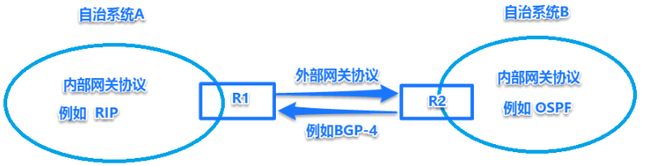
因特网中自治系统内部路由选择协议:RIP和OSPF、自治系统间的路由选择:BGP
路由选择协议可以分为两大类即 内部网关协议IGP和外部网关协议EGP
自治系统内部路由选择协议又称内部网关协议IGP,有:路由选择信息协议RIP和开放最短路径优先OSPF。
RIP:
- 概念:RIP协议是一种内部网关协议(IGP),是一种动态路由选择协议,用于自治系统(AS)内的路由信息的传递。RIP协议基于距离矢量算法,使用“跳数”来衡量到达目标地址的路由距离。这种协议的路由器只关心自己周围的世界,只与自己相邻的路由器交换信息,范围限制在15跳(15度)之内,再远,它就不关心了。
- 工作原理:RIP通过广播UDP报文(RIP响应报文)来交换路由信息,每30秒发送一次路由信息更新。RIP提供跳数(hopcount)作为尺度来衡量路由距离,跳数是沿着从源路由器到目的子网的最短路径所经过的子网数量。如果到相同目标有二个不等速或不同带宽的路由器,但跳数相同,则RIP认为两个路由是等距离的。RIP最多支持的跳数为15,即在源和目的网间所要经过的最多路由器的数目为15,跳数16表示不可达。
RIP有以下考虑:
(1)路由器和网络被表示为结点。
(2)终点是一个网络,即路由表第一列目的地址为一个网络地址。
(3)使用跳数作为度量。
(4)无穷大被定义为16。
(5)“下一个节点”是为了达到终点而要发往的下一个路由器的地址。
RIP协议报文格式:
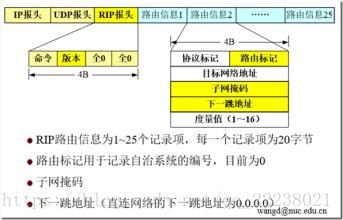

RIP首部:
命令(8位):指明报文类型,请求报文(1),请求路由器发送路由表、响应报文(2),可以是对请求的应答也可以是主动的更新。
版本(8位):RIP协议版本,1或2。
系列(16位):所使用协议系列,TCP/IP该值为2。
路由信息:
地址族标识符(24位):
它指出该入口的协议地址类型。由于 RIP2版本可能使用几种不同协议传送路由选择信息,所以要使用到该字段。IPv4协议地址的地址族标识符为2。
路由标记(32位):
路由标记填入自治系统的号码,这是考虑使RIP有可能收到本自治系统以外的路由选择信息。
仅在v2版本以上需要,第一版本不用,为0。用于路由器指定属性,必须通过路由器保存和重新广告。路由标志是分离内部和外部 RIP 路由线路的一种常用方法(路由选择域内的网络传送线路),该方法在 EGP或IGP都有应用。
网络地址:
目的网络地址,14个字节,可用于包括IP(4字节)在内的任何协议。这一项可以是网络地址、主机地址。
子网掩码字段:
IPv4子网掩码地址为32位。它应用于IP地址,生成非主机地址部分。如果为0,说明该入口不包括子网掩码。也仅在v2版本以上需要,在RIPv1中不需要,为0。、
下一跳字段:
指出下一跳IP地址,由路由入口指定的通向目的地的数据包需要转发到该地址。
距离(32位):
从发出通告的路由器一直到目的网络所经过的跳数。
RIP 协议的三个要点:
1、仅和相邻路由器交换信息。
2、交换的信息是当前本路由器所知道的全部信息,即自己的路由表。
3、按固定的时间间隔交换路由信息,例如,每隔 30 秒。
路由表的建立:
- 路由器在刚刚开始工作时,只知道到直接连接的网络的距离(此距离定义为1)。
- 以后,每一个路由器也只和数目非常有限的相邻路由器交换并更新路由信息。
