_SET(phdr, len, flags) (phdr)->_hdrlen_rsvd_flags = htons(((len) << 12) | (flags))
#define TCPH_SET_FLAG(phdr, flags ) (phdr)->_hdrlen_rsvd_flags = ((phdr)->_hdrlen_rsvd_flags | htons(flags))
#define TCPH_UNSET_FLAG(phdr, flags) (phdr)->_hdrlen_rsvd_flags = htons(ntohs((phdr)->_hdrlen_rsvd_flags) | (TCPH_FLAGS(phdr) & ~(flags)) )
#define TCP_TCPLEN(seg) ((seg)->len + ((TCPH_FLAGS((seg)->tcphdr) & (TCP_FIN | TCP_SYN)) != 0))
TCP首部中的各个标志位以宏定义的形式表示,同时定义了操作TCP首部各字段的宏定义。
与UDP的内容相同,在TCP实现中也专门使用一个数据结构来描述一个连接,把这个数据结构称为TCP控制块或传输控制块。TCP控制块中包含了双方实现基本通信所需要的信息,如发送窗口、接收窗口、数据缓冲区等,也包含了所有与该连接性能保障相关的字段,如定时器、拥塞控制、滑动窗口控制等。TCP协议实现的本质就是对TCP控制块中各个字段的操作:在接收到TCP报文段时,在所有控制块中查找,以得到和报文目的地相匹配的控制块,并调用控制块上注册的各个函数对报文进行处理;TCP内核维护了一些周期性的定时事件,在定时处理函数中会对所有控制块进行处理,例如把某些控制块中的超时报文段进行重传,把某些控制块中的失序报文段删除。TCP控制块是整个TCP协议的核心,也是整个内核中最大的数据结构,在LwIP中用于描述TCP控制块的数据结构如下:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\tcp.h
/* the TCP protocol control block */
struct tcp_pcb {
/** common PCB members */
IP_PCB;
/** protocol specific PCB members */
TCP_PCB_COMMON(struct tcp_pcb);
/* ports are in host byte order */
u16_t remote_port;
u8_t flags;
#define TF_ACK_DELAY ((u8_t)0x01U) /* Delayed ACK. */
#define TF_ACK_NOW ((u8_t)0x02U) /* Immediate ACK. */
#define TF_INFR ((u8_t)0x04U) /* In fast recovery. */
#define TF_TIMESTAMP ((u8_t)0x08U) /* Timestamp option enabled */
#define TF_RXCLOSED ((u8_t)0x10U) /* rx closed by tcp_shutdown */
#define TF_FIN ((u8_t)0x20U) /* Connection was closed locally (FIN segment enqueued). */
#define TF_NODELAY ((u8_t)0x40U) /* Disable Nagle algorithm */
#define TF_NAGLEMEMERR ((u8_t)0x80U) /* nagle enabled, memerr, try to output to prevent delayed ACK to happen */
/* the rest of the fields are in host byte order
as we have to do some math with them */
/* Timers */
u8_t polltmr, pollinterval;
u8_t last_timer;
u32_t tmr;
/* receiver variables */
u32_t rcv_nxt; /* next seqno expected */
u16_t rcv_wnd; /* receiver window available */
u16_t rcv_ann_wnd; /* receiver window to announce */
u32_t rcv_ann_right_edge; /* announced right edge of window */
/* Retransmission timer. */
s16_t rtime;
u16_t mss; /* maximum segment size */
/* RTT (round trip time) estimation variables */
u32_t rttest; /* RTT estimate in 500ms ticks */
u32_t rtseq; /* sequence number being timed */
s16_t sa, sv; /* @todo document this */
s16_t rto; /* retransmission time-out */
u8_t nrtx; /* number of retransmissions */
/* fast retransmit/recovery */
u8_t dupacks;
u32_t lastack; /* Highest acknowledged seqno. */
/* congestion avoidance/control variables */
u16_t cwnd;
u16_t ssthresh;
/* sender variables */
u32_t snd_nxt; /* next new seqno to be sent */
u32_t snd_wl1, snd_wl2; /* Sequence and acknowledgement numbers of last
window update. */
u32_t snd_lbb; /* Sequence number of next byte to be buffered. */
u16_t snd_wnd; /* sender window */
u16_t snd_wnd_max; /* the maximum sender window announced by the remote host */
u16_t acked;
u16_t snd_buf; /* Available buffer space for sending (in bytes). */
#define TCP_SNDQUEUELEN_OVERFLOW (0xffffU-3)
u16_t snd_queuelen; /* Available buffer space for sending (in tcp_segs). */
/* These are ordered by sequence number: */
struct tcp_seg *unsent; /* Unsent (queued) segments. */
struct tcp_seg *unacked; /* Sent but unacknowledged segments. */
struct tcp_seg *ooseq; /* Received out of sequence segments. */
struct pbuf *refused_data; /* Data previously received but not yet taken by upper layer */
/* Function to be called when more send buffer space is available. */
tcp_sent_fn sent;
/* Function to be called when (in-sequence) data has arrived. */
tcp_recv_fn recv;
/* Function to be called when a connection has been set up. */
tcp_connected_fn connected;
/* Function which is called periodically. */
tcp_poll_fn poll;
/* Function to be called whenever a fatal error occurs. */
tcp_err_fn errf;
/* idle time before KEEPALIVE is sent */
u32_t keep_idle;
/* Persist timer counter */
u8_t persist_cnt;
/* Persist timer back-off */
u8_t persist_backoff;
/* KEEPALIVE counter */
u8_t keep_cnt_sent;
};
struct tcp_pcb_listen {
/* Common members of all PCB types */
IP_PCB;
/* Protocol specific PCB members */
TCP_PCB_COMMON(struct tcp_pcb_listen);
};
/**
* members common to struct tcp_pcb and struct tcp_listen_pcb
*/
#define TCP_PCB_COMMON(type) \
type *next; /* for the linked list */ \
void *callback_arg; \
/* the accept callback for listen- and normal pcbs, if LWIP_CALLBACK_API */ \
DEF_ACCEPT_CALLBACK \
enum tcp_state state; /* TCP state */ \
u8_t prio; \
/* ports are in host byte order */ \
u16_t local_port
#define DEF_ACCEPT_CALLBACK tcp_accept_fn accept;
enum tcp_state {
CLOSED = 0,
LISTEN = 1,
SYN_SENT = 2,
SYN_RCVD = 3,
ESTABLISHED = 4,
FIN_WAIT_1 = 5,
FIN_WAIT_2 = 6,
CLOSE_WAIT = 7,
CLOSING = 8,
LAST_ACK = 9,
TIME_WAIT = 10
};
/* This structure represents a TCP segment on the unsent, unacked and ooseq queues */
struct tcp_seg {
struct tcp_seg *next; /* used when putting segements on a queue */
struct pbuf *p; /* buffer containing data + TCP header */
u16_t len; /* the TCP length of this segment */
u8_t flags;
#define TF_SEG_OPTS_MSS (u8_t)0x01U /* Include MSS option. */
#define TF_SEG_OPTS_TS (u8_t)0x02U /* Include timestamp option. */
#define TF_SEG_DATA_CHECKSUMMED (u8_t)0x04U /* ALL data (not the header) is
checksummed into 'chksum' */
struct tcp_hdr *tcphdr; /* the TCP header */
};
/** Function prototype for tcp accept callback functions. Called when a new
* connection can be accepted on a listening pcb.
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param newpcb The new connection pcb
* @param err An error code if there has been an error accepting.
* Only return ERR_ABRT if you have called tcp_abort from within the
* callback function!
*/
typedef err_t (*tcp_accept_fn)(void *arg, struct tcp_pcb *newpcb, err_t err);
/** Function prototype for tcp receive callback functions. Called when data has
* been received.
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param tpcb The connection pcb which received data
* @param p The received data (or NULL when the connection has been closed!)
* @param err An error code if there has been an error receiving
* Only return ERR_ABRT if you have called tcp_abort from within the
* callback function!
*/
typedef err_t (*tcp_recv_fn)(void *arg, struct tcp_pcb *tpcb,
struct pbuf *p, err_t err);
/** Function prototype for tcp sent callback functions. Called when sent data has
* been acknowledged by the remote side. Use it to free corresponding resources.
* This also means that the pcb has now space available to send new data.
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param tpcb The connection pcb for which data has been acknowledged
* @param len The amount of bytes acknowledged
* @return ERR_OK: try to send some data by calling tcp_output
* Only return ERR_ABRT if you have called tcp_abort from within the
* callback function!
*/
typedef err_t (*tcp_sent_fn)(void *arg, struct tcp_pcb *tpcb,
u16_t len);
/** Function prototype for tcp poll callback functions. Called periodically as
* specified by @see tcp_poll.
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param tpcb tcp pcb
* @return ERR_OK: try to send some data by calling tcp_output
* Only return ERR_ABRT if you have called tcp_abort from within the
* callback function!
