XGBoost解析系列-原理
- 前言
- Boosting算法框架
- XGBoost原理推导
- XGBoost算法
- XGBoost工程优化
- XGBoost算法复杂度
- 参考资料
0.前言
解析源码之前,还是介绍说明下XGBoost原理,网上对于XGBoost原理已有各种版本的解读。而这篇博客,笔者主要想根据自己的理解,梳理看过的XGBoost资料,包括陈天奇的论文以及引用论文内容,本文主要内容基于陈天奇的论文与PPT,希望能够做到系统地介绍XGBoost,同时加入源码新特性让内容上有增量。
XGBoost不仅能在单机上通过OMP实现高度并行化,还能通过MPI接口与近似分位点算法(论文中是weighted quantiles sketch)实现高效的分布式并行化。其中近似分位点算法(approximate quantiles)会附加一篇博客进行详细说明,分位点算法在分布式系统、流式系统中真的是个很天才的想法,很多分布式算法的基石。最早由M.Greenwald和S. Khanna与2001年提出的GK Summay算法,直到到2007年被Q. Zhang和W. Wang提出的多层level的merge与compress/prune框架进行高度优化,而被称为A fast algorithm for approximate quantiles,详情见下一篇博客。
1.Boosting算法框架
XGBoost算法属于集成学习中的boosting分支,其算法框架遵循1999年Friedman提出的boosting框架,该分支还有GBDT(Gradient Boosting Decision Tree),boosting集成是后一个模型是对前一个模型产生误差信息进行矫正。gradient boost更具体,新模型的引入是为了减少上个模型的残差(residual),我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。Friedman论文中针对回归过程提出boost框架如下:

Friedman提出boost算法框架过程描述如下:
1. 设定函数初始值 F0 ,为一个恒值函数,论文中基于变量优化出恒值,实际上也可以给定任意值或者直接为0。
2. 根据参数 M ,进行 M 次迭代,不断将当前函数 Fm−1 往最优函数 F∗ 空间上逼近,逼近方向就是当前函数下的函数负梯度方向 −∇L(y,F)∣∣F=Fm−1 。由于优化函数,而非变量,本质上属于泛函优化。
3. 每次迭代计算出函数负梯度,基于训练数据构建模型来拟合负梯度。原则上可以选择任何模型:树模型,线性模型或者神经网络等等,很少框架支持神经网络,推测:神经网络容易过拟合,后续函数负梯度恒为0就无法继续迭代优化下去。如果用树模型进行拟合,就是我们熟悉的CART建树过程。
4. 优化步长,根据目标函数来最优步长 ρm ,属于变量优化,并更新当前函数,继续迭代。框架并没有shrinkage机制来控制过拟合,采用树模型和线性模型也可能过度拟合,目前现代的boosting框架都支持shrinkage,即最终的优化步长应乘以shrinkage参数: ρm=ρmγ 。
该框架实际上是泛函梯度下降优化过程,尽管中间局部包含变量优化步骤,对比变量优化迭代不难发现相似之处。准确来说适合变量优化的其他策略同样适合泛函优化:1)基于梯度下降优化,步长优化可以是精确优化和非精确优化。2)基于牛顿法,根据二阶梯度直接计算步长 f″(x)−1 ,即更新变量 xn+1=xn−f′(x)f″(x) ,本质上XGBoost属于牛顿法,而且加入正则化,二阶导数恒大于0;3)拟牛顿法,用于二阶不可导时情况等等
谈到集成学习,不得不说bagging集成,比如随机森林,1)建树前对样本随机抽样(行采样),2)每个特征分裂随机采样生成特征候选集(列采样),3)根据增益公式选取最优分裂特征和对应特征分裂值建树。建树过程完全独立,不像boosting训练中下一颗树需要依赖前一颗树训练构建完成,因此能够完全并行化。Python机器学习包sklearn中随机森林RF能完全并行训练,而GBDT算法不行,训练过程还是单线程,无法利用多核导致速度慢。希望后续优化实现并行,Boosting并行不是同时构造N颗树,而是单颗树构建中遍历最优特征时的并行,类似XGBoost实现过程。随机森林中行采样与列采样有效抑制模型过拟合,XGBoost也支持这2种特性,此外其还支持Dropout抗过拟合。
2. XGBoost原理推导
1. XGBoost考虑正则化项,目标函数定义如下:
其中 ŷ i 为预测输出, yi 为label值, fk 为第 k 树模型, T 为树叶子节点数, w 为叶子权重值, γ 为叶子树惩罚正则项,具有剪枝作用, λ 为叶子权重惩罚正则项,防止过拟合。XGBoost也支持一阶正则化,容易优化叶子节点权重为0,不过不常用。
根据Boosting框架,可以优化出树的建模函数 ft(x) :
2. 因此,每次建树优化以下目标:
其中 gi=∂ŷ (t−1)il(yi,ŷ (t−1)i) , hi=∂2ŷ (t−1)il(yi,ŷ (t−1)i) ,而且:
3. 假设我们已知树结构 q ,即每个样本 xi 能通过该结构 q 找到对应的叶子节点 j ,可以定义 Ij={i|q(xi)=j} 为在树结构 q 下,落入叶子节点 j 所有样本序号的集合。展开上述表达式并通过配方法不难得到:
其中 Gj=∑i∈Ijgi 为落入叶子 i 所有样本一阶梯度统计值总和, Hj=∑i∈Ijhi 为落入叶子 i 所有样本二阶梯度统计值总和。最终得到叶子权重值为:
4. 最终的目标值为:
下图为树的目标值计算样例:

5. 回顾步骤3,可以发现前提假设是已知树结构 q ,除非遍历所有树结构,否则无法优化最优目标值,而且为了优化目标值,我们也不可能遍历所有树结构。论文提出了贪婪的算法,类似于CART定义增益公式来启发式的寻找最优树结构,若当前树结构 I 能被分裂成 IL 与 IR , I=IL⋃IR ,XGBoost的增益公式:
3. XGBoost算法
1)XGBoost精确贪婪算法
构建树流程如下:1.遍历每个特征 k ,2)遍历当前特征 k 下每个取值 xjk ,对于特征分裂值将前节点样本样本划分到左右子树,根据上述公式通过计算增益,选取增益最大对应的特征以及特征分裂值,执行节点分裂, Lsplit 最大值小于0则停止分裂, γ 可以视为分裂阈值,起到一定程度的预剪枝的作用,再不断重复。下图为根据特征值排序,从左到右进行扫描来找出当前特征下最优分裂值。

论文提出的精确贪婪算法流程如下:

2)XGBoost近似算法
精确算法由于需要遍历特征的所有取值,计算效率低,适合单机小数据,对于大数据、分布式场景并不适合。论文基于Weighted Quantile Sketch分位点算法提出相应的近似算法,也证明了该分位点的正确性。通过设置 ϵ 来设置近似程度,而且论文给出近似算法的2种方案:
1. 在建树之前预先将数据进行全局分桶,需要设置更小的 ϵ ,产生更多的桶,特征分裂查找基于候选点多,计算较慢,但只需在全局执行一次。
2. 每次分裂重新局部分桶,可以设置较大的 ϵ ,产生更少的桶,每次特征分裂查找基于候选点少,计算速度快,但是需要每次节点分裂后重新执行,论文中说该方案更适合树深的场景。
论文给出Higgs案例下,方案1全局分桶设置 ϵ=0.05 与精确算法效果差不多,方案2局部分桶设置 ϵ=0.3 与精确算法仅稍差点,方案1全局分桶设置 ϵ=0.3 则效果极差。
近似算法为什么能用于分布式?主要原因是分桶是基于分位点算法,分位点算法支持merge和prune操作,想了解该过程可以移步《分位点算法详解》,而且XGBoost场景属于weighted分位点算法,作者在论文后面也证明weighted分位点算法支持merge和prune操作,因此适合与分布式场景。近似算法主要对数据分布进行分桶,同时希望每个桶尽量均匀。考虑数据集:
定义rank函数为 rk:R→[0,+∞) , 二阶导数 hi 一定大于等于0,而一阶导数 gi 则不具备该条件,所以无法构建分位点。实际上XGBoost源代码不仅会构建 hi 的分位点,也会对 gi 进行拆分,分别构建 gi>0 集合分位点和 gi<0 集合分位点(取负),目前按照论文中仅考虑二阶导数统计值 hi :
rk(z) 表示特征值小于 z 的样本集合中, h 累计值的百分占比。在这个排序函数下,我们找到一组点 sk1,sk2,...,skl ,满足:
上述条件1为均匀条件,条件2为边界条件。这样就能得到 1/ε 个特征值分割候选点,假设数据量为1kw,设置 ϵ=0.01 ,则由候选点1kw降低为100,速度提升10w倍, 论文提出的精确贪婪算法流程如下:

3)XGBoost近似算法
对于数据缺失数据、one-hot编码等造成的特征稀疏现象,作者在论文中提出可以处理稀疏特征的分裂算法,主要是对稀疏特征值miss的样本学习出默认节点分裂方向:
1. 默认miss value进右子树,对non-missing value的样本在左子树的统计值 GL 与 HL ,右子树为 G−GL 与 H−HL ,其中包含miss的样本。
2. 默认miss value进左子树,对non-missing value的样本在右子树的统计值 GR 与 HR ,左子树为 G−GR 与 H−HR ,其中包含miss的样本。
最后,找出增益最大对于的特征、特征对于的值、以及miss value的分裂方向,作者在论文中提出基于稀疏分裂算法:

4. XGBoost工程优化
内部数据存储格式
从算法上看,每种算法都依赖特征排序,然后扫描,为了减少特征排序,XGBoost引入一种名为block的数据存储结构,将数据存储在内存单元,并对每一种特征进行排序。block中的数据以CSC格式存储。实际上源代码中XGBoost会把文件数据读入先生成CSR格式,然后转化为CSC格式。其中CSR格式如下:
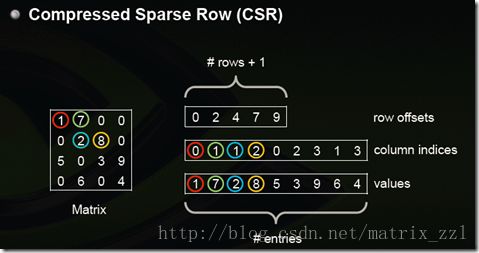
CSR包含非0数据块values,行偏移offsets,列下标indices。offsets数组大小为(总行数目+1),CSR是对稠密矩阵的压缩,实际上直接访问稠密矩阵元素 (i,j) 并不高效,毕竟损失部分信息,访问过程如下:
1. 根据行 i 得到偏移区间开始位置offsets[i]与区间结束位置offsets[i+1]-1,得到 i 行数据块values[offsets[i]..(offsets[i+1]-1)], 与非0的列下表indices[offsets[i]..(offsets[i+1]-1)],
2. 在列下标数据块中二分查找 j ,找不到则返回0,否则找到下标值 k ,返回values[offsets[i]+k]
从访问单个元素来说,从 O(1) 时间复杂度升到 O(logN) , N为该行非稀疏数据项个数。但是如果要遍历访问整行非0数据,则无需访问indices数组,时间复杂度反而更低,因为少了大量的稀疏为0的数据访问。
CSC与CSR变量结构上并无差别,只是变量意义不同,其中values仍然为非0数据块,offsets为列偏移,即特征id对应数组,indices为行下标,对应样本id数组,XBGoost使用CSC主要用于对特征的全局预排序。预先将CSR数据转化为无序的CSC数据,遍历每个特征,并对每个特征 i 进行排序:sort(&values[offsets[i]], &values[offsets[i+1]-1])。全局特征排序后,后期节点分裂可以复用全局排序信息,而不需要重新排序。
Cache-aware Access
CSC存储优化会导致获取每个样本获取统计值而不连续,造成样本计算cache不断切换而导致cache-miss,XGBoost通过选择适当的block size来缓存数据解决小样本量带来的资源浪费以及大样本量带来的cache-miss之间的权衡问题,XGBoost选择的block size为 216 。
Out-of-core Computation
XGBoost中提出Out-of-core Computation优化,解决了在硬盘上读取数据耗时过长,吞吐量不足:
1)Block Compression基于block,数据分块,每块 216 个样例,使用16bit来存储offset。利用压缩算法将硬盘中的数据进行压缩,在读取数据进内存的过程中利用一个独立的线程对数据进行解压缩,将disk reading cost转换为解压缩所消耗的计算资源。
2)Block Sharding将数据shard到多块硬盘上,每块硬盘分配一个预取线程,将数据fetche到in-memory buffer中。训练线程交替读取多块buffer,提升了硬盘总体的吞吐量。
5. XGBoost算法复杂度
针对精确贪婪算法,考虑数据样本量为 N ,特征数量为 M , 设置树的个数为 K , 树深为 D ,不考虑行采样与列采样,其时间复杂度分析如下:
1. 全局特征预排序,由于全局排序,后期节点再分裂可以复用全局排序信息,而不需要重新排序,因此排序复杂度为 O(MNlog(N))
2. 构建单树复杂度:由于XGBoost实现基于level-wise, 每层的时间复杂度是为 O(MN) ,K颗树复杂度为 O(KMND)
3. 最终时间复杂度为: O(MNlog(N)) + O(KMND) , 注意:跟论文的分析不同,主要按照笔者的理解,后期仔细分析后,如果有出入会修正。
参考资料
- Friedman Boosting框架论文:https://statweb.stanford.edu/~jhf/ftp/trebst.pdf
- 陈天奇XGBoost论文:https://arxiv.org/pdf/1603.02754.pdf
- XGBoost项目:https://github.com/dmlc/xgboost
- GK Summary算法论文:http://infolab.stanford.edu/~datar/courses/cs361a/papers/quantiles.pdf
- A fast algorithm for approximate quantiles论文: https://pdfs.semanticscholar.org/03a0/f978de91f70249dc39de75e8958c49df4583.pdf
- wepon GDBT ppt:http://202.38.196.91/cache/2/03/wepon.me/5aa84bcab4e621a09cc475c348590c35/gbdt.pdf