第25部分- Linux ARM汇编NEON基础知识
第25部分- Linux ARM汇编NEON基础知识
浮点指令除了VFP还有NEON。
NEON 支持整数、定点和单精度浮点 SIMD 运算。
NEON 是针对高级媒体和信号处理应用程序以及嵌入式处理器的 64/128 位混合 SIMD 技术。 它是作为 ARM内核的一部分实现的,但有自己的执行管道和寄存器组,该寄存器组不同于ARM 核心寄存器组。
VFP指令用FADD,NEON指令用VADD。
NEON指令集比VFP指令集更广泛,因此,尽管大多数VFP指令具有等效的NEON指令,但仍有许多NEON指令执行VFP指令无法执行的操作。
ARMv5开始引入了VFP(Vector Floating Point)指令,该指令用于向量化加速浮点运算。自ARMv7开始正式引入NEON指令,NEON性能远超VFP,因此VFP指令被废弃。类似于Intel CPU下的MMX/SSE/AVX/FMA指令。
VFP和NEON指令差异
| VFP Instruction |
Equivalent NEON Instruction |
Description |
| FADD[S|D]{cond} Fd, Fn, Fm |
VADD.[F32|F64] Fd, Fn, Fm |
Single and double precision add |
| FSUB[S|D]{cond} Fd, Fn, Fm |
VSUB.[F32|F64] Fd, Fn, Fm |
Single and double precision subtract |
| FMUL[S|D]{cond} Fd, Fn, Fm |
VMUL.[F32|F64] Fd, Fn, Fm |
Single and double precision multiply and multiply-and-negate |
| FNMUL[S|D]{cond} Fd, Fn, Fm |
VNMUL.[F32|F64] Fd, Fn, Fm |
|
| FDIV[S|D]{cond} Fd, Fn, Fm |
VDIV.[F32|F64] Fd, Fn, Fm |
Single and double precision divide |
| FABS[S|D]{cond} Fd, Fm |
VABS.[F32|F64] Fd, Fn, Fm |
Single and double precision absolute value |
| FNEG[S|D]{cond} Fd, Fm |
VNEG.[F32|F64] Fd, Fn, Fm |
Single and double precision negate |
| FSQRT[S|D]{cond} Fd, Fm |
VSQRT.[F32|F64] Fd, Fn, Fm |
Single and double precision square root |
| FCVTSD{cond} Fd, Fm |
VCVT.F32.F64 Fd, Fm |
Convert double precision to single precision |
| FCVTDS{cond} Fd, Fm |
VCVT.F64.F32 Fd, Fm |
Convert single precision to double precision |
|
|
VCVT.[S|U][32|16].[F32|F64], #fbits Fd, Fm |
Convert floating point to fixed point |
|
|
VCVT.[F32|F64].[S|U][32|16],#fbits Fd, Fm, #fbits |
Convert floating point to fixed point |
| FMAC[S|D]{cond} Fd, Fn, Fm |
VMLA.[F32|F64] Fd, Fn, Fm |
Single and double precision floating point multiply-accumulate, calculates Rd = Fn * Fm + Fd |
| There are similar instructions that negate the contents of Fd, Fn, or both prior to use, for example, FNMSC[S|D], VNMLS[.F32|.F64] |
||
| FLD[S|D]{cond} Fd,<address > |
VLDR{cond} Rd, < address > |
Single and double precision floating point load/store |
| FST[S|D]{cond} Fd,<address > |
LSTR{cond} Rd, < address > |
|
| FLDMI[S|D]{cond} < address >, < FPRegs > |
VLDM{cond} Rn{!}, < FPRegs > |
Single and double precision floating point load/store multiple |
| FSTMI[S|D]{cond} < address >, < FPRegs > |
VSTM{cond} Rn{!}, < FPRegs > |
|
| FMRX{cond} Rd |
VMRX Rd |
Move from/to floating point status and control |
