利用Dom,Sax,Pull三种方式解析xml文件
最近找工作,看到许多公司的要求里都写了要会xml解析,所以就把之前的xml解析知识又重新回顾了一下,写个小例子.
解析xml文件常用的几种方式也就dom,sax,pull了,并且面试官经常问到的也是这三种解析方式之间的优缺点以及使用情况,先说一下这三种方式的优缺点和使用情况吧:
其实dom,sax,pull之间的优缺点网上有很多,讲的搞不好比我的还要深入和贴切,不过还是要说一下,毕竟自己以后还是要回顾知识的,到时候不要再翻别人的文章了,
dom解析:优点:简单易学,可以对文档进行修改,如删除节点,增加节点等,灵活性较高,读取速度快,缺点:解析时,把整个xml文档读到内存中,占用较多资源,
使用范围:如果需要对文档进行修改,dom解析肯定是首选,如果只是读取文档中的某些内容或全部内容,且不作修改,建议不要使用dom解析,而用sax解析或者pull解析.
sax解析:优点:解析速度快,不需要把文档读入内存,并且可以根据自身需求来获取数据,而不必解析整个文档,缺点:需要自己编写事件逻辑,使用麻烦,并且不能同时访问文档中的不同部分.使用范围:对于较大的文档有较好的解析能力,所以适用大文档的解析
pull解析:自我感觉是sax的升级版,比sax好用多了,优点:你不必自己写事件逻辑,并且也不需要把文档读到内存,缺点:对文档进行修改较困难
ok,三种方式的优缺点及适用范围说明完毕,其实,任何一种解析方式肯定都可以解析xml,如果你愿意,你可以对任何xml文档都使用1种解析方式.下面具体说一下每种解析方式的用法
在解析之前,先把要解析的xml文档贴出来:
George
John
Reminder
Don't forget the meeting!
1,dom解析:
因为document是一个接口,没有构造方法,所以不能采用new的方式来获取实例,只能通过相关类来获取实例,
查看dom解析的相关类,可以发现利用DocumentBuilder类可以获得一个document实例,但是DocumentBuilder类是一个抽象类,也不能采用new的方式获取DocumentBuilder对象,并且这个类也没有给出其他方式来获取实例,所以也只能通过相关类来获取实例,然后发现DocumentBuilder有个工厂类,即DocumentBuilderFactory,这个类提供了获取DocumentBuilder实例的方法,但是DocumentBuilderFactory这个类也是个抽象类,不过这个类提供了其他方法来获取自身的实例,即DocumentBuilderFactory.newInstance(),OK,通过以上方式我们拿到了document对象,代码表示出来就是:
ocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
其实不只是dom解析,sax解析和pull解析都是不能直接new出实例的,都只能采用这种方式来获取解析实例,这应该是出于线程安全方面考虑,让程序自始至终只有一个解析实例.
OK,拿到document对象之后,就可以进行xml文档的解析工作,
因为dom解析的特点:把拿到的xml文档一次全部读到内存里,所以document肯定有个方法用来获取整个文档的所有信息的,即
Element element = document.getDocumentElement();//获取当前xml文档的所有信息
通过这个方法,我们又拿到一个element对象,这个element对象里就包含了所有的文档信息,所以element对象肯定提供了很多方法用来获取文档详细信息,下面用代码带一一展示:
/**
* dom解析,该方法里的代码演示了如何利用DOM解析,拿到该xml文档的所有信息,如根节点名称,属性,和该根节点包含的
* 所有子节点的所有信息(子节点的属性,文本内容,子节点又包含的子节点等等)
*/
public void DomParse(View view) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
//从assets目录获取xml文档输入流
AssetManager assets = getAssets();
InputStream is = assets.open("text.xml");
//通过 builder.parse(is)方法获取一个document实例
Document document = builder.parse(is);
//根节点相关
Element element = document.getDocumentElement();//获取当前xml文档的所有信息
element.getTagName();//返回根节点的名称,这里为:note
element.getAttribute("name");//根据根节点的属性名返回属性值,这里为:rqq
//子节点相关
NodeList nodeList = element.getElementsByTagName("*");//根据子节点的节点名返回一个节点列表,如果填写"*",则返回所有节点的列表信息
nodeList.item(0).getNodeName();//返回第0个位置子节点的节点名,这里为:to
nodeList.item(0).getTextContent();//返回第0个位置子节点里的文本内容,不是属性值,这里为:George
nodeList.item(0).getParentNode();//返回第0个位置子节点的父节点,因各种原因找不到父节点则返回null,这里为:note
nodeList.item(0).getChildNodes();//返回第0个位置子节点包含的所有子节点列表信息,没有子节点,也会返回一个NodeList,只不过长度为0,这里当前的子节点 //下面已经没有子节点了,所以返回的NodeList长度为0
NamedNodeMap map = nodeList.item(0).getAttributes();//获取第0个位置子节点所有的属性集合,这里只有1个属性,即id
String nodeValue = map.item(0).getNodeValue();//获取第0个位置子节点的第0个位置属性的属性值,这里为:1
/*
* //也可通过下面的方式获取
* //因为Element是Node的子类,所以可以把Node强转为Element
* Element element1 = (Element) nodeList.item(0);
* //然后通过Element拿到该子节点的各种属性值
* element1.getAttribute("id");//获取该子节点的id属性
* //因为Element继承自Node,所以Element可以使用父类即Node类的所有的public方法,如下:
* element1.getNodeName();
* element1.getTextContent();
* element1.getParentNode();
* element1.getChildNodes();
*
* */
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}2,sax解析:
sax解析主要需要继承DefaultHandler,然后重写一些方法,一般需要重写的方法为:
startDocument(),endDocument(),startElement(),endElement()haracters()error(). /**
* sax解析
*/
public void SaxParse(View view) {
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
SAXParser saxParser = factory.newSAXParser();
