编程基础---不同编程语言学习---让程序跑起来
内容比较乱
helloworld:Java版
让程序跑起来
通过Eclipse运行程序
如下创建java项目
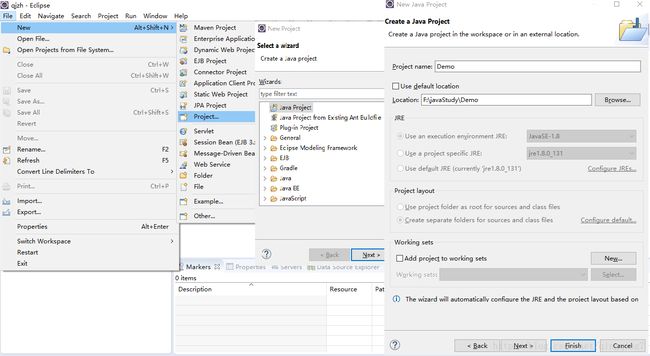
如果不勾选”use default location”,则需要在对应目录下创建与项目名称同名的文件。
如下创建java类

完成java项目并在项目下创建类eclipse中的目录结构如下:

可以看到会自动创建一个以.java为后缀,HelloWorld为文件名的java类源文件,其结构为
public class HelloWorld {
}电脑中的目录结构如下:
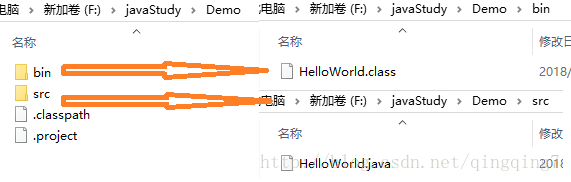
HelloWorld.class 文件,这就是编译生成的字节码。与C、C++不同,Java编译的结果不是可执行文件,而是字节码文件。字节码文件不能直接运行,必须由JVM翻译成机器码才能运行,这就是为什么运行Java程序必须安装JVM的原因。
输入代码到源文件
注意Java是大小写敏感的
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}如下运行java程序
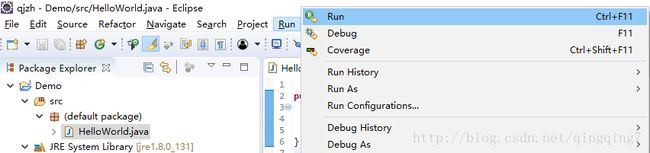
可在如下的控制台看到输出结果

通过命令行运行程序
通过javac filename编译,java filename运行
windows的运行如下
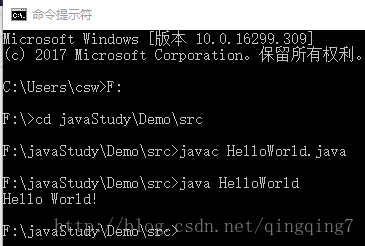
linux下运行过程类似
导入外部包
在使用JDBC编程时需要连接数据库,导入JAR包是必须的,导入其它的jar包方法同样如此,导入的方法是
打开eclipse
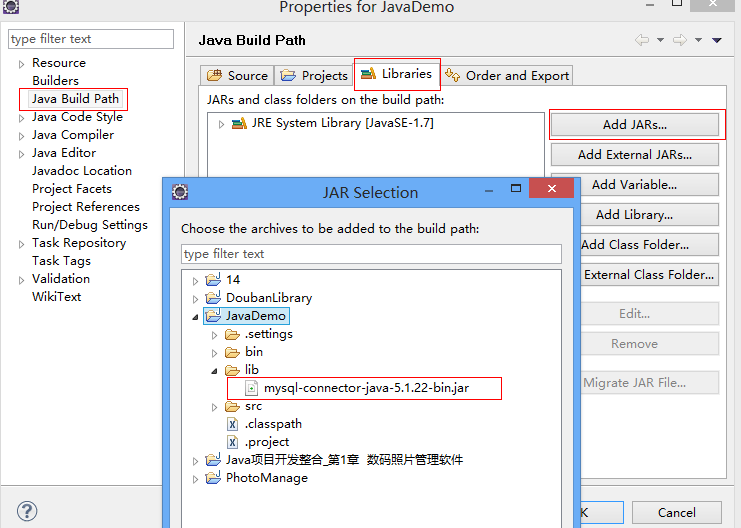
1.右击要导入jar包的项目,点properties
2.左边选择java build path,右边选择libraries
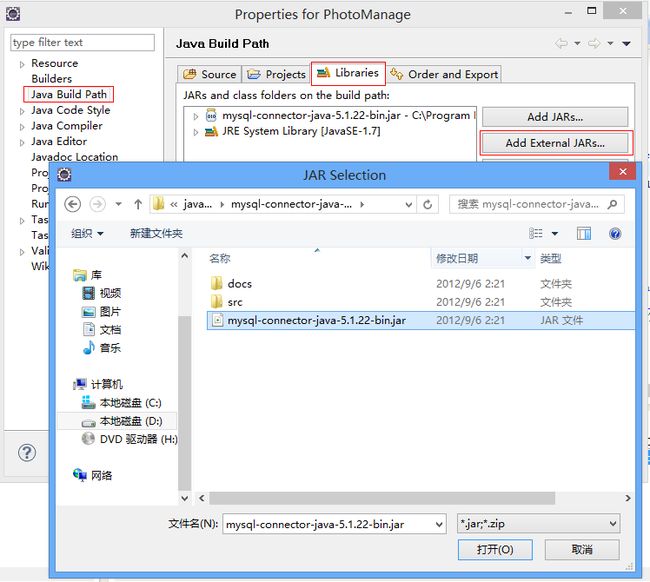
3.选择add External jars
4.选择jar包的按照路径下的
确定后就行了。Java连接MySQL的最新驱动包下载地址
http://www.mysql.com/downloads/connector/j
有两种方法导入jar包,第一种是先把jar包放在项目的目录下,通过添加jar包,是使用相对地址的,这样把项目复制到其它电脑也可以用; 第二种方法是导入外部的jar包,是绝对地址,如果项目要复制到其它电脑又要重新导入。
第一种方法 ,建议使用
第二种方法
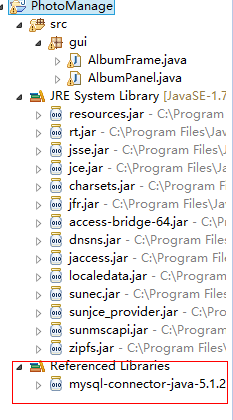
添加之后就会出现以下
程序结构
名字空间
这部分涉及程序设计语言的名字管理。假想程序里的某个模块使用了一个名字,而另一个人在这个程序的另一个模块里也使用了相同的名字,怎样区分他们的名字而防止发生冲突呢?于是就有了名字空间的概念,java为了给一个类库生成一个不会与其他名字混淆的名字,java的设计者希望开发者反过来使用自己Internet域名,因为这样是独一无二的,例如一个域名为mindview.net,那么各种工具类库就会命名为net.mindview.util.*,反转域名后,句点就用来代表子目录的划分,java.util.*就是这个道理。运用其他构件improt
如果想在自己的程序里运用预先定义好的类,那么编译器就要知道如何定位他们。当然,如果调用的类就在发出调用的那个源文件里,那么你就可以直接使用这个类(因为你们是一家人),即使这个类在调用语句之后才定义(java消除了类似于c语言中的“向前引用”的问题)
但是如果你要使用的对象类在其他文件中的话怎么办呢,编译器还可不可以自己找到你所要的类的,那个如何定位呢,于是java就使用关键字import来准确的告诉编译器你要的类是什么,import指示编译器导入一个包,也就是一个类库。关键字
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}不同结构体以{}包围,和python中通过严格的缩进来规范不一样
