python语法
解释器:
#!/usr/bin/python
或者
#!/usr/bin/env python
解释中文
# -*- coding: UTF-8 -*-
#coding=utf-8
Python的基础
变量
特殊变量
_xxx from module import * 无法导入的变量
__xxx__ 系统定义的变量
__xxx 类的本地变量
局部变量和全局变量
#####局部变量覆盖全局变量
#!/usr/bin/python
def p_num():
num = 5
print num
num = 10
print num
p_num()
#####函数内部有局部变量,解释器不使用全局变量,局部变量的定义晚于引用会报错。
#!/usr/bin/python
def p_num():
print num
num = 5
print num
num = 10
print num
p_num()
原因:解释器会一次性分析函数体,发现函数中有变量num,会使全局变量num失效。故在执行变量的时候会报错
#####在函数内部调用全局变量
#!/usr/bin/python
def p_num():
print num
num = 10
print num
p_num()
修改全局变量
#!/usr/bin/python
def p_num():
global num
num = 20
print num
num = 10
print num
p_num()
表达式
算数表达式
+ a 结果不变
- a 对结果符号取负
a + b a加b
a - b a减b
a ** b a的b次幂
a / b a除以b,真正除,浮点数保留小数
a // b a除以b,向下取整
a % b a对b取余数
逻辑表达式
not a a的逻辑非
a and b a和b的逻辑与
a or b a和b的逻辑或
a is b a和b是同一个对象
a is not b a和b不是同一个对象
关系表达式
== 等于
!= 不等于
<> 不等于(废弃)
> 大于
< 小于
>= 大于等于
<= 小于等于
位运算
~ a 按位取反
a << n a左移n位
a >> n a右移n位
a & b a和b按位与
a | b a和b按位或
a ^ b a和b按位异或
语法格式
分支语句
if-else
if a > b:
print "aaaa"
else:
print "bbb"
if-elif-else
if a > b:
print "a>b"
elif a == b:
print "a=b"
else:
print "aif/else的三元运算符
A=Y if X else Z
只有当X为真时才会执行表达式Y,而只有当X为假时,才会执行表达式Z
num = 2 if 1==1 else 4
print num
结果:2
num = 2 if 1==2 else 4
print num
结果:4
if/else的三元运算符的多重使用
判断端口是使用80端口还是443端口,如果指定了端口就是使用指定的端口,如果没有指定端口,则使用默认的,在使用默认的时候需要判断是否是安全级别的如果是,剧使用443.否则使用80.
port = 80
DEFAULT_SECURE_PORT = 443
is_secure = False
DEFAULT_INSECURE_PORT = 80
port1 = port if port is not None else DEFAULT_SECURE_PORT if is_secure else DEFAULT_INSECURE_PORT
print port1
判断流程
循环语句
#####while循环
while 判断条件:
执行语句
var = 10
while var > 1:
print var
var -= 1
for循环语句,可以遍历任何序列的项目
for iterating_var in squence:
执行语句
for letter in "python":
print 'Current Letter:',letter
fruits = ['banana','apple','mango']
for fruit in fruits:
print 'Current fruit:',fruit
for…else或者while…else
在python中,for…else表示的意思是,for中的语句和普通语句没有区别,else是循环正常执行完毕(不是通过break跳出中断的)之后的执行的代码。while…else也是类似的
for i in "python":
print "i is ",i
else:
print "over"
for i in "python":
print "i is ",i
if i == 'n':
print "break"
break
else:
print "over"
条件语句
in、not in
检查一个值是不是在序列中
a 测试a是不是小于b,并且b等于c
and、or
优先级是低于其他的比较操作符,not经常和这两个结合使用,not的优先级是最高的,or的优先级是最低的,A and not B or C 等价于(A and (not B)) or C
>>> string1, string2, string3 = '', 'Trondheim', 'Hammer Dance'
>>> non_null = string1 or string2 or string3
>>> non_null
'Trondheim
num = True and True and False
print num
结果:False
所有的都是True最后的结果才是True,A and B and C 如果B是False,A、C都是True,最后的结果是False,在执行的A and B,不会执行C。
列表
访问列表中的值
In [37]: alist = [1,2,3,4]
In [38]: alist[0]
Out[38]: 1
更新列表中的值
In [43]: alist
Out[43]: [1, 2, 3, 4]
In [44]: alist[3]=33
In [45]: alist
Out[45]: [1, 2, 3, 33]
删除列表中的值
In [46]: del alist[1]
In [47]: alist
Out[47]: [1, 3, 33]
python列表脚本操作符
对列表的操作符“*”和“+”相似,“+”号用于组合列表,"*"用于重复列表。
|Python表达式|结果|描述
|—|----|
|len([1,2,3,4])|4|列表的长度
|[1,2,3,4] + [3,2,3,4]|[1, 2, 3, 4, 3, 2, 3, 4]|组合
|[‘he’] * 4|[‘he’, ‘he’, ‘he’, ‘he’]|重复
|3 in [1,2,3,4]| True|判断元素是否在列表中
|for x in [1,2,3,4]: print x|1 2 3 4 |迭代
Python的截断
列表名[开始索引:结束索引:步长]
alist[0:3:2] 表示从索引为0的元素开始到索引为3的元素(不包含),步长为2(下一个索引的值为0+2)
In [39]: alist[0:]
Out[39]: [1, 2, 3, 4]
In [40]: alist[0::2]
Out[40]: [1, 3]
In [41]: alist[0:2:2]
Out[41]: [1]
In [42]: alist[0:2]
Out[42]: [1, 2]
列表的函数和方法
函数
|序号|函数|作用|
|:------:|||
|1|cmp(list1,list2)|比较两个列表的元素
|2|len(list1)|放回列表元素的个数
|3|max(list1)|返回列表中的最大值
|4|min(list1)|返回列表中的最小值
|5|list(seq)|元组转化为列表
方法:
|序号|方法|作用|
|—|||
|1|list.append(abc)|在列表的末尾添加一个新元素abc
|2|list.count(abc)| 在列表中元素出现的个数
|3|list.extend(seq)|在列表的最后追加另一个序列的多个值
|4|list.index(abc)| 显示列表中元素对应的索引
|5|list.insert(index,abc)|在列表的指定位置插入元素
|6|list.pop(index)|删除列表中指定位置的元素,返回该元素的值
|7|list.remove()|移除莫一个值的第一个匹配项
|8|list.reverse()| 反向列表中的元素
|9|list.sort([func]) | 对列表进行排序
pop()
In [48]: alist.pop()
Out[48]: 33
append()
In [50]: alist.append(323)
In [51]: alist
Out[51]: [1, 3, 3333, 323]
元组
python中的元组和数组类似,不同之处在于元组中的 数据不能修改,不能分片,不能连接操作,元组是圆括号,列表值方括号
In [77]: t1 = (1,2,3,4,5)
In [78]: t1
Out[78]: (1, 2, 3, 4, 5)
In [19]: abc = 1,2,3,
In [20]: abc
Out[20]: (1, 2, 3)
元组的访问
In [79]: t1[2]
