李宏毅学习笔记36.GAN.06.Feature Extraction
文章目录
- 简介
- InfoGAN
- What is InfoGAN?
- 结果
- VAE-GAN
- 具体算法
- BiGAN
- Algorithm
- Triple GAN
- Domain-adversarial training
- Feature Disentangle
简介
还有4个小主题。
这节主要讲特征的提取
公式输入请参考:在线Latex公式
InfoGAN
对于Regular GAN而言,我们很难从输入和输出中找到某种关联(Modifying a specific dimension, no clear meaning),例如下图中,每一列都是改变了输入的某一个维度,然后得到的结果,我们并不知道为什么第三行第六列为什么会突然多一个小尾巴。

(The colors represents the characteristics.)

InfoGAN就是要解决这个问题。来看它的概念:
What is InfoGAN?
来看流程,现有一个输入 z z z,和原始GAN不一样,这里把输入分为两个部分: c c c和 z ′ z' z′

然后经过Generator后,得到一个生成数据(图片) x x x,把生成数据丢到一个分类器中,分类器要从生成数据(图片) x x x中反推出原输入的 c c c

这里可以把Generator看做是encoder,分类器Classifier看做是decoder,两个组成一个“autoencoder”,这里的autoencoder是带引号的,因为
原来我们学过的autoencoder是将图片经过encoder变成编码,然后再把编码经过decoder变回图片。
这里是将编码经过encoder变成图片,然后再把图片经过decoder变回编码。
当然,模型中还要有Discriminator,不然就不叫GAN了

如果没有Discriminator,Generator为了让Classifer辨识出 c c c,直接就可以把 c c c贴到 x x x中,这样根本就没有训练到。所以加上Discriminator可以让输出的图片像真实图片。
在实作上由于Classifier和Discriminator都是吃同样的参数,所以,它们两个通常会share参数,只不过一个输出的是code,一个是scalar。
那么为什么加了Classifier可以work?因为只有在训练Generator的过程中,学习到了c影响x的关系,Classifier才能正确的从x中分辨出c来。

在图中我们看到还有一个 z ′ z' z′,这个东西代表一些随机的东西,就是我们也不知道这些东西影响输出的那些方面。
这里的c不是预先划分好的,而是应为我们设置了c,才训练出c影响了那些特征。
结果
原文结果如下(https://arxiv.org/abs/1606.03657):
第一维影响数字类型