public class HelloWorld定义了一个类,类是 “public” 公共类型的,类名为“HelloWorld”。另外,Java 中主类名应该和要保存的 Java 文件名相同,也就是说,这里定义的类名是“HelloWorld”,则文件应该保存为elloWorld.java”。
public static void main(String[] args)**Java 中的主运行方法,它和 C/C++中的main()作用是一样的,就是所有的程序都从“**main()”中开始执行。要执行 Java 程序,必须有一个包括主运行方法的类,而python中不需要有主运行方法也可以运行(python中为了结构清晰,可以在程序主体中使用if __name__ == '__main__':来标记程序主入口)。java的主运行方法必须以“public static void”来定义,否则报错。
static关键字
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,但是Java语言中没有全局变量的概念。
被static修饰的成员变量和成员方法独立于该类的任何对象。也就是说,它不依赖类特定的实例,被类的所有实例共享。
用public修饰的static成员变量和成员方法本质是全局变量和全局方法,当声明它类的对象时,不生成static变量的副本,而是类的所有实例共享同一个static变量。
关于java中static作用详解可参考
当类创建的时候,其实你只是描述了这个类的外观(属性)和行为(方法),只有当你new创建这个类的对象时,数据空间才会分配,其方法才能被外界调用。如果只为某一特定函数创建一个方法,而不管要创建多少对象的话怎么办呢,也就是说,即使没有创建对象,也可以调用该方法。
于是,就有关键字static,当声明一个事物static时,就说明这个事物与任何实例对象没有联系,而只是与你所创建的类有关,就是说即使你没有创建那个类的对象,仍然可以使用类内的方法。
在定义和方法的时候道理是一样的了,使用static方法的时候根本不需要事先实例化一个对象。
经过上面的分析之后,也许你就已经知道了为什么main方法用static关键字了。void关键字
Void - java.lang 中的 类
Void 类是一个不可实例化的占位符类,它保持一个对代表 Java 关键字 void 的 Class 对象的引用。void就是空,在方法申明的时候表示该方法没有返回值就行了。
C中有四种数据类型,里面居然有空类型,它里面有这样一说“有一类函数,调用后并不需要向调用者返回函数值, 这种函数可以定义为“空类型”。其类型说明符为void”。
Java中main方法参数String[ ] args的使用
public static void main(String[] args){ }
public static void main(String args[]){ } //两种写法都是一样的,都表示字符串数组args,其中args只是普通变量名,可以随意定义(前提是符合变量名规则)main方法参数必须为字符串数组(String [ ]),变量名可以随意,通常使用args即是arguments(”参数“的复数形式)的缩写。
如果我们就是不呢?那就不能被系统识别为主方法,例如这样:
public static void main(String args){ //将String[]改成了String
}在Eclipse运行结果:

如果在已经有正确main方法,再有同名的main方法就是方法重载了:
public static void main(String[] args){
//正确标准完美的main方法
}
public static void main(String args){
//方法重载
}参数String[ ] args的作用
可以在main方法运行前将参数传入main方法中。
1)从控制台,输入编译执行命令时传参数。例如下面代码:
public static void main(String[] args){
for(int i=0; iout.println(args[i]); //遍历输出args[]中元素