- 经过若干次更新后,所有的路由器最终都会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器的地址。
- RIP 协议的收敛(convergence)过程较快,即在自治系统中所有的结点都得到正确的路由选择信息的过程。
RIP距离向量算法:
收到相邻路由器(其地址为 X)的一个 RIP 报文:
1、先修改此RIP报文中的所有项目(每一个路由信息):
a.把“下一跳”字段中的地址都改为X,并把所有的“距离”字段的值加1。
b.每个项目中的三个关键数据:到目的网络N,距离为d,下一跳路由器是X。
(便于进行本路由表的更新,假设从位于地址X的相邻路由器发来的RIP报文某一个项目是"NET2 ,3, Y",意思是:我经过路由器Y到NET2的距离是3,那么本路由器可推断出,我通过X路由器到达NET2的距离应该是3+1=4)
2、对修改后的RIP 报文中的每一个项目(路由信息),进行以下步骤(更新路由表):
.若原来的路由表中没有目的网络N,则把该项目加到路由表中。否则,查看下一跳路由器地址:
若下一跳路由器地址是X,则用收到的项目替换原路由表中的项目。(为什么要替换?,要以 最新的地址为准,到目的网络的距离可能增大也可能减小,所以应该以最新的更新)
否则若收到项目中的距离小于路由表中的距离,则进行更新(例如若路由表已有项目"NET2 ,5,P",就要更新为:"NET2,4,X",因为距离从5变到4更短了,)
否则,什么也不做。
3、若3分钟还没有收到相邻路由器的更新路由表,则把此相邻路由器记为不可达路由器,即将距离置为16。
4、返回。
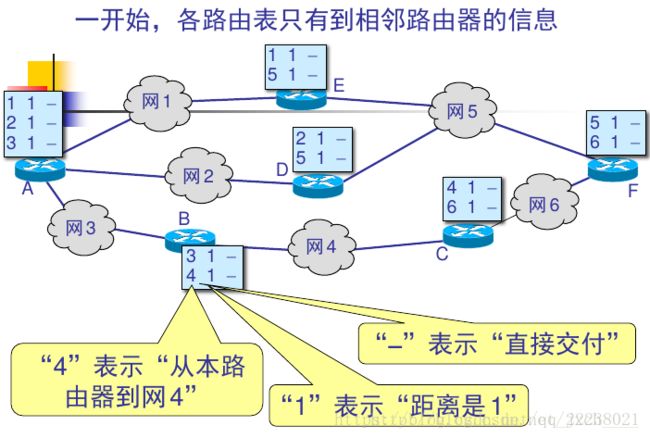
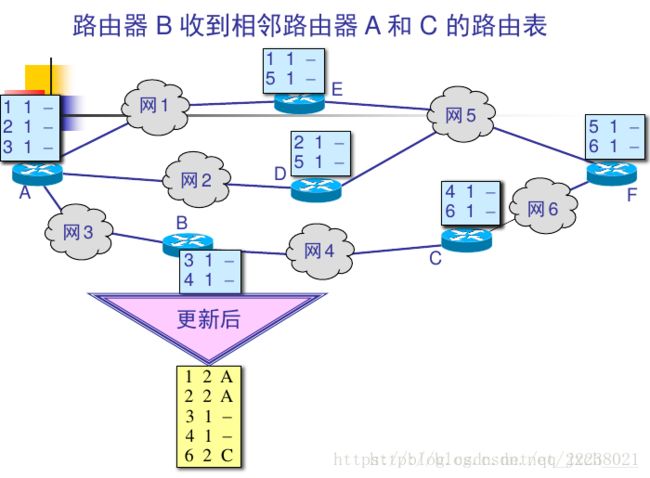

RIP协议让互联网中的所有路由器都和自己的相邻路由器不断交换路由信息,并不断更新其路由表,使得从每一个路由器到每一个目的网络的路由都是最短的(即跳数最少)。虽然所有的路由器最终都拥有了整个自治系统的全局路由信息,但由于每一个路由器的位置不同,它们的路由表当然也应当是不同的。
RIP使用三个定时器来支持它的操作:
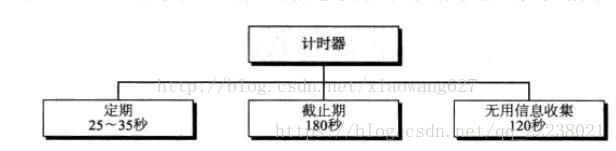
(1)定期计时器:控制更新报文的定期发送,倒数计时,为0时发送更新报文。
(2)截止期计时器:管理路由的有效性,为每个路由项设置一个计时器(180s),若该时间内没收到该路由项的任何更新报文,则将路由跳数设置为16。
(3)无用信息收集计时器:通知某个路由出了故障,当某个路由信息变成无效时,并不立即清除,而是设置无用信息收集计时器120秒,当计数倒数为0时删除该表项。这个计时器使得邻站在某个路由被清除之前能够了解该路由是无效的。
RIP 协议的优缺点:
- RIP协议最大的优点就是实现简单,开销较小。
- 问题: 好消息传播得快,而坏消息传播得慢。当网络出现故障时,要经过比较长的时间才能将此信息传送到所有的路由器。
- RIP 限制了网络的规模,它能使用的最大距离为 15(16 表示不可达)。
- 路由器之间交换的路由信息是路由器中的完整路由表,因而随着网络规模的扩大,开销也就增加。

坏消息传播得慢 :
1、R2 在收到 R1 的更新报文之前,还发送原来的报文,因为这时 R2 并不知道 R1 出了故障。