*/
typedef err_t (*tcp_poll_fn)(void *arg, struct tcp_pcb *tpcb);
/** Function prototype for tcp error callback functions. Called when the pcb
* receives a RST or is unexpectedly closed for any other reason.
* @note The corresponding pcb is already freed when this callback is called!
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param err Error code to indicate why the pcb has been closed
* ERR_ABRT: aborted through tcp_abort or by a TCP timer
* ERR_RST: the connection was reset by the remote host
*/
typedef void (*tcp_err_fn)(void *arg, err_t err);
/** Function prototype for tcp connected callback functions. Called when a pcb
* is connected to the remote side after initiating a connection attempt by
* calling tcp_connect().
* @param arg Additional argument to pass to the callback function (@see tcp_arg())
* @param tpcb The connection pcb which is connected
* @param err An unused error code, always ERR_OK currently ;-) TODO!
* Only return ERR_ABRT if you have called tcp_abort from within the
* callback function!
* @note When a connection attempt fails, the error callback is currently called!
*/
typedef err_t (*tcp_connected_fn)(void *arg, struct tcp_pcb *tpcb, err_t err);
/* The TCP PCB lists. */
/** List of all TCP PCBs bound but not yet (connected || listening) */
struct tcp_pcb *tcp_bound_pcbs;
/** List of all TCP PCBs in LISTEN state */
union tcp_listen_pcbs_t tcp_listen_pcbs;
/** List of all TCP PCBs that are in a state in which
* they accept or send data. */
struct tcp_pcb *tcp_active_pcbs;
/** List of all TCP PCBs in TIME-WAIT state */
struct tcp_pcb *tcp_tw_pcbs;
上面的TCP控制块tcp_pcb看起来很大,可以把成员变量分组,每种TCP相关机制的实现只涉及到其中的某几个字段,这几个字段可以按一组去理解和操作。除了定义tcp_pcb,还定义了tcp_pcb_listen,后者主要是用来描述处于LISTEN状态的连接,处于LISTEN状态的连接只记录本地端口信息,不记录任何远程端口信息,一般只用于在服务器端打开某个端口为客户端服务。处于LISTEN状态的控制块不会对应于任何一条有效连接,它会进行数据发送、连接握手之类的工作,因此描述LISTEN状态的控制块结构体比tcp_pcb相比更小,使用它可以节省内存空间。
对于描述一个连接的通用字段(比如远程端口、本地端口、远程IP地址、本地IP地址、控制块优先级等)就不再赘述了。重点说下flags字段,它描述了当前控制块的特性,例如是否允许立即发送ACK、是否使能Nagle算法等,这些标志位是提高TCP传输性能的关键。
TCP控制块中维护了三个缓冲队列,unsent、unacked、ooseq三个字段分别为队列的首指针,unsent用于连接还未被发送出去的报文段,unacked用于连接已经发送出去但还未被确认的报文段,ooseq用于连接接收到的无序报文段,这三个缓冲队列简单的实现了对连接的所有报文段的管理。每个报文段用结构体tcp_seg来描述,并以链表形式组织成队列,tcp_seg报文段不仅包含指向装载报文段的指针pbuf,还包含指向报文段中的TCP首部的指针tcp_hdr,报文段缓冲队列的组织关系如下图所示:
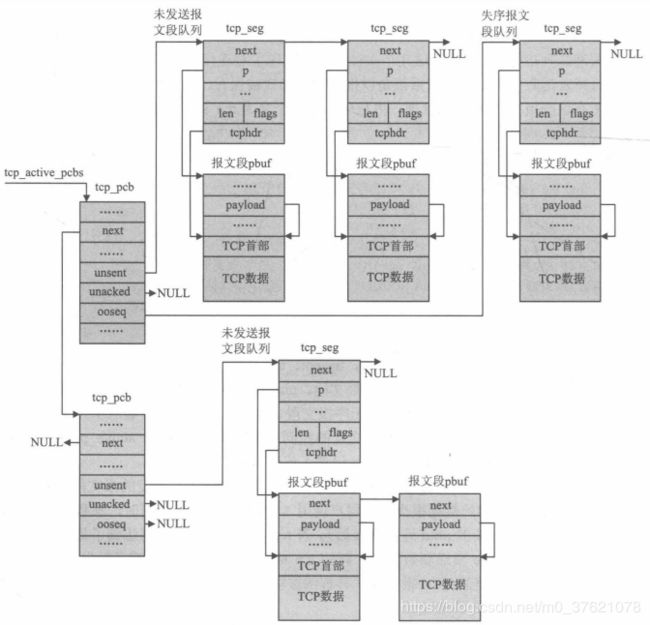
为了组织和描述系统内的所有TCP控制块,内核定义了四条链表来连接处于不同状态下的控制块,TCP操作过程通常都包括对链表上控制块的查找。定义四条链表的代码在上面已给出:tcp_bound_pcbs链表用来连接新创建的且绑定了本地端口的控制块,可以认为此时的控制块处于CLOSED状态;tcp_listen_pcbs链表用来连接处于LISTEN状态的控制块,该状态下用结构体tcp_pcb_listen来描述一个本地连接;tcp_tw_pcbs链表用来连接处于TIME_WAIT状态的控制块;tcp_active_pcbs用于连接处于TCP转换图中其它所有状态的控制块,上图展示的就是该链表上的控制块。
2.3 TCP状态机
TCP状态字段state表示一个连接在整个通信过程中的状态变迁。那么TCP连接的状态是如何变迁的呢?
前面介绍TCP连接管理时谈到TCP建立连接需要“三次握手”过程:首先客户端发送SYN置1的连接请求报文后,从CLOSED状态迁移到SYN_SENT状态;服务器收到客户端的连接请求报文后返回SYN与ACK都置1的应答报文,并从LISTEN状态迁移到SYN_RCVD状态;客户端收到服务器的SYN应答报文后会再次返回ACK置1的应答报文,当服务器收到该应答报文后双方的连接就建立起来了,此时双方都迁移到ESTABLISHED状态。
TCP断开连接需要“四次握手”过程:首先客户端向服务器发送FIN置1的报文后,从ESTABLISHED状态迁移到FIN_WAIT_1状态;服务器收到FIN报文后返回ACK置1的应答报文,并从ESTABLISHED状态迁移到CLOSE_WAIT状态,客户端收到来自服务器的ACK报文后从FIN_WAIT_1状态迁移到FIN_WAIT_2状态;服务器向上层通告该断开操作并向客户端发送一个FIN置1的报文段,从CLOSE_WAIT状态迁移到LAST_ACK状态;客户端收到来自服务器的FIN报文后返回ACK置1的应答报文,并从FIN_WAIT_2状态迁移到TIME_WAIT状态,服务器收到来自客户端的ACK报文后从LAST_ACK状态迁移到CLOSED状态。
在理解了TCP连接建立与断开流程后,再来看TCP状态迁移图就相对容易了,TCP为每个连接定义了11种状态(上面已给出实现代码),下面给出状态转换图如下:
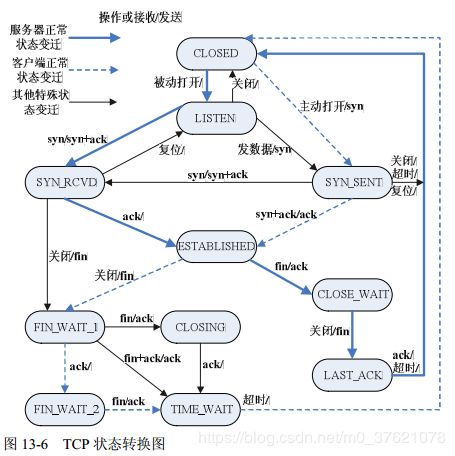
虽然上面的状态转换图看起来很复杂,但并不是每个连接都会出现图中的所有转换路径,图中有两条最经典的状态转换路径,而TCP绝大部分的状态转换都发生在这两条路径上:第一条路径描述了客户端申请建立连接与断开连接的整个过程,如图中虚线所示;第二条路径描述了服务器接受来自客户端的建立连接请求与断开连接请求的整个过程,如图中粗实线所示。配合前面介绍的建立连接的“三次握手”过程与断开连接的“四次握手”过程,应该更容易理解TCP连接的状态迁移过程。
实现TCP状态迁移的状态机函数实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp_in.c
/**
* Implements the TCP state machine. Called by tcp_input. In some
* states tcp_receive() is called to receive data. The tcp_seg
* argument will be freed by the caller (tcp_input()) unless the
* recv_data pointer in the pcb is set.
