领域驱动设计
文章目录
- 基本元素
- 导航图
- Entity
- Value Object
- Service
- Aggregate
- Factory
- Repository
- 总结
- 最佳实践
- 限界上下文
- 导航图
- Shared Kernel
- Customer/Supplier
- Conformist(跟随者)
- Anticorruption Layer
- Separate Way
- Open Host Service
- Published Language
基本元素
导航图
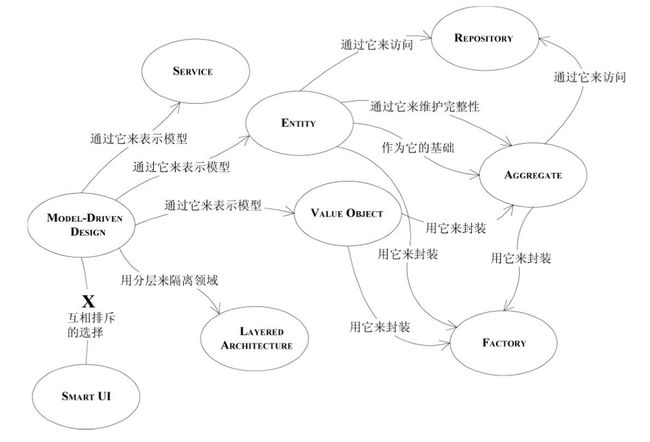
Entity
很多对象不是通过他们的属性定义的,而是通过连续性和标识定义的。
举例:
一个人有一个标识,这个标识会陪伴他走完这一生。他的名字可能改变,财务关系可能改变,没有哪个属性时一生不变的,但标识却是永久的。
连续性:一些对象主要不是由它们的属性定义的,它们实际上表示了一条“标识线”,这条线跨越时间,而且常常经历多种不同的表示。
实体的概念: 一种贯穿整个生命周期(甚至经历多种形式)的抽象的连续性。
标识是Entity的一个微妙的、有意义的属性,我们是不能把它交给语言的自动特性来处理的。(如Java中的==标识符,内存对比)
模型必须定义出符合什么条件才算是相同的事物。
示例:
体育场座位预订,如果每张票都有一个座位号,则座位是Entity;如果票采用入场券的形式,观众可以任意挑选座位,则座位不是Entity。
考虑ID:
有时ID只是内部需要,用户可能永远不需要看到它。比如检索两个同名联系人,用户可以通过地址、公司等属性区分他们。
用户需要看到ID的场景:快递单号。
Value Object
用于描述领域的某个方面而本身没有概念标识的对象称为Value Object。我们只关心它是什么,不关心它是谁。
- Value Object可以是其他对象的集合;
- Value Object可以引用Entity;
- Value Object经常作为参数在对象之间传递信息。
当我们只关心一个模型元素的属性时,应把它归类为Value Object。
我们应该使这个模型元素能够表示出其属性的意义,并为它提供相关功能。
Value Object应当是不可变的。
不要为它分配任何标识,而且不要把它设计成像Entity那么复杂。
Value Object的双向关联没有任何意义,请尽量清除Value Object之间的双向关联。
Service
Service是一系列操作,无状态,通常以动词命名。
所谓Service,它强调的是与其他对象的关系。与Entity和Value Object不同,它只是定义了能够为客户做什么。Service往往是以一个活动来命名,而不是一个Entity来命名,也就是说,它是动词而不是名词。
各层Service的区别:

细粒度的领域对象可能会把领域层的知识泄漏到应用层中。一种解决方法是引入领域层服务。
Service访问:可以用单例模式。
Aggregate
Aggregate(聚合)概念是为了管理领域对象的生命周期而引出的。另外两个所需的概念为:Factory和Repository。
Aggregate通过定义清晰的所属关系和边界,并避免混乱、复杂的对象关系网来实现模型的内聚。在生命周期的开始阶段,使用Factory来创建和重建复杂对象和Aggregate,从而封装它们的内部结构,在生命周期的中间和末尾使用Repository来提供查找持久化对象并封装庞大基础设施的手段。
示例:
假设我们从数据库中删除一个Person对象,这个人的姓名、出生日期和工作描述要一起删除,但如何处理地址呢?可能还有其他人住在同一地址。如果删除了地址,则其他Person对象将会引用一个被删除的对象。如果保留地址,那么垃圾地址在数据库中累积起来。即使数据库提供了一种垃圾处理机制,但一个基本的建模问题依然被忽略了。
定义:
Aggregate是一组相关对象的集合,我们把它作为数据修改的单元。每个Aggregate都有一个根和一个边界。边界定义了Aggregate内部都有什么。根则是Aggregate所包含的一个特定Entity。对Aggregate而言,外部对象只可以引用根么人边界内部的对象之间则可以互相引用。除根以外的其他Entity都有本地标识,但这些标识只在Aggregate内部才需要加以区别,因为外部对象除了根Entity之外看不到其他对象。
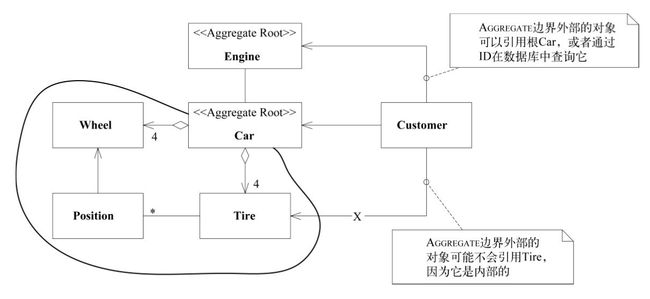
Factory
要求:
- 每个创建方法都是原子的;
- Factory应该被抽象为所需的类型,而不是所要创建的具体类
Factory应该放在什么位置?
