Pivotal Greenplum ——全世界首个开源、多云数据平台,专为高级分析而打造。作为一个开放的数据计算平台,它集成了对数据进行挖掘和分析的高级功能,通过这些功能,用户可以直接在Greenplum数据库里使用高级分析算法,对数据进行分析和处理。
本篇文章将从最近较热的人工智能应用场景说起,详细为大家介绍如何运用Greenplum的内置算法进行机器学习,帮助企业或用户从1到N,快速处理分析海量数据,获得行业洞察。

Greenplum库内集成的高级分析功能
首先来讲Greenplum,我相信大家对Greenplum多少有些了解。Greenplum是一个MPP架构的分布式数据库,其特点是可以做非常大规模的数据计算,它可以在几百个节点的服务器规模的集群内做数据的拓展,并且可以在PB级,就是一千个T或者几千个T的数据容量上,做快速的数据存储和计算。传统来讲,它是一个数据库,但实质上Greenplum不只是一个数据库,因为我们在库内集成了很多高级分析的功能。这些高级分析的功能,可以使用户更方便的使用数据,因为数据本身要进行挖掘才能产生价值,对于传统的友商,比如说像Oracle、MySQL或者SQLServer这样的数据库产品来讲,它可能只是一个数据库,您只能对数据进行传统的,基于SQL的分析。但在Greenplum,作为一个开放的数据计算平台,我们在库内集成了非常多的数据挖掘和分析功能,通过这些功能,您不再需要把数据从库内拿出来,直接在Greenplum数据库里就可以使用高级分析算法,对数据进行分析和处理。
在Greenplum内部我们集成了对地理信息的处理算法包、对文本处理的组件、对Python或者R等一些数据科学家使用的算法包、图计算算法包以及机器学习的算法包等等。今天重点要介绍的就是Greenplum库内集成的机器学习算法包和文本处理组件。通过这种库内的集成算法,客户可以直接在库内对数据进行挖掘,不用把数据搬进搬出数据库,从而提高数据的使用效率,降低数据挖掘的成本。
目前Pivotal研发人员正在试图实现对集成深度学习算法库内集成,接下来我们一起看下Greenplum目前在对机器学习领域的已有功能以及正在研发的路线图。
可扩展的机器学习算法库:MADlib
在Greenplum里面集成的基于机器学习或者人工智能分析的算法包,叫MADlib。您也许听说过MADlib扩展包,这个扩展包已经是apache基金会顶级开源项目,这个组件里面集成了大量的基于传统数学分析统计的算法、图计算的算法以及一些常见的机器学习的算法。


MADlib 可扩展的机器学习算法库
这个算法库直接在库内集成,您可以直接到MADlib.apache.org 的网站上下载,然后在Greenplum或者Postgres数据库里部署。因为Greenplum是跟Postgres社区是深度整合的,所以我们这个MADlib算法库会提供Postgres和Greenplum的版本。
MADlib的发展历程
简单说一下MADlib的发展历程。 MADlib是Pivotal从2011年就开始的产研结合项目,公司跟UC伯克利大学的Hellerstein教授一起合作开发的。到今天为止,包括UC伯克利、斯坦福、维斯康辛、佛罗里达大学等众多知名高校中的很多教授或科研人员,都加入了这个项目,为它做出持续的贡献,因此也是一个非常好的产研结合案例。
