DOTA数据集 | 数据预处理操作系列(持续更新)
文章目录
- 一、把DOTA数据集进行切割,生成600*600大小的图片和xml文件(hbb和obb都ok!)
- 二、在切割后图片中,进行统计各个类别的目标数量
- 三、分割后的图片中,统计各个类别的图片数量及xml文件
- 四、从预测结果图中找出某个类别的图片
- 五、读DOTA数据集的xml文件,得到每个对象的类别以及每个框的坐标,并存到tmp1.txt
- 六、读取检测生成的pkl文件
- 七、将DOTA数据集格式转成VOC格式
一、把DOTA数据集进行切割,生成600*600大小的图片和xml文件(hbb和obb都ok!)
更新2020.6.27
tarin_crop.py
import os
import scipy.misc as misc
from xml.dom.minidom import Document
import numpy as np
import copy, cv2
def save_to_xml(save_path, im_width, im_height, objects_axis, label_name, name, hbb=True):
im_depth = 0
object_num = len(objects_axis)
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('VOC2007')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filename = doc.createElement('filename')
filename_name = doc.createTextNode(name)
filename.appendChild(filename_name)
annotation.appendChild(filename)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('The VOC2007 Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('322409915'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('knautia'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('yang'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(im_width)))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(im_height)))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(im_depth)))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(object_num):
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode(label_name[int(objects_axis[i][-1])]))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('1'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
if hbb:
x0 = doc.createElement('xmin')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('ymin')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('xmax')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('ymax')
y1.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y1)
else:
x0 = doc.createElement('x0')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('y0')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('x1')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('y1')
y1.appendChild(doc.createTextNode(str((objects_axis[i][3]))))
bndbox.appendChild(y1)
x2 = doc.createElement('x2')
x2.appendChild(doc.createTextNode(str((objects_axis[i][4]))))
bndbox.appendChild(x2)
y2 = doc.createElement('y2')
y2.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y2)
x3 = doc.createElement('x3')
x3.appendChild(doc.createTextNode(str((objects_axis[i][6]))))
bndbox.appendChild(x3)
y3 = doc.createElement('y3')
y3.appendChild(doc.createTextNode(str((objects_axis[i][7]))))
bndbox.appendChild(y3)
f = open(save_path,'w')
f.write(doc.toprettyxml(indent = ''))
f.close()
class_list = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship',
'tennis-court', 'basketball-court',
'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor',
'swimming-pool', 'helicopter']
def format_label(txt_list):