Out[79]: 3
元组修改
In [80]: t1[2] = 3
TypeError: 'tuple' object does not support item assignment
In [81]: t2 = (4,2,3,4,4)
In [82]: t1 + t2
Out[82]: (1, 2, 3, 4, 5, 4, 2, 3, 4, 4)
In [83]: t1
Out[83]: (1, 2, 3, 4, 5)
In [84]: t3 = t1 + t2
In [85]: t3
Out[85]: (1, 2, 3, 4, 5, 4, 2, 3, 4, 4)
元组运算符
|Python表达式|结果|描述
|—|----|
|len((1,2,3,4))|4|列表的长度
|(1,2,3,4) + (3,2,3,4)|(1, 2, 3, 4, 3, 2, 3, 4)|连接
|(‘he’) * 4|(‘he’, ‘he’, ‘he’, ‘he’)|重复
|3 in (1,2,3,4)| True|判断元素是否存在
|for x in (1,2,3,4): print x|1 2 3 4 |迭代
元组的截取
In [88]: t1
Out[88]: (1, 2, 3, 4, 5)
In [89]: t1[1:]
Out[89]: (2, 3, 4, 5)
In [90]: t1[1:3]
Out[90]: (2, 3)
In [91]: t1[:5:2]
Out[91]: (1, 3, 5)
In [92]: t1[:5:-2]
Out[92]: ()
In [93]: t1[5:0:-2]
Out[93]: (5, 3)
内置方法
|序号|函数|作用|
|:------:|||
|1|cmp(tuple1,tuple2)|比较两个列表的元素
|2|len(tuple1)|放回列表元素的个数
|3|max(tuple1)|返回列表中的最大值
|4|min(tuple1)|返回列表中的最小值
|5|tuple(seq)|列表转化为元组
字典
字典是Python中的映射数据类型,由键值(key-value)构成,类似于关联数据或哈希表,key一般以数字和字符串居多,值一般是任意类型的Python对象,字典元素使用{}包括。
In [1]: dic = {'aa':123,'bb':234}
In [2]: dic
Out[2]: {'aa': 123, 'bb': 234}
访问字典中的值
In [1]: dic = {'aa':12,'bb':23}
In [2]: dic['aa']
Out[2]: 12
In [3]: for i in dic:
...: print i,dic[i]
...:
aa 12
bb 23
修改字典
有对应的key将会修改,如果没有将会自动增加一个键值对
In [4]: dic['aa']=3333
In [5]: dic
Out[5]: {'aa': 3333, 'bb': 23}
In [6]: dic['dd'] = 3434
In [7]: dic
Out[7]: {'aa': 3333, 'bb': 23, 'dd': 3434}
删除字典的元素
In [8]: dic
Out[8]: {'aa': 3333, 'bb': 23, 'dd': 3434}
In [9]: del dic['aa'] #删除指定的元素
In [10]: dic
Out[10]: {'bb': 23, 'dd': 3434}
In [11]: dic.clear() #清空字典
In [12]: dic
Out[12]: {}
In [13]: del dic #删除字典
字典(key)的特性
1)不允许同一个键出现两次。创建的时候同一个键赋值两次,后一个值会 被记住。
In [17]: dic = {'aa':123,'bb':22,'cc':33,"aa":345}
In [18]: dic
Out[18]: {'aa': 345, 'bb': 22, 'cc': 33}
2)键必须不可变,所以可以使用数字、字符串、或元组,不能使用列表
In [22]: dic1 = {[1,2]:11,'abc':22}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 dic1 = {[1,2]:11,'abc':22}
TypeError: unhashable type: 'list'
内置的函数和方法
|序号|函数|作用|
|:------:|||
|1|cmp(dic1,dic2)|比较两个字典的元素,相同返回0
|2|len(dic1)|放回字典元素的个数
|3|str(dic1)|输出字典可打印字符串表示
|序号|函数|作用|
|:------:|||
|1|dic1.clear()|清空字典中的所有元素
|2|dic1.copy()|浅复制
|3|dic1.items()|以列表返回可遍历的(键,值)元组数组
|4|dic1.keys()|以列表返回字典的所有的键
|5|dic1.values()|以列表返回字典的所有值
|6|dict.fromkeys(S[,v])|创建一个新字典,以序列s作为字典的键,以v作为字典的值
|7|dic1.get(‘aa’)|获取字典对应的键的值
|8|dic1.has_key(‘aa’)|判断字典中是否含指定的键
|9|dic1.setdefault(‘dd’,‘aa’)|和get类似,但是如果字典中不存在该键,会自动增加键值对
|10|dic2.update(dic1)|将dic1中的键值对更新到dic2中
集合
集合:无序排列、可哈希
支持集合关系测试:
支持成员关系测试:
in、not in、迭代
不支持索引、元素获取、切片
集合的类型:set()、fronzenset()
没有特定的语法格式,只能通过工厂函数创建
In [1]: l1 = [1,2,3,4]
In [2]: s1 = set(l1)
In [3]: s1
Out[3]: {1, 2, 3, 4}
In [4]: type(s1)
Out[4]: set
In [5]: print s1
set([1, 2, 3, 4])
frozenset()创建不可变集合
In [26]: l1
Out[26]: [1, 2, 3, 4]
In [27]: s3 = frozenset(l1)
In [28]: s3
Out[28]: frozenset({1, 2, 3, 4})
集合的方法
|方法|描述|
|::||
|len(s)|放回s的项目数
|s.copy()|制作s的副本
|s.difference(t)|求差集,返回s中有的t中没有的
|s.intersection(t)|求交集,返回s和t中都用的
|s.isdisjoint(t)|如果s和t中含有相同项,返回True
|s.issubset(t)|如果s是t的一个子集,返回True
|s.issuperset(t)|如果s是t的一个超集,返回True
|s.symmetric_difference(t)|求对称差集,返回所有的在s和t中,但又不同时在这两集合中的项。
|s.union(t)|求并集,返回所有在s或t中的项
|s.update(t)|求并集,放回所有在s或者t中的项,并赋值给s
集合操作
|操作|描述|
|:
|s | t|s和t的并集
|s & t|s和t的交集
|s - t|求差集
|s ^ t|求对称差集
|len(s)|集合中的项数
|max(s)|最大值
|min(s)|最小值
In [9]: s1
Out[9]: {1, 2, 3, 4}
In [10]: s2
Out[10]: {3, 4, 5}
In [11]: s1.difference(s2)
Out[11]: {1, 2}
In [12]: s1.intersection(s2)
Out[12]: {3, 4}
In [13]: s1 & s2
Out[13]: {3, 4}
In [14]: s1.union(s2)
Out[14]: {1, 2, 3, 4, 5}
In [15]: s1 | s2
Out[15]: {1, 2, 3, 4, 5}
In [16]: s1.symmetric_difference(s2)
Out[16]: {1, 2, 5}
In [17]: s1 ^ s2
Out[17]: {1, 2, 5}
In [18]: s1.difference(s2)
Out[18]: {1, 2}
In [19]: s1 - s2
Out[19]: {1, 2}
迭代器
iterable(可迭代)对象
支持每次返回自己所包含的一个成员的对象
对象实现了__iter__方法
序列的类型:如:list、str、tuple
非序列类型:如:dict、file
用户自定义一个包含__iter__()或者__getitem__()方法的类
In [1]: l1 = ['Mon','Tue','Wed','Thu','Fri','Sta','Sun']
In [2]: dir(l1)
Out[2]:
['__add__',
'__class__',
....
'__getattribute__',
'__getitem__',
'__getslice__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__iter__',
.....