AssetManager assets = getAssets();
InputStream is = assets.open("text.xml");
saxParser.parse(is, new SaxParseUtils());
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}SaxParseUtils类:
package com.rqq.xmlparse.utils;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxParseUtils extends DefaultHandler {
public SaxParseUtils() {
}
/**
* 文档开始解析时调用
*
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
System.out.println("文档开始解析...");
}
/**
* 相当于一个循环,从根节点开始,每读到一个新的节点,
* 便执行一次这个方法,然后把该节点里的所有属性都存到Attributes里,
*
* @param uri xml文档的uri地址,这里直接传入的是inputStream,所以uri为空
* @param localName 本地名,一般和qName相同
* @param qName 节点名
* @param attributes 当前节点下的所有属性都存放到该参数里了
* @throws SAXException 包含任何sax解析的异常
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println(qName + "节点开始读取");
attributes.getLength();//获取属性数量
String value = attributes.getValue(0);//也可根据索引号获取属性值,这里只有id一个属性,所以索引为0
String QName = attributes.getQName(0);
System.out.println("节点名: " + qName + ",属性名: " + QName + ",属性值: " + value + ";");
//System.out.println("uri: " + uri + "," + "localName: " + localName + "," + "qName: " + qName + "," + "attributes: " + attributes + ";");
}
/**
* 文档解析完毕时调用
*
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
System.out.println("文档解析结束...");
}
/**
* 该方法里存放的是每个节点里的文本内容,文本内容存到ch数组里,
*
* @param ch 用来存放每个节点里的文本内容
* @param start 文本内容是从哪开始的,如果文本内容前面有1个空格,则start为1,如果没有空格,则start为0
* @param length ch数组的长度,包含空格
* @throws SAXException 各种sax解析异常
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String data = new String(ch, start, length);
if (!data.trim().equals(""))
System.out.println("该节点存放的文本内容: " + data);
//System.out.println("ch: " + ch + "," + "start: " + start + "," + "length: " + length + ";");
}
/**
* 每个节点读取完毕时调用
*
* @param uri xml文档的uri地址,也可以为url,这里直接传入的是inputStream,所以uri为空
* @param localName 本地名,一般和qName相同
* @param qName 节点名
* @throws SAXException 各种sax解析异常
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
//System.out.println("uri: " + uri + "," + "localName: " + localName + "," + "qName: " + qName + ";");
System.out.println(qName + "节点读取完毕-----------");
}
/**
* 文档解析发生错误时调用
*
* @param e 具体的异常信息
* @throws SAXException 各种sax解析异常
*/
@Override
public void error(SAXParseException e) throws SAXException {
System.out.println("文档解析错误: " + e);
}
}
代码注释的也很详细,直接贴出结果吧:
重写的方法里的参数说明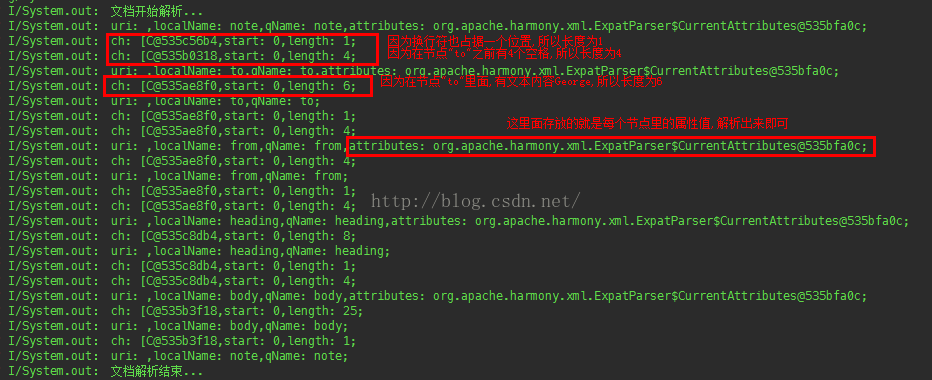
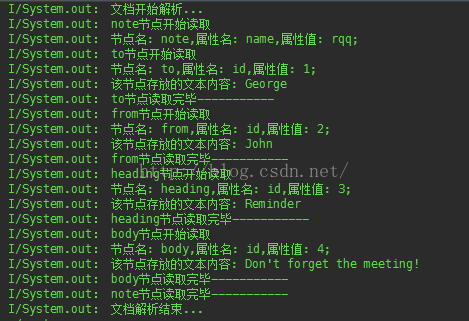
获取到的文档的具体内容为:
''
3,pull解析,
pull解析主要有两个关键点,1,获取到eventType,2,利用while循环,如下代码:
/**
* pull解析
*/
public void PullParse(View view) {
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser pull = factory.newPullParser();
AssetManager assets = getAssets();
InputStream is = assets.open("text.xml");
pull.setInput(is, "utf-8");
int eventType = pull.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
System.out.println("pull开始解析文档...");
break;
case XmlPullParser.START_TAG:
System.out.println("读取到节点: " + pull.getName() +
",属性名:" + pull.getAttributeName(0) +
",属性值:" + pull.getAttributeValue(0));
break;
case XmlPullParser.TEXT:
if (!pull.getText().trim().equals(""))
System.out.println("读取到的文本内容:" + pull.getText());
break;
case XmlPullParser.END_TAG:
System.out.println(pull.getName() + "节点读取完毕-------");
break;
}
eventType = pull.next();//这是关键,不然循环没有意义
}
System.out.println("pull解析文档完毕...");
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
ok,大致的关键点已经说完,还有一些具体的细节等以后有时间再说吧,