kettle案例四使用java脚本进行数据处理
如需转载请标明出处:直到世界的尽头-张小凡-http://my.525.life
本章我们学习使用java脚本进行数据处理。
数据情况
以嵌套Json结构为例进行解析,Json如下:
{
“id”: “0001”,
“name”: “Joe”,
“age”: 88,
“children”: [
{
“id”: “0002”,
“name”: “Jay”,
“age”: 52,
“children”: [
{
“id”: “0003”,
“name”: “zoe”,
“age”: 23,
“children”: []
}
]
}
]
}
保存在test3.json中。

建立转换流程
因为嵌套的Json Input不好处理,所以尝试使用Java代码来做递归处理。建立转换流程为
Json Input—>Java代码—->mongodb output

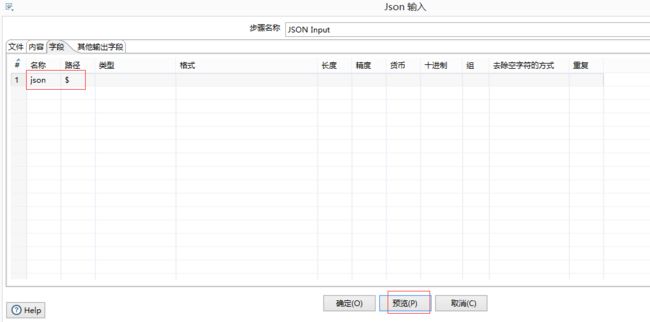
Json Input输入配置
则Json input的配置如下:
文本配置–>浏览选中test3.json—>增加

字段配置—>输入名称为json,路径为$表示整个根元素作为字段值—>预览查看

Java代码编写试运行
相关参考文献
https://wiki.pentaho.com/display/EAI/User+Defined+Java+Class
点击Code snippits–》Common use—》Main函数增加程序主体如下:
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while((infoRow = getRowFrom(infoStream)) != null){
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row’s Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
/* TODO: Your code here. (See Sample)
// Get the value from an input field
String foobar = get(Fields.In, “a_fieldname”).getString(r);
foobar += “bar”;
// Set a value in a new output field
get(Fields.Out, “output_fieldname”).setValue(r, foobar);
*/
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
可以看到 有完整的示例代码,我们只要根据示例代码来获取参数即可。
关键是要完成我们的处理逻辑。
首先我们来尝试读取上步骤输出的字段json(与上一步骤的输出字段名对应),拼接值形成新的字段json2(任意起字段名,但需要在下面的框中配置)输出到mongodb output中。
代码如下:
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row’s Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
// Get the value from an input field
String foobar = get(Fields.In, “json”).getString(r);
foobar += “bar”;
logBasic(“foobar:”+foobar);
// Set a value in a new output field
get(Fields.Out, “json2”).setValue(r, foobar);
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
此时还需要在下面字段部分设置与输出字段对应的字段名和类型。
否则会报错Unable to find Out field helper for field name ‘json2’。


确认代码无误和输出字段已经配置后点击确定。
mongodb output设置链接端口和库名集合名以及获取字段就不详细说了。
运行转换流程。
查看数据库中保存的记录,运行java代码成功。

说明:
打印日志使用:logBasic(); 例如:logBasic(“foobar:”+foobar);
if (first) {}这段代码块主要是在第一条记录的时候预先查好设置的字段数据类型或者自定义常量等情况。
RowMetaInterface inputRowMeta = getInputRowMeta(); inputRowMeta对象包含了输入行的元数据,包括域、数据类型、长度、名字、格式等等。例如,查找名字为”mysqldb”的域,可以采用如下方式:
Java代码
ValueMetaInterface customer = inputRowMeta.searchValueMeta("mysqldb"); 在一个transformation里查找域的名字是很慢的,因为每一条都要查找。建议在第一条记录的时候预先查好,所以一般会使用if(first){}:
例如获取mysql数据库的流程代码数据代码如下:

import java.sql.*;
import org.pentaho.di.core.database.*;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException
{
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
//获取数据库名和表名
String dbName = getInputRowMeta().getString(r, “conname”, null );
String tablename = getInputRowMeta().getString(r, “tablename”, null );
if (dbName==null||tablename==null) {
throw new KettleException(“Unable to find field with name “+tablename+” in the input row.”);
}
logBasic(“table—”+tablename);
//数据库连接
Database database=null;
DatabaseMeta databaseMeta=null;
try {
databaseMeta = getTransMeta().findDatabase(dbName);
if (databaseMeta==null) {
logError(“A connection with name “+dbName+” could not be found!”);
setErrors(1);
return false;
}
database = new Database(getTrans(), databaseMeta);
database.connect();
logBasic(“success!”);
} catch(Exception e) {
logError(“Connecting to database “+dbName+” failed.”, e);
setErrors(1);
return false;
}
//查询表数据
String sql=”select id,name from “+tablename;
ResultSet resultSet;
try {
resultSet = database.openQuery(sql);
Object[] idxRow = database.getRow(resultSet);
RowMetaInterface idxRowMeta =null;
if(idxRow!=null){
idxRowMeta=database.getReturnRowMeta();
}
int i=0;
while(idxRow!=null){
r = createOutputRow(r, data.outputRowMeta.size());
int index = getInputRowMeta().size();
// Add the index name
//
r[index++] = idxRowMeta.getString(idxRow, “id”, null);
// Add the column name
r[index++] = idxRowMeta.getString(idxRow, "name", null);
putRow(data.outputRowMeta, r);
idxRow = database.getRow(resultSet);
i++;
}
logBasic("idxRow--length"+i);
}
catch(Exception e) {
throw new KettleException(e);
}
//释放连接
if (database!=null) {
database.disconnect();
database.closeQuery(resultSet);
}
return true;
}
我们这里因为知道上一步骤传输的字段类型,所以不需要这样处理。在之后直接指定类型,例如 String foobar = get(Fields.In, “json”).getString(r);即可。
声明外部函数
我们引用的processRow是程序主体,类似于Java的main方法。
当时我们要处理例如递归等处理时,必须引用外部的函数处理递归的数据。
例如针对我们这个Json数据解析,我们需要声明一个处理children解析的外部函数dealChildren()。
整体思路是在processRow中先解析Root,获取到children,判断是否存在children,存在则调用处理dealChildren()。
dealChildren()中也需要获取到children,判断是否存在children,存在则调用处理dealChildren()。这样就完成了递归解决嵌套树的解析。
我们首先尝试怎么声明外部函数,在processRow函数之外再声明一个函数即可。甚至也可以引入其他包Map,HashMap等,还可以定义静态变量。
我们实现一个简单的外部函数给字符串拼接上ABC,代码如下:
import java.util.HashMap;
import java.util.Map;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row’s Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
// Get the value from an input field
String foobar = get(Fields.In, “json”).getString(r);
foobar += “bar”;
logBasic(“foobar:”+foobar);
foobar=appendABC(foobar);
logBasic(“foobar:”+foobar);
// Set a value in a new output field
get(Fields.Out, “json2”).setValue(r, foobar);
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
public static Map testMap = new HashMap();
public String appendABC(String S){
return S+”ABC”;
}
运行发现外部函数已经生效:

我们发现有两个问题:
1、kettle自带的包里有些数据类型没有。
2、在kettle里写代码没有自动补全,很难调试。
那我们是不是能够引入外部的jar或者我们自己写的jar包来处理呢,答案是肯定的。kettle支持引入外部的jar包。
引入外部jar包处理复杂逻辑
kettle使用的jar包都存放在kettle安装目录的lib文件夹中,旧版本的路径是安装目录的libext中。
如图:

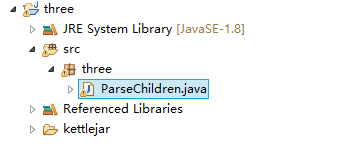
我们在Java的IDE中新建一个jar包项目,我这里使用的是Eclipse。
新建java project命名为three。
新建一个命名为ketllejar的文件夹。
把kettle安装目录的lib文件夹下的jar包都放入ketllejar文件夹中。
对着这些jar包右键选择 Add to Build Path添加引用。
我这里还下载了一个解析json比较好用的jar包
http://central.maven.org/maven2/net/sf/json-lib/json-lib/2.3/

