《统计学习方法》-李航、《机器学习-西瓜书》-周志华总结+Python代码连载(七)--支持向量机SVM(Support vector machines)
一、支持向量机的概述
给定训练样本集![]() ,分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同样本分开,支持向量机就是讨论并解决怎么找到这样的超平面。
,分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同样本分开,支持向量机就是讨论并解决怎么找到这样的超平面。
在样本空间中,划分超平面可通过如下线性方程来描述:
![]()
其中![]() 为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离,显然超平面可以由w和b共同决定。样本空间中任意点x与超平面的距离可以写为:
为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离,显然超平面可以由w和b共同决定。样本空间中任意点x与超平面的距离可以写为:
![]()
距离超平面最近的几个训练样本点成为‘支持向量’,该点满足![]() ,因此正负支持向量的间隔为
,因此正负支持向量的间隔为![]()
二、支持向量机的原理
2.1 线性支持向量机硬间隔最大化
由一可知道欲找到具有‘最大间隔’的划分超平面,也就是找到满足下列式子的参数,即
![]()
![]()
显然最大化间隔,可以等价于下面的式子
![]()
![]()
求解上式采用格拉朗日乘子法得到其的‘对偶问题’,对上述的每条约束条件添加拉格朗日乘子![]() ,该式子的拉格朗日函数可写为
,该式子的拉格朗日函数可写为
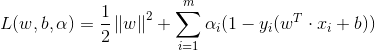
其中![]() ,L对w,b分别求导后的偏导为零可得
,L对w,b分别求导后的偏导为零可得
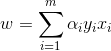 ,
,
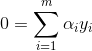 .
.
代入原式子可以消去w和b,再得到对偶问题


![]()
求解 后,求出w,b即可得到模型
后,求出w,b即可得到模型
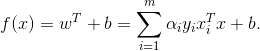
线性可分硬间隔最大化的支持向量机学习算法:
step1:构造并求解约束最优化问题

![]()
求得最优解![]()
step2:计算  ,并选择
,并选择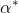 的一个正分量
的一个正分量![]() ,计算
,计算
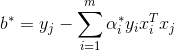
step3:求得分离超平面
![]()
分类决策函数:
![]()
2.2 线性支持向量机软间隔最大化
有些训练数据集不是线性可分的,通常情况下是,将这些不可分的特异点去除,于是剩下大部分的样本点组成的集合是线性可分的。线性不可分意味着这些样本点不能满足函数间隔最大化大于等于1的约束条件
,为了解决这个问题,可以对每个样本点引进一个松弛因子![]() ,使得函数间隔加上松弛因子大于等于1,这样,约束条件变为
,使得函数间隔加上松弛因子大于等于1,这样,约束条件变为
![]()
因此线性不可分软间隔最大化的支持向量机学习问题为:

![]()
![]()
对上式子采用拉格朗日乘子法所得到的拉格朗日函数是  ,其中
,其中![]()
首先求上面拉格朗日函数对 的极小,拉格朗日函数分别对三者求偏导,该偏导数设为0:
的极小,拉格朗日函数分别对三者求偏导,该偏导数设为0:
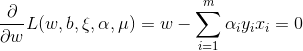
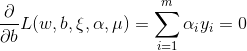
![]()
可以得到
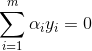
![]()
代入化简后有 
再对 ![]() 求的极大,即得对偶问题:
求的极大,即得对偶问题:


![]()
![]()
![]()
软间隔支持向量机学习算法:
step1:选择惩罚参数C>0,构造并求解带约束条件问题

s.t.
![]()
step2:计算
选择的一个分量![]() 的适合条件
的适合条件 ![]() ,并计算
,并计算 
step3:求得分离超平面
![]()
分类决策函数:
![]()
2.3 非线性支持向量机与核函数
对于分类非线性问题,可以使用非线性支持向量机,其主要特点是利用核技巧(kernel trick)。非线性问题往往不好求解,所以希望能用解线性分类问题来解决这个问题,其中采用一个方法就是进行一个非线性变换,将非线性问题转变成线性问题。
设原空间为![]() ,新空间为
,新空间为![]() ,定义从原空间到新空间的变换:
,定义从原空间到新空间的变换:
![]()
原空间![]() 变换为新空间
变换为新空间![]() ,则有原空间的椭圆:
,则有原空间的椭圆:
![]()
变换称为新空间中直线
![]()
上面的例子说明,用线性分类方法求解非线性分类问题分为两步:首先使用一个变换将原空间的数据映射到新空间;然后在新空间里用线性分类学习方法从训练数据中学习分类模型,核技巧就属于这样的方法。
设 是输入空间(欧氏空间
是输入空间(欧氏空间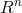 的子集或离散集合),又设H为特征空间(希尔伯特空间),如果存在一个从到H的映射
的子集或离散集合),又设H为特征空间(希尔伯特空间),如果存在一个从到H的映射
![]()
使得对所有![]() ,函数K(x,z)满足条件
,函数K(x,z)满足条件
![]()
为 和
和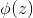 的内积。
的内积。
在支持向量机中内积![]() 可以用核函数
可以用核函数 来代替,此时对偶问题的目标函数为:
来代替,此时对偶问题的目标函数为:

同样,分类决策函数中的内积也可以用核函数代替,于是分类决策函数成为:

非线性支持向量机学习算法:
step1:选取适当的核函数K(x,z)和适当的参数C,构造并求解最优化问题

s.t. 
![]()
求得最优解![]() .
.
step2:选择的一个正分量![]() ,计算
,计算

step3:构造决策函数:
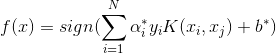
代码实现:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
]
data = np.array(df.iloc[:100, [0, 1, -1]])
for i in range(len(data)):
if data[i, -1] == 0:
data[i, -1] = -1
# print(data)
return data[:, :2], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
plt.scatter(X[:50,0],X[:50,1], label='0')
plt.scatter(X[50:,0],X[50:,1], label='1')
plt.legend()
class SVM:
def __init__(self, max_iter=100, kernel='linear'):
self.max_iter = max_iter
self._kernel = kernel
def init_args(self, features, labels):
self.m, self.n = features.shape
self.X = features
self.Y = labels
self.b = 0.0
# 将Ei保存在一个列表里
self.alpha = np.ones(self.m)
self.E = [self._E(i) for i in range(self.m)]
# 松弛变量
self.C = 1.0
def _KKT(self, i):
y_g = self._g(i) * self.Y[i]
if self.alpha[i] == 0:
return y_g >= 1
elif 0 < self.alpha[i] < self.C:
return y_g == 1
else:
return y_g <= 1
# g(x)预测值,输入xi(X[i])
def _g(self, i):
r = self.b
for j in range(self.m):
r += self.alpha[j] * self.Y[j] * self.kernel(self.X[i], self.X[j])
return r
# 核函数
def kernel(self, x1, x2):
if self._kernel == 'linear':
return sum([x1[k] * x2[k] for k in range(self.n)])
elif self._kernel == 'poly':
return (sum([x1[k] * x2[k] for k in range(self.n)]) + 1)**2
return 0
# E(x)为g(x)对输入x的预测值和y的差
def _E(self, i):
return self._g(i) - self.Y[i]
def _init_alpha(self):
# 外层循环首先遍历所有满足0= 0:
j = min(range(self.m), key=lambda x: self.E[x])
else:
j = max(range(self.m), key=lambda x: self.E[x])
return i, j
def _compare(self, _alpha, L, H):
if _alpha > H:
return H
elif _alpha < L:
return L
else:
return _alpha
def fit(self, features, labels):
self.init_args(features, labels)
for t in range(self.max_iter):
# train
i1, i2 = self._init_alpha()
# 边界
if self.Y[i1] == self.Y[i2]:
L = max(0, self.alpha[i1] + self.alpha[i2] - self.C)
H = min(self.C, self.alpha[i1] + self.alpha[i2])
else:
L = max(0, self.alpha[i2] - self.alpha[i1])
H = min(self.C, self.C + self.alpha[i2] - self.alpha[i1])
E1 = self.E[i1]
E2 = self.E[i2]
# eta=K11+K22-2K12
eta = self.kernel(self.X[i1], self.X[i1]) + self.kernel(
self.X[i2],
self.X[i2]) - 2 * self.kernel(self.X[i1], self.X[i2])
if eta <= 0:
# print('eta <= 0')
continue
alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (
E1 - E2) / eta #此处有修改,根据书上应该是E1 - E2,书上130-131页
alpha2_new = self._compare(alpha2_new_unc, L, H)
alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] * (
self.alpha[i2] - alpha2_new)
b1_new = -E1 - self.Y[i1] * self.kernel(self.X[i1], self.X[i1]) * (
alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel(
self.X[i2],
self.X[i1]) * (alpha2_new - self.alpha[i2]) + self.b
b2_new = -E2 - self.Y[i1] * self.kernel(self.X[i1], self.X[i2]) * (
alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel(
self.X[i2],
self.X[i2]) * (alpha2_new - self.alpha[i2]) + self.b
if 0 < alpha1_new < self.C:
b_new = b1_new
elif 0 < alpha2_new < self.C:
b_new = b2_new
else:
# 选择中点
b_new = (b1_new + b2_new) / 2
# 更新参数
self.alpha[i1] = alpha1_new
self.alpha[i2] = alpha2_new
self.b = b_new
self.E[i1] = self._E(i1)
self.E[i2] = self._E(i2)
return 'train done!'
def predict(self, data):
r = self.b
for i in range(self.m):
r += self.alpha[i] * self.Y[i] * self.kernel(data, self.X[i])
return 1 if r > 0 else -1
def score(self, X_test, y_test):
right_count = 0
for i in range(len(X_test)):
result = self.predict(X_test[i])
if result == y_test[i]:
right_count += 1
return right_count / len(X_test)
def _weight(self):
# linear model
yx = self.Y.reshape(-1, 1) * self.X
self.w = np.dot(yx.T, self.alpha)
return self.w
svm = SVM(max_iter=200)
svm.fit(X_train, y_train)
svm.score(X_test, y_test)
#sklearn实例
from sklearn.svm import SVC
clf = SVC()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
连载GitHub同步更新:https://github.com/wenhan123/ML-Python-