} 但是此时args[]并没有赋值,我们需要从控制台命令行进行赋值,就像这样:
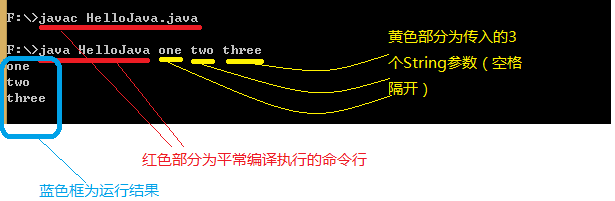
所以在命令行中使用String[ ] args即传入参数的使用为:java 类名 【参数1】 【参数2】 【参数3】 .。。。
2)在Eclipse使用String[ ] args。
鼠标右键点击程序
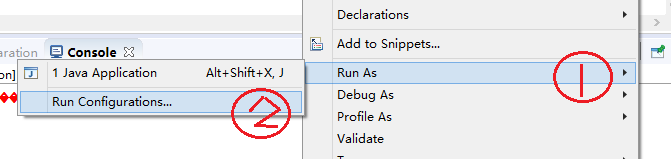
出现以下窗口,切换到(x)=Arguments窗口,输入参数
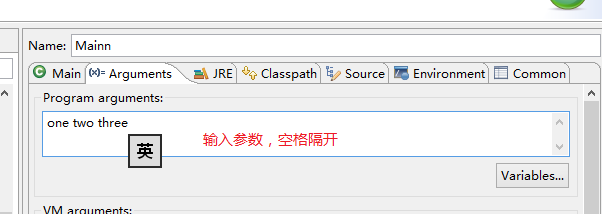
最后点击Run运行即可。
主体功能代码
System.out.println(“Hello world”);实现了将字串“Hello world”输出到命令行窗口。“System.out.println()”是 Java.lang 包的一个方法,与python一样可以直接用”包名.方法”的方法来使用,也可以先”import 包”,再调用方法。
循环控制
参考《不同软件中的条件分支、循环和跳出》
python版
让程序跑起来
比起其他语言,让python程序运行起来显得特别简单
通过pycharm运行程序
如下图创建项目
如下图新建pythonfile

文件目录如下:
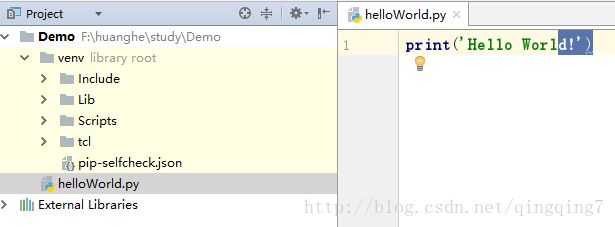
输入代码到源文件
print('Hello World!')如下运行代码
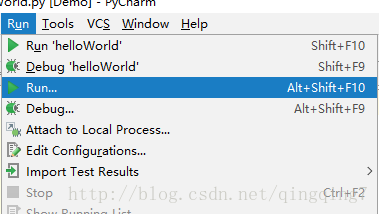
可以在控制台看到输出:Hello World!
就是这么简单的代码就可以跑出结果,实际上可能还会添加其他部分。
如果有多个python版本,需要在pycharm中指定编译器版本。
通过命令行运行程序
直接用”python 程序名.py”就可以运行python程序
window如下所示
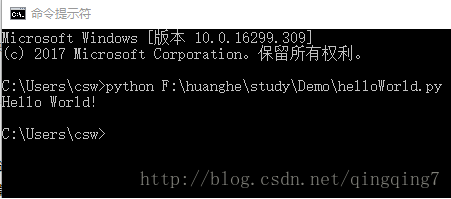
linux平台类似。
也可以运行编译过的文件”python 程序名.pyc”
导入外部包
待
程序结构
名字空间
待
运用其他构件improt
待
类
类的概念在许多语言中出现,很容易理解。它将数据和操作进行封装,以便将来的复用。
类由类成员,方法,数据属性组成
Python中,方法定义在类的定义中,但是只能被实例所调用,调用一个方法的最终途径必须是这样的:关于类的定义及使用更详细的可参考。
(1)定义类和类中的方法
class Student(object):
pass由于类起到模板的作用,我们可以把我们认为必须绑定的属性用__init__()强制填写进去
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score注意:(1)、__init__方法的第一参数永远是self,表示创建的类实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。(2)、有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器会自己把实例变量传进去。
这里self就是指类本身,self.name就是Student类的属性变量,是Student类所有。而name是外部传来的参数,不是Student类所自带的。故,self.name = name的意思就是把外部传来的参数name的值赋值给Student类自己的属性变量self.name。
(2)创建一个实例或者说将类实例化
student = Student("Hugh", 99)(3)最后用这个实例调用方法
print(student.name)
#结果为:"Hugh"
print(student.score)
#结果为:99Python中__init__()其实是一个初始化方法,是一个特殊的方法。
下面是定义类并实例化类的一个例子
# -*- coding: utf-8 -*-
class MyDataWithMethod(object): # 定义类
def printFoo(self): # 定义方法
print('You invoked printFoo()!')