2、R1 收到 R2 的更新报文后,误认为可经过 R2 到达网1,于是更新自己的路由表,说:“我到网 1 的距离是3,下一跳经过R2”。然后将此更新信息发送给R2。
3、R2 以后又更新自己的路由表为“1, 4, R1”,表明“我到网 1 距离是 4,下一跳经过 R1”。
4、这样不断更新下去,直到 R 1 和 R2 到网 1 的距离都增大到 16 时,R1 和 R2 才知道网 1 是不可达的。
这就是好消息传播得快,而坏消息传播得慢。网络出故障的传播时间往往需要较长的时间(例如数分钟)。这是 RIP 的一个主要缺点。
例 :
假定网络中的路由器B的路由表有如下的项目(“目的网络”、“距离”、“下一跳路由器”)
N1 7 A
N2 2 C
N6 8 F
N8 4 E
N9 4 F现在B收到从C发来的路由信息(“目的网络”、“距离”):
N2 4
N3 8
N6 4
N8 3
N9 5试求出路由器B更新后的路由表(详细说明每一个步骤)。
路由器B更新后的路由表如下:
N1 7 A 无新信息,不改变
N2 5 C 相同的下一跳,更新
N3 9 C 新的项目,添加进来
N6 5 C 不同的下一跳,距离更短,更新
N8 4 E 不同的下一跳,距离一样,不改变
N9 4 F 不同的下一跳,距离更大,不改变例 2:
假定网络中的路由器A的路由表有如下的项目(格式同上题):
N1 4 B
N2 2 C
N3 1 F
N4 5 G现将A收到从C发来的路由信息(格式同上题):
N1 2
N2 1
N3 3
N4 7试求出路由器A更新后的路由表(详细说明每一个步骤)。
路由器A更新后的路由表如下:
N1 3 C 不同的下一跳,距离更短,改变
N2 2 C 相同的下一跳,距离一样,更新
N3 1 F 不同的下一跳,距离更大,不改变
N4 5 G 无新信息,不改变OSPF:
一种基于链路状态路由选择的AS内路由选择协议。OSPF使用五种不同类型的分组(报文):
问候分组、数据库描述分组、链路状态请求分组、链路状态更新分组、链路状态确认分组。
1 公共首部
所有的OSPF分组都有相同的公共首部,如下所示:

类型: 值1到5表示五种类型。
报文长度:包括首部在内的总报文长度。
鉴别字段为64位(上图有误),公共首部总长度为24字节。
2 链路状态更新分组
OSPF运行的核心,路由器用它来通告自己的链路状态,其通用格式如下:

每个更新分组可包含数个不同的LSA(链路状态通告),所有五种LSA具有相同的通用首部,格式如下:
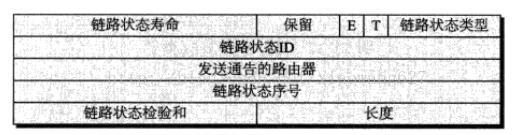
链路状态类型:定义了五种LSA的类型之一。
3 其他分组
(1)问候报文:用于建立邻站关系,并测试邻站的可达性。
(2)数据库描述报文: 邻站收到新连接路由器发送的问候报文后,若是第一次收到该消息,他们就发送数据库描述报文给新连接路由器,数据库描述分组并不包含完整的数据库信息,它只给出了概要,即数据库中每一行的标题,新连接上的路由器检查这些标题,并找出哪些行的信息它还没有,然后再发送一个或多个链路状态请求报文,以便得到这个特定链路的完整信息。
(3)链路状态请求分组:对它的回答是链路状态更新分组。
(4)链路状态确认分组:对所收到的每一个链路状态更新分组进行确认,使得路由选择更加可靠。
4 封装