目前,我们已经实现的在库内集成的算法包括哪些呢?在机器学习方面,有监督学习算法,比如支持向量机;回归类的算法,比如逻辑回归、线性回归、聚类;树型模型,比如随机森林、决策树等。现在的MADlib1.5版本里,已经完全集成上述算法可以直接接下载并在库内运算。
 MADlib 算法库
MADlib 算法库
除了机器学习算法,MADlib还包括Graph处理,比如最短路径,图形直径等等算法,此外还有一些效用函数、线性求解,或者传统的统计分析类的汇总函数、统计分析函数、交叉验证选型函数,都在库内集成,非常方便。
如果您之前使用过相关机器学习算法,可能会用到随机森林或者决策树这样的模型,或者用Python的库函数包,用的时候需要把存储在数据库里(如Oracle)的数据抽出来,抽取到一个文本或者图形化工具里面,然后再用Python程序对数据进行处理。有了这个算法库之后,就不需要把数据来回倒腾,直接把数据存在Greenplum里面,在Greenplum里面使用这些算法库,可以直接对这些数据进行模型训练、预测或者是评估操作,会大大简化操作过程。
此外我们整个算法都是集成在SQL接口里面的,可以非常方便的使用SQL语句,像调用函数一样来调用这些模型的训练,可以直接把您数据表的名字作为一个参数,您要分析的数据列也作为一个参数,那些模型需要调整的参数作为参数直接传到函数里面,然后直接用SQL语法就可以完成训练,使用起来非常简便,学习成本低。
1+1>2:MADlib+Greenplum的优势
接下来您可能会问,MADlib加上Greenplum的优势到底是什么?传统来讲,这些算法都是公开提出的一些paper,经过漫长工业界的使用,形成了算法库,有Python算法库,有R算法库,包括MADlib也是一种算法库。包括神经网络、随机森林的模型,都是八九十年代的算法,最终进行工业化落地的产品。您可能做了很多Python方面的编程。那么用MADlib和Greenplum究竟有什么样的优势呢?
首先,Greenplum是一个MPP架构的分布式计算的框架,Greenplum+MADlib之后,就等于我们在MADlib的基础上把MADlib放到了一个分布式计算框架的里面,这样做的好处就是我们可以并发对很大规模的数据进行模型训练或者统计分析计算。而在一个单机分析体系里,是没有办法实现的。通过这样的结合,算法并发度更好,因为作为Greenplum来讲,我们的数据是分散存储在不同节点上的,一些算法也可以在不同的节点上对部分数据进行计算、训练,再把最后的结果汇总后返回,这样就会有一个非常好的并发度和扩展性。
这两个功能可以使我们获得更好的预测精度。因为在做模型训练的时候,如果没有像Greenplum+MADlib这样的架构的话,就只能做采样模型训练,不能使用全量数据。比如您有一百亿条数据,可能训练模型的时候只能使用其中的一百万或者一千万条数据做训练,然后再用这个模型去对一百亿条数据进行预测,这个模型和预测的结果肯定准确度不如有条件做一百亿条训练出来的模型那么准确。
我们在MADlib+Greenplum的架构下面,由于分布式存储、分布式计算框架,您可以把数据直接在Greenplum的分布式存储计算结构里面进行模型训练,也就是说可以用全量数据进行模型训练,这样一来预测的精度肯定会比用部分采样数据高得多。这就是我们说的,如果采用MADlib+Greenplum分析平台可以得到的好处。