]
In [3]: l1.__iter__()
Out[3]: #放回一个迭代器
In [4]: d1 = l1.__iter__()
In [5]: d1.next()
Out[5]: 'Mon'
In [6]: d1.next()
Out[6]: 'Tue'
In [7]: d1.next()
Out[7]: 'Wed'
In [8]: d1.next()
Out[8]: 'Thu'
通过iter()函数生成迭代器
In [10]: iter(l1)
Out[10]:
可以使用for循环来获取迭代对象的元素
In [26]: for i in l1:
...: print i
...:
1
2
3
5
容器数据类型特征
1.列表、元组、字典可以写在多个行,可以在最后写逗号,元素为空时,不能写逗号
2.所有对象都有引用计数
In [29]: import sys
In [30]: sys.getrefcount(s3)
Out[30]: 8
3.列表、字典都支持两种类型的复制,浅复制和深复制,深复制可以使用copy模块中的deepcopy()实现
4.所有的序列都支持迭代
5.所有序列都支持的操作和方法
s[i]
s[i,j]
s[i,j,stride]
len(s)
min(s)
max(s)
sum(s)
all(s)
any(s)
s1 + s2 连接
s1 * n 重复
obj in s1 :成员关系
obj not in s2:
6.可变序列的操作
s1[index] = value: 元素赋值
s1[i:j] = t 切片赋值
del s1[index]:
del s1[i:j]:
del s2[i:j:stride]:
列表解析
根据已有的列表快速生成新列表
语法:
[expression for iter_var in iterable ]
[expression for iter_var in iterable if cond_expr]
In [11]: l1 = [1,2,3,5]
In [12]: l2 = [i**2 for i in l1]
In [13]: l2
Out[13]: [1, 4, 9, 25]
In [14]: l3 = [i**2 for i in l1 if i > 2]
In [15]: l3
Out[15]: [9, 25]
删除变量
del 直接释放资源,变量名删除,引用计数减1
ipython的常用命令:
In [6]: %history
sublime使用技巧
调出installpackage界面
ctrl+shift+p
install package
常用工具包
AdvanceNewFile
Djaneriro
Emmet HTML代码补齐
Git
Side Bar
HTML/CSS/JS Prettify HTML/CSS/JS对齐工具
Python PEP8 Autoformat python的语法检查工具
SublimecodeIntel 代码补齐工具
ColorPicker 拾色器
OmniMarkupPreviewer 写markdown使用
字符串处理和特殊函数
用引号括起来的字符集合称为字符串,引号可以是一对单引号、双引号、三引号
In [1]: var1 = 'abcd'
In [2]: var2 = "hello"
In [3]: var3 = '''hello world'''
输出hello “dear”
In [4]: print 'hello "dear"'
hello "dear"
In [5]: print "hello \"dear\""
hello "dear"
In [6]: print '''hello "dear" '''
hello "dear"
Python访问字符串的值
In [10]: var3
Out[10]: 'hello world'
In [11]: var3[0]
Out[11]: 'h'
In [12]: var3[3]
Out[12]: 'l'
In [13]: var3[3:7:2]
Out[13]: 'l '
In [14]: var3[1:9:2]
Out[14]: 'el o'
字符串的运算符
实例变量a为hello,变量b为world
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串的连接 | a + b 输出结果’helloworld’ |
| * | 重复输出字符串 | a * 2 输出的结果是’hellohello’ |
| [] | 通过索引获取字符串 | a[1] 输出的结果是:e |
| [:] | 截取字符串的一部分 | a[1:3] 输出结果是:el |
| in | 成员运算符 | 如果字符串中包含返回true |
| not in | 成员运算符 | 如果字符串中不包含返回true |
| r/R | 原始字符串 | 字符串按照字面的意思显示,没有转义或不能打印的字符 |
防止转换
In [7]: print "C:\shell\name"
C:\shell
ame
In [8]: print r"C:\shell\name"
C:\shell\name
字符串的格式化输出
%s 和%d都是占位符,%s代表的是一个字符串,%d代表的是一个整型
In [25]: print "my name is %s and weight is %d " % ('tom',21)
my name is tom and weight is 21
字符串的函数
In [27]: mystr = "I have many dreams, my first dream is becomi
...: ng a teacher.My second dream is becoming a hecker "
find()和rfind()查找字符串
find()返回查找的字符的第一次出现的位置,没有找到则返回-1
rfind()和find类似,rfind是从后向前查询
S.find(sub [,start [,end]]) -> int
In [30]: mystr.find('my')
Out[30]: 20
In [34]: mystr.find('hhh')
Out[34]: -1
In [40]: mystr.find('is',36,90)
Out[40]: 73
index()和rindex()查找指定字符串的索引
index()从左向右开始查找
rindex()从右向左开始查找
In [42]: mystr.index('is')
Out[42]: 35
和find()的区别,如果是查找的字符串不存在find会返回-1,但是index()返回异常。
count() 字符串出现的次数
In [43]: mystr.count('is')
Out[43]: 2
decode()解码和encode()编码
以encoding指定的编码格式编码mystr,如果出错默认会报ValueError的异常,除非设置error指定的是ignore或者replace
S.encode([encoding[,errors]]) -> object
S.decode([encoding[,errors]]) -> object
In [46]: mystr.decode('UTF-8')
Out[46]: u'I have many dreams, my first dream is becoming a teacher.My second dream is becoming a hecker '
In [47]: mystr.encode('UTF-8')
Out[47]: 'I have many dreams, my first dream is becoming a teacher.My second dream is becoming a hecker '
replace()
S.replace(old, new[, count]) -> string
count 为2表示替换前两个
字符串本身没有变化
In [53]: mystr.replace('My','my')
Out[53]: 'I have many dreams, my first dream is becoming a teacher.my second dream is becoming a hecker '
In [54]: mystr
Out[54]: 'I have many dreams, my first dream is becoming a teacher.My second dream is becoming a hecker '
split()
S.split([sep [,maxsplit]]) -> list of strings
默认是以空格作为分隔符
In [63]: mystr.split(' ')
Out[63]:
['I',
'have',
'many',
'dreams,',
'my',
'first',
'dream',
'is',
'becoming',
'a',
'teacher.my',
'second',
'dream',
'is',
'becoming',
'a',
'hecker',
'']
capitalize()首字母大写
In [68]: mystr.capitalize()
Out[68]: 'I have many dreams, my first dream is becoming a teacher.my second dream is becoming a hecker '
center()将字符串在指定的宽度中居中
In [70]: mystr.center(100)
Out[70]: ' I have many dreams, my first dream is becoming a teacher.my second dream is becoming a hecker '
startswith()和endswith() 判断字符串的开头和结尾
In [71]: mystr.endswith('')
Out[71]: True
In [72]: mystr.endswith('hecker')
Out[72]: False
In [73]: mystr.startswith('I')
Out[73]: True
isalnum()判断是否为字符
判断字符串是不是只有字母数字(不含空格),最少有一个字符,否则为假
In [76]: var1
Out[76]: 'abcd'
In [77]: var1.isalnum()
Out[77]: True
In [78]: var1 = "anc d"
In [79]: var1.isalnum()
Out[79]: False
In [89]: var1 = ""
In [90]: var1.isalnum()
Out[90]: False
isalpha() 是否全是字母不含数字、空格
In [1]: str1 = "hello world"
In [2]: str1.isalpha()
Out[2]: False
In [3]: str2 = "hello"
In [4]: str2.isalpha()
Out[4]: True
In [5]: str3 = "hello1"
In [6]: str3.isalpha()
Out[6]: False
isdigit()是否都是数字
In [13]: str1
Out[13]: '123'
In [14]: str1.isdigit()
Out[14]: True
In [15]: str1 = "12ac"
In [16]: str1.isdigit()
Out[16]: False
islower() 和 isupper() 判断大小写
只判断字符是否为小写,和空格、数字无关。
In [17]: str1
Out[17]: '12ac'
In [18]: str1.islower()
Out[18]: True
In [19]: str1 = "HE"
In [20]: str1.islower()
Out[20]: False
In [21]: str1 = "a aa"
In [22]: str1.islower()
Out[22]: True
isspace()是否为空
In [31]: str1 = ""
In [32]: str1.isspace()
Out[32]: False
In [33]: str1 = " "
In [34]: str1.isspace()
Out[34]: True
join()
S.join(iterable)将字符串加到后面的迭代器中,返回字符串。
In [2]: str1 = "hello"
In [3]: str2 = "xxxxx"
In [4]: str2.join(str1)