OSPF分组被封装成IP数据报,这些数据报包括确认机制,以实现流量控制和差错控制。它们不需要通过运输层协议来提供这些服务。
OSPF协议工作过程:
- 发现邻居,建立并维护邻居关系
- 生成LSA,每台路由器都会生成自己的LSA
- 泛洪LSA,使用OPSF自身具备可靠传输能力将LSA泛洪到区域中的其它路由器上
- 将收到的LSA组装成链路状态数据库(LSDB),根据SPF算法计算出到达拓扑中所有网络的最短路径
- 将计算得出的路由装载到路由表
更多信息参看这里
6. OSPF动态路由协议
6.1 OSPF协议(Open Shortest Path First,OSPF开放式最短路径优先协议)
(1)通过路由器之间通告链路的状态来建立链路状态数据库,网络中所有的路由器具有相同的链路状态数据库,通过该数据库构建出网络拓扑。
(2)运行OSPF协议的路由器通过网络拓扑计算到各个网络的最短路径(开销最小的路径),路由器使用这些最短路径来构造路由表。
6.2 OSPF术语
(1)Router-ID:每一台OSPF路由器只有一个Router-ID,使用IP地址的形式来表示,该ID可以手工指定或路由器上活动Loopback接口中最大的IP地址,如C类地址优先于B类地址,注意非活动接口的IP地址不能被用作Router-ID。如果没有活动的Loopback接口,则选择活动物理接口IP地址最大的。
(2)开销(Cost):
①OSPF协议选择最佳路径的标准是带宽,带宽越高计算出来的开销越低。到达目标网络的各个链路累计开销最低的,就是最佳路径。用Metric(度量值)来表示开销,如10Mb/s接口(10 000 000),其Metric=100 000 000/10 000 000 = 10。其中的分子是个固定值。
②OSPF路由器计算到目标网络的Metric值,必须将沿途所有接口的Cost值累加起来,但只累加出接口,不计算进接口。
③OSPF会自动计算接口上的Cost值,但也可以通过手工指定该接口的Cost值,手工指定的值优先于自动计算的值。如果到目标网络Cost值相同,会执行负载均衡,最多有6条链路同时执行负载均衡。
(3)链路(Link):运行在OSPF进程下的路由器接口。
(4)链路状态(Link-State,LSA):即OSPF接口上的描述信息。如接口的IP地址、子网掩码、网络类型、Cost值等等。OSPF路由器之间交换的并不是路由表,而是链路状态。
(5)邻居(Neighbor)
①要想在OSPF路由器之间交换LSA,必须先形成OSPF邻居。只有邻居才会交换LSA,路由器将链路状态数据库中所有的内容毫不保留地发给所有邻居。
②OSPF靠周期性地发送Hello包来建立和维护。当超过4倍的Hello时间,也就是Dead时间过后还没收到邻居的Hello包,邻居关系将被断开。
6.3 OSPF协议工作过程
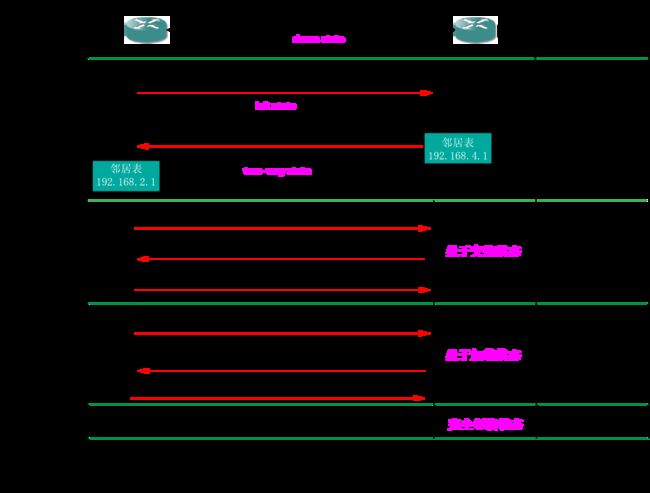
(1)邻居表的建立
①当R1路由器刚开始工作时,接口状态为down state,然后R1发送一个 Hello包,状态变为init state,等收到R2路由器发送来的Hello数据包,看到自己的ID出现在其应答的邻居表中,就建立了邻接关系,将其状态改为双向(two-way state)。
②OSPF规定,每两个相邻路由器每隔10秒要交换一次问候数据包,这样就能确定哪些邻站是可达的。若40秒钟没收到某相邻路由器发来的问候数据包,则可认为该相邻路由器不可到达,应立即修改链路状态数据库,并重新计算路由表。