关联包ezmorph-1.0.6.jar
http://mvnrepository.com/artifact/net.sf.ezmorph/ezmorph/1.0.6
把新增的jar包放入ketllejar文件夹中。
对着这个jar包右键选择 Add to Build Path添加引用。
新建类命名为ParseChildren,代码如下:
package three;
import java.util.ArrayList;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class ParseChildren {
public static final ArrayList> parseChildren(String json){
//resultTables用来存放所有的行,每行是一个节点解析出来的值
ArrayList> resultTables=new ArrayList>();
JSONObject root=JSONObject.fromObject(json);
String id= root.getString("id");
String name= root.getString("name");
int age= root.getInt("age");
JSONArray children=root.getJSONArray("children");
ArrayList resultRow=new ArrayList<>();
resultRow.add(id);
resultRow.add(name);
resultRow.add(String.valueOf(age));
resultTables.add(resultRow);
if(children!=null&&children.size()>0) {
for(int i=0;i> childrenTables=parseChildren(childrenString);
resultTables.addAll(childrenTables);
}
}
return resultTables;
}
}
最终的项目结构如图:
对着three右键Export成jar包。命名为three.jar

把three.jar包放在kettle目录的lib文件夹中。
使用到的json-lib-2.3-jdk13.jar,morph-1.1.1.jar也需要放入kettle目录的lib文件中。
如图:

然后我们回到kettle的java脚本,加入对three包的引用。
import three.ParseChildren; three对应package名,ParseChildren对应class名。
注意:需要重启kettle的spoon.bat才能识别到新添加的jar包。否则会报 not load的错误。
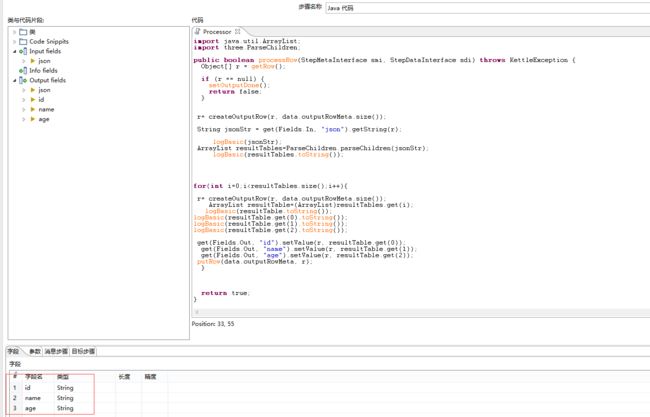
完整代码为:
import java.util.ArrayList;
import three.ParseChildren;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r= createOutputRow(r, data.outputRowMeta.size());
String jsonStr = get(Fields.In, "json").getString(r);
logBasic(jsonStr);
ArrayList resultTables=ParseChildren.parseChildren(jsonStr);
logBasic(resultTables.toString());
for(int i=0;i
r= createOutputRow(r, data.outputRowMeta.size());
ArrayList resultTable=(ArrayList)resultTables.get(i);
logBasic(resultTable.toString());
logBasic(resultTable.get(0).toString());
logBasic(resultTable.get(1).toString());
logBasic(resultTable.get(2).toString());
get(Fields.Out, "id").setValue(r, resultTable.get(0));
get(Fields.Out, "name").setValue(r, resultTable.get(1));
get(Fields.Out, "age").setValue(r, resultTable.get(2));
putRow(data.outputRowMeta, r);
}
return true;
} 设置输出字段为:
id String
name String
age String
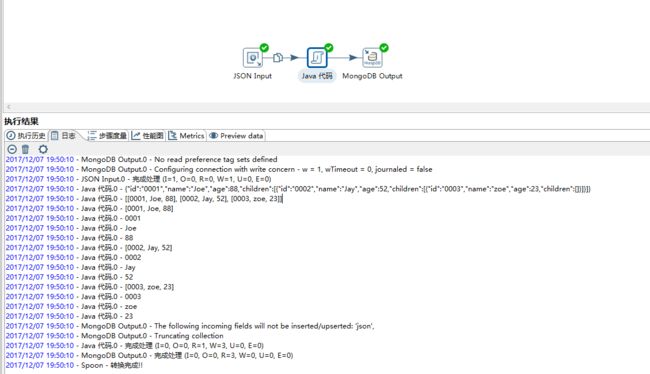
运行如图:
mongodb output设置链接端口和库名集合名以及获取字段就不详细说了。
这里需要重新获取一次字段,删除json字段,保留id和name以及age。
运行转换流程。
查看数据库中保存的记录,运行java代码成功。

如果报错
JSONObject[“children”] is not a JSONArray
说明某个节点没有包含children这个节点,需要补上。或者修改代码逻辑先判空。
如需转载请标明出处:直到世界的尽头-张小凡-http://my.525.life