format_data = []
for i in txt_list[2:]:
format_data.append(
[int(xy) for xy in i.split(' ')[:8]] + [class_list.index(i.split(' ')[8])]
# {'x0': int(i.split(' ')[0]),
# 'x1': int(i.split(' ')[2]),
# 'x2': int(i.split(' ')[4]),
# 'x3': int(i.split(' ')[6]),
# 'y1': int(i.split(' ')[1]),
# 'y2': int(i.split(' ')[3]),
# 'y3': int(i.split(' ')[5]),
# 'y4': int(i.split(' ')[7]),
# 'class': class_list.index(i.split(' ')[8]) if i.split(' ')[8] in class_list else 0,
# 'difficulty': int(i.split(' ')[9])}
)
if i.split(' ')[8] not in class_list :
print ('warning found a new label :', i.split(' ')[8])
exit()
return np.array(format_data)
def clip_image(file_idx, image, boxes_all, width, height):
# print ('image shape', image.shape)
if len(boxes_all) > 0:
shape = image.shape
for start_h in range(0, shape[0], 256):
for start_w in range(0, shape[1], 256):
boxes = copy.deepcopy(boxes_all)
box = np.zeros_like(boxes_all)
start_h_new = start_h
start_w_new = start_w
if start_h + height > shape[0]:
start_h_new = shape[0] - height
if start_w + width > shape[1]:
start_w_new = shape[1] - width
top_left_row = max(start_h_new, 0)
top_left_col = max(start_w_new, 0)
bottom_right_row = min(start_h + height, shape[0])
bottom_right_col = min(start_w + width, shape[1])
subImage = image[top_left_row:bottom_right_row, top_left_col: bottom_right_col]
box[:, 0] = boxes[:, 0] - top_left_col
box[:, 2] = boxes[:, 2] - top_left_col
box[:, 4] = boxes[:, 4] - top_left_col
box[:, 6] = boxes[:, 6] - top_left_col
box[:, 1] = boxes[:, 1] - top_left_row
box[:, 3] = boxes[:, 3] - top_left_row
box[:, 5] = boxes[:, 5] - top_left_row
box[:, 7] = boxes[:, 7] - top_left_row
box[:, 8] = boxes[:, 8]
center_y = 0.25*(box[:, 1] + box[:, 3] + box[:, 5] + box[:, 7])
center_x = 0.25*(box[:, 0] + box[:, 2] + box[:, 4] + box[:, 6])
# print('center_y', center_y)
# print('center_x', center_x)
# print ('boxes', boxes)
# print ('boxes_all', boxes_all)
# print ('top_left_col', top_left_col, 'top_left_row', top_left_row)
cond1 = np.intersect1d(np.where(center_y[:]>=0 )[0], np.where(center_x[:]>=0 )[0])
cond2 = np.intersect1d(np.where(center_y[:] <= (bottom_right_row - top_left_row))[0],
np.where(center_x[:] <= (bottom_right_col - top_left_col))[0])
idx = np.intersect1d(cond1, cond2)
# idx = np.where(center_y[:]>=0 and center_x[:]>=0 and center_y[:] <= (bottom_right_row - top_left_row) and center_x[:] <= (bottom_right_col - top_left_col))[0]
# save_path, im_width, im_height, objects_axis, label_name
if len(idx) > 0:
name="%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col)
print(name)
xml = os.path.join(save_dir, 'labeltxt', "%s_%04d_%04d.xml" % (file_idx, top_left_row, top_left_col))
save_to_xml(xml, subImage.shape[1], subImage.shape[0], box[idx, :], class_list, str(name))
# print ('save xml : ', xml)
if subImage.shape[0] > 5 and subImage.shape[1] >5:
img = os.path.join(save_dir, 'images', "%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col))
cv2.imwrite(img, subImage)
print ('class_list', len(class_list))
raw_data = 'D:/datasets/DOTA/train/'
raw_images_dir = os.path.join(raw_data, 'images')
raw_label_dir = os.path.join(raw_data, 'labelTxt')
save_dir = 'D:/datasets/DOTA_clip/train/'
images = [i for i in os.listdir(raw_images_dir) if 'png' in i]
labels = [i for i in os.listdir(raw_label_dir) if 'txt' in i]
print ('find image', len(images))
print ('find label', len(labels))
min_length = 1e10
max_length = 1
for idx, img in enumerate(images):
# img = 'P1524.png'
print (idx, 'read image', img)
img_data = misc.imread(os.path.join(raw_images_dir, img))
# if len(img_data.shape) == 2:
# img_data = img_data[:, :, np.newaxis]
# print ('find gray image')
txt_data = open(os.path.join(raw_label_dir, img.replace('png', 'txt')), 'r').readlines()
# print (idx, len(format_label(txt_data)), img_data.shape)
# if max(img_data.shape[:2]) > max_length:
# max_length = max(img_data.shape[:2])
# if min(img_data.shape[:2]) < min_length:
# min_length = min(img_data.shape[:2])
# if idx % 50 ==0:
# print (idx, len(format_label(txt_data)), img_data.shape)
# print (idx, 'min_length', min_length, 'max_length', max_length)
box = format_label(txt_data)
clip_image(img.strip('.png'), img_data, box, 600, 600)
# rm train/images/* && rm train/labeltxt/*

二、在切割后图片中,进行统计各个类别的目标数量
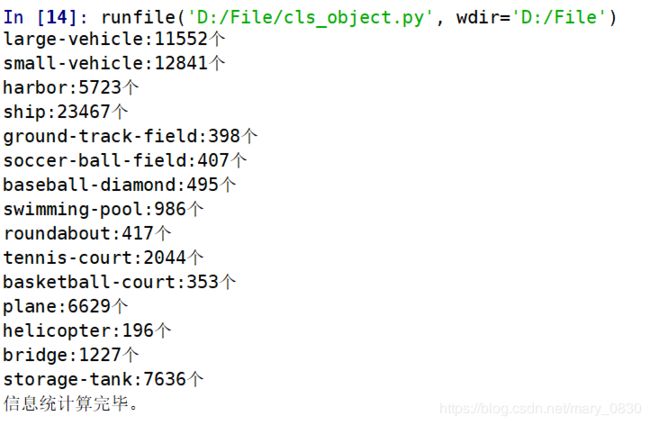
cls_object.py
# -*- coding: utf-8 -*-
# -*- coding:utf-8 -*-
#根据xml文件统计目标种类以及数量
import os
import xml.etree.ElementTree as ET
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree=ET.parse(xml_path+filename)
objects=[]
for obj in tree.findall('object'):
obj_struct={}
obj_struct['name']=obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im=Image.open(image_path+filename)
W=im.size[0]
H=im.size[1]
area=W*H
im_info=[W,H,area]
return im_info
if __name__ == '__main__':
xml_path='D:/datasets/DOTA_clip/val/labeltxt/'
filenamess=os.listdir(xml_path)
filenames=[]
for name in filenamess:
name=name.replace('.xml','')
filenames.append(name)
recs={}
obs_shape={}
classnames=[]
num_objs={}
obj_avg={}
for i,name in enumerate(filenames):
recs[name]=parse_obj(xml_path, name+ '.xml' )
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']]=1
else:
num_objs[object['name']]+=1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}个'.format(name,num_objs[name]))
print('信息统计算完毕。')
三、分割后的图片中,统计各个类别的图片数量及xml文件
cls_get.py
# -*- coding: utf-8 -*-
import os
import os.path
import shutil
# 修改文件的xml和img图片的位置
fileDir_ann = r'D:/datasets/DOTA_clip/val/labeltxt/'
fileDir_img = r'D:/datasets/DOTA_clip/val/images/'
#存放包含需要的类的图片
saveDir_img = r'D:/datasets/DOTA_clip/helicopter/val/images'
if not os.path.exists(saveDir_img):
os.mkdir(saveDir_img)
names = locals()
for files in os.walk(fileDir_ann):
#遍历Annotations中的所有文件
for file in files[2]:
print (file + "-->start!")
#存放包含需要的类的图片对应的xml文件
saveDir_ann = r'D:/datasets/DOTA_clip/helicopter/val/annotations/'
if not os.path.exists(saveDir_ann):
os.mkdir(saveDir_ann)
fp = open(fileDir_ann + file)
saveDir_ann = saveDir_ann + file
fp_w = open(saveDir_ann, 'w')
# 修改为自己数据集的类别
classes = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship',
'tennis-court', 'basketball-court',
'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor',
'swimming-pool', 'helicopter']
lines = fp.readlines()
#记录所有的\t
ind_start = []
#记录所有的\t\n的位置
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
# 根据xml文件中的格式进行修改
while " in lines_id_start:
a = lines_id_start.index(")
ind_start.append(a)
lines_id_start[a] = "delete"
while "\n" in lines_id_end:
b = lines_id_end.index("\n")
ind_end.append(b)
lines_id_end[b] = "delete"
for k in range(0,len(ind_start)):
for j in range(0,len(classes)):
if classes[j] in lines[ind_start[k]+1]:
a = ind_start[k]
names['block%d'%k] = lines[a:ind_end[k]+1]
break
# 修改为自己所需要的类别,可以创建多个类别
# 根据xml格式进行修改
classes1 = 'large-vehicle \n'
string_start = lines[0:ind_start[0]]
print(string_start)
string_end = lines[ind_end[-1] + 1:]
a = 0
for k in range(0,len(ind_start)):
if classes1 in names['block%d'%k]:
a += 1
string_start += names['block%d'%k]
string_start += string_end
for c in range(0,len(string_start)):
fp_w.write(string_start[c])
fp_w.close()
if a == 0:
os.remove(saveDir_ann)
else:
# 。png或者是.jpg文件,根据自己的格式进行修改
name_img = fileDir_img + os.path.splitext(file)[0] + ".png"
shutil.copy(name_img,saveDir_img)
fp.close()
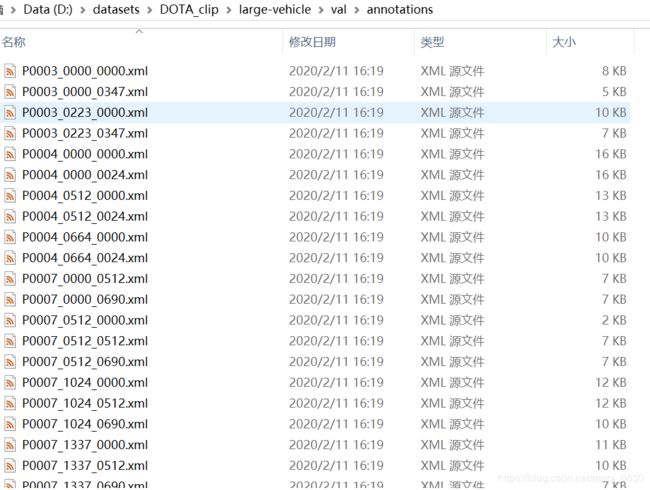
下面是检测大型汽车的结果:
四、从预测结果图中找出某个类别的图片
find_same_name.py
下面的代码是找出桥梁的图片。
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
# !/usr/bin/env python
import shutil
import os
import glob
from PIL import Image
import re
#指定找到文件后,另存为的文件夹绝对路径
outDir = os.path.abspath('D:/datasets/output')
#指定第一个文件夹的位置
imageDir1 = os.path.abspath('D:/datasets/DOTA_clip/bridge/val/images')
#定义要处理的第一个文件夹变量
image1 = [] #image1指文件夹里的文件,包括文件后缀格式;
imgname1 = [] #imgname1指里面的文件名称,不包括文件后缀格式
#通过glob.glob来获取第一个文件夹下,所有'.png'文件
imageList1 = glob.glob(os.path.join(imageDir1, '*.png'))
#遍历所有文件,获取文件名称(包括后缀)
for item in imageList1:
image1.append(os.path.basename(item))
#遍历文件名称,去除后缀,只保留名称
for item in image1:
(temp1, temp2) = os.path.splitext(item)
imgname1.append(temp1)
#对于第二个文件夹绝对路径,做同样的操作
imageDir2 = os.path.abspath('D:/datasets/R2CNN_20180922_DOTA_v28/R2CNN_20180922_DOTA_v28')
image2 = []
imgname2 = []
imageList2 = glob.glob(os.path.join(imageDir2, '*.jpg'))
for item in imageList2:
image2.append(os.path.basename(item))
for item in image2:
(temp1, temp2) = os.path.splitext(item)
temp3 = temp1[0:15] # 取前15位字符
imgname2.append(temp3)
#通过遍历,获取第一个文件夹下,文件名称(不包括后缀)与第二个文件夹相同的文件,
#并另存在outDir文件夹下。文件名称与第一个文件夹里的文件相同,后缀格式亦保持不变。
List = []
for item1 in imgname1:
for item2 in imgname2:
if item1 == item2:
temp = item1
