【单片记笔记】分享一个纯C语言的base64加密解密算法
base64简介
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充'='号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“_-”或“._”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
规则
关于这个编码的规则:
①.把3个字节变成4个字节。
②每76个字符加一个换行符。
③.最后的结束符也要处理。
例子1
转换前 11111111, 11111111, 11111111 (二进制)
转换后 00111111, 00111111, 00111111, 00111111 (二进制)
上面的三个字节是原文,下面的四个字节是转换后的Base64编码,其前两位均为0。
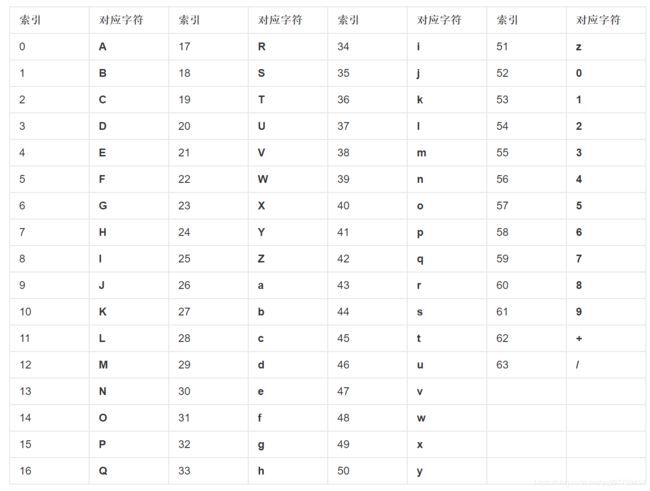
转换后,我们用一个码表来得到我们想要的字符串(也就是最终的Base64编码),这个表是这样的:(摘自RFC2045)
转换表
码表
base64.h
#ifndef base64_h
#define base64_h
#include
int base64_encode(const char *indata, int inlen, char *outdata, int *outlen);
int base64_decode(const char *indata, int inlen, char *outdata, int *outlen);
#endif /* base64_h */
base64.c
/**
* 转解码过程
* 3 * 8 = 4 * 6; 3字节占24位, 4*6=24
* 先将要编码的转成对应的ASCII值
* 如编码: s 1 3
* 对应ASCII值为: 115 49 51
* 对应二进制为: 01110011 00110001 00110011
* 将其6个分组分4组: 011100 110011 000100 110011
* 而计算机是以8bit存储, 所以在每组的高位补两个0如下:
* 00011100 00110011 00000100 00110011对应:28 51 4 51
* 查找base64 转换表 对应 c z E z
*
* 解码
* c z E z
* 对应ASCII值为 99 122 69 122
* 对应表base64_suffix_map的值为 28 51 4 51
* 对应二进制值为 00011100 00110011 00000100 00110011
* 依次去除每组的前两位, 再拼接成3字节
* 即: 01110011 00110001 00110011
* 对应的就是s 1 3
*/
#include "driver/base64.h"
#include
#include
// base64 转换表, 共64个
static const char base64_alphabet[] = {
'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z',
'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'+', '/'};
// 解码时使用
static const unsigned char base64_suffix_map[256] = {
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 253, 255,
255, 253, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 253, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 62, 255, 255, 255, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 255, 255,
255, 254, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 23, 24, 25, 255, 255, 255, 255, 255,
255, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,
37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255 };
static char cmove_bits(unsigned char src, unsigned lnum, unsigned rnum) {
src <<= lnum; // src = src << lnum;
src >>= rnum; // src = src >> rnum;
return src;
}
int base64_encode(const char *indata, int inlen, char *outdata, int *outlen) {
int ret = 0; // return value
if (indata == NULL || inlen == 0) {
return ret = -1;
}
int i;
int in_len = 0; // 源字符串长度, 如果in_len不是3的倍数, 那么需要补成3的倍数
int pad_num = 0; // 需要补齐的字符个数, 这样只有2, 1, 0(0的话不需要拼接, )
if (inlen % 3 != 0) {
pad_num = 3 - inlen % 3;
}
in_len = inlen + pad_num; // 拼接后的长度, 实际编码需要的长度(3的倍数)
int out_len = in_len * 8 / 6; // 编码后的长度
char *p = outdata; // 定义指针指向传出data的首地址
//编码, 长度为调整后的长度, 3字节一组
for (i = 0; i < in_len; i+=3) {
int value = *indata >> 2; // 将indata第一个字符向右移动2bit(丢弃2bit)
char c = base64_alphabet[value]; // 对应base64转换表的字符
*p = c; // 将对应字符(编码后字符)赋值给outdata第一字节
//处理最后一组(最后3字节)的数据
if (i == inlen + pad_num - 3 && pad_num != 0) {
if(pad_num == 1) {
*(p + 1) = base64_alphabet[(int)(cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4))];
*(p + 2) = base64_alphabet[(int)cmove_bits(*(indata + 1), 4, 2)];
*(p + 3) = '=';
} else if (pad_num == 2) { // 编码后的数据要补两个 '='
*(p + 1) = base64_alphabet[(int)cmove_bits(*indata, 6, 2)];
*(p + 2) = '=';
*(p + 3) = '=';
}
} else { // 处理正常的3字节的数据
*(p + 1) = base64_alphabet[cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4)];
*(p + 2) = base64_alphabet[cmove_bits(*(indata + 1), 4, 2) + cmove_bits(*(indata + 2), 0, 6)];
*(p + 3) = base64_alphabet[*(indata + 2) & 0x3f];
}
p += 4;
indata += 3;
}
if(outlen != NULL) {
*outlen = out_len;
}
return ret;
}
int base64_decode(const char *indata, int inlen, char *outdata, int *outlen) {
int ret = 0;
if (indata == NULL || inlen <= 0 || outdata == NULL || outlen == NULL) {
return ret = -1;
}
if (inlen % 4 != 0) { // 需要解码的数据不是4字节倍数
return ret = -2;
}
int t = 0, x = 0, y = 0, i = 0;
unsigned char c = 0;
int g = 3;
while (indata[x] != 0) {
// 需要解码的数据对应的ASCII值对应base64_suffix_map的值
c = base64_suffix_map[indata[x++]];
if (c == 255) return -1;// 对应的值不在转码表中
if (c == 253) continue;// 对应的值是换行或者回车
if (c == 254) { c = 0; g--; }// 对应的值是'='
t = (t<<6) | c; // 将其依次放入一个int型中占3字节
if (++y == 4) {
outdata[i++] = (unsigned char)((t>>16)&0xff);
if (g > 1) outdata[i++] = (unsigned char)((t>>8)&0xff);
if (g > 2) outdata[i++] = (unsigned char)(t&0xff);
y = t = 0;
}
}
if (outlen != NULL) {
*outlen = i;
}
return ret;
}
测试:

By Urien 2020年3月1日 13:32:36