Out[4]: 'hxxxxxexxxxxlxxxxxlxxxxxo'
In [11]: l1 = ['1','2','3','4']
In [12]: str2.join(l1)
Out[12]: '1xxxxx2xxxxx3xxxxx4'
ljust()和rjust()指定字符串的长度,左对齐和右对齐
In [14]: str1.ljust(20)
Out[14]: 'hello '
In [15]: str1.rjust(20)
Out[15]: ' hello'
lstrip()和rstrip()去掉开头、结尾的空格
In [16]: str1 = " hello world "
In [17]: str1.lstrip()
Out[17]: 'hello world '
In [18]: str1.rs
str1.rsplit str1.rstrip
In [18]: str1.rstrip()
Out[18]: ' hello world'
partition()和rpartition()指定分隔的字符串
partition()指定分隔的字符串,将字符串分隔为三段,并以元组的形式返回。
rpartition()和partition()类似,从后向前查找分隔的字符串。
In [19]: str1 = "Creating Unicode strings in Python is just as simple as creating normal strings"
In [21]: str1.partition("strings")
Out[21]:
('Creating Unicode ',
'strings',
' in Python is just as simple as creating normal strings')
In [22]: str1.rpartition("strings")
Out[22]:
('Creating Unicode strings in Python is just as simple as creating normal ',
'strings',
'')
zfill() 指定字符串的宽度左侧用0填充
In [26]: str2
Out[26]: 'xxxxx'
In [27]: str2.zfill(10)
Out[27]: '00000xxxxx'
函数
自定义函数
语法格式:
def functionname (parameters):
"函数文档字符串"
function_suite
return [expression]
默认情况下,参数值和函数名称是按照函数声明中定义的顺序匹配的
def add(x,y):
z = x + y
return z
res = add(2,3)
print res
函数的调用
#!/usr/bin/python
def printMe(str1):
"print string" #函数的功能描述
print str1
printMe("hello world")
按值传递参数和按引用传递参数
按引用传递参数,函数的操作导致变量的改变
#!/usr/bin/python
def list_append(list1):
"list append"
list1.append([1,2,3,4])
list1 = [2,3,3,33,21]
print list1
list_append(list1)
print list1
结果:
[2, 3, 3, 33, 21]
[2, 3, 3, 33, 21, [1, 2, 3, 4]]
按值传递参数
#!/usr/bin/python
def add_5(var):
"var + 5"
var += 5
print var
var = 10
print var
add_5(var)
print var
输出结果:
10
15
10
参数
调用函数时,使用的参数类型:
必备参数
命名参数
缺省参数
不定长参数
必备参数
必备参数必须以正确的顺序传入参数,调用的参数的数量必须和声明的一样
printme()函数,必须传入一个参数,不然会出现语法错误
命名参数
命名参数和函数调用关系密切,调用方用参数的命名确定传入的参数值,
print_a(b=1,a=2)
#!/usr/bin/python
def print_a(a,b):
"pirnt a"
print a
In [28]: import print_a
In [29]: print_a.print_a(1,2)
1
In [30]: print_a.print_a(b=1,a=2)
2
缺省参数
调用函数时,缺省函数的值如果没有传入,则被认为是默认的值,
在函数中指定默认的参数变量,但是指定参数的默认变量要从右向左。否则会报错。
# cat default_pra.py
#!/usr/bin/python
def print_AandB(a,b=3):
"print a and b"
print "a = %d" %(a)
print "b = %d" %(b)
In [33]: default_pra.print_AandB(2)
a = 2
b = 3
结果:
In [32]: import default_pra
In [34]: default_pra.print_AandB(2,4)
a = 2
b = 4
不定长参数
需要一个参数能出来比当初声明时更多的参数。这些参数叫做不定长参数。
基本语法:
def function([formal_args,] *var_args_tuple)
"函数___文档字符串"
function_suite
return [expression]
加【*】的变量名会存放所有的为命名的变量参数。会以元组的形式存在。
# cat print_alarg.py
#!/usr/bin/python
def print_args(a,b,*c):
"print all arguments"
print "a = %d" %(a)
print "b = %d" %(b)
print c
结果:
In [1]: import print_alarg
In [2]: print_alar
print_alarg print_alarg.py print_alarg.pyc
In [2]: print_alarg.print_args(1,2,3,4)
a = 1
b = 2
(3, 4)
In [3]: print_alarg.print_args(1,2,3)
a = 1
b = 2
(3,)
In [4]: print_alarg.print_args(1,2)
a = 1
b = 2
()
可变长参数使用[**]接收到的参数以字典的形式存在,传递参数时,必须使用命名方式的传参形式。
# cat print_args.py
#!/usr/bin/python
def print_args(**a):
print a
结果:
In [9]: print_args.print_args(x=1,y=2,z=3)
{'y': 2, 'x': 1, 'z': 3}
匿名函数
用户lambda关键字能创建小型匿名函数 ,这种函数得名于省略了用户def声明函数的标准步骤。
lambda函数能接受任何数量的参数但是只能返回一个表达式的值,
匿名函数不能直接调用print,因为lambda需要一个表达式
lambda函数拥有自己的名字空间,切不能访问自有函数列表之外或全局名字空间里的参数虽然lambda函数看起来只能写一行,却不等同于c或c++的内联函数,后者的目的是调用小函数
lambda函数的语法只包含一个语句,如下:
lambda [arg1[,arg2...]]:expression
In [17]: sum = lambda a,b: a + b
In [18]: sum(2,3)
Out[18]: 5
闭包
闭包:词法闭包,
在通过Python的语言介绍一下,一个闭包就是你调用了一个函数A,这个函数A返回了一个函数B给你。这个返回的函数B就叫做闭包。你在调用函数A的时候传递的参数就是自由变量
In [1]: def f1(x):
...: def f2(y):
...: return x ** y
...: return f2
...:
In [2]: f3 = f1(2)
In [3]: f3(3)
Out[3]: 8
In [4]: f3(4)
Out[4]: 16
执行过程解释, f1 函数内部定义函数f2 ,当然此处的f2 函数没有执行,最后return的时候,返回的类型是函数,返回f2 但是没有给f2 传具体的参数。
注意: f2 和 f2()的区别
f2 表示函数名称或者函数的引用
f2() 表示函数的调用。
闭包的显著特征:
- 两个函数嵌套
- 外层函数返回内层函数
- 内层函数调用外层函数的变量
闭包写一个计数器
# encoding=utf-8
# 用闭包定义一个计数器
def counter():
num = [0]
def add():
num[0] += 1
return num[0]
return add
num = counter()
print num()
print num()
闭包写一个a*x +b 的函数
# a * x + b = y 如果是大量的替换x,但是a、b 不变的情况下,可以使用闭包解决
def aLine(a,b):
def arg(x):
return a * x + b
return arg
line = aLine(2,3)
y = line(2)
print y
print line(3)
print line(4)
print line(5)
装饰器
装饰器本身是一个函数,用于装饰其他函数
功能:增强被装饰函数的功能
装饰器一般接受一个函数对象作为参数,以对其进行增强
In [24]: def deco(func):
...: def wrapper():
...: print "plz say sometiong...."
...: func()
...: print "hello..."
...: return wrapper
...:
In [25]: @deco
...: def show():
...: print "showtime"
In [26]: show
Out[26]: <function __main__.wrapper>
In [27]: show()
plz say sometiong....
showtime
hello...
装饰器的演化
简单来看闭包和装饰器是很类似的,只是闭包传入的是变量,但是装饰器传入的是函数
#encoding=utf-8
import time
def timmer(func):
def wrapper():
startTime = time.time()
func()
endTime = time.time()
print "运行时间:%f s" % (endTime - startTime)
return wrapper
@timmer # 装饰器的函数
def sleep(): # 被装饰的函数
time.sleep(3)
类似闭包的引用,其实上面的写法就是下面闭包写法的简化版本,下面是一段伪代码
t1 = timmer(sleep())
t1()
不传参数的被装饰函数
#encoding=utf-8
import time
def timmer(func):
def wrapper():
startTime = time.time()
func()
endTime = time.time()
print "运行时间:%f s" % (endTime - startTime)
return wrapper
@timmer # 装饰器的函数
def sleep(): # 被装饰的函数
time.sleep(3)
sleep()
传参的被装饰函数
被装饰的函数add,可以认为是闭包的内部函数。所以传参的时候需要将被装饰的函数的变量传递给装饰器的内部函数。
#encoding=utf-8
def tip(func):
def tipNei(arg1,arg2):
print "start...."
func(arg1,arg2)
print "end....."
return tipNei
@tip
def add(a,b):
print a + b
@tip
def sub(a,b):
print a - b
add(1,2)
sub(2,1)
传参的装饰器
装饰器传参,需要在装饰器再加一个外部函数
#encoding=utf-8
def newTip(tipArg):
def tip(func):
def tipNei(arg1,arg2):
print "start....",tipArg,func.__name__ #func.__name__ 打印被装饰函数的名称
func(arg1,arg2)
print "end....."