- 如果需要向一个已存在的Aggregate添加元素,可以在Aggregate的根上创建一个Factory method。
- 如果要用Factory创建的对象与另一个对象密切相关,比如需要向要创建的对象中传递自己内部的属性,则可以将Factory method放在另一个对象中,即使该对象在关系上不拥有要创建的对象。
- 如果Aggregate内部的某个对象需要一个Factory,而这个Factory又不适合在Aggregate根上创建,那么应该构建一个独立的Factory。
Value Object Factory:
因为Value Object是不可变的,因此Factory操作必须得到被创建对象的完整描述。
Entity Factory:
Entity的标识符可以是用户提供或者自动分配,如果是用户提供的话,必须作为参数显式传递给Factory。
Repository
无论要用对象执行什么操作,都需要保持一个对它的引用。如何获得这个引用呢?
- 创建对象
- 遍历关联
为什么需要Repository?
在所有持久化对象中,有一小部分必须通过基于对象属性的搜索来全局访问。当很难通过遍历方式来访问某些Aggregate根的时候,就需要使用这种访问方式。它们通常是Entity,有时是具有复杂内部结构的Value Object,还可能是枚举Value。而其他对象则不宜使用这种访问方式,因为这会混淆它们之间的重要区别。随意的数据库查询会破坏领域对象的封装和Aggregate。技术基础设施和数据库访问机制的暴露会增加客户的复杂度,并妨碍模型驱动的设计。
定义:
为每种需要全局访问的对象类型创建一个对象(Repository),这个对象相当于该类型的所有对象在内存中的一个集合的“替身”。通过一个众所周知的全局接口来提供访问。通过添加和删除对象的方法,用这些方法来封装在数据存储中实际插入或删除数据的操作。提供根据具体条件来挑选对象的方法,并返回属性值满足查询条件的对象或对象集合,从而将实际的存储和查询技术封装起来。只为那些确实需要直接访问的Aggregate根提供Repository。让客户始终聚焦于模型,而将所有对象的存储和访问操作交给Repository来完成。
Repository中findAll()这种方法谨慎考虑。如果数据库存储的数据很大,findAll()相当于把整个数据库加载到内存,极有可能撑爆内存。
将事务控制权留给客户。尽管Repository会执行数据库的插入和删除操作,但它通常不会提交事务。例如,保存数据后紧接着就提交似乎是很自然的事情,但想必只有客户才有上下文,从而能够正确地初始化和提交工作单元。如果Repository不插手事务控制,那么事务管理就会简单很多。
Factory和Repository的区别:Factory负责制造新对象,而Repository负责查找已有对象。从数据库中查找应该看成是一个对象重建过程,而不是制造新对象,虽然它确实是在实例化对象。Repository应该让客户感觉到那些对象就好像驻留在内存中一样。
总结
领域对象希望类有自己的行为,而不是开放好多setter,让外部的类来控制自己的状态变化。
Entity: stateful, mutable.