myObj = MyDataWithMethod() # 创建实例
myObj.printFoo() # 现在调用方法
#结果:
#You invoked printFoo()!python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是”立即”的, 由解释器在适当的时机,将垃圾对象占用的内存空间回收。
a = 40 # 创建对象 <40>
b = a # 增加引用, <40> 的计数
c = [b] # 增加引用. <40> 的计数
del a # 减少引用 <40> 的计数
b = 100 # 减少引用 <40> 的计数
c[0] = -1 # 减少引用 <40> 的计数垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
隐式超类——object
来源
每一个Python类都隐含了一个超类:object。它是一个非常简单的类定义,几乎不做任何事情。我们可以创建object的实例,但是我们不能用它做太多,因为许多特殊的方法容易抛出异常。
当我们自定义一个类,object则为超类。下面是一个类定义示例,它使用新的名称简单的继承了object:
# -*- coding: utf-8 -*-
class X:
pass
print(X.__class__)
print(X.__bases__)
# ,) 我们可以看到该类是type类的一个对象,且它的基类为object。
就像在每个方法中看到的那样,我们也看看从object继承的默认行为。在某些情况下,超类的特殊方法是我们想要的。而在其他情况下,我们又需要覆盖这个特殊方法。
self的仔细用法
(1)、self代表类的实例,而非类。
而self.__class__则指向类。
注意:把self换成this,结果也一样,但Python中最好用约定俗成的self。
(2)、self可以不写吗?
在Python解释器的内部,当我们调用t.ppr()时,实际上Python解释成Test.ppr(t),也就是把self替换成了类的实例。
class Test:
def ppr():
print(self)
t = Test()
t.ppr()运行结果如下:
Traceback (most recent call last):
File "cl.py", line 6, in <module>
t.ppr()
TypeError: ppr() takes 0 positional arguments but 1 was given运行时提醒错误如下:ppr在定义时没有参数,但是我们运行时强行传了一个参数。由于上面解释过了t.ppr()等同于Test.ppr(t),所以程序提醒我们多传了一个参数t。这里实际上已经部分说明了self在定义时不可以省略(类内部定义时不可以省略,外部实例化的不需要写)。
当然,如果我们的定义和调用时均不传类实例是可以的,这就是类方法。
(3)、在继承时,传入的是哪个实例,就是那个传入的实例,而不是指定义了self的类的实例。
class Parent:
def pprt(self):
print(self)
class Child(Parent):
def cprt(self):
print(self)
c = Child()
c.cprt()
c.pprt()
p = Parent()
p.pprt()
# <__main__.Child object at 0x000002221A7CA4A8>
# <__main__.Child object at 0x000002221A7CA4A8>
# <__main__.Parent object at 0x000002221A7CAA20>(4)、在描述符类中,self指的是描述符类的实例
class Desc:
def __get__(self, ins, cls):
print('self in Desc: %s ' % self )
print(self, ins, cls)
class Test:
x = Desc()
def prt(self):
print('self in Test: %s' % self)
t = Test()
t.prt()
t.x
# self in Test: <__main__.Test object at 0x000002714052A780>
# self in Desc: <__main__.Desc object at 0x000002714052A4E0>
# <__main__.Desc object at 0x000002714052A4E0> <__main__.Test object at 0x000002714052A780> 这里主要的疑问应该在:Desc类中定义的self不是应该是调用它的实例t吗?怎么变成了Desc类的实例了呢?