前面我们也提到了很多算法,而传统的机器学习的算法,比如向量机或者随机森林等算法,在CPU上都可以得到很好的模型训练。但对于一些深度学习的算法,在CPU上已经没有办法很好的支持这种算法的模型的训练了,包括一些预测。因为神经网络的算法需要消耗大量的算力,需要大量的计算节点同时工作,才能够满足这种计算的要求,所以我们在Apache MADlib1.5的版本上面,主要是集成了在CPU上能够很好处理的算法。

Greenplum支持的数据科学分析算法
还有一部分是深度学习的算法,可能需要在基于GPU的计算框架下才能够发挥它的优势,或者说才能真正跑起来。我们正在做的Apache MADlib2.0里,就在试图把这些深度学习的算法也集成到MADlib库里边。比如卷积神经网络、循环神经网络,长短期记忆的模型,生成式的对抗网络等模型。而为了更好的支持这些算法,还我们会在整个计算框架上有一些调整从而来实现GPU加速等,这些是我们目前研发的重点方向。
人工智能算法概览
下面跟大家介绍一下人工智能和机器学习的关系图谱。人工智能是一个非常大的范畴,它可能包括诸多领域的高深理论。而目前现在在工业界和IT行业能够落地实现的,主要是指机器学习,通过机器学习实现部分人工智能应用的方法,机器学习仅仅是人工智能的一部分实现。机器学习包括传统的机器学习,像前面提到的随机森林、树型、向量机、线性回归、逻辑回归等等上世纪提出的一些算法的模型,以及近些年提出的深度学习算法。

人工智能算法概览
深度学习算法是试图模仿生物大脑的工作原理,大脑工作原理里有很多神经元,有一层一层的网络,通过输入、输出,以及中间很多层级的网络处理,让每一层的输出是基于上一层的输入来计算得到分层次学习的概念,可能算法会非常复杂。
深度学习是机器学习的一部分,机器学习是人工智能的一部分,而我们在做数据分析或者数据挖掘的时候,管自己叫数据科学家或者数据分析员。数据科学里面使用了很多深度学习的算法和机器学习的算法,包括其他人工智能领域的传统数据统计分析的算法和方法论。包括Pivotal也有很好的数据科学团队,来帮助您怎么样用、用什么样的模型、什么样的方式更好的来做数据的挖掘和创作。

常见深度学习算法
常见的深度学习算法有多层感知器(MLP),MLP是上世纪90年代的算法模型,它是一个最初级的浅层的神经网络模型,当时该模型的整个计算框架和理论模型被向量机模型逐渐取代,MLP也不能叫完全的深度学习。但它的确是一个模拟人脑工作的方式,是一个浅层的神经网络的算法。随着这几年深度学习慢慢火热起来,MLP也逐渐重新回到人们的视野中。
此外,递归神经网络和卷积神经网络是目前比较常见的深度学习算法,卷积神经网络在图像识别领域,主要做一些模式的匹配。递归神经网络的算法,主要用于语义的分析、自然语言处理用得比较多。前面我们讲的长短期记忆模型,也是对递归神经网络算法的一个加强。
目前,数据挖掘分析来说,深度学习算法在这些领域,比方说对自然语音的识别,包括对视觉处理,对图像识别、模式匹配,包括对视频流的建模和处理,包括对翻译自然语言语义的分析,以及对生物学的预测和探索,会应用得比较广泛。
但是所有这些算法并不是每一个领域都可以拿来就用的,它只是一个工具,大家需要根据不同的领域、不同的数据类型、不同的应用来选择。至于说怎么用这个工具,比如把语音识别这样的业务处理好,其实还是需要很多的打磨。
采用GPU加速的数据库实现方式
前面我们提到的深度学习算法,很多是基于一个前提的,即现在的CPU处理很难满足深度学习算法的算力要求,因为深度学习算法很多程度上需要用大量的数据去训练模型,这样这个模型才能更好的学习或者预测的更精确。大量的数据训练就不是CPU擅长的工作方式,CPU的工作方式是面向延时的,要求延时非常低。而GPU的工作方式是面向吞吐量的,通过很小的处理核加上很小的缓存,进行大量的相对简单的数据计算。所以说深度学习算法很多时候是依赖于GPU加速的方式,才能很好的进行训练和使用。
