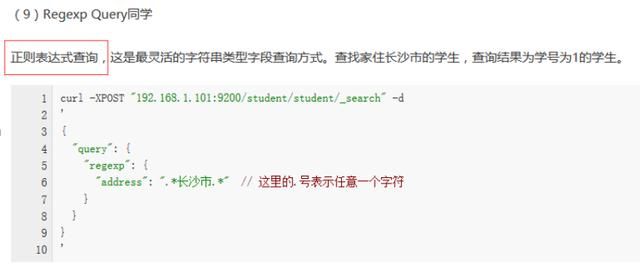
一丶elk日志搭建的原理,以及elasticsearch的查询语句都有哪些。
#查询集群是否健康
GET /_cluster/health
#关闭集群
GET /_cluster/nodes/_shutdown
#查看索引的详细字段
GET products/product/1/_source
#查看索引的mapping
GET products/product/_mapping
二丶相关的查询API
ES为用户提供两类查询API,一类是在查询阶段就进行条件过滤的query查询,另一类是在query查询出来的数据基础上再进行过滤的filter查询。这两类查询的区别是:
1、query方法会计算查询条件与待查询数据之间的相关性,计算结果写入一个score字段,类似于搜索引擎。filter仅仅做字符串匹配,不会计算相关性,类似于一般的数据查询,所以filter得查询速度比query快。
2、filter查询出来的数据会自动被缓存,而query不能。










三、mysql有哪些存储引擎以及这些存储引擎的区别。
四、各种集合类的使用,特别是分段锁的ConcurrenHashMap集合原理。
五、Linux经常的命令,大部分系统配置问在哪些目录下,介绍一个几个文件分别存储的配置作用,以及用户权限、组权限、其他的组权限的使用和配置。
六、Ssh和ssm框架的原理讲解,以及Struts和Springmvc的过滤器,拦截器的原理机制。
七、Linux亿万级别的日志,如何查询分段想要的日志。
答:
两个最基本的命令:
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
grep 简单使用
grep 'INFO' demo.log #在文件demo.log中查找所有包行INFO的行
grep -c 'ERROR' demo.log #输出文件demo.log中查找所有包行ERROR的行的数量
grep -v 'ERROR' demo.log #查找不含"ERROR"的行;
八、乐观锁与悲观锁的机制原理,并且在Mybetis如何实现锁,以及乐观锁。
九、同步代码如何实现,用在什么地方,要是在普通方法上加同步表示什么锁,要是在静态方法上用是什么锁。
十、http协议原理,包含哪些协议.
十一、el表表达式的使用,以及freemarker、thymeleaf模板的使用json数据或者接受后台返回的数据是如何进行显示的。
十二、Session在redis共享方式,有什么优点,有什么缺点。
十三、Ngins服务的使用,在哪里配置负载均衡,权重配置使用,多个tomcat的转发的配置
(1)weight:指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。weight越大,负载的权重就越大。
(2)ip_hash:
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
(3)fair:按后端服务器的响应时间来分配请求,响应时间短的优先分配。(第三方)
(4)url_hash:按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
十四、Tomcat如何做性能调优。
(1)tomcat内存优化:

(2)Tomcat线程优化:

(3)禁止DNS查询:

(4)设置session过期时间

(4)APR插件提高tomcat性能
Tomcat可以使用APR来提供超强的可伸缩性和性能,更好地集成本地服务器技术
十五、设置你们系统的代理级别对应商品的不同价格的表设计结构,在Mybetis中如何实现这个购买商品的逻辑,包括映射,以及配置sql以及参数传递和返回。
总结
以上是对大型企业面试题收集分享,分享给大家,希望大家可以了解什么是大型企业面试题。觉得收获的话可以点个关注收藏转发一波喔,谢谢大佬们支持。(吹一波,233~~)
学习Java的同学注意了!!!
学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入Java学习交流群346942462,我们一起学Java!