因为这里调用的是t.x,也就是说是Test类的实例t的属性x,由于实例t中并没有定义属性x,所以找到了类属性x,而该属性是描述符属性,为Desc类的实例而已,所以此处并没有顶用Test的任何方法。
那么我们如果直接通过类来调用属性x也可以得到相同的结果。
下面是把t.x改为Test.x运行的结果。
self in Test: <__main__.Test object at 0x00000000022570B8>
self in Desc: <__main__.Desc object at 0x000000000223E208>
<__main__.Desc object at 0x000000000223E208> None <class '__main__.Test'>基类对象的__init__()方法
对象生命周期的基础是它的创建、初始化和销毁。我们将创建和销毁推迟到后面章节的高级特殊方法中讲,目前只关注初始化。
所有类的超类object,有一个默认包含pass的__init__()方法,我们不一定需要去实现它。如果不实现它,则在对象创建后就不会创建实例变量。在某些情况下,这种默认行为是可以接受的。
但更多时候我们需要给对象添加属性,该对象为基类object的子类。
思考下面的类,它需要两个实例变量但不初始化它们:
class Rectangle:
def area(self):
return self.length * self.widthRectangle类有一个使用两个属性来返回一个值的方法。这些属性没有初始化,是合法的Python代码。它可以明确地避免设置属性,虽然感觉有点奇怪,但是合法。
下面是与Rectangle类的交互:
r = Rectangle()
r.length,r.width=13,8
print(r.area())
#结果为104显然这是合法的,但这也是容易混淆的根源,所以也是我们需要避免的原因。
无论如何,这个设计给予了很大的灵活性,这样有时候我们不用在__init__()方法中设置所有属性。至此我们走的很顺利。一个可选属性其实就是一个子类,只是没有真正的正式声明为子类。我们创建多态在某种程度上可能会引起混乱,以及if语句的不恰当使用所造成的盘绕。虽然未初始化的属性可能是有用的,但也很有可能是糟糕设计的前兆。
《Python之禅》中的建议:
"显式比隐式更好。"一个__init__()方法应该让实例变量显式。
非常差的多态
灵活和愚蠢就在一念之间。
当我们觉得需要像下面这样写的时候,我们正从灵活的边缘走向愚蠢:
if 'x' in self.__dict__:或者:
try:
self.x
except AttributeError:是时候重新考虑API并添加一个通用的方法或属性。重构比添加if语句更明智。
在超类中实现__init__()
我们通过实现__init__()方法来初始化对象。当一个对象被创建,Python首先创建一个空对象并为该新对象调用__init__()方法。这个方法函数通常用来创建对象的实例变量并执行任何其他一次性处理。
下面是Card类示例定义的层次结构。我们将定义Card超类和三个子类,这三个子类是Card的变种。两个实例变量直接由参数值设置,并通过初始化方法计算:
# -*- coding: utf-8 -*-
class Card:
def __init__(self, rank, suit):
self.suit = suit
self.rank = rank
self.hard, self.soft = self._points()
class NumberCard(Card):
def _points(self):
return int(self.rank), int(self.rank)
class AceCard(Card):
def _points(self):
return 1, 11
class FaceCard(Card):
def _points(self):
return 10, 10在这个示例中,我们提取init()方法到超类,这样在Card超类中的通用初始化可以适用于三个子类NumberCard、AceCard和FaceCard。
这是一种常见的多态设计。每一个子类都提供一个唯一的_points()方法实现。所有子类都有相同的签名:有相同的方法和属性。这三个子类的对象在一个应用程序中可以交替使用。
如果我们为花色使用简单的字符,我们可以创建Card实例,如下所示:
cards = [AceCard('A', '♠'), NumberCard('2','♠'), NumberCard('3','♠'),]
#结果:[<__main__.AceCard instance at 0x0000000004D9E108>, <__main__.NumberCard instance at 0x0000000004D9E188>, <__main__.NumberCard instance at 0x0000000004D9E1C8>]我们在列表中枚举出一些牌的类、牌值和花色。从长远来说,我们需要更智能的工厂函数来创建Card实例,用这个方法枚举52张牌无聊且容易出错。在我们接触工厂函数之前,我们看一些其他问题。
使用__init__()创建显而易见的常量
可以给牌定义花色类。在二十一点中,花色无关紧要,简单的字符串就可以。
我们使用花色构造函数作为创建常量对象示例。在许多情况下,我们应用中小部分对象可以通过常量集合来定义。小部分的静态对象可能是实现策略模式或状态模式的一部分。
在某些情况下,我们会有一个在初始化或配置文件中创建的常量对象池,或者我们可以基于命令行参数创建常量对象。我们会在第十六章《命令行处理》中获取初始化设计和启动设计的详细信息。
Python没有简单正式的机制来定义一个不可变对象,我们将在第三章《属性访问、特性和描述符》中看看保证不可变性的相关技术。在本示例中,花色不可变是有道理的。
下面这个类,我们将用于创建四个显而易见的常量:
class Suit:
def __init__(self, name, symbol):
self.name = name
self.symbol = symbol下面是通过这个类创建的常量:
Club, Diamond, Heart, Spade = Suit('Club','♣'), Suit('Diamond','♦'), Suit('Heart','♥'), Suit('Spade','♠')
print(Club)
#结果:<__main__.Suit instance at 0x0000000005AFEF88>现在我们可以通过下面展示的代码片段创建cards:
cards = [AceCard('A', Spade), NumberCard('2', Spade), NumberCard('3', Spade)]这个小示例的方法对于单个字符花色的代码来说并没有多大改进。在更复杂的情况下,会通过这个方式创建一些策略或状态对象。从小的静态常量池中复用对象使得策略或状态设计模式效率更高。
我们必须承认,在Python中这些对象并不是技术上一成不变的,它是可变的。进行额外的编码使得这些对象真正不可变可能会有一些好处。