return tipNei
return tip
@newTip("add_module")
def add(a,b):
print a + b
@newTip("del_module")
def sub(a,b):
print a - b
add(1,2)
sub(2,1)
生成器
In [3]: a = (i for i in range(0,10))
In [4]: a.next
Out[4]: <method-wrapper 'next' of generator object at 0x22f4370>
In [5]: a.next() #生成器取值
Out[5]: 0
生成器转化为列表
In [9]: list((i for i in range(12)))
Out[9]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
yeid 返回生成器对象
代码执行过程:
g1 = getNum(10) 只是产生一个生成器
g1.next() 执行一次,会执行一次函数getNum(),到达yield时结束。第二次执行g1.next()时,会从yield的下一句开始执行。
In [10]: def getNum(x):
...: i = 1
...: while i <= x:
...: yield i ** 2
...: i += 1
...:
In [11]: g1 = getNum(10)
In [12]: g1.next()
Out[12]: 1
In [13]: g1.next()
Out[13]: 4
In [14]: g1.next()
Out[14]: 9
递归
阶乘使用递归函数表示:
In [31]: def fact(n):
...: if n <= 1:
...: return 1
...: else:
...: return n * fact(n-1)
...:
In [32]: fact(3)
Out[32]: 6
In [33]: fact(4)
Out[33]: 24
汉诺塔的代码:
#!/usr/bin/python
def move(n,x,y,z):
if n == 1:
print "%d from %s to %s" %(n,x,z)
else:
move(n-1,x,z,y)
print "%d from %s to %s" %(n,x,z)
move(n-1,y,x,z)
num = input("input a number :")
move(num,'x','y','z')
函数的设计规范
耦合性:
1.通过参数接收输入,以及通过return产生输出以保证函数的独立
2.尽量减少使用全局变量进行函数间的通信
3.不要再函数中修改可变类型的参数。
4.避免直接改变定义在另外一个模块中的变量
聚合性:
1.每个函数都应该有一个单一的,统一的目标
2.每一个函数都应该相对简单
python内置函数
查看内存地址
id()
In [7]: a = 123
In [8]: b = 123
In [9]: id(a)
Out[9]: 34113616
In [10]: id(b)
Out[10]: 34113616
dir()
返回对象的属性。
In [9]: dir(str)
Out[9]:
['__add__',
'__class__',
'__contains__',
'__delattr__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getnewargs__',
'__getslice__',
'__gt__',
'__hash__',
....
]
globals()和locals()函数
根据调用地方的不同,globals()和locals()函数可被用来返回全局和 局部命名空间的名字。
如果在函数内部嗲用locals(),返回的是所有能在该函数里访问的命名
如果在函数内部钓鱼那个globals(),返回的是所有在该函数里能访问的全局名字
两个函数放回的类型都是字典,所以名字能用keys()函数摘取。
In [1]: sum = 100
In [2]: def fun():
...: num = 10
...: print locals()
...: print globals()
...:
In [3]: fun()
{'num': 10}
{'_dh': [u'/test'], '__': '', '_i': u'def fun():\n num = 10\n print locals()\n print globals()\n ', 'quit': <IPython.core.autocall.ExitAutocall object at 0x19a8910>, '__builtins__': <module '__builtin__' (built-in)>, '_ih': ['', u'sum = 100', u'def fun():\n num = 10\n print locals()\n print globals()\n ', u'fun()'], '__builtin__': <module '__builtin__' (built-in)>, '__name__': '__main__', '___': '', '_': '', '_sh': <module 'IPython.core.shadowns' from '/usr/lib/python2.7/site-packages/IPython/core/shadowns.pyc'>, 'sum': 100, '_i3': u'fun()', '_i2': u'def fun():\n num = 10\n print locals()\n print globals()\n ', '_i1': u'sum = 100', '__doc__': 'Automatically created module for IPython interactive environment', '_iii': u'', 'exit': <IPython.core.autocall.ExitAutocall object at 0x19a8910>, 'get_ipython': <bound method TerminalInteractiveShell.get_ipython of <IPython.terminal.interactiveshell.TerminalInteractiveShell object at 0x18f8f50>>, '_ii': u'sum = 100', 'In': ['', u'sum = 100', u'def fun():\n num = 10\n print locals()\n print globals()\n ', u'fun()'], 'fun': <function fun at 0x1d5db18>, '_oh': {}, 'Out': {}}
input 和raw_input 等待用户输入
文件处理
| 方法 | 作用 |
|---|---|
| open(“filename”,‘r’) | 打开文件 |
| read() | 读取文件 |
| readline() | 读取一行 |
| seek() | 移动文件内移动光标 |
| write() | 向文件中写入 |
| close() | 关闭打开的文件 |
打开一个文件并写入内容
f = open('test.txt','w') # ‘w’ 以写入的方式打开文件
f.write("tom")
f.write("jim")
f.close()
打开文件并读取里面的全部内容
f = open('test.txt','r')
print f.read()
f.close()
在文件最后追加文本
f = open('test.txt','a')
f.write("jessis")
f.close()
windows 中查看文件的内容
>type test.txt
tom
jim
jessis
逐行读取文件的内容
f = open('test.txt','r')
for line in f.readlines():
print line
print "#" * 10
f.close()
对文件的指针操作
文件的指针可以理解为是操作中的光标
f = open('test.txt','r')
print "指针的位置:" , f.tell() # 查看文件的指针
print "读取的内容:" , f.read(1) # 指针移动一个字符
print "指针的位置:" , f.tell() # 查看文件的指针
f.seek(0)
print "指针的位置:" , f.tell() # 查看文件的指针
print "读取的内容:" , f.read(1) # 指针右移动一个字符
f.seek(2,0) # 第一个参数2 表示偏移量,第二个参数 0 表示从文件的开头, 1,表示从当前位置偏移,2 表示从文件结尾偏移
print "指针的位置:" , f.tell() # 查看文件的指针
print "读取的内容:" , f.read(1)
f.seek(2,2) # 从文件末尾开始向有移动两个位置
print "指针的位置:" , f.tell() # 查看文件的指针
print "读取的内容:" , f.read(1)
f.seek(3,0)
print "指针的位置:" , f.tell() # 查看文件的指针
print "读取的内容:" , f.read(2)
f.close()
面向对象
面向对象的技术介绍
类(Class):用来描述具有相同的属性和方法的对象的集合,他定义了该集合中每个对象所共有的属性和方法,对象是类的实例,
对象:通过类定义的数据结构实例,对象包括两个数据成员(类变量和实例变量)和方法
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据
方法重载:如果从父类继承的方法不能满足子类的需求。可以对其进行改写,这个过程叫做覆盖(override),重载
实例变量:定义在方法中的变量,值作用于当前实例的类。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体外,类变量通常不作为实例变量的使用。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。
继承也允许把一个派生类的对象作为一个基类对象对待。
创建类
# cat employer.py
#!/usr/bin/python
class Employee:
"""
this is a test demo class
"""
classstr = "it is a test class"
def __init__(self,name,pay):
self.name = name
self.pay = pay
def hello(self):
"say hello"
print self.name
print 'say hello'
结果:
In [5]: import employer
In [6]: worker1 = employer.Employee('tom',10000)
In [9]: worker1.hello()
tom
say hello
In [10]: worker1.name
Out[10]: 'tom'
In [11]: worker1.pay
Out[11]: 10000
类中的三种方法:实例方法、类方法、静态方法
实例方法:一般是以self作为第一个参数,必须和具体的对象实例进行绑定才能访问。
类方法:以cls作为第一个参数,cls表示类本身,定义时使用@classmethod。那么通过cls引用的必定是类对象的属性和方法。
静态方法不需要默认的任何参数,跟一般的普通函数类似,定义的时候需要使用@staticmethod。静态方法中不需要额外定义参数,因此在金泰方法中引用类属性的话,必须通过类对象来引用。
而实例方法的第一个参数是实例对象self,那么通过self引用的可能是类属性,也有可能是实例属性,不妥在错在相同名称的类属性和实例属性的情况下,实例属性优先级更高。
###self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
实例
class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
创建实例对象
要创建一个类实例,你可以使用类的名称,并通过__init__方法接收参数。
创建对象的过程:
1.创建一个对象`Employee()`
2.python会自动调用`__init__()`方法
3.返回创建对象的应用给`worker1`
In [6]: worker1 = Employee('tom',10000)
访问属性
In [9]: worker1.hello()
tom
say hello
In [10]: worker1.name
Out[10]: 'tom'
In [11]: worker1.pay
Out[11]: 10000
n [11]: worker1.pay
Out[11]: 10000
In [12]: del worker1.pay # 删除'pay'属性
In [13]: worker1.pay = 2000 # 修改'pay'属性