采用GPU加速的数据库实现方式
加速所有查询的性能 :
- 通常都是从数据底层实现的彻底改变。
- 例如:Kinetica, MapD, SQream, Blazegraph, BlazingDB, Brytlyt, PG-Strom
针对特定深度学习算法的加速 :
- 在现有数据库基础上对特定算法的扩展,对企业来说更容易适应。
- 例如:Greenplum with Apache MADlib
因此在异构计算方面,其实也有不同的路径。包括现在基于GPU加速的内存数据库产品,通常从整个数据库的底层算法开始做GPU加速。通过用GPU对大批量数据的同时的计算,来加快数据处理的过程,是对从下至上整个数据库的完全的改造。比如SQream,MapD等等基于GPU的数据库产品。
还有一种是现在Pivotal的想法,在现有的数据库基础上对特定的算法进行GPU加速扩展,怎么说呢?就是对传统的SQL、比如传统的哈希等,因为其性能已经在很大程度上满足了企业级应用的要求性能,CPU的算力上已经足够了。但是对于深度学习的算法,CPU是没办法满足算力要求的,所以我们就针对Apache MADlib2.0里面的深度学习算法,对这些特定的深度学习算法进行GPU的加速。通过这样一种组合方式,能够给用户提供更好的体验,而且整个适应的过程和成本都是最低的。因为一般的业务或者非深度学习类的业务,还是跑在CPU的计算的平台上面。而对深度学习的算法,是跑在GPU新的算力平台上面的。通过这样一种结合的方式,就可以提供更加强大的计算平台给到企业客户。
常规训练深度学习算法的模型是这么一个架构,会在一台机器上插多块GPU的处理卡,这是常规进行深度学习算法训练的体系架构。
Greenplum现在的架构是,没有GPU卡,但是是一个MPP的架构,存储、CPU都可以通过MPP算法把一个大的集群整合起来。如果把MPP架构和GPU的算力整合起来,会是什么效果呢?那就是在集群内部,每一台节点上都可以插一块到多块GPU,大家可以想象一下,如果是这样一种架构的话,能够进行多大规模的深度学习的模型的训练,或者预测。对客户来讲,包括对深度学习整个算法体系来讲,可能都是一个非常好的平台架构,可以直接在库内对这些深度学习算法,进行全量数据的加速的模型训练、预测、评估的整套过程。
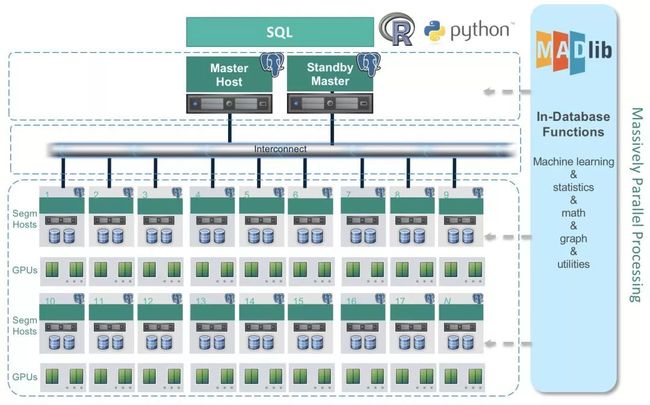
大规模集群计算
当然这个是我们现在正在研发、正在做的部分。在实现了以上想法之后,我们可以通过用对库内内置的R和Python这样的语言,直接对GPU进行一些处理,深度学习算法直接把这些负载分配到GPU上,而对传统的数据库操作还在CPU里计算,这样的体系架构才是值得期待的。即在一个非常大的规模上进行扩展的计算,大规模集群计算的情况下,以后的想象空间是非常诱人的。
当前Pivotal在深度学习库内挖掘这部分的主要研发方向是研究在MADlib里面实现使用GPU加速的深度学习算法在Greenplum里面落地。尤其是Keras,Keras是一个算法库,是跑在Tensorflow上面的算法库、算法包,我们希望把Keras里面的这些算法能够集成到MADlib2.0里面去,同时因为Keras这些深度学习算法真的需要GPU加速才能很好的使用,毕竟GPU算力跟CPU还是有量级上的区别。我们需要把Keras集成到MADlib产品里面去并通过GPU加速它的落地。