③路由器通过发送Hello得知哪些相邻路由器在工作,以及将数据发往相邻路由器所需的“代价”,生成“邻居表”。
(2)拓扑表的建立
①交换状态:OSPF让每一个路由器和相邻路由器交换己有的链路状态摘要信息。
②加载状态:经过与相邻路由器交换摘要信息后,路由器就使用链路状态请求数据包向对方请求发送自己所缺少的某些链路状态项目的详细信息。经过一系列的分组交换,全网同步的链路数据库就建立了。
③完全邻接状态:邻居间的链路状态数据库同步完成,通过邻居链路状态请求列表为空且邻居状态为Loading判断。
(3)生成路由表
①每个路由器按照产生的全区域数据拓扑图,再运行最短路径算法,产生到目标网段的路由条目。
②在网络运行中,只要一个路由器的链路状态发生变化,该路由器就要使用链路状态更新数据包,用洪泛法向全网更新链路状态。(洪泛法指的是路由器通过所有输出端口向所有相邻的路由器发送消息。而每一个相邻路由器又再将此消息发往其所有的相邻路由器(但不再发送给刚刚发来消息的那个路由器)。这样,最终整个区域中所有的路由器都得到这个消息的一个副本,所以OSPF总是比RIP收敛更快,也没有RIP那种“坏消息传播得慢”的问题。)
6.4 OSPF的5种报文
(1)问候数据包(hello包):发现并建立邻接关系。
(2)数据库描述数据包:向邻居给出自己的链路状态数据库中的所有链路状态项目的摘要信息。
(3)链路状态请求(LSR)数据包:向对方请求某些链路状态项目的完整信息。
(4)链路状态更新(LSU)数据包:用洪泛法对全网更新链路状态。这种数据包是OSPF协议最核心的部分,也是最复杂的数据包。
(5)链路状态确认(LSAck):对LSU做确认
6.4 配置OSPF单区域
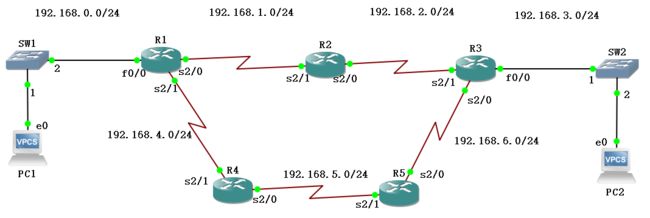
(1)配置OSPF协议(以R1路由器为例)
①R1(config)#router ospf 1 //1表示给ospf进程指定一个进程编号
②R1(config-router)#network 192.168.0.0 0.0.255.255 area 0,network的作用是为本路由器的OSPF进程指定网络范围,路由器R1的三个接口都属于192.168.0.0/16这个网段,可以合并,但注意使用的是反转掩码。
(2)查看OSPF协议的三张表
①显示邻居信息:R1#show ip ospf neighbor (注意NeighborID就是邻居路由的ID。FULL状态表示路由器与其他邻居处于完全邻接状态)
②显示邻居详细信息:R1#show ip ospf neighbor detail
③显示链路状态数据库:R1#show ip ospf database(其中的ADV Router表示通告链路状态的路由器)
④查看完全的链路状态数据库:R1#show ip ospf database router(每条链路状态包括自己与哪个路由器直连,以及自己连接着哪些网段)
⑤查看路由表:R1#show ip route或R1#show ip route ospf(只显示OSPF生成的路由表)
(3)监控OSPF协议的活动
①R1#debug ip ospf ? //查看能诊断的事件
②R1#debug ip ospf hello //显示hello数据包的活动(采用多播地址224.0.0.5)