In [14]: worker1.pay
Out[14]: 2000
对对象的属性和方法操作
getattr(obj,name[,default]) : 访问对象的属性
hasattr(obj,name):检查是否存在一个属性
setattr(obj,name,value):设置一个属性,如果属性不存在会创建一个新的属性
delattr(obj,name):删除属性
In [17]: hasattr(worker1,'name')
Out[17]: True
In [18]: hasattr(worker1,'pay')
Out[18]: True
In [19]: hasattr(worker1,'sex')
Out[19]: False
In [20]: getattr(worker1,'name')
Out[20]: 'tom'
In [21]: setattr(worker1,'name','jim')
In [22]: worker1.name
Out[22]: 'jim'
In [23]: delattr(worker1,'pay')
内置类属性
__dict__: 类的属性(包含一个字典,有类的数据属性组成)
__doc__: 类的文档字符串
__name__: 类名
__module__:类定义所在的模块(类的全名是'__main__.className'。如果类位于一个导入模块mymod中,那么className.__module__等于mymod)
__bases__:类的所有父类构成元素(包含了一个由所有父类组成的元组)
内置方法
| 序号 | 方法 | 作用 | 调用 |
|---|---|---|---|
| 1 | __init__(self[,args...]) |
构造函数,对象的初始化, | 简单的调用方法: obj = className(args) |
| 2 | __del__( self ) |
析构方法, 删除一个对象 | 简单的调用方法 : del obj |
| 3 | __repr__( self ) |
转化为供解释器读取的形式 | 简单的调用方法 : repr(obj) |
| 4 | __str__( self ) |
用于将值转化为适于人阅读的形式 | str(obj) |
| 5 | __cmp__ ( self, x ) |
对象比较 | 简单的调用方法 : cmp(obj, x) |
实例:
In [2]: class Person(object):
...: def __init__(self,name,sex):
...: self.name = name
...: self.sex = sex
...: def __str__(self):
...: return "%s is %s" %(self.name,self.sex)
...:
In [3]: tom = Person('tom','man')
In [4]: tom.__str__()
Out[4]: 'tom is man'
In [5]: str(tom)
Out[5]: 'tom is man'
In [7]: print tom #打印对象,直接调用__str__()
tom is man
类的继承
面向对象的编程带来的主要好处之一是代码的重用,继承完全可以理解成为类之间的父类型和子类型关系。
继承语法:
class 派生类名(基类名): //…基类名写在括号里,基类是在类定义的时候,在元组之中指明的。
在python中继承的一些特点:
1.在继承中的基类的构造(init()方法)不会自动调用,它需要在其派生类的构造中亲自专门调用。
2.在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量
区别在于在类中调用普通函数时并不需要带上self参数
3.python总是首先查找对应类型的方法,如果他不能再派生类中找到对应的方法,他才会到基类中逐个查找。
(先在本类中查找调用的方法,周不到才会到基类中查找)
如果在继承元组中列了一个以上的类,那么他就被称作"多重继承"
语法:
class SubClassName (ParentClass1[ParentClass2,…]):
“Optional class documentation string”
class_suite
#!/usr/bin/python
#coding=utf-8
class Parent:
parentAttr = 100
def __init__(self):
print "父类的构造函数"
def parentMethod(self):
print "调用父类方法"
def setAttr(self,attr):
Parent.parentAttr = attr
def getAttr(self):
print "父类属性:",Parent.parentAttr
class Child(Parent):
def __init__(self):
print "调用子类的构造方法"
def childMethod(self):
print "调用子类方法"
c = Child()
c.childMethod()
c.parentMethod()
c.setAttr(200)
c.getAttr()
结果:
调用子类的构造方法
调用子类方法
调用父类方法
父类属性: 200
在子类的构造函数中调用父类的方法
class Child(Parent):
def __init__(self):
Parent()
print "调用子类的构造方法"
def childMethod(self):
print "调用子类方法"
方法重载
#!/usr/bin/python
#coding=utf-8
class Parent:
parentAttr = 100
def __init__(self):
print "父类的构造函数"
def parentMethod(self):
print "调用父类方法"
def setAttr(self,attr):
Parent.parentAttr = attr
def getAttr(self):
print "父类属性:",Parent.parentAttr
def sayHello(self):
print "Parent hello"
class Child(Parent):
def __init__(self):
print "调用子类的构造方法"
def childMethod(self):
print "调用子类方法"
def sayHello(self):
print "Child hello"
c = Child()
c.sayHello()
p = Parent()
p.sayHello()
结果:
调用子类的构造方法
Child hello
父类的构造函数
Parent hello
类中重写
| 序号 | 方法 | 描述 | 简单调用 |
|---|---|---|---|
| 1 | init(self[,args…]) | 构造函数 | ClassName(args) |
| 2 | del(self) | 删除一个对象 | del obj |
| 3 | repr(self) | 转化为供解释器读取的形式 | repr(obj) |
| 4 | str(self) | 用于将值转化为适于人阅读的形式 | str(obj) |
| 5 | cmp(self,x) | 对象比较 | cmp(obj,x) |
#!/usr/bin/python
class Vector:
def __init__(self,a,b):
self.a = a
self.b = b
def __str__(self,):
return "Vector(%d,%d)" % (self.a,self.b)
def __add__(self,other):
return Vector(self.a + other.a,self.b + other.b)
v1 = Vector(10,3)
v2 = Vector(3,-2)
print v1 + v2
隐藏类的属性
如果一个对象,当需要对其进行修改时,有2种方法:
- 对象名.属性名 = 数据 ------> 直接修改
- 对象名.方法名() -------> 间接修改
为了更好的保护属性安全,即不能随意修改,一般的处理方法是,
- 将属性定义为私有属性
- 提供一个可以调用的方法
In [4]: class Person(object):
...: def __init__(self,name,age):
...: self.__name = name
...: self.__age = age
...: def set_age(self,age): #如果有需要可以做必要的判断等。
...: self.__age = age
...: def get_age(self):
...: return self.__age
...:
In [5]: tom = Person('tom',12)
In [7]: tom.get_age()
Out[7]: 12
In [8]: tom.set_age(13)
In [10]: tom.get_age()
Out[10]: 13
类的私有属性和方法
__private_attrs :两个下划线开头,声明该属性为私有,不能在类外部被直接使用或者直接访问。在类内部的方法中使用self.__private_attrs
####类的方法
在类的内部,使用def关键字可以为类定义一个方法,与一般函数的定义不同,类方法包括参数self,且为第一个参数。
类的私有方法
__private_method :两个下划线开头,声明该方法为私有方法。不能再类的外部调用。在类的内部调用self.__private_method
#!/usr/bin/python
class Person:
__color = 'yellow'
sex = 'man'
def print_col(self):
print self.__color
p1 = Person()
p1.print_col()
#!/usr/bin/python
class Student(object):
"2015 new students"
grade = 2015 #类属性
__school = "qinghua" #类的私有属性
def __init__(self,subj,name,age,sex): #构造函数,初始化对象的属性
"this is create fun"
self.subj = subj
self.name = name
self.age = age
self.sex = sex
def setName(self,newname): #普通方法,操作实例化对象的属性
self.name = newname
def getName(self):
return self.name
def showStudent(self):
print "subj=",self.subj
print "name=",self.name
print "age=",self.age
print "sex=",self.sex
print "grade=",Student.grade
print "school=",Student.__school
@classmethod #装饰器
def updategrade(cls,newgrade): #类方法,操作类属性
cls.grade = newgrade
@classmethod
def showClass(cls):
print "__name__=",cls.__name__
print "__dict__",cls.__dict__
print "__class__",cls.__class__
实例:不能让客户直接调用发送短信的功能,故需要配置私有函数,通过公共方法判断客户的余额。
#!/usr/bin/python
#coding=utf-8
class sendMessage(object):
#私有方法
#发送短信
def __send_msg(self):
print "----正在发送------"
#判断余额
def send_msg(self,money):
if money >= 1000:
self.__send_msg()
else:
print "------余额不足---------"
test = sendMessage()
test.send_msg(10000)
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特列方法,类似 init() 之类的。_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
类的使用-自定义with语句
class TestWith():
def __enter__(self):
'''__enter__类的内置函数,对象初始化的时候使用'''
print("init")
def __exit__(self, exc_type, exc_val, exc_tb):
'''__exit__ 类的内置函数,对象退出的时候使用'''
if exc_tb is None:
print("正常结束")
else:
print("异常是%s" %exc_tb)
with TestWith():
print("test is running...")