* @param pcb the tcp_pcb for which a segment arrived
* @note the segment which arrived is saved in global variables, therefore only the pcb
* involved is passed as a parameter to this function
*/
static err_t tcp_process(struct tcp_pcb *pcb)
{
struct tcp_seg *rseg;
u8_t acceptable = 0;
err_t err;
err = ERR_OK;
/* Process incoming RST segments. */
if (flags & TCP_RST) {
/* First, determine if the reset is acceptable. */
if (pcb->state == SYN_SENT) {
if (ackno == pcb->snd_nxt) {
acceptable = 1;
}
} else {
if (TCP_SEQ_BETWEEN(seqno, pcb->rcv_nxt,
pcb->rcv_nxt+pcb->rcv_wnd)) {
acceptable = 1;
}
}
if (acceptable) {
recv_flags |= TF_RESET;
pcb->flags &= ~TF_ACK_DELAY;
return ERR_RST;
} else {
return ERR_OK;
}
}
if ((flags & TCP_SYN) && (pcb->state != SYN_SENT && pcb->state != SYN_RCVD)) {
/* Cope with new connection attempt after remote end crashed */
tcp_ack_now(pcb);
return ERR_OK;
}
if ((pcb->flags & TF_RXCLOSED) == 0) {
/* Update the PCB (in)activity timer unless rx is closed (see tcp_shutdown) */
pcb->tmr = tcp_ticks;
}
pcb->keep_cnt_sent = 0;
tcp_parseopt(pcb);
/* Do different things depending on the TCP state. */
switch (pcb->state) {
case SYN_SENT:
/* received SYN ACK with expected sequence number? */
if ((flags & TCP_ACK) && (flags & TCP_SYN)
&& ackno == ntohl(pcb->unacked->tcphdr->seqno) + 1) {
pcb->snd_buf++;
pcb->rcv_nxt = seqno + 1;
pcb->rcv_ann_right_edge = pcb->rcv_nxt;
pcb->lastack = ackno;
pcb->snd_wnd = tcphdr->wnd;
pcb->snd_wnd_max = tcphdr->wnd;
pcb->snd_wl1 = seqno - 1; /* initialise to seqno - 1 to force window update */
pcb->state = ESTABLISHED;
#if TCP_CALCULATE_EFF_SEND_MSS
pcb->mss = tcp_eff_send_mss(pcb->mss, &(pcb->remote_ip));
#endif /* TCP_CALCULATE_EFF_SEND_MSS */
/* Set ssthresh again after changing pcb->mss (already set in tcp_connect
* but for the default value of pcb->mss) */
pcb->ssthresh = pcb->mss * 10;
pcb->cwnd = ((pcb->cwnd == 1) ? (pcb->mss * 2) : pcb->mss);
--pcb->snd_queuelen;
rseg = pcb->unacked;
pcb->unacked = rseg->next;
tcp_seg_free(rseg);
/* If there's nothing left to acknowledge, stop the retransmit
timer, otherwise reset it to start again */
if(pcb->unacked == NULL)
pcb->rtime = -1;
else {
pcb->rtime = 0;
pcb->nrtx = 0;
}
/* Call the user specified function to call when sucessfully
* connected. */
TCP_EVENT_CONNECTED(pcb, ERR_OK, err);
if (err == ERR_ABRT) {
return ERR_ABRT;
}
tcp_ack_now(pcb);
}
/* received ACK? possibly a half-open connection */
else if (flags & TCP_ACK) {
/* send a RST to bring the other side in a non-synchronized state. */
tcp_rst(ackno, seqno + tcplen, ip_current_dest_addr(), ip_current_src_addr(),
tcphdr->dest, tcphdr->src);
}
break;
case SYN_RCVD:
if (flags & TCP_ACK) {
/* expected ACK number? */
if (TCP_SEQ_BETWEEN(ackno, pcb->lastack+1, pcb->snd_nxt)) {
u16_t old_cwnd;
pcb->state = ESTABLISHED;
/* Call the accept function. */
TCP_EVENT_ACCEPT(pcb, ERR_OK, err);
if (err != ERR_OK) {
/* If the accept function returns with an error, we abort
* the connection. */
/* Already aborted? */
if (err != ERR_ABRT) {
tcp_abort(pcb);
}
return ERR_ABRT;
}
old_cwnd = pcb->cwnd;
/* If there was any data contained within this ACK,
* we'd better pass it on to the application as well. */
tcp_receive(pcb);
/* Prevent ACK for SYN to generate a sent event */
if (pcb->acked != 0) {
pcb->acked--;
}
pcb->cwnd = ((old_cwnd == 1) ? (pcb->mss * 2) : pcb->mss);
if (recv_flags & TF_GOT_FIN) {
tcp_ack_now(pcb);
pcb->state = CLOSE_WAIT;
}
} else {
/* incorrect ACK number, send RST */
tcp_rst(ackno, seqno + tcplen, ip_current_dest_addr(), ip_current_src_addr(),
tcphdr->dest, tcphdr->src);
}
} else if ((flags & TCP_SYN) && (seqno == pcb->rcv_nxt - 1)) {
/* Looks like another copy of the SYN - retransmit our SYN-ACK */
tcp_rexmit(pcb);
}
break;
case CLOSE_WAIT:
/* FALLTHROUGH */
case ESTABLISHED:
tcp_receive(pcb);
if (recv_flags & TF_GOT_FIN) { /* passive close */
tcp_ack_now(pcb);
pcb->state = CLOSE_WAIT;
}
break;
case FIN_WAIT_1:
tcp_receive(pcb);
if (recv_flags & TF_GOT_FIN) {
if ((flags & TCP_ACK) && (ackno == pcb->snd_nxt)) {
tcp_ack_now(pcb);
tcp_pcb_purge(pcb);
TCP_RMV_ACTIVE(pcb);
pcb->state = TIME_WAIT;
TCP_REG(&tcp_tw_pcbs, pcb);
} else {
tcp_ack_now(pcb);
pcb->state = CLOSING;
}
} else if ((flags & TCP_ACK) && (ackno == pcb->snd_nxt)) {
pcb->state = FIN_WAIT_2;
}
break;
case FIN_WAIT_2:
tcp_receive(pcb);
if (recv_flags & TF_GOT_FIN) {
tcp_ack_now(pcb);
tcp_pcb_purge(pcb);
TCP_RMV_ACTIVE(pcb);
pcb->state = TIME_WAIT;
TCP_REG(&tcp_tw_pcbs, pcb);
}
break;
case CLOSING:
tcp_receive(pcb);
if (flags & TCP_ACK && ackno == pcb->snd_nxt) {
tcp_pcb_purge(pcb);
TCP_RMV_ACTIVE(pcb);
pcb->state = TIME_WAIT;
TCP_REG(&tcp_tw_pcbs, pcb);
}
break;
case LAST_ACK:
tcp_receive(pcb);
if (flags & TCP_ACK && ackno == pcb->snd_nxt) {
/* bugfix #21699: don't set pcb->state to CLOSED here or we risk leaking segments */
recv_flags |= TF_CLOSED;
}
break;
default:
break;
}
return ERR_OK;
}
上面就是TCP状态机的转换代码,对照状态转换图更容易理解代码逻辑。
2.4 TCP数据报操作
TCP的输入/输出处理函数较多,它们之间的调用关系也比较复杂,下面用一个总函数调用流程来展示所有这些函数之间的调用关系:

2.4.1 TCP报文段输出处理
前面介绍了TCP Raw API编程,用户应用程序可以通过TCP编程函数tcp_connect、tcp_write等构造一个报文段,这个报文可以用于连接建立和断开的握手报文,也可以是双方的数据交互报文,握手报文段的构造由函数tcp_enqueue_flags构造完成并放入到控制块的发送队列中;而数据报文段的构造是函数tcp_write直接完成的,它将TCP数据和首部部分字段填入报文中,并使用tcp_seg结构体将报文段组织在发送缓冲队列上(一个tcp_seg描述一个可独立发送的报文段);当函数tcp_output被调用时,它会在控制块的发送缓冲队列上依次取下报文段发送,这个函数的唯一工作就是判断报文段是否在允许的发送窗口内,然后调用函数tcp_output_segment发送报文段,当发送完成后,tcp_output会把相应报文段放在控制块的未确认队列unacked上;在tcp_output_segment发送报文段时,它会填写首部中的剩余字段,包括确认序号、通告窗口、选项等,最重要的是,它需要与IP层的ip_route函数交互,获得伪首部中的源IP地址字段,计算并填写TCP首部中的校验和。最后,IP层的发送函数ip_output会被调用,用来组装并发送IP数据报。
下面给出构造数据报文段的tcp_write函数的流程图,实现代码较复杂,读者可以根据流程图对照源码理解其逻辑,构造握手报文段的tcp_enqueue_flags函数比tcp_write简单许多,读者可以参考下面的流程图直接阅读源码:

发送报文段的函数是tcp_output,其唯一参数是某个连接的TCP控制块指针pcb,函数把这个控制块unsent队列上的报文段发送出去或只发送一个ACK报文段(unsent队列无数据发送或发送窗口此时不允许发送数据)。报文段实际由tcp_output_segment发送出去后,tcp_output需将发送出去的报文段放入控制块unacked缓冲队列中(需保证队列中的所有报文段序号有序排列),以便后续的重发操作。当unsent队列上的第一个报文段处理完毕,tcp_output会按照上述方法依次处理unsent队列上的剩余报文段,直到数据被全部发送出去或发送窗口被填满。tcp_write函数的重要部分和tcp_output的实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp_out.c
/**
* Write data for sending (but does not send it immediately).