③R1#debug ip ospf flood //洪泛数据包跟踪,显示链路状态更新(LSU)数据包的发送和接收。
④R1#undebug all //关闭诊断
(4)验证OSPF协议的健壮性
①PC1> tracer 192.168.3.2 //通过R1→R2→R3
②断开R1和R2之间的链路,再次PC1> tracer 192.168.3.2 //通过R1→R4→R5→R6
6.5 OSPF多区域
(1)自治系统与OSPF区域
将路由器分成了几类
- 区域内部路由器:所有的接口都位于同一区域
- 区域边界路由器(ABR):有不同的接口位于不同的区域且其中一个为骨干区域
- 自治系统边界路由器(ASBR):进行了重分布操作将其它路由器源学习到的路由引入OSPF的路由器
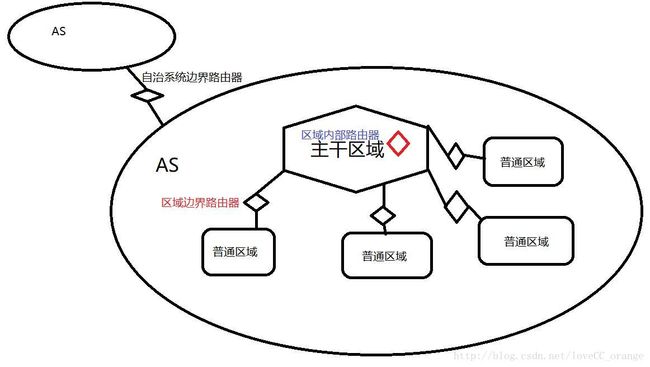

①因特网的规模非常大,有成千上万的路由设备的互连在一起。如果让所有的路由器知道所有网络怎样到达,则路由表将非常大。
②许多单位不愿外界了解自己单位网络的布局细节以及本部门所采用的路由选择协议。
③划分区域的好处就是利用洪泛法交换链路状态信息的范围局限于每一个区域而不是整个自治系统。在一个区域内部的路由器只需要知道本区域的完整网络拓扑,而不需要知道其他区域的网络拓扑。
④OSPF使用层次结构的区域划分,在上层的区域叫主干区域(标识符为0.0.0.0),其作用是连通其下层的区域。从其他区域来的信息都由区域边界路由器进行概括(路由汇总)(如上图主干路由器有R1、R2、R3,自治系统边界路由器有R3,区域边界路由器有R4和R5)
(2)两大类路由选择协议
①内部网关协议(IGP):即在一个自治系统内部使用的路由选择协议,与在互联网中的其他自治系统选用什么协议无关。目前主要使用RIP和OSPF协议。
②外部网关协议(EGP):负责在不同的自治系统间进行路由选择协议(不同的自治系统可能使用不同的内部网关协议)。目前使用最多的外部网关协议是BGPv4协议。
(3)OSPF多区域
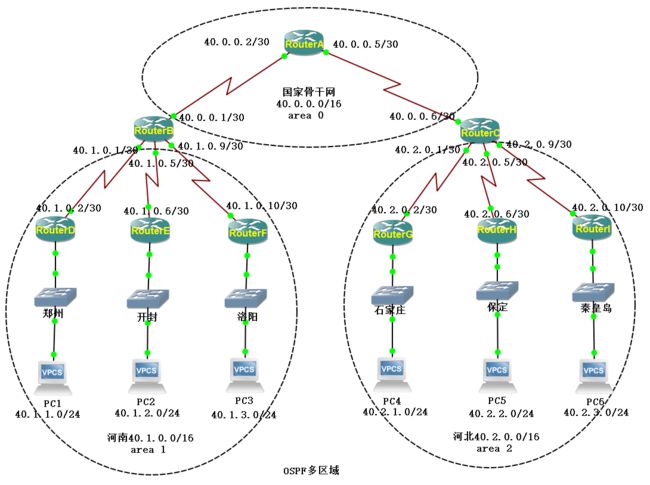
OSPF协议同步数据库的过程:
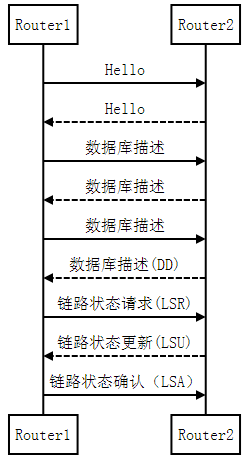
BGP:
外部网关协议BGP称为边界网关协议,为什么外部网关不使用内部网关协议?主要是BGP使用的环境不同。主要因为一下两个原因:
第一、 因特网的规模太大,使得AS之间路由选择非常困难。想一想如果运用OSPF需要建立一个非常大的数据库,这显然不现实。
第二、 AS之间的路由选择必须考虑有关策略。比如安全问题,或者路径上的路由不允许其非该AS的数据报通过等等。
所以BGP只能是力求寻找一条能够到达目的网络且比较好的路由(不能兜圈子),而并非要寻找一条最佳路由。BGP采用路径向量路由选择协议,与距离向量协议和链路状态协议不同。
在配置BGP时,每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“BGP发言人”。一个BGP发言人与其他AS的BGP发言人要交换路由信息,就要先建立TCP连接,然后在此连接上交换BGP报文以建立BGP会话,利用BGP交换路由信息。如下图:
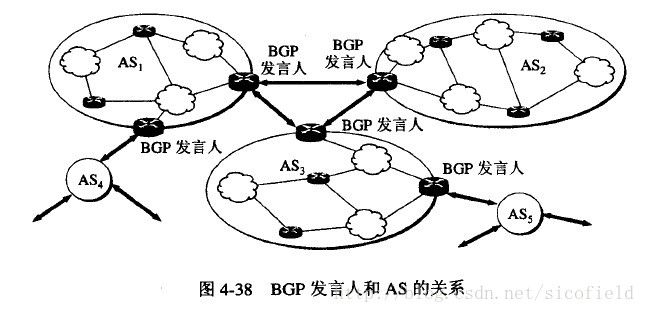
