周志华《机器学习》第二章 模型评估与选择 笔记及习题解答
第二章 模型评估与选择 笔记
- 笔记
- 经验误差与泛化误差
- 过拟合
- 评估法
- 留出法
- 交叉验证法
- 留一法
- 性能度量
- 错误率和精度
- 错误率
- 精度
- 查准率、查全率与F1
- 查准率
- 查全率
- F1度量
- ROC与AUC
- 代价敏感错误率与代价曲线
- 比较检验
- 假设检验
- 二项检验(binomial test)
- t 检验(t-test)
- 交叉验证t检验
- McNemar检验
- Friedman检验与Nemenyi检验
- 偏差与方差
- 习题
- 1.数据集包含1000个样本,其中500个正例,500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
- 2.数据集包含100个样本,其中正反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
- 4.试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
笔记
经验误差与泛化误差
学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”
过拟合
学习器把训练样本自身特点当做所有潜在样本都会具有一样的性质,导致泛化能力下降,这种现象叫做过拟合
评估法
留出法
用“分层抽样法”将数据集D划分为两个集合:训练集 S S S,测试集 T T T,并且 S ⋂ S\bigcap S⋂ T T T= ∅ \varnothing ∅,用 S S S训练出模型后,用 T T T评估其泛化误差。
交叉验证法
用“分层抽样法”将数据集D划分为K个集合,每次训练使用K-1个集合,用另外一个作为测试集,从而可以进行K次训练与测试,最终返回的是K次训练后的均值。
留一法
交叉验证法的特例,留一法将数据集D中的m个样本划分为m个集合,每次用m-1个样本(集合)去训练,1个样本(集合)去测试。训练结果较为准确,但开销较大。#### 自助法
将数据集D进行有放回取样m次,得到包含m个样本的数据集 D ‘ D^` D‘,未被取到的样本作为测试集。
性能度量
性能度量:衡量模型泛化能力的标准
在对比不同模型的能力时,使用不同的性能度量会导致不同的评判结果,这就意味着模型的“好坏”是相对的。什么样的模型是好的,不仅取决于算法和数据,还取决于需求。
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) . . . . ( x m , y m ) } D=\{(x_1,y_1),(x_2,y_2)....(x_m,y_m)\} D={(x1,y1),(x2,y2)....(xm,ym)},其中 y i y_i yi是 x i x_i xi真实标记。
回归任务最常用的性能度量是均方误差:
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D)=\frac{1}{m}\displaystyle\sum_{i=1}^m(f(x_i)-y_i)^2 E(f;D)=m1i=1∑m(f(xi)−yi)2
更一般的,数据分布D和概率密度函数 p ( . ) p(.) p(.),均方误差:(此处设计积分)
E ( f ; D ) = 1 m ∫ x ∼ D ( f ( x i ) − y i ) 2 p ( x ) E(f;D)=\frac{1}{m}\displaystyle\int_{x{\sim}D} (f(x_i)-y_i)^2p(x) E(f;D)=m1∫x∼D(f(xi)−yi)2p(x)d x x x
错误率和精度
错误率
错误数/数据集总数
精度
正确数/数据集总数
查准率、查全率与F1
T: true
F:false
P:positive
N:negative
| 真实情况 | 预测结果 | |
| 正列 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率
R = T P T P + F P \frac{TP}{TP+FP} TP+FPTP
查准率又叫精确率,这里注重的是预测结果中的真例,有多少是真正的真例。就如西瓜书上所说:“挑出的西瓜中有多少比例是好瓜(真正例)”
查全率
P = T P T P + F N \frac{TP}{TP+FN} TP+FNTP
查全率又叫召回率,这里注重的是原本样本中的真例,有多少是真正的真例。就如西瓜书上所说:“所有好瓜中有多少被挑出来了”
F1度量
F β F_\beta Fβ = ( 1 + β 2 ) × P × R ( β 2 × P + R ) \frac{(1+\beta^2){\times}P{\times}R}{(\beta^2{\times}P+R)} (β2×P+R)(1+β2)×P×R
当 β > 0 \beta>0 β>0度量了查全率对查准率的相对重要性,当 β = 1 \beta=1 β=1时退化为标准的F1; β > 1 \beta>1 β>1时查全率有更大影响, β < 1 \beta<1 β<1时查准率有更大影响。
ROC与AUC
roc
我们对测试样本进行排序,最可能是正例的排在最前面,然后我们可以根据需求选择不同的截断点,排序质量的好坏体现了”一般情况下泛化性能的好坏“,roc曲线则是从这个角度出发来研究机器学习泛化能力的有力工具。
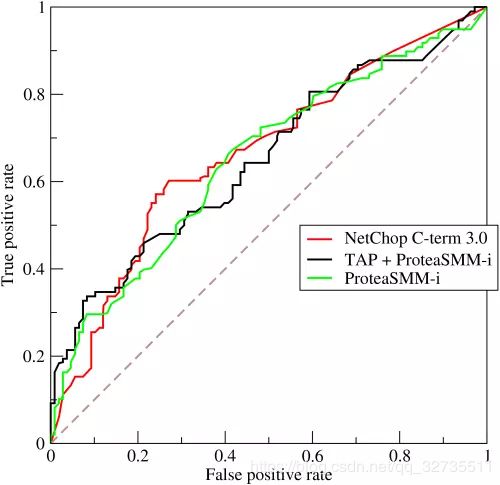
Reference: https://www.jianshu.com/p/c61ae11cc5f6
横坐标:假正例率 FPR = F P F P + T N \frac{FP}{FP+TN} FP+TNFP
纵坐标:真正例率 TPR = T P T P + F N \frac{TP}{TP+FN} TP+FNTP
如何得到ROC图:
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR)
理想情况 TPR 越趋近于1并且FPR越趋近于0,则效果越好。
auc
a u c = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ( y i + y i + 1 ) auc = \frac{1}{2}\displaystyle\sum_{i=1}^{m-1}(x_{i+1}-x_i)(y_{i}+y_{i+1}) auc=21i=1∑m−1(xi+1−xi)(yi+yi+1)
auc被定义为ROC曲线下的面积,显然不会大于1,那它意味着什么?