*
* It waits in the expectation of more data being sent soon (as
* it can send them more efficiently by combining them together).
* To prompt the system to send data now, call tcp_output() after
* calling tcp_write().
*
* @param pcb Protocol control block for the TCP connection to enqueue data for.
* @param arg Pointer to the data to be enqueued for sending.
* @param len Data length in bytes
* @param apiflags combination of following flags :
* - TCP_WRITE_FLAG_COPY (0x01) data will be copied into memory belonging to the stack
* - TCP_WRITE_FLAG_MORE (0x02) for TCP connection, PSH flag will be set on last segment sent,
* @return ERR_OK if enqueued, another err_t on error
*/
err_t tcp_write(struct tcp_pcb *pcb, const void *arg, u16_t len, u8_t apiflags)
{
......
/*
* Finally update the pcb state.
*/
pcb->snd_lbb += len;
pcb->snd_buf -= len;
pcb->snd_queuelen = queuelen;
/* Set the PSH flag in the last segment that we enqueued. */
if (seg != NULL && seg->tcphdr != NULL && ((apiflags & TCP_WRITE_FLAG_MORE)==0)) {
TCPH_SET_FLAG(seg->tcphdr, TCP_PSH);
}
......
}
/**
* Find out what we can send and send it
*
* @param pcb Protocol control block for the TCP connection to send data
* @return ERR_OK if data has been sent or nothing to send
* another err_t on error
*/
err_t tcp_output(struct tcp_pcb *pcb)
{
struct tcp_seg *seg, *useg;
u32_t wnd, snd_nxt;
/* First, check if we are invoked by the TCP input processing
code. If so, we do not output anything. Instead, we rely on the
input processing code to call us when input processing is done
with. */
if (tcp_input_pcb == pcb) {
return ERR_OK;
}
wnd = LWIP_MIN(pcb->snd_wnd, pcb->cwnd);
seg = pcb->unsent;
/* If the TF_ACK_NOW flag is set and no data will be sent (either
* because the ->unsent queue is empty or because the window does
* not allow it), construct an empty ACK segment and send it.
* If data is to be sent, we will just piggyback the ACK (see below).
*/
if (pcb->flags & TF_ACK_NOW &&
(seg == NULL ||
ntohl(seg->tcphdr->seqno) - pcb->lastack + seg->len > wnd)) {
return tcp_send_empty_ack(pcb);
}
/* useg should point to last segment on unacked queue */
useg = pcb->unacked;
if (useg != NULL) {
for (; useg->next != NULL; useg = useg->next);
}
/* data available and window allows it to be sent? */
while (seg != NULL &&
ntohl(seg->tcphdr->seqno) - pcb->lastack + seg->len <= wnd) {
/* Stop sending if the nagle algorithm would prevent it
* Don't stop:
* - if tcp_write had a memory error before (prevent delayed ACK timeout) or
* - if FIN was already enqueued for this PCB (SYN is always alone in a segment -
* either seg->next != NULL or pcb->unacked == NULL;
* RST is no sent using tcp_write/tcp_output.
*/
if((tcp_do_output_nagle(pcb) == 0) &&
((pcb->flags & (TF_NAGLEMEMERR | TF_FIN)) == 0)){
break;
}
pcb->unsent = seg->next;
if (pcb->state != SYN_SENT) {
TCPH_SET_FLAG(seg->tcphdr, TCP_ACK);
pcb->flags &= ~(TF_ACK_DELAY | TF_ACK_NOW);
}
tcp_output_segment(seg, pcb);
snd_nxt = ntohl(seg->tcphdr->seqno) + TCP_TCPLEN(seg);
if (TCP_SEQ_LT(pcb->snd_nxt, snd_nxt)) {
pcb->snd_nxt = snd_nxt;
}
/* put segment on unacknowledged list if length > 0 */
if (TCP_TCPLEN(seg) > 0) {
seg->next = NULL;
/* unacked list is empty? */
if (pcb->unacked == NULL) {
pcb->unacked = seg;
useg = seg;
/* unacked list is not empty? */
} else {
/* In the case of fast retransmit, the packet should not go to the tail
* of the unacked queue, but rather somewhere before it. We need to check for
* this case. -STJ Jul 27, 2004 */
if (TCP_SEQ_LT(ntohl(seg->tcphdr->seqno), ntohl(useg->tcphdr->seqno))) {
/* add segment to before tail of unacked list, keeping the list sorted */
struct tcp_seg **cur_seg = &(pcb->unacked);
while (*cur_seg &&
TCP_SEQ_LT(ntohl((*cur_seg)->tcphdr->seqno), ntohl(seg->tcphdr->seqno))) {
cur_seg = &((*cur_seg)->next );
}
seg->next = (*cur_seg);
(*cur_seg) = seg;
} else {
/* add segment to tail of unacked list */
useg->next = seg;
useg = useg->next;
}
}
/* do not queue empty segments on the unacked list */
} else {
tcp_seg_free(seg);
}
seg = pcb->unsent;
}
pcb->flags &= ~TF_NAGLEMEMERR;
return ERR_OK;
}
从整个发送过程来看,tcp_output只是检查某个报文是否满足被发送的条件,然后调用函数tcp_output_segment将报文段发送出去,后者需要填写TCP报文首部中剩下的几个必要字段,然后调用IP层输出函数ip_output发送报文,tcp_output_segment函数的功能有点类似于UDP协议中的udp_sendto函数,读者可以对照源码理解。
2.4.2 TCP报文段输入处理
从上面的TCP函数调用流程图可以看出,与TCP输入相关的函数有5个,TCP报文被IP层递交给tcp_input函数,这个函数可以说是TCP层的总输入函数,它会为报文段寻找一个匹配的TCP控制块,根据控制块状态的不同,调用tcp_timewait_input、tcp_listen_input或tcp_process处理报文段;这里的重点是函数tcp_process,它实现了前面介绍过的TCP状态机(实现源码也在前面给出),函数根据报文信息完成连接状态的变迁,同时若报文中有数据,则函数tcp_receive会被调用;整个过程中的难点在于函数tcp_receive,它完成了TCP中的数据接收、数据重组等工作,同时TCP中各种性能算法的实现也是在该函数中完成。
在IP层收到数据报后,ip_input函数会判断IP首部中的协议字段,把属于TCP的报文通过tcp_input函数传递到TCP层。tcp_input完成报文向各个控制块的分发,并等待控制块对相应报文的处理结果,它会根据处理结果向用户递交数据或向连接另一端输出响应报文。对于每一个待处理报文,tcp_input都将它们的信息记录在一些全局变量中,其它各函数可以直接操作这些全局变量来得到想要的信息,这些全局变量的定义如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp_in.c
/* These variables are global to all functions involved in the input
processing of TCP segments. They are set by the tcp_input()
function. */
static struct tcp_seg inseg;
static struct tcp_hdr *tcphdr;
static struct ip_hdr *iphdr;
static u32_t seqno, ackno;
static u8_t flags;
static u16_t tcplen;
static u8_t recv_flags;
static struct pbuf *recv_data;
struct tcp_pcb *tcp_input_pcb;
tcp_input函数开始会对IP层递交进来的报文段进行一些基本操作,如丢弃广播或多播数据报、数据校验和验证,同时提取TCP报文首部各个字段填写到上述全局变量中。接下来根据TCP报文段中表示连接的四个字段的值来查找四条链表,在哪条链表上找到对应的控制块则交由相应的函数继续处理。下面给出tcp_input函数的流程图如下:
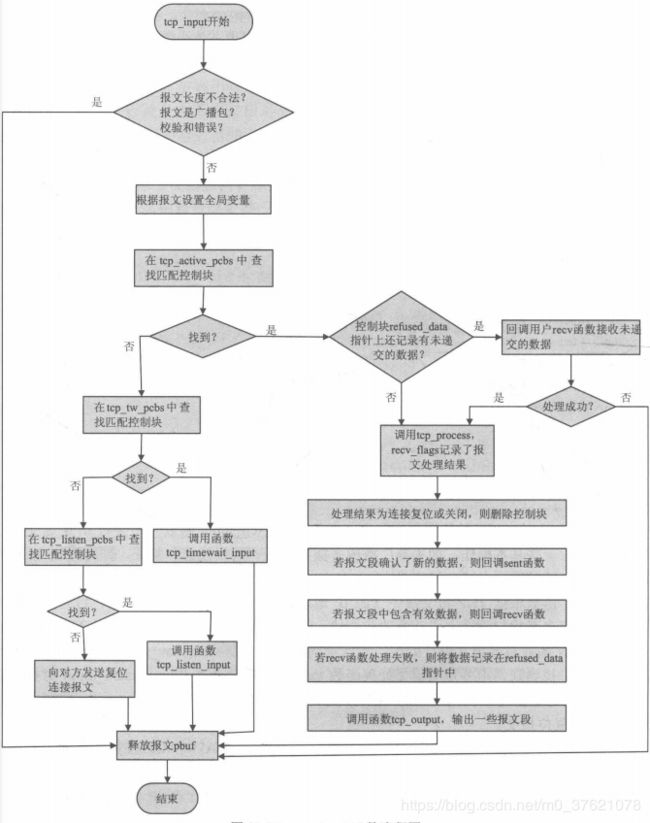
tcp_process函数实现代码前面已给出,下面给出tcp_input部分比较重要的代码(函数太长,不再全部展示,读者可以结合流程图理解源码)、tcp_timewait_input与tcp_listen_input实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp_in.c
/**
* The initial input processing of TCP. It verifies the TCP header, demultiplexes
* the segment between the PCBs and passes it on to tcp_process(), which implements
* the TCP finite state machine. This function is called by the IP layer (in
* ip_input()).
