现在告诉你MySQL为什么选择B+Tree呢?
大家都知道MySQL数据库选择的是B+Tree作为索引的数据结构,那为什么会选择B+Tree呢?
本文分四种数据结构来分析:
二叉查找树
平衡二叉树
多路平衡查找树
加强版多路平衡查找树(B+Tree)
二叉查找树
二叉搜索树的特点:左子树的键值小于根的键值,右子树的键值大于根的键值。 
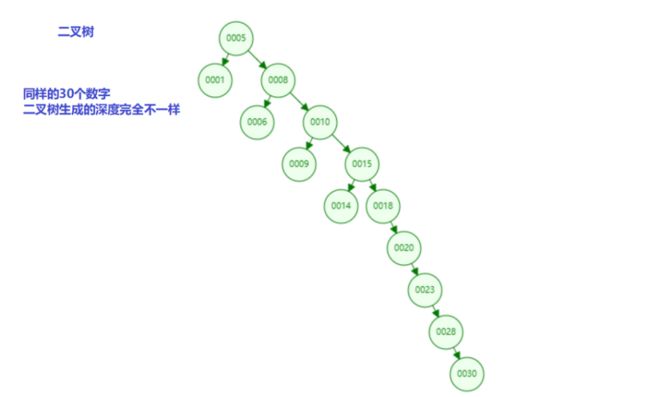 从上面的 2 个图来看,同样是 30 个数字,插入的数据顺序不一样,二叉树的结构完全不一样,图 1 里查找 30 需要 2 次检索的 IO 操作,但是在图 2 里查找 30 需要 7 次检索的 IO 操作,在图 2 里查找 30 类似于全表扫描。
从上面的 2 个图来看,同样是 30 个数字,插入的数据顺序不一样,二叉树的结构完全不一样,图 1 里查找 30 需要 2 次检索的 IO 操作,但是在图 2 里查找 30 需要 7 次检索的 IO 操作,在图 2 里查找 30 类似于全表扫描。
此处为什么说是一次检索就有一次 IO 呢,因为要查找的数据在文件里,需要从文件里读取出来加载到内存里进行数据比较,如果相等就返回,如果不相等,假设比要查找的数字大,需要接着往左边找;假设比要查找的数字小,需要接着往右边找。
以上可以看出,二叉树的数据检索取决于数据的分布情况,不适合用作索引的数据结构,因为二叉树的深度太深的话,IO 操作会特变多,查询效率就会很低,因此若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的,从而引出新的数据结构,平衡二叉树(Balanced Binary Search Tree)或者完全平衡二叉树(又叫 AVL 树)。
平衡二叉树
平衡二叉树(Balanced Binary Search Tree 树)在符合二叉查找树的条件下,满足某一个节点的子节点的高度差不超过 1,也就是相对平衡;如果整棵树的所有节点的高度差不超过 1 就是完全平衡二叉树(又叫 AVL 树)。 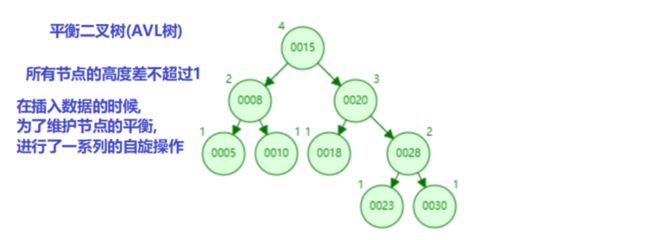 树节点的数据存储结构示意图:
树节点的数据存储结构示意图: 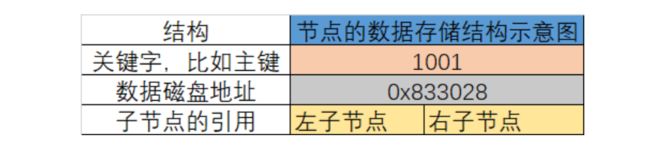 每个节点其实就是一个磁盘块,有 3 部分数据区,一个是关键字:用于存放主键或者其他索引的值,一个是数据磁盘块的地址,一个是子节点的引用,分别指向父节点的左子节点的引用和右子节点的引用。
每个节点其实就是一个磁盘块,有 3 部分数据区,一个是关键字:用于存放主键或者其他索引的值,一个是数据磁盘块的地址,一个是子节点的引用,分别指向父节点的左子节点的引用和右子节点的引用。
以上面的平衡二叉树的图片为例,通过查找关键字为 10 的数据记录,来说明节点的查找过程说明:
1、先找到节点 15,把节点 15 加载到内存后,与 10 比较,发现比 10 大,那么需要找到 节点 15 的左子节点,也就是节点 8;
2、通过节点 15 的左子节点的引用,找到节点 8,把节点 8 加载到内存后,与 10 比较,发现比 10 小,那么需要找到节点 8 的右子节点,也就是节点 10;