raise NameError("testNameError")
模块
如果开发程序需要由多个文件组成,只能提供一入口文件(顶层文件),其他的被包含的文件都应该只包含变量、函数、类
# cat print1.py
#!/usr/bin/python
def star():
print "*" * 20
def out():
print "#" * 20
import的工作机制
import导入对应的模块时会执行的三个步骤:
-
找到模块的文件
在指定的路径下搜索模块文件 -
编译成字节码
文件导入就会编译,因此顶层文件的.pyc字节码文件在内部使用后会被丢弃,只有在被导入的文件才会留下.pyc文件 -
执行模块的代码来创建其定义的对象
模块文件中的所有语句会一次执行,从头到尾,而且步骤中任何对变量名的赋值运算,都会产生所得到的模块的文件属性。
注意:模块的导入只在第一次导入时,才会执行如上步骤:
- 后续的导入操作只不过是提取内存中已加载的模块对象
- reload()用于重新加载模块
模块的搜索
python解释器在import模块时必须先找到对应的模块文件
- 程序的主目录(安装目录)
- PYTHONTPATH目录(如果设置了该系统变量)
- 标准链接库目录
- 任何.pth文件的内容
这四个组件组合起来即为sys.path所包含的路径,而python会选择在搜索路径中的第一个符合导入文件名的文件。
import语句
语法:
import module1,module2...
import module1 as module_alias
实例
从ipython中导入模块:
In [1]: import print1
In [2]: print1.star()
********************
In [3]: print1.out()
####################
from … import 语句
语法:
from modname import name1[,name2[,name3...]]
实例
从ipython中导入模块:
In [1]: from print1 import star,out
或者:from print1 import *
In [2]: star()
********************
In [3]: out()
####################
从模块中导入类
test1.py的内容
class A(object):
@staticmethod
def printStar():
print '*' * 5
test.py的内容
from test1 import A
A.printStar()
运行结果:
*****
从模块中导入类,直接调用类的静态方法。
__all__模块属性
>>> import timeit
>>> print dir(timeit)
['Timer', '__all__', '__builtins__', '__doc__', '__file__', '__name__', '__package__', '_template_func', 'default_number', 'default_repeat', 'default_timer', 'dummy_src_name', 'gc', 'itertools', 'main', 'reindent', 'repeat', 'sys', 'template', 'time', 'timeit']
>>> import timeit
>>> print timeit.__all__
['Timer']
注意:如果设置__all__ 属性,只会显示出该模块允许调用的属性。如果使用from model_name import * 只导入__all__属性中包含的函数或变量。如果没有__all__属性,会导入所有不以‘__’开头的属性。
__file__显示方法对应模块的存放位置
>>> import timeit
>>> print timeit.__file__
D:\python\python\lib\timeit.pyc
__name__ 变量
当模块被导入时,变量__name__代表的是模块的名称
In [1]: import mymode
In [2]: mymode.__name__
Out[2]: 'mymode'
如果模块自行执行,变量__name__代表的是__main__,常用于模块的自我测试。
#!/usr/bin/python
def print_star():
print 12*"*"
if __name__=='__main__':
print_star()
python包
包用于将一组模块归并到一个目录中,此目录为包,目录名为包名
- 包是一个有层次的文件目录结构,它定义了一个由模块和子包组成的python应用程序执行环境
- 基于包,python在执行模块导入时可以指定模块的导入路径
import dir1.dir2.mod1
目录结构如下图,则py_pkg_mod容器必须要在搜索目录中(该目录在sys.path中)
import pkg1.mode1
[root@miner-k test]# tree py_pkg_mod/
py_pkg_mod/
├── mode3.py
├── pkg1
│ ├── __init__.py
│ └── mode1.py
└── pkg2
├── __init__.py
└── mode2.py
包导入语句的路径中的每一个目录内都必须有__init__.py文件
__init__.py可以包含python代码,但通常为空,仅用于扮演初始化的挂钩,替目录产生模块命名空间以及使用目录导入时实现from行为的角色。
发布模块或程序
python模块、扩展和应用程序可以按照以下几种方式进行打包
-
压缩文件(使用distutils)
windows的zip文件和类Unix平台的.tar.gz文件 -
自动解包或自动安装可执行文件
windows中的.exe文件 -
子包含的,不要求安装的预备运行的可执行程序
windows的.exe文件、unix上带有一个小的脚本前缀的ZIP压缩文件、mac的.app文件等 -
平台相关的安装程序
windows上的.msi文件、Linux上的.rpm、src.rpm和.deb文件等
发布流程
- 将各代码文件组织到模块容器中
- 准备一个README或者README.txt文件
- 在容器中创建setup.py文件
| 参数 | 描述 |
|---|---|
| name | 包的名称(必须) |
| version | 版本号(必须 ) |
| py_modules | 各模块名称组成的列表,此些包位于包的跟目录下(modulename),也可能在某子包的目录中(subpkg1.modename) |
| platforms | 适用的平台列表 |
| packages | 各子包名称的列表 |
| license | 许可证 |
| author | 作者的名称 |
| author_email | 作者的邮箱地址 |
| maintainer | 维护者的名称 |
| maintainer_email | 维护者的邮件地址 |
| url | 包的主页 |
| description | 包的简单描述 |
| long_description | 包的详细描述 |
| down_url | 包的下载位置 |
| classifiers | 字符串分类器列表 |
-
打包成指定的格式
打包为源码格式 python setup.py sdist 可以指定sdist的格式: zip: zip file gztar: tar.gz file bztar: tar.bz2 file ztar: tar.z file tar: tar file 打包为二进制格式 python setup.py bdist 可以指定bdist指定格式: zip: zip file gztar: tar.gz file bztar: tar.bz2 file ztar: tar.z file rpm:RPM Package wininst:windows上的自解压zip格式的包 msi:Microsoft Installer
实例
创建一个目录
[root@centos7-2 test]# mkdir mymodule
创建一个README文件
[root@centos7-2 test]# touch README
创建一个setup.py文件
[root@centos7-2 test]# cat setup.py
#!/usr/bin/python
from distutils.core import setup
setup(
name = "xwp",
version = "1.0",
author = 'miner_k',
author_email = 'miner_k',
py_module = ['suba.aa','subb.bb'],
url = 'http://www.miner_k.com',
description = 'A simple module.',
)
# tree mymodule/
mymodule/
├── setup.py
├── suba
│ ├── aa.py
│ └── __init__.py
└── subb
├── bb.py
└── __init__.py
可省略
[root@centos7-2 mymodule]# python setup.py build
running build
running build_py
....
copying subb/__init__.py -> build/lib/subb
copying subb/bb.py -> build/lib/subb
构建后的目录结构
[root@centos7-2 mymodule]# tree
.
├── build
│ └── lib
│ ├── suba
│ │ ├── aa.py
│ │ └── __init__.py
│ └── subb
│ ├── bb.py
│ └── __init__.py
├── setup.py
├── suba
│ ├── aa.py
│ └── __init__.py
└── subb
├── bb.py
└── __init__.py
打包成指定格式
[root@centos7-2 mymodule]# python setup.py sdist
running sdist
...
hard linking subb/bb.py -> xwp-1.0/subb
creating dist
Creating tar archive
removing 'xwp-1.0' (and everything under it)
打包后生成对应的压缩包
[root@centos7-2 mymodule]# tree .
.