这里的每个BGP发言人除了必须运行BGP协议外,还必须运行该自治系统所使用的内部网关协议,如OSPF或RIP。
BGP所交换的网络可达性的信息就是要到达某个网络所经过的一系列自治系统。当BGP发言人相互交换了网络可达性信息之后,各BGP发言人就从收到的路由信息中找到到达各自治系统的较好路由。
BGP发言人构造出来的自治系统连通图是树状结构,不存在回路,如下图:
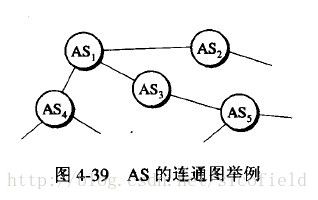
下图给出了一个BGP发言人交换路径向量的例子。自治系统AS2的BGP发言人通知主干网的BGP发言人:“要到达网络N1、N2、N3和N4可经过AS2。”主干网在收到这个通知之后就发出通知:“要到达网络N1、N2、N3和N4可沿路径(AS1,AS2)。”同理主干网还发出通知:“要到达网络N5、N6和N7可沿路径(AS1,AS3)。”这里采用了路径向量信息所以可以有效避免兜圈子的现象。比如如果一个BGP发言人收到其他BGP发言人发来的路径通知,它就要检查一下本自治系统是否在此路径中。如果在此路径之中就不能采用这条路径。

这就可以看出,BGP交换的路由信息的结点数量的数量级是自治系统个数的量级,这样比自治系统中的网络数少很多。同时搜索正确的路径就是寻找正确的BGP发言人。
BGP报文
在BGP刚刚运行的时候,BGP的临站是交换整个的路由表。但以后只需要在发生变化时更新有变化的部分。这样做节省了网络带宽的消耗。BGP有四种报文格式:
①OPEN(打开)报文——用来与相邻的另一个BGP发言人建立关系,是通信初始化。
②UPDATE(更新)报文——用来通告某一路由的信息,以及列出要撤销的多条路由。
③KEEPALIVE(保活)报文——用来周期性的验证邻站的连通性(与TCP保活比较)。
④NOTIFICATION(通知)报文——用来发送检测到的差错。
如果一个BGP发言人希望和另一个BGP发言人周期性交换信息,那么首先得建立关系,因为可能另一个BGP负载已经很重所以不希望建立关系。建立关系就发送OPEN报文,另外一个BGP回复KEEPALIVE报文。
一旦关系建立就需要继续维护,维护就是发送KEEPALIVE报文。
UPDATE报文可以撤销以前通知过的路径,也可以增加新的路径。
所有BGP报文共享相同的公共首部,如下所示:
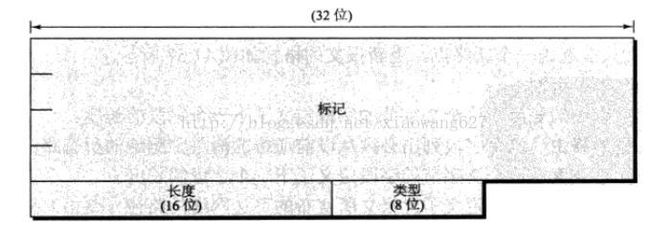
标记Maker(16字节)——-全为1,否者,标记的值要使用认证机制来计算(认证机制是通过认证信息的一部分来指定的)。标记可以用来探测BGP对端的同步丢失,认证进入的BGP消息。
长度:包括首部在内的报文总长度。
类型:1到4定义的四种类型。1 - OPEN;2 - UPDATE;3 - NOTIFICATION;4 – KEEPALIVE
BGP报文封装成TCP报文段,并使用熟知端口179,这表示不需要使用差错控制和流量控制,在TCP连接被打开后,就不停的交换着更新报文,直到发出停止类型的通知为止。
(1)OPEN类型格式: 
Ø Version(1字节)—–当前的BGP版本号为4
Ø My Autonomous System(2字节)—-发送者自制系统号
Ø Hold Time(2字节)—-BGP hold time 为180秒。
Ø BGP Identifier(4)—-发送者的BGP router-ID.