| FMXR{cond} Rm |
VMXR Rm |
register |
| FCPY[S|D]{cond} Fd,Fm |
VMOV{cond} Fd,Fm |
Copy floating point register |
编译器编译可以选择。
禁用NEON启用VFP
编译器将生成用于单精度和双精度浮点运算的VFPv3指令
禁用VFP启用NEON
编译器将为SIMD整数运算生成NEON指令。 它不会生成NEON指令来向量化浮点运算。
如果未启用VFP,则不允许浮点NEON指令的动机是因为可以实现NEON的仅整数变量。 为了使NEON单元支持浮点运算,必须存在VFPv3协处理器。
启用NEON和启用VFP
在这种模式下,编译器将生成NEON和VFP指令的混合。 NEON指令可以是整数或浮点数。
NEON技术
Neon指令遵循如下的规则:
16x8-bit, 8x16-bit,4x32-bit,2x64-bit 整形操作
8x16-bit*,4x32-bit,2x64-bit 浮点操作
NEON指令
复制指令
VMOV:
两个arm寄存器和d之间
vmov d0, r0, r1:将r1的内容送到d0到低半部分,r0的内容送到d0到高半部分
vmov r0, r1, d0:将d0的低半部分送到r0,d0的高半部分内容送到r1
一个arm寄存器和d之间
vmov.U32 d0[0], r0:将r0的内容送到d0[0]中,d0[0]指d0到低32位
vmov.U32 r0, d0[0]:将d0[0]的内容送到r0中
通用算术指令
做neon乘法指令的时候会有大约2个clock的阻塞时间,如果要立即使用乘法的结果,则就会阻塞,在写neon指令的时候需要特别注意。乘法的结果不能立即使用,可以将一些其他的操作插入到乘法后面而不会有时间的消耗。
64位NEON指令和浮点指令
先来看下64位的NEON指令。是基于32位的NEON指令的。
加载LDR和存储STR指令还可以访问浮点/NEON寄存器。 此处,大小仅由加载或存储的寄存器确定,该寄存器可以是B,H,S,D或Q寄存器中的任何一个。
有如下的变化。
64位NEON变化
- 现在有32个128位寄存器,而不是16个可用于ARMv7的寄存器。
- 较小的寄存器不再打包到较大的寄存器中,而是一对一映射到128位寄存器的低位。单精度浮点值使用128位寄存器的低32位,而双精度值使用128位寄存器的低64位。
- ARMv7-A NEON指令中存在的V前缀已被删除。
- 向矢量寄存器写入64位或更少的位会导致高位被清零。
- 在AArch64中,没有对通用寄存器进行操作的SIMD或饱和算术指令。此类操作使用NEON寄存器。
- 添加了新的通道插入和提取指令以支持新的寄存器打包方案。
- 提供了用于生成或使用128位向量寄存器的高64位的附加指令。数据处理指令已分解为单独的指令,这些指令将生成多个结果寄存器(扩展到256位向量),或消耗两个源(缩小到128位向量)。
- 一组新的向量归约运算提供了跨行求和,最小值和最大值。
- 一些现有指令已扩展为支持64位整数值。例如,比较,加法,绝对值和求反,包括饱和版本。
- 饱和指令已扩展为包括“无符号累积到有符号”和“有符号到无符号的累积”。
- AArch64 NEON提供了对双精度浮点和完整IEEE754操作的支持,其中包括舍入模式,非规范化数和NaN处理。
64位浮点变化
- ARMv7-A浮点指令中的V前缀已替换为F。
- 支持单精度(32位)和双精度(64位)浮点矢量数据类型以及IEEE 754浮点标准定义的算术,同时支持FPCR舍入模式字段,默认NaN控件,“从零刷新”控件以及(在实现支持的地方)“异常”陷阱启用位。
- FP / NEON寄存器的加载/存储寻址模式与整数加载/存储相同,包括加载或存储一对浮点寄存器的功能。
- 添加了等于整数CSEL和CCMP的浮点FCSEL和选择和比较指令。浮点FCMP,FCMPE,FCCMP和FCCMP会根据浮点比较的结果设置PSTATE。{N,Z,C,V}标志依赖浮点比较,但是不会修改浮点状态寄存器中的条件标志( FPSR),如同ARMv7。
- 所有浮点乘法加法和乘法减法指令都已融合。融合乘法是在VFPv4中引入的,这意味着乘法结果在用于加法之前不会四舍五入。在较早的ARM浮点体系结构中,“乘累加”运算将对中间结果和最终结果都进行四舍五入,这可能会导致精度的少量损失。
- 在64位整数和浮点之间以及半精度和双精度之间提供了附加的转换操作。
将float转换为整数(FCVTxU,FCVTxS)指令可编码有向舍入模式:
—趋于零。
—朝+∞。
—朝–∞。
—与偶数关系最近。
—距离最近。
- 添加了具有浮点格式(FRINTx)的四舍五入到最接近的整数,具有相同的定向四舍五入模式以及根据环境四舍五入模式进行的四舍五入。
- 一种新的双精度到单精度下转换指令,具有不精确舍入到奇数的功能,适用于通过正确舍入(FCVTXN)正在进行的下转换到半精度的转换。
- 添加了FMINNM和FMAXNM指令,它们实现了IEEE754-2008 minNum()和maxNum()操作。如果操作数之一是NaN,则它们将返回数值。
- 添加了加速浮点向量归一化的指令(FRECPX,FMULX)。
寄存器:
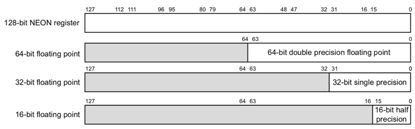
32×64位D寄存器D0-D31。 D寄存器称为双精度寄存器,
包含双精度浮点值。
32×32位S寄存器S0-S31。 S寄存器称为单精度寄存器,而
包含单精度浮点值。
32×16位H寄存器H0-H31。 H寄存器称为半精度寄存器,
包含半精度浮点值。
以上视图中的寄存器组合。