普通GAN无特效

第二维影响角度

第三维影响笔画的粗细。

VAE-GAN
Anders Boesen, Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, Ole Winther, “Autoencoding beyond pixels using a learned similarity metric”, ICML. 2016
模型如下图所示,VAE部分的z应该还有一个normal分布的constraint没有画出来。
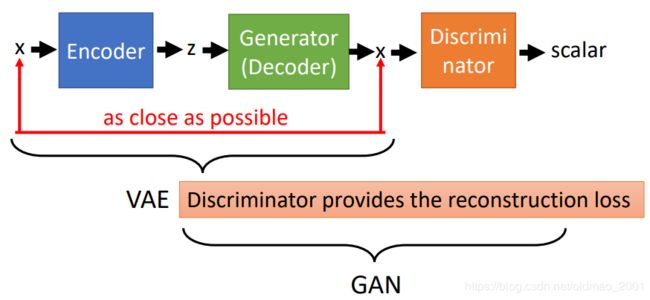
从VAE的角度来看:如果只是VAE追求输入x和decoder还原的x之间的reconstruction error的最小化,那么得到结果是不真实的(很模糊),具体可以看之前的VAE的讲解,那么加上Discriminator之后,可以促使生成的图片更加接近真实图片(否则不能通过Discriminator的分辨)。
从GAN的角度来看:Generator是看过真实的图片,并且要以还原真实图片为目标的,它并不单单是想要骗过Discriminator这么简单,所以加了VAE的GAN会比较稳。
上图中的三个东西的目标如下表:
| Encoder | Generator(Decoder) | Discriminator |
|---|---|---|
| ➢ Minimize reconstruction error ➢ z close to normal |
➢ Minimize reconstruction error ➢ Cheat discriminator |
➢ Discriminate real, generated and reconstructed images |
具体算法
• Initialize E n , D e , D i s En, De, Dis En,De,Dis初始化三个东西(都是network,有参数需要初始化)
• In each iteration:
• Sample M M M images x 1 , x 2 , ⋯ , x M x^1,x^2,\cdots,x^M x1,x2,⋯,xM from database(产生图片:真实数据)
• Generate M M M codes z ~ 1 , z ~ 2 , ⋯ , z ~ M \tilde z^1,\tilde z^2,\cdots,\tilde z^M z~1,z~2,⋯,z~M from encoder (产生code)
z ~ i = E n ( x i ) \tilde z^i=En(x^i) z~i=En(xi)
• Generate M M M images x ~ 1 , x ~ 2 , ⋯ , x ~ M \tilde x^1,\tilde x^2,\cdots,\tilde x^M x~1,x~2,⋯,x~M from decoder(产生reconstruction图片)
x ~ i = D e ( z ~ i ) \tilde x^i=De(\tilde z^i) x~i=De(z~i)
• Sample M M M codes z ~ 1 , z ~ 2 , ⋯ , z ~ M \tilde z^1,\tilde z^2,\cdots,\tilde z^M z~1,z~2,⋯,z~M from prior P ( z ) P(z) P(z)
• Generate M M M images x ^ 1 , x ^ 2 , ⋯ , x ^ M \hat x^1,\hat x^2,\cdots,\hat x^M x^1,x^2,⋯,x^M from decoder(从正态分布中生成图片:生成数据)
x ^ i = D e ( z i ) \hat x^i=De(z^i) x^i=De(zi)
• Update E n En En to decrease ∣ ∣ x ~ i − x i ∣ ∣ ||\tilde x^i- x^i|| ∣∣x~i−xi∣∣, decrease K L ( P ( z ~ i ∣ x i ) ∣ ∣ P ( z ) ) KL(P(\tilde z^i|x^i)||P(z)) KL(P(z~i∣xi)∣∣P(z))(1.Encoder的目标是使得输入图片( x i x^i xi)和Decoder得到的图片( x ~ i \tilde x^i x~i)的reconstruction error越小越好;2. x i x^i xi产生的 z ~ i \tilde z^i z~i和正态分布越接近越好,这个是VAE的规定)
• Update D e De De to decrease ∣ ∣ x ~ i − x i ∣ ∣ ||\tilde x^i- x^i|| ∣∣x~i−xi∣∣, increase D i s ( x ~ i ) Dis(\tilde x^i) Dis(x~i) and D i s ( x ^ i ) Dis(\hat x^i) Dis(x^i)(1.Decoder的目标是是使得输入图片( x i x^i xi)和Decoder得到的图片( x ~ i \tilde x^i x~i)的reconstruction erro越小越好;2.生成的图片【 x ~ i \tilde x^i x~i是reconstruction 的图片, x ^ i \hat x^i x^i是直接生成的图片】丢到Discriminator里面,得到的值越大越好)
• Update D i s Dis Dis to increase D i s ( x i ) Dis(x^i) Dis(xi), decrease D i s ( x ~ i ) Dis(\tilde x^i) Dis(x~i) and D i s ( x i ) Dis(x^i) Dis(xi)(Discriminator对于真实的图片 x i x_i xi分数要越高越好,生成的图片【 x ~ i \tilde x^i x~i是reconstruction 的图片, x ^ i \hat x^i x^i是直接生成的图片】分数越低越好)
这里的Discriminator是二分类(区分真实和生成图片),还有一种做法是做成三分类的分类器:

BiGAN
先把VAE部分拆开,变成:

拆开之后的Encoder和Decoder是完全分开的,Decoder的输入不是根据Encoder的输出来的,而是从一个正态分布中生成图片,两个东西最后如何训练?通过Discriminator:

把图像和代码分别丢到Discriminator中,Discriminator判别是Encoder还是Decoder。
Algorithm
• Initialize encoder E n En En, decoder D e De De, discriminator D i s Dis Dis
• In each iteration:
• Sample M M M images x 1 , x 2 , ⋯ , x M x^1,x^2,\cdots,x^M x1,x2,⋯,xM from database(产生图片:真实数据)
• Generate M M M codes z ~ 1 , z ~ 2 , ⋯ , z ~ M \tilde z^1,\tilde z^2,\cdots,\tilde z^M z~1,z~2,⋯,z~M from encoder (产生code)
z ~ i = E n ( x i ) \tilde z^i=En(x^i) z~i=En(xi)
• Sample M M M codes z 1 , z 2 , ⋯ , z M z^1, z^2,\cdots, z^M z1,z2,⋯,zM from prior P ( z ) P(z) P(z)
• Generate M M M images x ~ 1 , x ~ 2 , ⋯ , x ~ M \tilde x^1,\tilde x^2,\cdots,\tilde x^M x~1,x~2,⋯,x~M from decoder(产生reconstruction图片)
x ~ i = D e ( z i ) \tilde x^i=De( z^i) x~i=De(zi)
• Update D i s Dis Dis to increase D i s ( x i , z ~ i ) Dis(x^i,\tilde z^i) Dis(xi,z~i), decrease D i s ( x ~ i , z i ) Dis(\tilde x^i,z^i) Dis(x~i,zi)(一个高分一个低分)
• Update E n En En and D e De De to decrease D i s ( x i , z ~ i ) Dis(x^i,\tilde z^i) Dis(xi,z~i), increase D i s ( x ~ i , z i ) Dis(\tilde x^i,z^i) Dis(x~i,zi)(骗过Discriminator,一个低分一个高分)
Discriminator实际上在evaluate两组data是否接近,可以把上图中的Encoder的输入输出看成一个joint distribution P ( x , z ) P(x,z) P(x,z),把上图中的Decoder的输入输出看成一个joint distribution Q ( x , z ) Q(x,z) Q(x,z),那么Discriminator就是Evaluate the difference between P and Q.最后的理想结果是: P and Q would be the same. 然后就会有:

世界大同,不多解释。
既然Discriminator存在的是为了使得Encoder和Decoder输入和输出的分布相同,那么能否使用如下模型:
用VAE,左边是输入图片还原图片,右边是输入code还原code(反向AE),两边的目的都是使得reconstruction error越小越好。

可以看到上面的模型也可以达到使用Discriminator+VAE的结果,为什么还要加入GAN?
从结果上看两个VAE的结果是模糊的(因为优化的结果会有误差,reconstruction error不可能为0),输入一只鸟得到一只同样的模糊的鸟,而BiGAN输入一只鸟,得到另外一只鸟。
Triple GAN
Chongxuan Li, Kun Xu, Jun Zhu, Bo Zhang, “Triple Generative Adversarial Nets”, arXiv 2017

蓝色是Discriminator,黄色是Generator,绿色是Classifier。
如果不看Classifier,就是一个conditional GAN。输入一个东西(文字),按条件生成另外一个东西(图片)。
G吃一个condition: Y g Y_g Yg,然后产生一个 X g X_g Xg,然后把 ( X g , Y g ) (X_g,Y_g) (Xg,Yg)丢到Discriminator里面,D要分辨 ( X g , Y g ) (X_g,Y_g) (Xg,Yg)是生成数据,从数据库里面sample出来的数据是真实数据。
加了一个Classifier后,整个Triple GAN类似semi-supervisor learning:
在数据中,我们只有少量的labeled data( ( X , Y ) (X,Y) (X,Y)),大量的unlabel data(单独的 X , Y X,Y X,Y),可以看到Classifier可以学三部分的东西:
1.丢 X X X,得到 ( X , Y ) (X,Y) (X,Y)
2.学习数据中本身的 ( X , Y ) (X,Y) (X,Y)
3.学习G吃 Y g Y_g Yg生成的 ( X g , Y g ) (X_g,Y_g) (Xg,Yg)
可以看到,无论是单独的 X , Y X,Y X,Y都可以学习到对应的 ( X , Y ) (X,Y) (X,Y),制造了大量的training data。然后Discriminator会判断Classifier生成的 ( X , Y ) (X,Y) (X,Y)与真实的 ( X , Y ) (X,Y) (X,Y)是不是很像。
Domain-adversarial training
当训练数据和测试数据不太一样(不同分布)的时候,直接用训练出来的模型会翻车。
这块内容有讲,就是Transfer learning
不多解释,后面要用到

This is a big network, but different parts have different goals.
这里注意一下,虽然论文中是三个模块(network)一起train的,但是分开迭代train会比较稳(先训练Domain Classifer,再训练feature extractor)。

用这个技术可以用来实现下面这个技术:Feature Disentangle
Feature Disentangle
为了讲清楚这个东西,我们用语音为例,这个技术也可以用在图像处理等方面。
假设我们训练一个语音的AE,Original Seq2seq Auto-encoder

把一段声音信息压缩为code,在把code还原回声音信号。目标是input和ouput越接近越好。中间抽取出来的code我们希望它能够代表这段声音信息的特征,但是这个是不可能的,因为这一段声音信息还包含了其他信息,如:说话人的信息、环境的信息。
因此我们想要知道在这个code中那些维度代表了发音的信息,不包含其他信息。这里就是要用到Feature Disentangle的技术。
从字面上理解Disentangle是解开的意思,各种信息的特征交织打结在一起,要把它解开。这样我们就知道那些维度代表发音的信息,哪些维度代表语者的信息。
具体做法:

train两个Encoder,一个学习语音信息,一个学习语者信息。这样训练出来的语音Encoder可以处理与人无关的语音,直接提取出语音特征;训练出来的语者Encoder可以用来做为识别语者身份的声纹特征。
如何分布训练上面两个Encoder?
先看训练语者信息的Encoder,这个时候Assume that we know speaker ID of segments.
我们假设我们知道那些声音信号是来自同一个语者,这个很好弄,可以把同一个人说的话切开,变成几个小段语音,就得到同一个人说的不同语音。
如果两个语音来自相同的人(说的语音内容不一样,但是说话的人是同一个),我们希望下图中两个语者信息的Encoder的输出越接近越好:

如果两个语音来自不同的人(说话的人不是同一个),我们希望下图中两个语者信息的Encoder的输出越不同越好(接近某个阈值):

但是上面的模型中Encoder得到的code也是可以包含语音信息的,不单单是语者信息。这里就要用到Domain-adversarial training
训练一个Speaker Classifier,用来分辨两个code: z i , z j z^i,z^j zi,zj是不是同一个语者的声音。Encoder要想办法骗过Classifier。

论文的结果如下图,不多解释,左边两个是针对语音,右边两个是针对语者。