├── build
│ └── lib
│ ├── suba
│ │ ├── aa.py
│ │ └── __init__.py
│ └── subb
│ ├── bb.py
│ └── __init__.py
├── dist
│ └── xwp-1.0.tar.gz
├── MANIFEST
├── setup.py
├── suba
│ ├── aa.py
│ └── __init__.py
└── subb
├── bb.py
└── __init__.py
xwp-1.0.tar.gz 就是最后制作好的包
安装发布的包
[root@centos7-2 ~]# tar -xvf xwp-1.0.tar.gz
xwp-1.0/
xwp-1.0/setup.py
xwp-1.0/suba/
xwp-1.0/suba/aa.py
xwp-1.0/suba/__init__.py
xwp-1.0/subb/
xwp-1.0/subb/bb.py
xwp-1.0/subb/__init__.py
xwp-1.0/PKG-INFO
[root@centos7-2 ~]# cd xwp-1.0
[root@centos7-2 xwp-1.0]# python setup.py install
running install
running build
测试是否已经导入
In [2]: import suba.aa
In [3]: suba.aa.showa()
show aa
安装windows包
报错如下:
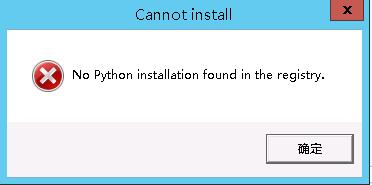
解决方法:
安装python并修改注册表
HKEY_LOCAL_MACHINE/SOFTWARE/Wow6432Node/Python/PythonCore/2.7/InstallPath
将上面的值复制到下面的值处
HKEY_LOCAL_MACHINE/SOFTWARE/Python/PythonCore/2.7/InstallPath
doctest 模块
doctest模块允许在文档字符串中嵌入注释以显示各种语句的期望行为,尤其是函数和方法的结果
[root@miner_k ~]# cat mymod.py
#!/usr/bin/python
#coding=utf-8
def sum(x,y):
'''
the sum of two numbers
>>> sum(1,2)
3
>>> sum(2,3)
5
'''
return x + y
In [1]: import mymod
In [2]: import doctest
In [3]: doctest.testmod(mymod)
Out[3]: TestResults(failed=0, attempted=2)
异常
python的运行中的错误称为异常
语法错误:软件的结构上有错误导致不能被解析器解析或不能被编译器编译
逻辑错误:由于不完整不合法的输出导致,也可能是逻辑无法生成、计算或者输出结果的过程无法执行等。
异常的检查和处理:
异常通过try语句来检查
try语句的两种形式
try-except:检测和处理异常
可以有多个except
支持使用else子句处理没有探测异常的执行的代码
try -finally:仅检测异常并做一些必要的清理工作
仅能有一个finally
try语句的复合形式
try - except -finally
try - except
语法:
try:
try_suite
except Exception[,reason]:
except_suite
reason变量的作用是接收异常的输出结果。
In [33]: try:
...: f1 = open('/tmp/abc.txt','r')
...: except IOError,reason:
...: print "can't find the file",reason
...:
can't find the file [Errno 2] No such file or directory: '/tmp/abc.txt'
In [34]: try:
...: f1 = open('/tmp/abc.txt','r')
...: except IOError:
...: print "can't find the file"
...:
...:
can't find the file
try-except-else
语法格式:
try:
try_suite
except Exception1[,reason]:
except_suite1
except (Exception2,Exception3...)[,reason]: #一次捕捉多个异常时,使用元组
except_suite1
except: #空except语句用于捕获一切异常
suite
else:
else_suite
except分句个数没有限制,但else只能有一个
没有异常发生时,else分句才会执行
没有符合的except分句时,异常会向上传递到程序中的之前进入try中或者到进程的顶层。
#!/usr/bin/python
#coding=utf-8
'''
除法运算
'''
try:
while True:
d1 = raw_input("An integer:")
if d1 == 'q':
break
d2 = raw_input("Another integer:")
print int(d1) / int(d2)
except ZeroDivisionError,reason:
print "Not 0"
except ValueError:
print "Not string"
except:
print "Error"
else:
print "....over...."
执行结果:
[root@miner_k test]# python divide.py
An integer:q
....over....
[root@miner_k test]# python divide.py
An integer:21
Another integer:2
10
An integer:ss
Another integer:1
Not string
[root@miner_k test]# python divide.py
An integer:1
Another integer:0
Not 0
try-finally 不做异常处理,向上抛出
try-except-else-finally
语法格式:
try:
try_suite
except Exception1[,reason]:
except_suite1
except (Exception2,Exception3...)[,reason]: #一次捕捉多个异常时,使用元组
except_suite1
except: #空except语句用于捕获一切异常
suite
else:
else_suite
finally: #是否有异常都会执行
finally_suite
raise语句显示触发异常
有异常就会终止程序的执行
语法格式:
raise [SomeException[,args[,traceback]]]
someException:可选,异常的名字,仅能使用字符串、类或者实例,必须是BaseException的子类
args:可选,以元组的形式传递给异常的参数
traceback:可选,异常触发时新生成的一个用于异常-正常化的跟踪记录,多用于重新引发异常时
In [5]: def links(st1,st2):
...: if not st1 or not st2:
...: raise ValueError,"args must not be empty"
...: return st1 + st2
...:
In [6]: links(s1,s2)
Out[6]: 'abcddjaooo'
In [7]: links(s1,'')
异常对象
python异常是内置的经典exception的子类实例
从python2.5之后,Exception是从BaseException继承的新类,故可以使用BaseException可以接收所有的异常。
In [9]: try:
...: i = 1 / 0
...: except BaseException,e:
...: print "not 0",e
...:
not 0 integer division or modulo by zero
大多数的异常都是由StandardError派生的。其中有3个抽象类
ArithmeticError
由于算术错误而引发的异常基类
OverflowError、ZeroDivisionError、FloatingPointError
LookupError
容器在接收到一个无效键或者索引时引发的异常的基类
IndexError、KeyError
EnvironmentError
由于外部原因而导致的异常基类
IOError、OSError、WindowsError
| 异常类 | 解 释 |
|---|---|
| AssertionError | 断言语句异常 |
| AttributeError | 属性引用或赋值失败 |
| FloatingPointError | 浮点型运算失败 |
| IOError | I/O操作失败 |
| ImportError | import找不到对应的模块 |
| IndentationError | 由于错误缩进引发的异常 |
| IndexError | 用来索引的整数超出范围 |
| KeyError | 用来索引映射的键不在映射中 |
| KeyboardInterrupt | 用户按了中断键(ctrl + c 、ctrl + break或者Del) |
| MemoryError | 运算耗尽内存 |
| NameError | 引用一个不存在的变量 |
| NotImplementedError | 由于抽象基类引发的异常,用于指示一个具有的子类必须覆盖一个方法 |
| OSError | 由模块OS函数引发的异常,用来指示平台相关的异常 |
| OverflowError | 整数运算的结果太多导致溢出 |
assert语句
语法:
assert condition[,expression]
如果condition条件满足,则assert不做任何操作
如果condition条件不满足,则assert使用expresstion作为参数实例化
注意: 如果运行python时,使用-O优化选项,则assert将是一个空操作:编译器不为assert语句生成代码
运行python时,不是使用-O选项,则__debug__内置变量为True,否则为False
assert语句相当于下面的代码
if __debug__:
if not condition:
raise AssertionError,<expression>
In [10]: assert 1 == 1
In [11]: assert 1 == 0
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-11-34d369bab8db> in <module>()
----> 1 assert 1 == 0
AssertionError:
In [12]: assert 1 == 0,' someting error'
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-12-56e4659653ba> in <module>()
----> 1 assert 1 == 0,' someting error'
AssertionError: someting error #表达式就是此处输出的结果
实例
从网站上下载一个网页
import requests
res=requests.get("http://www.baidu.com")
savefile=open("baidu.html","w")
savefile.write(res.content)
savefile.close()
生成激活码
#coding:utf-8
import string,random
#激活码中的字符和数字
field = string.letters + string.digits
#获取随机子母和数字的组合
def getRandom():
return "".join(random.sample(field,4))
#生成每个激活码的组数
def concatenate(group):
return "-".join([getRandom() for i in range(group)])
#生成激活码的个数
def genrante(n):
return [concatenate(4) for i in range(n)]
if __name__ == '__main__':
print genrante(3)
统计文本中单词的个数
#coding=utf-8
import re
from collections import Counter
File = "1.txt.txt"
def getWorldsCount(filesource):
"输入一个英文的纯文本文件,统计其中的单词的个数"
pattern = r"[A-Za-z]+|\$?\d+%?$"
with open(filesource) as f:
r = re.findall(pattern,f.read())
return Counter(r).most_common()
if __name__ == '__main__':
print getWorldsCount(File
python的调试
通过print输出执行过程的结果
错误代码如下,如果解决该错误代码可以在不同的阶段输出变量的值,判断错误的位置。
#conding=utf-8
num = [1,2,3,4,5,6,7,8,9]
def getArr(num):
new_arr = []
for i in num:
# print("num:",i)
if i % 2 == 0:
new_arr.extend(i)
return new_arr
if __name__ == '__main__':
print(getArr(num))