Ø Optional Parameters Length(可选参数长度)(1字节):如果这个域是0,说明没有可选参数。
Ø Optional Parameters(可选参数):
(2)UPDATE类型格式: 
Ø Unfeasible Routes Length(不可用路由长度)—-2字节,指示了撤销路由的字节总长度。0说明没有撤销路由, UPDATE消息内部没有撤销路由。
Ø Withdrawn Routes (撤销路由)—-如果没有撤销路由则无此字段,如果有撤销路由,此字段列出所撤销的路由条目。
Ø Total Path Attribute Length(总的路径属性长度)—-2字节,0代表在UPDATE消息中没有网络层可达信息域。
Ø Path Attributes(路径属性):在每一个UPDATE消息中有可能有多个路径属性对。每一个路径属性对包括Attribute Flags 、Attribute type code 、Attribute Data Length三个字段。Attribute Flags 、Attribute type code各占位1个字节。
Ø Network Layer Reachability Information(网络层可达信息):
(3)keepalive类型只包含BGP包头19字节。
(4)NOTIFICATION类型格式: 
Ø Error(错误码):1-消息头错误;2-OPEN消息错误;3-UPDATE消息错误;4-Hold计时器溢出;5-FSM错误;6-终止。
Ø Error subcode(错误子码): 
Ø Data(数据):
BGP协议的特点
1. BGP与RIP和OSPF的不同之处在于BGP使用TCP作为其传输层协议。两个运行BGP的系统之间建立一条TCP连接,运行在TCP的179端口,然后交换整个BGP路由表。从这个时候开始,在路由表发
生变化时,再发送更新信号。
2. BGP是一个距离向量协议,但是与RIP不同的是,BGP列举了到每个目的地址的路由。这样就排除了一些距离向量协议的问题(闭合环路问题)。采用16bit数字表示自治系统标识。
3. BGP通过定期发送keepalive报文给其邻站来检测TCP连接对端的链路或主机失败。两个报文之间的时间间隔建议值为30秒。
要注意的是,应用层的keepalive报文与TCP的keepalive选项是独立的。
4. 由于传输是可靠的,所以BGP使用增量更新,在可靠的链路上不需要使用定期更新,所以BGP使用触发更新。类似于OSPF和ISIS路由协议的Hello报文,BGP使用keepalive周期性地发送存活消息(60s)(维持邻居关系)
5. BGP在接收更新分组的时候,TCP使用滑动窗口,接收方在发送方窗口达到一半的时候进行确定,不同于OSPF等路由协议使1-to-1窗口。
6. 丰富的属性值
7. 可以组建可扩展的巨大的网络
RIP、OSPF、BGP比较
RIP使用UDP,OSPF使用IP,BRP使用TCP。这样做有何优点?为什么?RIP周期性与邻站交换信息而BGP为什么不这样做?
RIP只和邻站交换信息,UDP虽不保证可靠交付,但UDP开销小,可以满足RIP的要求,并且由于使用UDP,RIP周期性地与邻站交换信息。来克服UDP不可靠的缺点。
OSPF使用可靠的洪泛法,所以直接使用IP,好处就是灵活性好开销小。
BGP需要交换整个路由表和更新信息,所以要保证正确,运用TCP,由于BGP使用TCP所以已经能够保证可靠交付,用不着继续周期性交互信息。