DOTA数据集 | YOLOv3 实现训练、测试
YOLOv3 跑 DOTA数据集
- 源码链接
- 运行环境
- 需要下载文件
- 训练步骤
源码链接
https://github.com/xiaomogui/DOTA-yolov3
运行环境
- Ubuntu16.04
- python3
- CUDA 10.1 ( NVIDIA-SMI 418.39 Driver Version: 418.39 )
- opencv-python 等工具包
- Shapely (need geos|需要安装geos)
需要下载文件
-
预训练的参数:
百度云 链接: https://pan.baidu.com/s/1V6fxrUpHLhukiJ-vT0F0pQ 提取码: pfq6
google drive: https://drive.google.com/drive/folders/1Y-W2npeaqflfO8IUA7gx9PzmesaSl9rY?usp=sharing -
DOTA数据集:https://captain-whu.github.io/DOTA/dataset.html
-
下载darknet:https://pjreddie.com/darknet/install/
注意:
下载darknet后,cd darknet —>vim Makefile ,修改Makefile文件内容:
GPU=1
CUDNN=1
OPENCV=0
NVCC=/usr/local/cuda-10.1/bin/nvcc # 根据自己CUDA版本修改
训练步骤
- 下载该仓库:
git clone https://github.com/xiaomogui/DOTA-yolov3.git - 进入到该文件夹下:
cd DOTA-yolov3 - 然后按如下结构存放 :
DOTA-yolov3
|
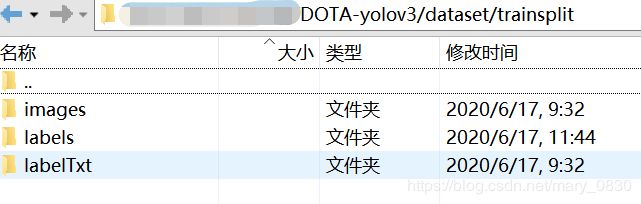
├─dataset
│ ├─train
│ │ ├─images
│ │ └─labelTxt
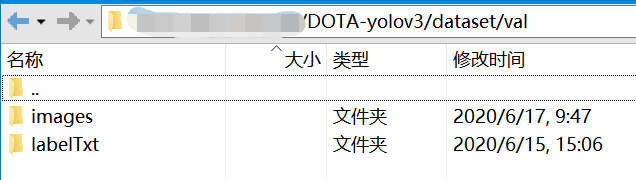
│ └─val
│ ├─images
│ └─labelTxt

4. 切割数据集:python3 data_transform/split.py
5. 转换label :
mkdir dataset/trainsplit/labels
mkdir dataset/valsplit/labels
python3 data_transform/YOLO_Transform.py
# check labels
# cd dataset/trainsplit/labels
# awk -F" " '{col[$1]++} END {for (i in col) print i, col[i]}' *.txt
6. 生成 train.txt & val.txt :
ls -1d $PWD/dataset/trainsplit/images/* > cfg/train.txt
ls -1d $PWD/dataset/valsplit/images/* > cfg/val.txt
# when too many images
# find "$(pwd)/dataset/trainsplit512/images">cfg/train.txt
# find "$(pwd)/dataset/valsplit512/images">cfg/val.txt

7. 训练:
cd cfg
mkdir backup
# yolo-tiny
darknet detector train dota.data dota-yolov3-tiny.cfg
# more gpus
darknet detector train dota.data dota-yolov3-tiny.cfg -gpus 0,1,2
# resume from unexpected stop
darknet detector train dota.data dota-yolov3-tiny.cfg backup/dota-yolov3-tiny.backup
# or yolov3-416
darknet detector train dota.data dota-yolov3-416.cfg
以上是作者提供的运行命令。
下面是笔者运行命令。
./darknet detector train ./cfg/dota.data ./cfg/dota-yolov3-tiny.cfg ./backup/dota-yolov3-tiny_30000.weights -gpus 0,1
注意,笔者根据原作者的步骤不能运行成功,因此修改了一些步骤。
- 在原目录下 cfg/下存入darknet
- …/cfg/darknet/cfg中重新存入
- 将train.txt和val.txt放在如下图所示的文件夹下:

在DOTA-yolov3/cfg/darknet的目录下,运行./darknet detector train ./cfg/dota.data ./cfg/dota-yolov3-tiny.cfg ./backup/dota-yolov3-tiny_30000.weights -gpus 0,1即可使代码跑起来。
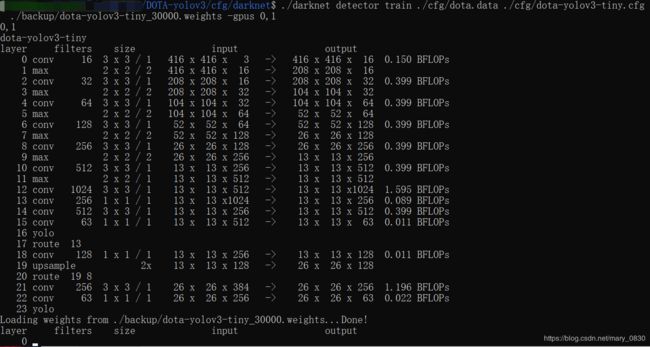
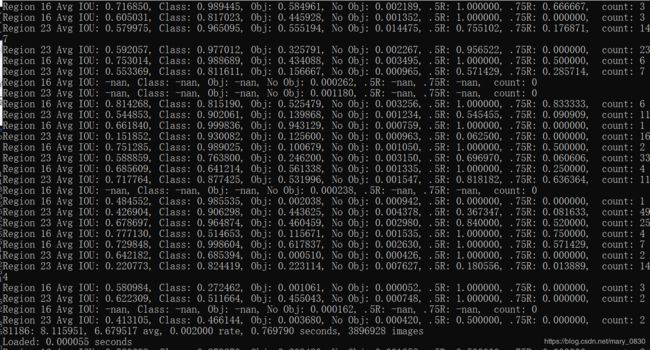
参数说明:
Region 16 Avg IOU: 0.703332, Class: 0.894307, Obj: 0.383686, No Obj: 0.000546, .5R: 1.000000, .75R: 0.333333, count: 3
Region 23 Avg IOU: 0.266371, Class: 0.987170, Obj: 0.062990, No Obj: 0.000677, .5R: 0.100000, .75R: 0.000000, count: 10
Region 16 Avg IOU: 0.774730, Class: 0.999647, Obj: 0.592616, No Obj: 0.000410, .5R: 1.000000, .75R: 1.000000, count: 1
以上输出显示了所有训练图片的一个批次(batch),批次大小的划分根据在 .cfg 文件(dota-yolov3-tiny.cfg)中设置的subdivisions参数。
使用的 .cfg 文件中 batch = 24 ,subdivision = 8,所以在训练输出中,训练迭代包含了8组,每组又包含了3张图片,跟设定的batch和subdivision的值一致。
以上信息表示两个不同尺度(16,23)上预测到的不同大小的框的参数。
- 16卷积层为最大的预测尺度,使用较大的 mask,但是可以预测出较小的物体。
- 23卷积层为最小的预测尺度,使用较小的 mask,可以预测出较大的物体。
- Region Avg IOU: 0.703332:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1。
- Class: 0.894307: 标注物体的分类准确率,越大越好,期望数值为1。
- Obj: 0.383686: 越大越好,期望数值为1。
- No Obj: 0.000546: 期望该值越来越小, 但不为零。
- .5R: 1.000000: 以IOU=0.5为阈值时候的recall。recall = 检出的正样本/实际的正样本
- .75R: 0.333333:以IOU=0.75为阈值时候的recall。
- count: 4:正样本数目。
每个batch都会有这样一个输出:
81035: 4.439195, 7.309046 avg, 0.002000 rate, 1.153535 seconds, 3889680 images Loaded: 0.000055 seconds
- 81035:batch是第几组。
- 4.439195:总损失。
- 7.309046 avg : 平均损失。
- 0.002000 rate:当前的学习率。
- 1.153535 seconds: 当前batch训练所花的时间。
- 3889680 images : 目前为止参与训练的图片总数。
- 预测图片:为了方便运行,这里用 opnencv做检测,要高性能还是用 darknent binding | Here I prepared opencv for easy set up, you can use darknet bindings for better performance
# tiny
python test.py --image test.png --config cfg/dota-yolov3-tiny.cfg --weights cfg/backup/dota-yolov3-tiny_final.weights --classes cfg/dota.names
# or 416
python test.py --image test.png --config cfg/dota-yolov3-416.cfg --weights cfg/backup/dota-yolov3-416_final.weights --classes cfg/dota.names
测试结果:

参考博客:
https://blog.csdn.net/qq_29377279/article/details/83141239
https://blog.csdn.net/xiaotian127/article/details/104741658
https://blog.csdn.net/cxxxxxxxxxxxxx/article/details/106481976
https://blog.csdn.net/weixin_42447868/article/details/106480845