使用Nsight如何实现核函数的递归或者嵌套
实现cuda+ubuntu+nsight+动态并行,需要实现核函数的嵌套或者递归。
第一种方式使用命令行NVCC编译:
nvcc 111.cu -rdc=true -arch=sm_52只要-rdc=true 就可以了;
第二钟方式,在NSight:
在新建工程的时候需要打开

要不然会报错。
例如:我需要这么一行代码
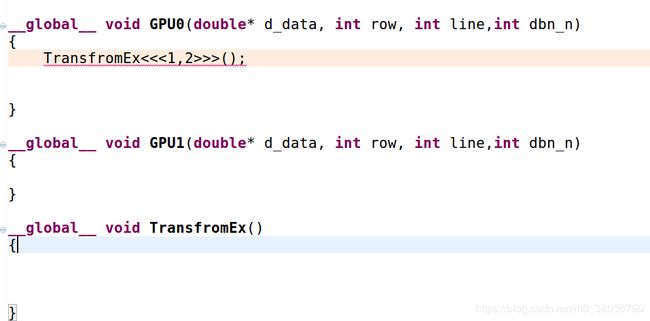
核函数中需要嵌套一个核函数,实现动态并行。
编译器会报错
../src/deviceGpu.cu(5): error: kernel launch from __device__ or __global__ functions requires separate compilation mode
1 error detected in the compilation of "/tmp/tmpxft_00003c34_00000000-6_deviceGpu.cpp1.ii".
make: *** [src/deviceGpu.o] Error 1
src/subdir.mk:33: recipe for target 'src/deviceGpu.o' failed
解决办法就是打开
这个选项。
在什么位置哪?
右击项目-》属性-》build-》settings-》cuda

勾选,保存,编译没得问题了。完美解决,据说需要sm>2.0因为我的GPUsm是5.2的。没有报错,2.0的太老了,似乎NVIDIA公司已经不支持了。
------------------------------------分割线2019.5.20-----------------------------------------------------------------------------------------------------
补充一点:
关于__global__和__device__函数的用法(自己总结的可能不太全面)
关于__global__ 可以被__global__调用无返回值,但是必须有三个尖括号

必须是这样的。
![]()
这样会报错的。
而__device__以这个开头的是不需要尖括号的。
![]()
这样完全可以编译成功的。
来一个例子:
#include
#include
#include
//#include
__global__ void sam(double* d_sam,double* d_max,double* d_sum,int n)
{
double temp = 0;
int iidx = threadIdx.x;
for(int i = 0; i < 4;++i)
{
temp += d_sam[n * 8 + iidx + i] * d_max[i];
}
d_sum[n * 5 + iidx] = temp;
}
__global__ void gpu(double* d_sam,double* d_max,double* d_sum)
{
int idx = threadIdx.x;
switch(idx)
{
case 0:
printf("case 0: = %d\n",idx);
sam<<<1,5>>>(d_sam,d_max,d_sum,idx);
__syncthreads();
break;
case 1:
printf("case 0: = %d\n",idx);
sam<<<1,5>>>(d_sam,d_max,d_sum,idx);
__syncthreads();
break;
case 2:
printf("case 0: = %d\n",idx);
sam<<<1,5>>>(d_sam,d_max,d_sum,idx);
__syncthreads();
break;
case 3:
printf("case 0: = %d\n",idx);
sam<<<1,5>>>(d_sam,d_max,d_sum,idx);
__syncthreads();
break;
}
}
int main()
{
double* max = new double[4];
double* samData = new double[4*8];
double* sum = new double[4 * 5];
double *d_sam,*d_max,*d_sum;
cudaMalloc((void**)&d_sam,4 * 8 * sizeof(double));
cudaMalloc((void**)&d_max,4 * sizeof(double));
cudaMalloc((void**)&d_sum,4 * 5 * sizeof(double));
for(int i = 0; i < 4; ++i)
{
for(int j = 0; j < 8; ++j)
{
samData[i * 8 + j] = i * 8 + j + 1;
std::cout << "samData = " << samData[i * 8 + j] << " ";
}
std::cout << std::endl;
}
for(int i = 0; i < 4; ++i)
{
max[i] = i + 1;
std::cout << "max = " << max[i] << " ";
}
std::cout << std::endl;
cudaMemcpy(d_sam,samData,4 * 8 * sizeof(double),cudaMemcpyHostToDevice);
cudaMemcpy(d_max,max,4 * sizeof(double),cudaMemcpyHostToDevice);
gpu<<<1,4>>>(d_sam,d_max,d_sum);
cudaMemcpy(sum,d_sum,4 * 5 * sizeof(double),cudaMemcpyDeviceToHost);
for(int i = 0; i < 4; ++i)
{
for(int j = 0; j < 5; ++j)
{
std::cout << "sum[" << i << "][" << j <<"]= " << sum[i * 5 + j] << " ";
}
std::cout << std::endl;
}
std::cout << std::endl;
return 0;
}

执行结果:
解释一下:
数据是一个4*8的矩阵.要和一个1*4的数据做卷积和.做的是行向量卷积,得出的结果是一个4*5的矩阵.
什么意思那?

---------------------------2019.6.8-----------------------------------------------------------------------------
在这个全国高考的日子里,更新一个小问题,关于核函数递归的问题,会遇到二层核函数不启动的问题

比如这个核函数嵌套一个核函数,有时候核函数里面的核函数不启动,我遇到过这类问题,一般的就是<<
--------------------------------------2019.0818-----------------------------------
更新一点,想要核函数嵌套实现,必须都是__global__开头的才可以的,__device__开头是不可以的.实际操作得出.
例如:
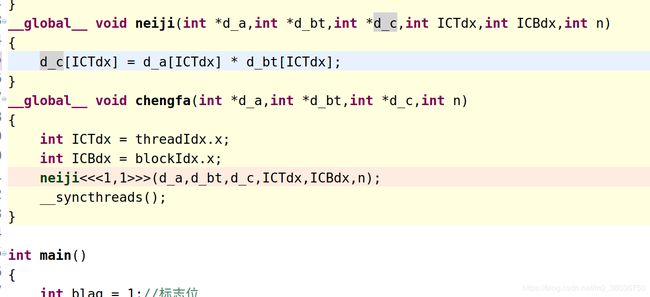
neiji()这个函数必须是__global__ void neiji();这种形式才可以的.__device__ void neiji()是编译不过去的,具体原理不太清楚.有明白的大佬可以留言讨论.
总结一下:
__global__ 开头的核函数是可以实现嵌套并行的.
__device__开头的也是可以嵌套的,但是不可以再开线程了.