* @param p received TCP segment to process (p->payload pointing to the IP header)
* @param inp network interface on which this segment was received
*/
void tcp_input(struct pbuf *p, struct netif *inp)
{
......
tcp_input_pcb = pcb;
err = tcp_process(pcb);
/* A return value of ERR_ABRT means that tcp_abort() was called
and that the pcb has been freed. If so, we don't do anything. */
if (err != ERR_ABRT) {
if (recv_flags & TF_RESET) {
/* TF_RESET means that the connection was reset by the other
end. We then call the error callback to inform the
application that the connection is dead before we
deallocate the PCB. */
TCP_EVENT_ERR(pcb->errf, pcb->callback_arg, ERR_RST);
tcp_pcb_remove(&tcp_active_pcbs, pcb);
memp_free(MEMP_TCP_PCB, pcb);
} else if (recv_flags & TF_CLOSED) {
/* The connection has been closed and we will deallocate the
PCB. */
if (!(pcb->flags & TF_RXCLOSED)) {
/* Connection closed although the application has only shut down the
tx side: call the PCB's err callback and indicate the closure to
ensure the application doesn't continue using the PCB. */
TCP_EVENT_ERR(pcb->errf, pcb->callback_arg, ERR_CLSD);
}
tcp_pcb_remove(&tcp_active_pcbs, pcb);
memp_free(MEMP_TCP_PCB, pcb);
} else {
err = ERR_OK;
/* If the application has registered a "sent" function to be
called when new send buffer space is available, we call it
now. */
if (pcb->acked > 0) {
TCP_EVENT_SENT(pcb, pcb->acked, err);
if (err == ERR_ABRT) {
goto aborted;
}
}
if (recv_data != NULL) {
if (pcb->flags & TF_RXCLOSED) {
/* received data although already closed -> abort (send RST) to
notify the remote host that not all data has been processed */
pbuf_free(recv_data);
tcp_abort(pcb);
goto aborted;
}
/* Notify application that data has been received. */
TCP_EVENT_RECV(pcb, recv_data, ERR_OK, err);
if (err == ERR_ABRT) {
goto aborted;
}
/* If the upper layer can't receive this data, store it */
if (err != ERR_OK) {
pcb->refused_data = recv_data;
}
}
/* If a FIN segment was received, we call the callback
function with a NULL buffer to indicate EOF. */
if (recv_flags & TF_GOT_FIN) {
if (pcb->refused_data != NULL) {
/* Delay this if we have refused data. */
pcb->refused_data->flags |= PBUF_FLAG_TCP_FIN;
} else {
/* correct rcv_wnd as the application won't call tcp_recved()
for the FIN's seqno */
if (pcb->rcv_wnd != TCP_WND) {
pcb->rcv_wnd++;
}
TCP_EVENT_CLOSED(pcb, err);
if (err == ERR_ABRT) {
goto aborted;
}
}
}
tcp_input_pcb = NULL;
/* Try to send something out. */
tcp_output(pcb);
}
}
......
}
/**
* Called by tcp_input() when a segment arrives for a listening
* connection (from tcp_input()).
* @param pcb the tcp_pcb_listen for which a segment arrived
* @return ERR_OK if the segment was processed
* another err_t on error
* @note the return value is not (yet?) used in tcp_input()
* @note the segment which arrived is saved in global variables, therefore only the pcb
* involved is passed as a parameter to this function
*/
static err_t tcp_listen_input(struct tcp_pcb_listen *pcb)
{
struct tcp_pcb *npcb;
err_t rc;
if (flags & TCP_RST) {
/* An incoming RST should be ignored. Return. */
return ERR_OK;
}
/* In the LISTEN state, we check for incoming SYN segments,
creates a new PCB, and responds with a SYN|ACK. */
if (flags & TCP_ACK) {
/* For incoming segments with the ACK flag set, respond with a RST. */
tcp_rst(ackno, seqno + tcplen, ip_current_dest_addr(),
ip_current_src_addr(), tcphdr->dest, tcphdr->src);
} else if (flags & TCP_SYN) {
npcb = tcp_alloc(pcb->prio);
/* If a new PCB could not be created (probably due to lack of memory),
we don't do anything, but rely on the sender will retransmit the
SYN at a time when we have more memory available. */
if (npcb == NULL) {
return ERR_MEM;
}
/* Set up the new PCB. */
ip_addr_copy(npcb->local_ip, current_iphdr_dest);
npcb->local_port = pcb->local_port;
ip_addr_copy(npcb->remote_ip, current_iphdr_src);
npcb->remote_port = tcphdr->src;
npcb->state = SYN_RCVD;
npcb->rcv_nxt = seqno + 1;
npcb->rcv_ann_right_edge = npcb->rcv_nxt;
npcb->snd_wnd = tcphdr->wnd;
npcb->snd_wnd_max = tcphdr->wnd;
npcb->ssthresh = npcb->snd_wnd;
npcb->snd_wl1 = seqno - 1;/* initialise to seqno-1 to force window update */
npcb->callback_arg = pcb->callback_arg;
npcb->accept = pcb->accept;
/* inherit socket options */
npcb->so_options = pcb->so_options & SOF_INHERITED;
/* Register the new PCB so that we can begin receiving segments
for it. */
TCP_REG_ACTIVE(npcb);
/* Parse any options in the SYN. */
tcp_parseopt(npcb);
npcb->mss = tcp_eff_send_mss(npcb->mss, &(npcb->remote_ip));
/* Send a SYN|ACK together with the MSS option. */
rc = tcp_enqueue_flags(npcb, TCP_SYN | TCP_ACK);
if (rc != ERR_OK) {
tcp_abandon(npcb, 0);
return rc;
}
return tcp_output(npcb);
}
return ERR_OK;
}
/**
* Called by tcp_input() when a segment arrives for a connection in
* TIME_WAIT.
* @param pcb the tcp_pcb for which a segment arrived
* @note the segment which arrived is saved in global variables, therefore only the pcb
* involved is passed as a parameter to this function
*/
static err_t tcp_timewait_input(struct tcp_pcb *pcb)
{
/* RFC 1337: in TIME_WAIT, ignore RST and ACK FINs + any 'acceptable' segments */
/* RFC 793 3.9 Event Processing - Segment Arrives:
* - first check sequence number - we skip that one in TIME_WAIT (always
* acceptable since we only send ACKs)
* - second check the RST bit (... return) */
if (flags & TCP_RST) {
return ERR_OK;
}
/* - fourth, check the SYN bit, */
if (flags & TCP_SYN) {
/* If an incoming segment is not acceptable, an acknowledgment
should be sent in reply */
if (TCP_SEQ_BETWEEN(seqno, pcb->rcv_nxt, pcb->rcv_nxt+pcb->rcv_wnd)) {
/* If the SYN is in the window it is an error, send a reset */
tcp_rst(ackno, seqno + tcplen, ip_current_dest_addr(), ip_current_src_addr(),
tcphdr->dest, tcphdr->src);
return ERR_OK;
}
} else if (flags & TCP_FIN) {
/* - eighth, check the FIN bit: Remain in the TIME-WAIT state.