3、通过节点 8 的右子节点的引用,找到节点 10,把节点 10 加载到内存后,与 10 比较,发现正好匹配,那么说明要查询的数据就是节点 10;
4、通过节点 10 的数据磁盘地址,找到数据区,进行数据的获取,返回到客户端即可。
二叉树存在数据分布不均匀,出现查询深度太深,平衡二叉树解决了数据分布相对平衡的事情,但是用平衡二叉树作为索引的话还是有问题,原因主要有两个:
一个就是数据节点的深度决定了磁盘的 IO 操作次数,IO 操作非常消耗时间,从上图可以看出 9 条记录,如果查找 30 就需要 4 次 IO 操作,如果记录成千上万,这种 IO 操作是巨大的灾难。
另外一个就是平衡二叉树的节点磁盘块保存的数据量太少,它没有很好的利用操作系统读取磁盘 IO 的数据交互特性(操作系统去磁盘上读取的数据是 4KB,交互的单位是以页为单位的),以上的二叉树数据结构一个节点不可能用满 4KB 的空间;也没有利用好磁盘 IO 的预读能力(即空间局部性原理)(磁盘预读能力就是当你一次 IO 读取到数据的页后,会认为你马上要读取相邻的数据页,所以磁盘会多返回几个页的数据到内存),从而带来频繁的 IO 操作。
多路平衡查找树
多路平衡(B-Tree)是指每个节点可以有多个分支,也就是可以有多个子节点,二叉树就是 2 个子节点,有几个子节点就是几路。
多路平衡与二叉平衡相比,可以大大减少树的深度,从而减少 IO 的操作次数。
多路平衡查找树的节点里的关键字最多有(路数-1)个,如果用 N 来表示路数,那么关键字的个数最多就是 N-1 个。
InnoDB 存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB 存储引擎中默认每个页的大小为 16KB,可通过参数 innodbpagesize 将页的大小设置为 4K、8K、16K,在 MySQL 中可通过如下命令查看页的大小: show variables like 'innodb_page_size';
由于 MySQL 数据库里默认的一页是 16KB,因此在数据库设计的时候要特别注意,如果一个列的长度太大,该列用作索引时,占用的空间就大,那么以此列为索引的索引文件的路数就会减少,从而使树的深度增加,也就使 IO 的操作次数增加,导致数据库性能下降,这也就是人们常说的创建字段的时候,字段的长度尽量小一点,不要太大的原因。  B-Tree 是一个绝对平衡的查找树,也就是所有的子节点都在一个高度上,为了维持树的绝对平衡,在数据插入更新操作时,会通过一些分裂组合的操作来维持,这块也是比较消耗性能的,这也就是人们常说的索引建立够用就行,建立索引不易太多的主要原因。因为索引建多了,当数据插入或者更新的时候,维护索引的成本也是很大的。
B-Tree 是一个绝对平衡的查找树,也就是所有的子节点都在一个高度上,为了维持树的绝对平衡,在数据插入更新操作时,会通过一些分裂组合的操作来维持,这块也是比较消耗性能的,这也就是人们常说的索引建立够用就行,建立索引不易太多的主要原因。因为索引建多了,当数据插入或者更新的时候,维护索引的成本也是很大的。