无关紧要的不变性
不变性很有吸引力但却容易带来麻烦。有时候神话般的“恶意程序员”在他们的应用程序中通过修改常量值进行调整。从设计上考虑,这是非常愚蠢的。这些神话般的、恶意的程序员不会停止这样做。在Python中没有更好的方法保证没有白痴的代码。恶意程序员访问到源码并且修改它仅仅是希望尽可能轻松地编写代码来修改一个常数。
在定义不可变对象的类的时候最好不要挣扎太久。在第三章《属性访问、特性和描述符》中,我们将在有bug的程序中提供合适的诊断信息来展示如何实现不变性。
* 通过工厂函数对__init__()加以利用*
* 在各个子类中实现__init__()*
当我们看到创建Card对象的工厂函数,再看看Card类设计。我想我们可能要重构牌值转换功能,因为这是Card类自身应该负责的内容。这会将初始化向下延伸到每个子类。
这需要共用的超类初始化以及特定的子类初始化。我们要谨遵Don’t Repeat Yourself(DRY)原则来保持代码可以被克隆到每一个子类中。
下面的示例展示了每个子类初始化的职责:
class Card:
pass
class NumberCard(Card):
def __init__(self, rank, suit):
self.suit = suit
self.rank = str(rank)
self.hard = self.soft = rank
class AceCard(Card):
def __init__(self, rank, suit):
self.suit = suit
self.rank = "A"
self.hard, self.soft = 1, 11
class FaceCard(Card):
def __init__(self, rank, suit):
self.suit = suit
self.rank = {11: 'J', 12: 'Q', 13: 'K'}[rank]
self.hard = self.soft = 10这仍是清晰的多态。然而,缺乏一个真正的共用初始化,会导致一些冗余。缺点在于重复初始化suit,所以必须将其抽象到超类中。各子类的__init__()会对超类的__init__()做显式的引用。
该版本的Card类有一个超类级别的初始化函数用于各子类,如下面代码片段所示:
class Card:
def __init__(self, rank, suit, hard, soft):
self.rank = rank
self.suit = suit
self.hard = hard
self.soft = soft
class NumberCard(Card):
def __init__(self, rank, suit):
super().__init__(str(rank), suit, rank, rank)
class AceCard(Card):
def __init__(self, rank, suit):
super().__init__("A", suit, 1, 11)
class FaceCard(Card):
def __init__(self, rank, suit):
super().__init__({11: 'J', 12: 'Q', 13: 'K' }[rank], suit, 10, 10)我们在子类和父类都提供了__init__()函数。好处是简化了我们的工厂函数,如下面代码片段所示:
def card10(rank, suit):
if rank == 1:
return AceCard(rank, suit)
elif 2 <= rank < 11:
return NumberCard(rank, suit)
elif 11 <= rank < 14:
return FaceCard(rank, suit)
else:
raise Exception("Rank out of range")简化工厂函数不应该是我们关注的焦点。不过我们从这可以看到一些变化,我们创建了比较复杂的__init__()函数,而对工厂函数却有一些较小的改进。这是比较常见的权衡。
工厂函数封装复杂性
在复杂的`__init__()方法和工厂函数之间有个权衡。最好就是坚持更直接,更少程序员友好的__init__()方法,并将复杂性推给工厂函数。如果你想封装复杂结构,工厂函数可以做的很好。
* 简单复合对象*
复合对象也可被称为容器。我们来看一个简单的复合对象:一副单独的牌。这是一个基本的集合。事实上它是如此基本,以至于我们不用过多的花费心思,直接使用简单的list做为一副牌。
在设计一个新类之前,我们需要问这个问题:使用一个简单的list是否合适?
我们可以使用random.shuffle()来洗牌和使用deck.pop()发牌到玩家手里。
一些程序员急于定义新类就像使用内置类一样草率,这很容易违反面向对象的设计原则。我们要避免一个新类像如下代码片段所示:
d = [card6(r+1, s) for r in range(13) for s in (Club, Diamond, Heart, Spade)]
random.shuffle(d)
hand = [d.pop(), d.pop()]如果就这么简单,为什么要写一个新类?
答案并不完全清楚。一个好处是,提供一个简化的、未实现接口的对象。正如我们前面提到的工厂函数一样,但在Python中类并不是一个硬性要求。
在前面的代码中,一副牌只有两个简单的用例和一个似乎并不够简化的类定义。它的优势在于隐藏实现的细节,但细节是如此微不足道,揭露它们几乎没有任何意义。在本章中,我们的关注主要放在__init__()方法上,我们将看一些创建并初始化集合的设计。
设计一个对象集合,有以下三个总体设计策略:
- 封装:该设计模式是现有的集合的定义。这可能是Facade设计模式的一个例子。
- 继承:该设计模式是现有的集合类,是普通子类的定义。
- 多态:从头开始设计。我们将在第六章看看《创建容器和集合》。
这三个概念是面向对象设计的核心。在设计一个类的时候我们必须总是这样做选择。
1. 封装集合类
以下是封装设计,其中包含一个内部集合:
import random
class Deck:
def __init__(self):
self._cards = [card6(r+1, s) for r in range(13) for s in (Club, Diamond, Heart, Spade)]
random.shuffle(self._cards)
def pop(self):
return self._cards.pop()我们已经定义了Deck,内部集合是一个list对象。Deck的pop()方法简单的委托给封装好的list对象。
然后我们可以通过下面这样的代码创建一个Hand实例:
d = Deck()
hand = [d.pop(), d.pop()]一般来说,Facade设计模式或封装好方法的类是简单的被委托给底层实现类的。这个委托会变得冗长。对于一个复杂的集合,我们可以委托大量方法给封装的对象。
2. 继承集合类