Restart the 2 MSL time-wait timeout.*/
pcb->tmr = tcp_ticks;
}
if ((tcplen > 0)) {
/* Acknowledge data, FIN or out-of-window SYN */
pcb->flags |= TF_ACK_NOW;
return tcp_output(pcb);
}
return ERR_OK;
}
在TCP内核中,输入报文段中的数据接收和处理都是由函数tcp_receive来完成的,这个函数可以说是整个协议栈内核中代码最长、最难懂的部分了。在前面TCP状态机实现函数tcp_process中可以看到,函数tcp_receive在多个地方被调用来处理报文段中的数据。总结下该函数需要完成的工作:首先检查报文中携带的确认序号是否确认了未确认序列unacked中的数据,如果是则释放掉被确认的数据空间,并设置acked字段值以便tcp_input回调用户函数;同时,如果报文段中有数据且数据有序,这些数据会被记录在recv_data中,以便用户程序处理;如果控制块的ooseq队列上的报文段因为新报文段的到来而变得有序,则这些报文段的数据也会被一起连接在recv_data中,在函数退出后由tcp_input递交给应用程序处理;如果新报文段不是有序的,则报文段将被插入到队列ooseq上,该报文段的引用指针将被加1,防止在其他地方被删除。最后,还有很多其他工作也需要在该函数中完成,例如当前确认序号包含了对正在进行RTT估计的报文段的确认,则RTT需要被计算;如果收到重复的ACK,这可能会在函数中启动快速重传算法等。下面展示了整个tcp_receive函数的处理流程,读者可以参照这个流程图去阅读该函数的源代码:
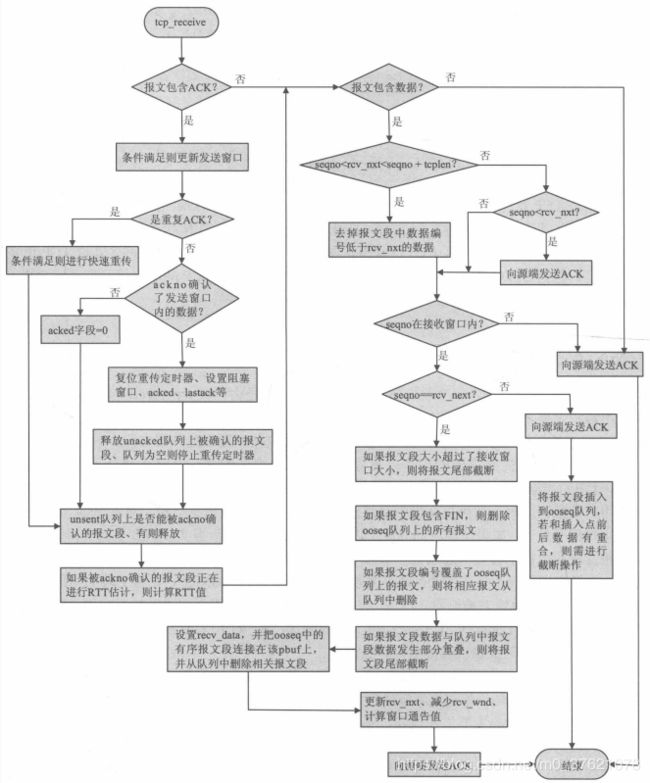
前面介绍了TCP协议如何提供可靠的传输服务,比如超时重传与RTT估计、保活机制、快速重传与快速恢复、慢启动与拥塞避免、零窗口探查、Nagle算法与延迟捎带确认应答等,这些功能的实现代码也都分布在上面介绍的函数中,限于篇幅且某功能实现代码并不局限于某一个函数内,这里就不再一一列出了,读者可以阅读源码理解相应功能的实现逻辑。下面以零窗口探查、快速重传与快速恢复、慢启动与拥塞避免、RTT(Round-Rrip Time)估算与RTO(Retransmission Timeout)更新等功能在tcp_receive函数中的部分实现为例,展示其实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp_in.c
/**
* Called by tcp_process. Checks if the given segment is an ACK for outstanding
* data, and if so frees the memory of the buffered data. Next, is places the
* segment on any of the receive queues (pcb->recved or pcb->ooseq). If the segment
* is buffered, the pbuf is referenced by pbuf_ref so that it will not be freed until
* it has been removed from the buffer.
*
* If the incoming segment constitutes an ACK for a segment that was used for RTT
* estimation, the RTT is estimated here as well.
*
* Called from tcp_process().
*/
static void tcp_receive(struct tcp_pcb *pcb)
{
struct tcp_seg *next;
struct tcp_seg *prev, *cseg;
struct pbuf *p;
s32_t off;
s16_t m;
u32_t right_wnd_edge;
u16_t new_tot_len;
int found_dupack = 0;
if (flags & TCP_ACK) {
right_wnd_edge = pcb->snd_wnd + pcb->snd_wl2;
/* Update window. */
if (TCP_SEQ_LT(pcb->snd_wl1, seqno) ||
(pcb->snd_wl1 == seqno && TCP_SEQ_LT(pcb->snd_wl2, ackno)) ||
(pcb->snd_wl2 == ackno && tcphdr->wnd > pcb->snd_wnd)) {
pcb->snd_wnd = tcphdr->wnd;
/* keep track of the biggest window announced by the remote host to calculate
the maximum segment size */
if (pcb->snd_wnd_max < tcphdr->wnd) {
pcb->snd_wnd_max = tcphdr->wnd;
}
pcb->snd_wl1 = seqno;
pcb->snd_wl2 = ackno;
if (pcb->snd_wnd == 0) {
if (pcb->persist_backoff == 0) {
/* start persist timer */
pcb->persist_cnt = 0;
pcb->persist_backoff = 1;
}
} else if (pcb->persist_backoff > 0) {
/* stop persist timer */
pcb->persist_backoff = 0;
}
}
/* (From Stevens TCP/IP Illustrated Vol II, p970.) Its only a
* duplicate ack if:
* 1) It doesn't ACK new data
* 2) length of received packet is zero (i.e. no payload)
* 3) the advertised window hasn't changed
* 4) There is outstanding unacknowledged data (retransmission timer running)
* 5) The ACK is == biggest ACK sequence number so far seen (snd_una)
*
* If it passes all five, should process as a dupack:
* a) dupacks < 3: do nothing
* b) dupacks == 3: fast retransmit
* c) dupacks > 3: increase cwnd
*
* If it only passes 1-3, should reset dupack counter (and add to
* stats, which we don't do in lwIP)
* If it only passes 1, should reset dupack counter
*/
/* Clause 1 */
if (TCP_SEQ_LEQ(ackno, pcb->lastack)) {
pcb->acked = 0;
/* Clause 2 */
if (tcplen == 0) {
/* Clause 3 */
if (pcb->snd_wl2 + pcb->snd_wnd == right_wnd_edge){
/* Clause 4 */
if (pcb->rtime >= 0) {
/* Clause 5 */
if (pcb->lastack == ackno) {
found_dupack = 1;
if ((u8_t)(pcb->dupacks + 1) > pcb->dupacks) {
++pcb->dupacks;
}
if (pcb->dupacks > 3) {
/* Inflate the congestion window, but not if it means that
the value overflows. */
if ((u16_t)(pcb->cwnd + pcb->mss) > pcb->cwnd) {
pcb->cwnd += pcb->mss;
}
} else if (pcb->dupacks == 3) {
/* Do fast retransmit */
tcp_rexmit_fast(pcb);
}
}
}
}
}
/* If Clause (1) or more is true, but not a duplicate ack, reset
* count of consecutive duplicate acks */
if (!found_dupack) {
pcb->dupacks = 0;
}
} else if (TCP_SEQ_BETWEEN(ackno, pcb->lastack+1, pcb->snd_nxt)){
/* We come here when the ACK acknowledges new data. */
/* Reset the "IN Fast Retransmit" flag, since we are no longer
in fast retransmit. Also reset the congestion window to the
slow start threshold. */
if (pcb->flags & TF_INFR) {
pcb->flags &= ~TF_INFR;
pcb->cwnd = pcb->ssthresh;
}
/* Reset the number of retransmissions. */
pcb->nrtx = 0;
/* Reset the retransmission time-out. */
pcb->rto = (pcb->sa >> 3) + pcb->sv;
/* Update the send buffer space. Diff between the two can never exceed 64K? */
pcb->acked = (u16_t)(ackno - pcb->lastack);
pcb->snd_buf += pcb->acked;
/* Reset the fast retransmit variables. */
pcb->dupacks = 0;
pcb->lastack = ackno;
/* Update the congestion control variables (cwnd and
ssthresh). */
if (pcb->state >= ESTABLISHED) {
if (pcb->cwnd < pcb->ssthresh) {
if ((u16_t)(pcb->cwnd + pcb->mss) > pcb->cwnd) {
pcb->cwnd += pcb->mss;
}
} else {
u16_t new_cwnd = (pcb->cwnd + pcb->mss * pcb->mss / pcb->cwnd);
if (new_cwnd > pcb->cwnd) {
pcb->cwnd = new_cwnd;
}
}
}
......
/* RTT estimation calculations. This is done by checking if the
incoming segment acknowledges the segment we use to take a
round-trip time measurement. */
if (pcb->rttest && TCP_SEQ_LT(pcb->rtseq, ackno)) {
/* diff between this shouldn't exceed 32K since this are tcp timer ticks
and a round-trip shouldn't be that long... */
m = (s16_t)(tcp_ticks - pcb->rttest);
/* This is taken directly from VJs original code in his paper */
m = m - (pcb->sa >> 3);
pcb->sa += m;
if (m < 0) {
m = -m;
}
m = m - (pcb->sv >> 2);
pcb->sv += m;
pcb->rto = (pcb->sa >> 3) + pcb->sv;
pcb->rttest = 0;
}
......