首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,正样本的score比负样本score大的概率就是auc值
代价敏感错误率与代价曲线
//todo
比较检验
假设检验
Reference: https://blog.csdn.net/andy_shenzl/article/details/81453509
ϵ \epsilon ϵ:泛化错误率
ϵ ^ \hat{\epsilon} ϵ^:测试错误率,意味着在m个测试样本中有 ϵ ^ × m \hat{\epsilon}\times{m} ϵ^×m个被误分类
以下公式代表, ϵ ^ × m \hat{\epsilon}\times{m} ϵ^×m个样本误分类的概率:
P ( ϵ ^ ; ϵ ) P(\hat{\epsilon};\epsilon) P(ϵ^;ϵ) = C ( m , ϵ ^ × m ) ϵ ϵ ^ × m ( 1 − ϵ ) m − ϵ ^ × m C(m,\hat{\epsilon}\times{m})\epsilon^{\hat{\epsilon}\times{m}}(1-\epsilon)^{m-\hat{\epsilon}\times{m}} C(m,ϵ^×m)ϵϵ^×m(1−ϵ)m−ϵ^×m
给定测试错误率 ϵ ^ \hat{\epsilon} ϵ^,计算如下公式:
![]()
P ( ϵ ^ ; ϵ ) P(\hat{\epsilon};\epsilon) P(ϵ^;ϵ)在 ϵ \epsilon ϵ= ϵ ^ \hat{\epsilon} ϵ^时最大,差值绝对值增大而减小, P ( ϵ ^ ; ϵ ) P(\hat{\epsilon};\epsilon) P(ϵ^;ϵ)符合二项分布。
二项检验(binomial test)
提出假设:假设泛化错误率 ϵ \epsilon ϵ< ϵ 0 \epsilon_0 ϵ0
做出检验:在 1 − α 1-\alpha 1−α概率内观测到的最大错误率如下公式
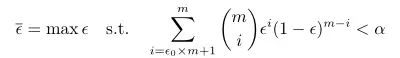
结论:
若 ϵ ^ \hat{\epsilon} ϵ^< ϵ ‾ \overline{\epsilon} ϵ(即测试错误率小于在 1 − α 1-\alpha 1−α概率内观测到的最大错误率, α \alpha α一般取值0.05,0.1),则认为能以 1 − α 1-\alpha 1−α的置信度下可认为,泛化错误率不大于 ϵ 0 \epsilon_0 ϵ0
t 检验(t-test)
经过K次训练(交叉验证/留出法),会得到k个测试错误率( ϵ ^ 1 , ϵ ^ 2 , . . . , ϵ ^ k \hat{\epsilon}_1,\hat{\epsilon}_2,... ,\hat{\epsilon}_k ϵ^1,ϵ^2,...,ϵ^k),则平均测试错误率 μ μ μ 和方差 σ 2 σ^2 σ2 为
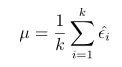
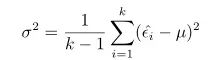
考虑到这 k 个测试错误率可看作泛化错误率 ϵ0 的独立采样,则变量
![]()
服从自由度为 k - 1 的 t 分布。(t分布概念)
对显著度 α \alpha α 和假设的错误率 ϵ 0 \epsilon_0 ϵ0,确定临界值,最后进行判断
若平均错误率与假设错误率之差位于临界值范围内,则认为能以 1 − α 1-\alpha 1−α的置信度下可认为,泛化错误率不大于 ϵ 0 \epsilon_0 ϵ0
交叉验证t检验
//todo
McNemar检验
//todo
Friedman检验与Nemenyi检验
//todo
偏差与方差
偏差:度量了学习算法的期望预测与真实结果的偏离程度
方差:度量了同样大小的数据集的变动所导致的学习性能的变化
噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差下界
泛化误差 = 偏差+方差+噪声
习题
1.数据集包含1000个样本,其中500个正例,500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
分层抽样:从500个正例中,抽70%做训练集,30%做测试集;从500个反例中,抽70%做训练集,30%做测试集。
即: C 500 150 × C 500 150 C_{500}^{150}{\times}C_{500}^{150} C500150×C500150 种划分方式
2.数据集包含100个样本,其中正反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
10折交叉验证法:因为数据集需保持一致性,所以用分层抽样法得到的数据集。即每次9份训练集中的正例反例的样本数量是一样多的,所以正确率为50%
留一法:每次只留1个作为测试集,若留正例,则测试集中反例多,会将测试集的正例预测为反例,反之亦然。错误率为 100 % 100\% 100%
4.试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
查全率: 数据集中真正的正例被预测为正例的比例
真正例率: 数据集中真正的正例被预测为正例的比例
查准率:预测结果中为正例的实例中真实正例的比例
假正例率: 真实反例被预测为正例的比例