封装的另一种方法是继承内置类。这样做的优势是没有重新实现pop()方法,因为我们可以简单地继承它。
pop()的优点就是不用写过多的代码就能创建类。在这个例子中,继承list类的缺点是提供了一些我们不需要的函数。
下面是继承内置list的Deck定义:
class Deck2(list):
def __init__(self):
super().__init__(card6(r+1, s) for r in range(13) for s in (Club, Diamond, Heart, Spade))
random.shuffle(self)在某些情况下,为了拥有合适的类行为,我们的方法将必须显式地使用超类。在下面的章节中我们将会看到其他相关示例。
我们利用超类的init()方法填充我们的list对象来初始化单副扑克牌,然后我们洗牌。pop()方法只是简单从list继承过来且工作完美。从list继承的其他方法也能一起工作。
3. 更多的需求和另一种设计
在赌场中,牌通常从牌盒发出,里面有半打喜忧参半的扑克牌。这个原因使得我们有必要建立自己版本的Deck,而不是简单、纯粹的使用list对象。
此外,牌盒里的牌并不完全发完。相反,会插入标记牌。因为有标记牌,有些牌会被保留,而不是用来玩。
下面是包含多组52张牌的Deck定义:
class Deck3(list):
def __init__(self, decks=1):
super().__init__()
for i in range(decks):
self.extend(card6(r+1, s) for r in range(13) for s in (Club, Diamond, Heart, Spade))
random.shuffle(self)
burn = random.randint(1, 52)
for i in range(burn):
self.pop()未完待续
https://blog.csdn.net/langb2014/article/details/54800016
Python中self用法详解
关键字
global
当你在函数定义内声明变量的时候,它们与函数外具有相同名称的其他变量没有任何关系,即变量名称对于函数来说是 局部 的。这称为变量的 作用域 。所有变量的作用域是它们被定义的块,从它们的名称被定义的那点开始。
如果你想要为一个定义在函数外的变量赋值,那么你就得告诉Python这个变量名不是局部的,而是 全局 的(即存在于整个模块内部作用域的变量名)。我们使用global语句完成这一功能。没有global语句,是不可能为定义在函数外的变量赋值的。
你可以使用定义在函数外的变量的值(假设在函数内没有同名的变量)。然而,我并不鼓励你这样做,并且你应该尽量避免这样做,因为这使得程序的读者会不清楚这个变量是在哪里定义的。使用global语句可以清楚地表明变量是在外面的块定义的。
global语句被用来声明x是全局的——因此,当我们在函数内把值赋给x的时候,这个变化也反映在我们在主块中使用x的值的时候。
你可以使用同一个global语句指定多个全局变量。例如global x, y, z。
一个例子:
def func():
global x
print('x is', x)
x = 2
print('Changed local x to', x)
x = 50
func()
print('Value of x is', x)
#结果:
# ('x is', 50)
# ('Changed local x to', 2)
# ('Value of x is', 2)pass
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
if letter == 'h':
pass
print('这是 pass 块')主体功能代码
#hello.py
#-*-coding:utf8-*-
import numpy as np
class helloworld:
param1=1
_paramProtected=0
__paramPrivate=2
def __init__(self,innerp1,innerp2):#构造函数在类实例化的时候就会被执行
self.height=innerp1
self.weight=innerp2
def sayHello(self):
#类中的函数,不管是上面的构造函数还是这里的普通函数,第一个参数都是self,否则在创建函数的时候就会出错。
#而且在操作的时候,会使用self.属性将操作对象限定在类中,避免类对外部变量产生影响,而造成混乱。如果要获取操作结果可使用return
self.strHello='hello'
print(self.strHello)
def passParams(self,innerp1=1,innerp2=2):
self.a=innerp1
self.b=innerp2
self.c=self.a+self.b
return self.c
class helloworld2:
print('just have a try')#发现在后面if部分语句执行之前就已经打印了just have a try,说明python程序程序时是从上到下先扫了一遍的,
# 不管是类中的语句还要主体中的语句都会执行,并且按先后顺序,但是类中的函数则不会执行。因为函数都要被调用的时候才执行。
def normalHello():
str='world'
print(np.array(str))
if __name__=='__main__':
#python中.py文件就是一个模型,里面可以只是一个简单的执行语句,可以有函数,可以有类,也可以有多个类,而文件名称不需要与类名一样,
# 这个与java不一样,java类的文件名需要与类名一致;python里不管是包,还是模块其实只是一个命名空间(这部分对应搜索路径)
#当一个模块作为程序主体被运行的时候,它的__name__为__main__,if才成立,后面的语句才被执行;
# 当它被其他模块引用的时候,它的__name__就是模块的文件名。模块的__name__需要区别于类的__name__,如下
print(helloworld.__name__)#结果为helloworld
#我们可以先运行一下模块中的普通函数
normalHello()#结果为world
#下面测试类的相关用法
helloworldInstance=helloworld(175,70)#实例化对象
#通过外部给实例传入初始化参数,需要在类中定义好构造函数__init__(self)
print(helloworldInstance.height)#175
print(helloworldInstance.param1)#1,python中的变量一般是全局变量,全局可访问,可通过实例拿出来
print(helloworldInstance._paramProtected)#0,保护变量也可访问,但是一般不要这样操作。
# print(helloworldInstance.__paramPrivate)#出错,私有变量只能在类内部访问,外部访问不到。
helloworldInstance.sayHello()#hello