}
2.4.3 TCP定时器
在TCP函数调用总流程中,TCP报文段输出函数tcp_output是被定时器tcp_tmr周期性调用的。此外,与TCP功能相关的定时器还有很多,比如回调函数poll需要定时器的支持,重传、保活等也都离不开定时器支持。总结来说,TCP为每条连接总共建立了七个定时器,分别如下:
- 建立连接(connection establishment)定时器:在服务器响应一个SYN握手报文并试图建立一条新连接时启动,此时服务器已发出自己的SYN+ACK并处于SYN_RCVD等待对方ACK的返回,如果在75秒内没有收到响应,连接建立将中止,这也是服务器处理SYN攻击的有效手段;
- 重传(retransmission)定时器:在TCP发送某个报文时设定,如果该定时器超时而对端的确认还未到达,TCP将重传该报文段。重传间隔是根据RTT估计值动态计算的,且取决于报文段已被重传的次数;
- 数据组装(assemble)定时器:在接收缓冲队列ooseq不为空时有效,如果连接上很长时间内都没有数据交互,但是失序报文段缓冲队列ooseq上还有失序的报文,则相应的报文需要在队列中删除;
- 坚持(persist)定时器:在对方通告接收窗口为0,阻止TCP继续发送数据时设定。定时器超时后,将向对方发送1字节的数据,判断对方接收窗口是否已打开;
- 保活(keep alive)定时器:在TCP控制块的so_options字段设置了SOF_KEEPALIVE选项时生效。如果连接的连续空闲时间超过2小时,则保活定时器超时,此时应向对方发送保活探查报文,强迫对方响应。如果收到期待的响应,TCP可确定对方主机工作正常,重置保活定时器;如果未收到期待的响应,则TCP关闭连接释放资源并通知应用程序对方已断开;
- FIN_WAIT_2定时器:当某个连接从FIN_WAIT_1状态变迁到FIN_WAIT_2状态并且不能再接收任何新数据时,FIN_WAIT_2定时器启动,定时器超时后连接被关闭。
- TIME_WAIT定时器:一般也称为2MSL(Maximum Segment Lifetime)定时器,当连接转移到TIME_WAIT状态即连接主动关闭时,该定时器启动,超时后TCP控制块被删除,端口号可重新使用。同样,服务器端在断开连接过程中会处于LAST_ACK状态等待对方ACK的返回,如果在该状态下的2MSL时间内未收到对方的响应,连接也会被立即关闭。
所有的7个定时器中,重传定时器使用rtime字段计数,坚持定时器使用persist_cnt字段计数,其它所有5个定时器都使用tmr字段,通过与各自的一个全局变量做比较判断是否超时,超时后执行相应的处理。这几个定时器是在连接处于几种不同的状态时使用的,因此它们可以完全独立的使用tmr字段而不会相互影响,下面是它们的超时上限宏定义:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\tcp_impl.h
#define TCP_TMR_INTERVAL 250 /* The TCP timer interval in milliseconds. */
#define TCP_FAST_INTERVAL TCP_TMR_INTERVAL /* the fine grained timeout in milliseconds */
#define TCP_SLOW_INTERVAL (2*TCP_TMR_INTERVAL) /* the coarse grained timeout in milliseconds */
#define TCP_FIN_WAIT_TIMEOUT 20000 /* milliseconds */
#define TCP_SYN_RCVD_TIMEOUT 20000 /* milliseconds */
#define TCP_OOSEQ_TIMEOUT 6U /* x RTO */
#define TCP_MSL 60000UL /* The maximum segment lifetime in milliseconds */
/* Keepalive values, compliant with RFC 1122. Don't change this unless you know what you're doing */
#define TCP_KEEPIDLE_DEFAULT 7200000UL /* Default KEEPALIVE timer in milliseconds */
#define TCP_KEEPINTVL_DEFAULT 75000UL /* Default Time between KEEPALIVE probes in milliseconds */
#define TCP_KEEPCNT_DEFAULT 9U /* Default Counter for KEEPALIVE probes */
#define TCP_MAXIDLE TCP_KEEPCNT_DEFAULT * TCP_KEEPINTVL_DEFAULT /* Maximum KEEPALIVE probe time */
上面介绍的7种定时器包括TCP绝大部分可靠性的保障都是在tcp_slowtmr慢速定时器处理函数中完成的,该函数的实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp.c
/* Incremented every coarse grained timer shot (typically every 500 ms). */
u32_t tcp_ticks;
const u8_t tcp_backoff[13] = { 1, 2, 3, 4, 5, 6, 7, 7, 7, 7, 7, 7, 7};
/* Times per slowtmr hits */
const u8_t tcp_persist_backoff[7] = { 3, 6, 12, 24, 48, 96, 120 };
/* The TCP PCB lists. */
/** List of all TCP PCBs bound but not yet (connected || listening) */
struct tcp_pcb *tcp_bound_pcbs;
/** List of all TCP PCBs in LISTEN state */
union tcp_listen_pcbs_t tcp_listen_pcbs;
/** List of all TCP PCBs that are in a state in which
* they accept or send data. */
struct tcp_pcb *tcp_active_pcbs;
/** List of all TCP PCBs in TIME-WAIT state */
struct tcp_pcb *tcp_tw_pcbs;
/**
* Called every 500 ms and implements the retransmission timer and the timer that
* removes PCBs that have been in TIME-WAIT for enough time. It also increments
* various timers such as the inactivity timer in each PCB.
*
* Automatically called from tcp_tmr().
*/
void tcp_slowtmr(void)
{
struct tcp_pcb *pcb, *prev;
u16_t eff_wnd;
u8_t pcb_remove; /* flag if a PCB should be removed */
u8_t pcb_reset; /* flag if a RST should be sent when removing */
err_t err;
err = ERR_OK;
++tcp_ticks;
++tcp_timer_ctr;
tcp_slowtmr_start:
/* Steps through all of the active PCBs. */
prev = NULL;
pcb = tcp_active_pcbs;
while (pcb != NULL) {
if (pcb->last_timer == tcp_timer_ctr) {
/* skip this pcb, we have already processed it */
pcb = pcb->next;
continue;
}
pcb->last_timer = tcp_timer_ctr;
pcb_remove = 0;
pcb_reset = 0;
if (pcb->state == SYN_SENT && pcb->nrtx == TCP_SYNMAXRTX) {
++pcb_remove;
}
else if (pcb->nrtx == TCP_MAXRTX) {
++pcb_remove;
} else {
if (pcb->persist_backoff > 0) {
/* If snd_wnd is zero, use persist timer to send 1 byte probes
* instead of using the standard retransmission mechanism. */
pcb->persist_cnt++;
if (pcb->persist_cnt >= tcp_persist_backoff[pcb->persist_backoff-1]) {
pcb->persist_cnt = 0;
if (pcb->persist_backoff < sizeof(tcp_persist_backoff)) {
pcb->persist_backoff++;
}
tcp_zero_window_probe(pcb);
}
} else {
/* Increase the retransmission timer if it is running */
if(pcb->rtime >= 0) {
++pcb->rtime;
}
if (pcb->unacked != NULL && pcb->rtime >= pcb->rto) {
/* Double retransmission time-out unless we are trying to
* connect to somebody (i.e., we are in SYN_SENT). */
if (pcb->state != SYN_SENT) {
pcb->rto = ((pcb->sa >> 3) + pcb->sv) << tcp_backoff[pcb->nrtx];
}
/* Reset the retransmission timer. */
pcb->rtime = 0;
/* Reduce congestion window and ssthresh. */
eff_wnd = LWIP_MIN(pcb->cwnd, pcb->snd_wnd);
pcb->ssthresh = eff_wnd >> 1;
if (pcb->ssthresh < (pcb->mss << 1)) {
pcb->ssthresh = (pcb->mss << 1);
}
pcb->cwnd = pcb->mss;
/* The following needs to be called AFTER cwnd is set to one
mss - STJ */
tcp_rexmit_rto(pcb);
}
}
}
/* Check if this PCB has stayed too long in FIN-WAIT-2 */
if (pcb->state == FIN_WAIT_2) {
/* If this PCB is in FIN_WAIT_2 because of SHUT_WR don't let it time out. */
if (pcb->flags & TF_RXCLOSED) {
/* PCB was fully closed (either through close() or SHUT_RDWR):
normal FIN-WAIT timeout handling. */
if ((u32_t)(tcp_ticks - pcb->tmr) >
TCP_FIN_WAIT_TIMEOUT / TCP_SLOW_INTERVAL) {
++pcb_remove;