List.append(temp)
# print(List)
# print(temp)
# 如何在两个列表中,取出第二个列表对应的第一个列表的元素 .
#1,先根据数字在第二个列表的位置找第一个列表的数
#2,再根据第一个列表数字位置找第二个
print(List)
for i in List:
# 字符串前加上f可以使得{}里的变量不被转换成字符串
old_path0 = f'D:/datasets/R2CNN_20180922_DOTA_v28/R2CNN_20180922_DOTA_v28/{i}_r.jpg'
old_path1 = f'D:/datasets/R2CNN_20180922_DOTA_v28/R2CNN_20180922_DOTA_v28/{i}_h.jpg'
new_path0 = f'D:/datasets/output/bridge/{i}_r.jpg'
new_path1 = f'D:/datasets/output/bridge/{i}_h.jpg'
shutil.copy2(old_path0, new_path0); shutil.copy2(old_path1, new_path1)
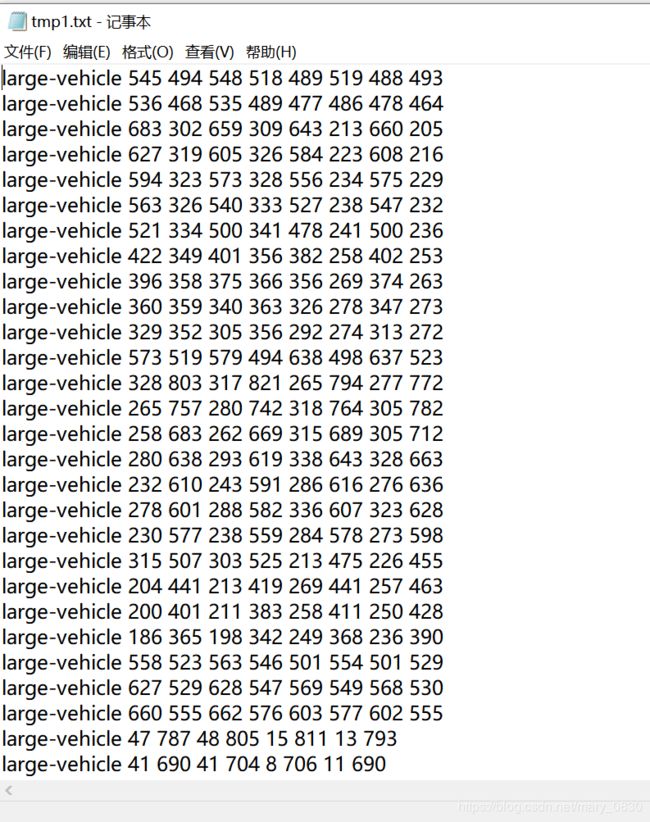
五、读DOTA数据集的xml文件,得到每个对象的类别以及每个框的坐标,并存到tmp1.txt
get_cls_and_xy.py
以下介绍两种获取对象类别和坐标的方法,分别使用xml元素树和切分的方法,供大家使用。
# -*- coding: utf-8 -*-
# 方法一:用元素树的方法
# 读xml文件中的一个rect
import xml.etree.ElementTree as ET
import sys
import numpy as np
#import importlib
#importlib.reload(sys)
#sys.setdefaultencoding('utf-8')
xml_path="D:/datasets/DOTA_clip/val/labeltxt/P0003_0000_0000.xml"
root = ET.parse(xml_path).getroot() #获取元素树的根节点
rect={}
objects=[]
line=[]
for name in root.iter('name'):
rect['name'] = name.text
for ob in root.iter('object'):
for bndbox in ob.iter('bndbox'):
for x0 in bndbox.iter('x0'):
rect['x0'] = x0.text
for y0 in bndbox.iter('y0'):
rect['y0'] = y0.text
for x1 in bndbox.iter('x1'):
rect['x1'] = x1.text
for y1 in bndbox.iter('y1'):
rect['y1'] = y1.text
for x2 in bndbox.iter('x2'):
rect['x2'] = x2.text
for y2 in bndbox.iter('y2'):
rect['y2'] = y2.text
for x3 in bndbox.iter('x3'):
rect['x3'] = x3.text
for y3 in bndbox.iter('y3'):
rect['y3'] = y3.text
line = rect['name'] + " "+ rect['x0']+ " "+rect['y0']+" "+rect['x1']+" "+rect['y1']+" "+rect['x2']+" "+rect['y2']+" "+rect['x3']+" "+rect['y3']
# print(line)
objects.append(line)
print(objects)
# f1 = open('D:/datasets/output/tmp1.txt', 'w')
np.savetxt('D:/datasets/output/tmp1.txt', objects, fmt = '%s')
# --------------------------------------------------------------------------
# 方法二:split切分的方法
#import re
#
#xml_path="D:/datasets/DOTA_clip/val/labeltxt/P0003_0000_0000.xml"
#
#text = open(xml_path, 'r').read().split('\n')[20:-2]
#
#for i in range(0, len(text)-1, 16):
# name = text[i+1].split('>')[1].split('<')[0]
# x0 = text[i+6].split('>')[1].split('<')[0]
# y0 = text[i+7].split('>')[1].split('<')[0]
# x1 = text[i+8].split('>')[1].split('<')[0]
# y1 = text[i+9].split('>')[1].split('<')[0]
# x2 = text[i+10].split('>')[1].split('<')[0]
# y2 = text[i+11].split('>')[1].split('<')[0]
# x3 = text[i+12].split('>')[1].split('<')[0]
# y3 = text[i+13].split('>')[1].split('<')[0]
# output = f'{name} {x0} {y0} {x1} {y1} {x2} {y2} {x3} {y3}'
# print(output)
推荐这个元素树使用详解链接,个人认为讲得很好!
六、读取检测生成的pkl文件
read_pkl.py
# -*- coding: utf-8 -*-
import pickle, pprint
pkl_file = open(r'D:/datasets/R2CNN_20180922_DOTA_v28/R2CNN_20180922_DOTA_v28_detections_r.pkl', 'rb')
data = pickle.load(pkl_file, encoding='bytes')
pprint.pprint(data)
pkl_file.close()