#Python中的类方法也是一种对象。由于既可以通过实例也可以通过类来访问方法,所以在Python里有两种风格:
# 未绑定的类方法:没有self
# 通过类来引用方法返回一个未绑定方法对象。要调用它,你必须显示地提供一个实例作为第一个参数。
#
# 绑定的实例方法:有self
# 通过实例访问方法返回一个绑定的方法对象。Python自动地给方法绑定一个实例,所以我们调用它时不用再传一个实例参数。
print(helloworldInstance.strHello)#hello
#测试使用类中的函数来完成功能并返回结果
c=helloworldInstance.passParams(innerp1=2,innerp2=3)
print(c)python作为一种脚本语言,我们用python写的各个module都可以包含以上那么一个类似c中的main函数,只不过python中的这种main与c中有一些区别,主要体现在:
1、当单独执行该module时,比如单独执行以上hello.py: python hello.py,则输出
just have a try
helloworld
world
175
1
0
hello
hello
5可以理解为”if __name__=="__main__":” 这一句与c中的main()函数所表述的是一致的,即作为入口;但是这个不是必须的;python程序程序时是从上到下先扫了一遍的,不管是类中的语句还要主体中的语句都会执行,并且按先后顺序,但是类中的函数则不会执行。因为函数都要被调用的时候才执行。至于if条件后的程序主体能不能执行要看if条件能不能成立。
2、当该module被其它module 引入使用时,其中的”if __name__=="__main__":“所表示的Block不会被执行,这是因为此时module被其它module引用时,其__name__的 值将发生变化,__name__的值将会是module的名字。比如在python shell中import hello后,查看hello.__name__:
import hello
print(hello.__name__)输出为:hello
3、因此,在python中,当一个module作为整体被执行时,moduel.__name__的值将是"__main__";而当一个 module被其它module引用时,module.__name__将是module自己的名字,当然一个module被其它module引用时,其 本身并不需要一个可执行的入口main了。
4、Python中的类方法调用:
像函数一样,Python中的类方法也是一种对象。由于既可以通过实例也可以通过类来访问方法,所以在Python里有两种风格:
未绑定的类方法:没有self
通过类来引用方法返回一个未绑定方法对象。要调用它,你必须显示地提供一个实例作为第一个参数。
绑定的实例方法:有self
通过实例访问方法返回一个绑定的方法对象。Python自动地给方法绑定一个实例,所以我们调用它时不用再传一个实例参数。
两种方法都是对象,它们可以被传递、存入列表等待。两者运行时都需要一个实例作为第一参数(妤一个self值),但当通过一个实例调用一个绑定方法时Python自动会提供一个。例如我们运行如下的代码:
class Test:
def func(self,message):
print message
object1=Test()
x=object1.func
#x('绑定方法对象,实例是隐含的')
t=Test.func
#t(object1,'未绑定的方法对象,需要传递一个实例')
#t('未绑定的方法对象,需要传递一个实例') #错误的调用object1=Test()生成一个实例,object1.func返回一个绑定的方法,把实例object1和方法func绑定。
而Test.func是用类去引用方法,我们得到一个未绑定的方法对象。要调用它就得传一个实例参数,如t(object1,'未绑定的方法对象,需要传递一个实例') 。
大多数时候,我们都直接调用方法,所以一般不会注意到方法对象。但是如果开始写通用的调用对象的代码时,需要特别仔细地注意未绑定方法,它们需要地传一个实例参数。
关于python封装的问题
https://www.cnblogs.com/Michael–chen/p/6740455.html
循环控制
参考《不同软件中的条件分支、循环和跳出》
helloworld:scala版
让程序跑起来
通过Eclipse运行程序
可以在该网站http://scala-ide.org/下载集成了scala的eclipse,解压即可用,同时该IDE也可以编写java程序。注意jdk的版本要与之相配套
新建scala项目后可以在该项目下新建scala object源文件,会自动生成如下的结构
package com.digger.test
object helloWorld {
}添加主程序入口
package com.digger.test
object helloWorld {
def main(args: Array[String]): Unit = {
println("Hello, world!")
}
}这样便可以运行出如下结果
Hello, world!修改object 名称,重新运行,结果一样,且不报错,说明源文件名称不需要与object 一致。
与java一样,运行时会自动编译生成.class文件。
与java一样,scala程序也需要一个主程序入口,而且主方法是放在object 这个结构体里(不知道可不可以放在class的结构体里),更详细的语法可参考下面的链接。
基本语法
通过命令行运行程序
scala> 1 + 1
res0: Int = 2
scala> println("Hello World!")
Hello World!导入外部包
定义包
Scala 使用 package 关键字定义包,在Scala将代码定义到某个包中有两种方式:
第一种方法和 Java 一样,在文件的头定义包名,这种方法就后续所有代码都放在该包中。 比如:
package com.runoob
class HelloWorld第二种方法有些类似 C#,如:
package com.runoob {
class HelloWorld
}第二种方法,可以在一个文件中定义多个包。
引用
Scala 使用 import 关键字引用包。
import java.awt.Color // 引入Color
import java.awt._ // 引入包内所有成员
def handler(evt: event.ActionEvent) { // java.awt.event.ActionEvent
... // 因为引入了java.awt,所以可以省去前面的部分
}import语句可以出现在任何地方,而不是只能在文件顶部。import的效果从开始延伸到语句块的结束。这可以大幅减少名称冲突的可能性。
如果想要引入包中的几个成员,可以使用selector(选取器):
程序结构
名字空间
循环控制
参考《不同软件中的条件分支、循环和跳出》