我们目前也可以在Greenplum里用Tensorflow或者keras的算法。比如您可以直接把Tensorflow和keras装到Greenplum里面,用Python来调算法库里的内容,但是可能有些算法是跑不出来的,因为没有GPU加速,并且很多算法没有办法进行分布式计算,还需要后续算法的优化。
我们研发的方向会有两个主题,一个是在真的需要大量数据做建模和分析的时候,需要把keras里面相应的一些算法做一个分布式的处理,这样就可以把算力分配到整个集群上去,也是前面说的,实现一个全量数据或者大量数据处理的方式。
当前的研发方向
- 积极探索在madlib中实现通过GPU加速的深度学习算法在Greenplum中落地的可能。
- Keras是当前工作的重点。
- 主题:
– 分布式的算法模型
– 并发数据的算法模型
此外,另一个是需要并发性的,比如有的数据可以按照国家或者一定的字段进行分组,可以建立很多个模型同时对不同的数据进行处理,每个模型可能放在一个节点上去做。其实这两块都是可能会对当前正在做的方向。
前面我们讲述的都是MADlib这部分,集成了机器学习的机器学习、数据分析的算法库,非常简便易用。
结构化分析与非结构化分析的完美结合:GPText
接下来为大家介绍GPText产品,GPText产品是在Greenplum里可以直接内置在库内的对非结构化的文本进行快速索引和检索的组件,GPText集成了solr文本分析引擎,把结构化分析和非结构化分析完美的结合在一起,可以通过SQL对非结构化文本进行快速的检索和索引。
GPText SQL 数据仓库 + 文本分析
- 文本检索
- 将文本分析功能与结构化数据分析完美整合

支持内、外部数据源的索引
- 多种数据源支持(GPDB, 外部数据源)
- 多种数据类型(word,pdf,excel,图片)等

自然语言处理和AI的整合
- 与Madlib整合使用机器学习算法对文本数据进行分析
- 与PL/Python 、PL/Java 整合进行自然语言处理
- 与Open NLP算法库的集成

GPText -对文本进行索引和检索
这种效果与刚才MADlib+Greenplum的效果是一样的,因为Greenplum是一个分布式计算的框架、平台,结合了solr这个引擎之后,也可以把solr放到整个处理的大的平台上面,做分布式的文本的检索,对数据量的处理的效率和能够处理的能力有一个非常大的扩展。它可以支持比方说Word、PDF等等文件直接存入Greenplum里面去,并且通过对文本的处理,再结合跟MADlib机器学习的算法对文本内容进行的分析。后面也会有一个例子专门介绍结合GPText的索引加上MADlib的模型分析,把非结构化文本,处理成我们结构化公告的例子。
此外,我们对Open NLP的算法包集成,可以直接用Open NLP的算法包,通过PL/Python的方式直接对库内存储的文本进行分析和处理。
GPText的分布式框架
GPText的分布式框架就是通过对solr引擎的集成,把solr放到每一个数据库处理的实例上面,每一个solr实例都有相应的高可用配置,通过这样操作,可以对非常大规模的文本文件信息进行高速有效的处理。
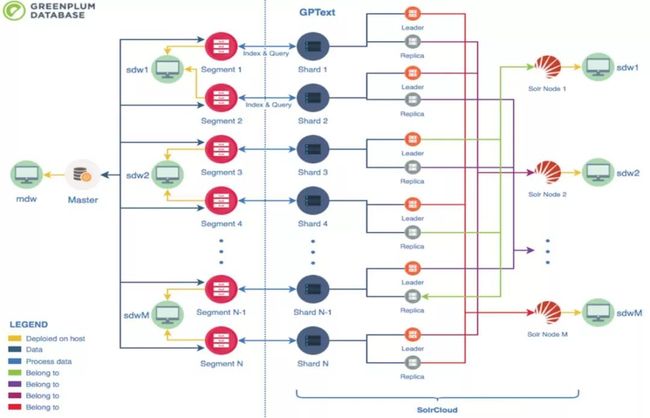
GPText - 分布式架构