}
}
}
/* Check if KEEPALIVE should be sent */
if(ip_get_option(pcb, SOF_KEEPALIVE) &&
((pcb->state == ESTABLISHED) ||
(pcb->state == CLOSE_WAIT))) {
if((u32_t)(tcp_ticks - pcb->tmr) >
(pcb->keep_idle + TCP_KEEP_DUR(pcb)) / TCP_SLOW_INTERVAL)
{
++pcb_remove;
++pcb_reset;
}
else if((u32_t)(tcp_ticks - pcb->tmr) >
(pcb->keep_idle + pcb->keep_cnt_sent * TCP_KEEP_INTVL(pcb))
/ TCP_SLOW_INTERVAL)
{
tcp_keepalive(pcb);
pcb->keep_cnt_sent++;
}
}
/* If this PCB has queued out of sequence data, but has been
inactive for too long, will drop the data (it will eventually
be retransmitted). */
if (pcb->ooseq != NULL &&
(u32_t)tcp_ticks - pcb->tmr >= pcb->rto * TCP_OOSEQ_TIMEOUT) {
tcp_segs_free(pcb->ooseq);
pcb->ooseq = NULL;
}
/* Check if this PCB has stayed too long in SYN-RCVD */
if (pcb->state == SYN_RCVD) {
if ((u32_t)(tcp_ticks - pcb->tmr) >
TCP_SYN_RCVD_TIMEOUT / TCP_SLOW_INTERVAL) {
++pcb_remove;
}
}
/* Check if this PCB has stayed too long in LAST-ACK */
if (pcb->state == LAST_ACK) {
if ((u32_t)(tcp_ticks - pcb->tmr) > 2 * TCP_MSL / TCP_SLOW_INTERVAL) {
++pcb_remove;
}
}
/* If the PCB should be removed, do it. */
if (pcb_remove) {
struct tcp_pcb *pcb2;
tcp_err_fn err_fn;
void *err_arg;
tcp_pcb_purge(pcb);
/* Remove PCB from tcp_active_pcbs list. */
if (prev != NULL) {
prev->next = pcb->next;
} else {
/* This PCB was the first. */
tcp_active_pcbs = pcb->next;
}
if (pcb_reset) {
tcp_rst(pcb->snd_nxt, pcb->rcv_nxt, &pcb->local_ip, &pcb->remote_ip,
pcb->local_port, pcb->remote_port);
}
err_fn = pcb->errf;
err_arg = pcb->callback_arg;
pcb2 = pcb;
pcb = pcb->next;
memp_free(MEMP_TCP_PCB, pcb2);
tcp_active_pcbs_changed = 0;
TCP_EVENT_ERR(err_fn, err_arg, ERR_ABRT);
if (tcp_active_pcbs_changed) {
goto tcp_slowtmr_start;
}
} else {
/* get the 'next' element now and work with 'prev' below (in case of abort) */
prev = pcb;
pcb = pcb->next;
/* We check if we should poll the connection. */
++prev->polltmr;
if (prev->polltmr >= prev->pollinterval) {
prev->polltmr = 0;
tcp_active_pcbs_changed = 0;
TCP_EVENT_POLL(prev, err);
if (tcp_active_pcbs_changed) {
goto tcp_slowtmr_start;
}
/* if err == ERR_ABRT, 'prev' is already deallocated */
if (err == ERR_OK) {
tcp_output(prev);
}
}
}
}
/* Steps through all of the TIME-WAIT PCBs. */
prev = NULL;
pcb = tcp_tw_pcbs;
while (pcb != NULL) {
pcb_remove = 0;
/* Check if this PCB has stayed long enough in TIME-WAIT */
if ((u32_t)(tcp_ticks - pcb->tmr) > 2 * TCP_MSL / TCP_SLOW_INTERVAL) {
++pcb_remove;
}
/* If the PCB should be removed, do it. */
if (pcb_remove) {
struct tcp_pcb *pcb2;
tcp_pcb_purge(pcb);
/* Remove PCB from tcp_tw_pcbs list. */
if (prev != NULL) {
prev->next = pcb->next;
} else {
/* This PCB was the first. */
tcp_tw_pcbs = pcb->next;
}
pcb2 = pcb;
pcb = pcb->next;
memp_free(MEMP_TCP_PCB, pcb2);
} else {
prev = pcb;
pcb = pcb->next;
}
}
}
很容易看出,各个定时器的实现都是通过使用全局变量tcp_ticks与tmr字段的差值来实现的,当TCP进入某个状态时,就会将控制块tmr字段设置为以前的全局时钟tcp_ticks的值,所以上面的差值可以有效表示出TCP处于某个状态的时间。各定时器超时后的处理也很类似,即将变量pcb_remove加1,pcb_remove变量是超时处理中最核心的变量,当针对某个控制块做完超时判断后,函数通过判断pcb_remove的值来处理TCP控制块,当pcb_remove值大于1时,则表示该控制块上有超时事件发生,该控制块或被删除或被挂起。
LwIP中包含两个定时器相关函数:一个是上述周期在500ms的慢速定时器函数tcp_slowtmr,它完成了基本所有TCP需要实现的定时功能;第二个是周期为250ms的快速定时器函数tcp_fasttmr,它完成的一个重要功能是让连接上被延迟的ACK立即发送出去,同时未被成功递交的数据也在这里被递交,tcp_fasttmr的实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp.c
/**
* Is called every TCP_FAST_INTERVAL (250 ms) and process data previously
* "refused" by upper layer (application) and sends delayed ACKs.
*
* Automatically called from tcp_tmr().
*/
void tcp_fasttmr(void)
{
struct tcp_pcb *pcb;
++tcp_timer_ctr;
tcp_fasttmr_start:
pcb = tcp_active_pcbs;
while(pcb != NULL) {
if (pcb->last_timer != tcp_timer_ctr) {
struct tcp_pcb *next;
pcb->last_timer = tcp_timer_ctr;
/* send delayed ACKs */
if (pcb->flags & TF_ACK_DELAY) {
tcp_ack_now(pcb);
tcp_output(pcb);
pcb->flags &= ~(TF_ACK_DELAY | TF_ACK_NOW);
}
next = pcb->next;
/* If there is data which was previously "refused" by upper layer */
if (pcb->refused_data != NULL) {
tcp_active_pcbs_changed = 0;
tcp_process_refused_data(pcb);
if (tcp_active_pcbs_changed) {
/* application callback has changed the pcb list: restart the loop */
goto tcp_fasttmr_start;
}
}
pcb = next;
}
}
}
为了实现TCP的功能,TCP的上述两个定时器函数需要被周期性的调用,在LwIP的实现中,内核需要以250ms为周期调用tcp_tmr,这个函数会自动完成对tcp_slowtmr和tcp_fasttmr的调用。为了便于用户程序的编写,内核已经将tcp_timer以及其他所有定时调用函数封装到了sys_check_timeouts中,因此在没有操作系统模拟层的支持下,应用程序应至少每隔250ms调用sys_check_timeouts一次,以保证内核机制的正常工作。下面给出tcp_timer的实现代码:
// rt-thread\components\net\lwip-1.4.1\src\core\tcp.c
/** Timer counter to handle calling slow-timer from tcp_tmr() */
static u8_t tcp_timer;
/**
* Called periodically to dispatch TCP timers.
*/
void tcp_tmr(void)
{
/* Call tcp_fasttmr() every 250 ms */
tcp_fasttmr();
if (++tcp_timer & 1) {
/* Call tcp_tmr() every 500 ms, i.e., every other timer
tcp_tmr() is called. */
tcp_slowtmr();
}
}
2.5 SYN攻击
SYN洪水攻击是目前被广泛使用的一种基于TCP的DDos攻击技术,通常受攻击的机器是网络中服务固定功能的TCP服务器,由于它们的端口号和IP地址都很容易得到,所以它们很容易成为黑客攻击的对象。这种攻击过程可以用前面介绍的tcp_listen_input的原理来解释:当服务器接收到一个连接请求后,它无法判断客户端的合法性;另一方面,服务器需要为新连接申请一个控制块内存空间,然后向对方返回ACK+SYN报文,并等待对方的握手ACK返回;如果这个连接请求是恶意者发起的,那么服务器永远等不到这个ACK返回(SYN握手报文中的源IP地址是伪造的),服务器必须将这个连接维持足够长的时间后,服务器才能清除它认为无效的连接。
假如网络黑客控制了大量的计算机,并同时向服务器发送SYN请求,则此时服务器将占用大量的内存空间和时间在等待对方的ACK返回上,而显然这种等待都是徒劳的。如果这样的连接达到了很大的数目,系统没有更多的资源来响应新连接,那么正常用户的TCP连接也就无法建立,服务器将无法提供正常的访问服务。TCP协议连接建立握手过程存在的缺陷,注定了网络中的TCP服务器很容易受到SYN攻击。
更多文章
- 《qemu-vexpress-a9 for LwIP stack》
- 《TCP/IP协议栈之LwIP(五)— 网络传输管理之UDP协议》
- 《TCP/IP协议栈之LwIP(七)— 内核定时事件管理》