Value Object: immutable
Aggregate: Entity和Value Object的集合
Repository: stateless,储存Aggregate
最佳实践
ddd的战术篇: domain object之二
限界上下文
导航图
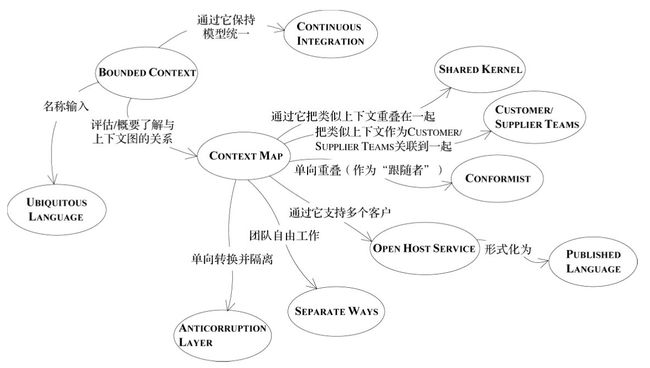
Bound Context不是Module:
每个人使用Module的动机不同,有些人想把它定义为Bound Context,而有些人则仅仅是用它来组织元素,不一定要表达Bound Context的意图,这就产生了歧义,使人们很难发现意外发生的模型分裂。
如何识别Bound Context:
判断两类问题:重复的概念和假同源。
重复的概念:是指两个模型元素以及伴随的实现实际上表示同一个概念,每当这个概念的信息发生变化时,都必须更新两个地方。
假同源:是指使用相同术语的两个人认为他们在谈论同一件事情,但实际并不是这样。比如,图书,在购买系统里表示为作者、价格等信息,而在货运系统里则表示为快递单号、目标地址等信息。
Shared Kernel
为什么需要Shared Kernel:
保持整个模型和代码完全同步的开销可能太高了,但从系统中仔细挑选一部分并保持同步,就能以较小的代价获得较大的利益。
定义:
从领域模型中选出两个团队都同意共享的一个子集。当然,除了这个模型子集以外,还包括了与该模型部分相关的代码子集,或数据库设计子集。这部分明确共享的内容具有特殊地位,一个团队在没与另一个团队商量的情况下不应擅自修改它。
Shared Kernel目的是减少重复。
Customer/Supplier
在上下游系统中,上游和下游子系统很自然地分隔到两个不同的Bound Context中。如果两个组件需要不同的技能或工具集来实现时,更需要把它们隔离到不同的上下文中。转换很容易,因为只需要进行单向转换。
| 上游 | 下游 |
|---|---|
| 供应商 | 客户 |
Conformist(跟随者)
为什么需要Confirmist:
有时使用上游软件具有非常大的价值,并且这个软件的接口很大,不易自主开发。同时,上游软件具有良好的设计风格。(如果设计很差,那就不要跟随了,使用防腐层)
定义:
通过严格遵从上游团队的模型,可以消除在Bound Context之间转换的复杂性。(什么叫遵从呢?就好比使用pandas库,它是上游软件,其中有个DataFrame模型,我们直接使用该模型来实现应用程序的功能,这就叫遵从)
注意与Shared Kernel的区别:
两者均有共享模型,但Conformist模式中的模型是另一个团队直接给的,而不是由两个团队共同制定维护的。
Anticorruption Layer
为什么需要Anticorruption Layer:
当正在构建的新系统与另一个系统的接口很大时,为了克服连接两个模型的困难,亦或是另一个系统的模型不符合当前项目的需要时,有必要使用Anticorruption Layer。
定义:
创建一个隔离层,以便根据客户自己的领域模型来为客户提供相关功能。这个层通过另一个系统现有接口与其对话,而只需对那个系统做出很少的修改,甚至无需修改。在内部,这个层在两个模型之间进行必要的双向转换。
区别于协议:
Anticorruption Layer不是如http协议等这种向另一个系统发送消息的机制。它是在不同模型和协议之间转换概念对象和操作的机制。
Anticorruption Layer通常以Service的形式出现,偶尔是Entity。
可以是实现为Facade、Adapter和Translator的组合,外加两个系统之间进行对话所需的通信和传输机制。
Separate Way
为什么需要Separate Way:
集成总是代价高昂,而有时又获益很小。Separate Way(各行其道)反而能够简化开发。
定义:
声明一个与其他上下文毫无关联的Bound Context,使开发人员能够在这个小范围内找到简单的、专用的解决方案。
Open Host Service
为什么需要Open Host Service:
一般来说,在Bound Context中工作时,我们会为Context外部的每个需要集成的组件定义一个转换层。当子系统要与很多系统集成时,为每个集成定制一个转换层可能会减慢团队的工作速度。
定义:
定义一个协议,把你的子系统作为一组Service供其他系统访问。开放这个协议,以便所有需要与你子系统集成的人都可以使用它。(Restful API就是一种Open Host Service)
Published Language
为什么需要Published Language:
两个Context之间的模型转换需要一种公共的语言。与现有领域模型进行直接的转换可能不是一种好的解决方案。这些模型可能过于复杂或设计的较差,它们可能没有被很好地文档化,如果其中一个模型作为数据交换语言,它实质上就被固定住了,而无法满足新的开发需求。
定义:
把一个良好文档化的、能够表达出所需领域信息的共享语言作为公共的通信媒介,必要时在其他信息与该语言之间进行转换。(说白了就是使用协议,可以是json、xml等已经存在的或者是自己定义的)