Hadoop完全分布式集群搭建(一)
第一步、搭建三个虚拟机
如下图所示

当然,每个人的IP地址可能会有所不同
如上图,搭建完毕
第二步、配置网络
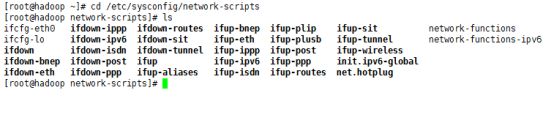
在Linux系统命令终端,执行命令cd /etc/sysconfig/network-scripts,切换到该目录并查看该目录下的文件ifcfg-eth0,如图所示
在Linx系统命令终端,执行命令 vim ifcfg-eth0,并修改文件的内容,按“键入编辑内容编译完成后按Esc键退出编译状态,之后执行命令wq,保存并退出。IPADDR、 NETMASK、 GATEWAY、DNS1的值可以根据自己的本机进行修改,如下所示。
DEVICE="eth0" #设备名字
BOOTPROTO="static" #静态ip
HWADDR="00:0C:29:ED:83:F7" #mac地址
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes" #开启自启动
TYPE="Ethernet" #网络类型
UUID="28354862-67a7-4a5b-9f9a-54561401f614"
IPADDR=192.168.11.10 #IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.11.2 #网关
DNS1=192.168.11.2 # dns
具体怎么改,我在这个链接里说过
配置静态ip
注意:三台虚拟机都要配
第四步、修改主机名和映射
启动命令终端,在任何目录下执行命令cd/ etc/sysconfig,切换到该目录并查看目录下的文件,可以发现存在文件 network,如图所示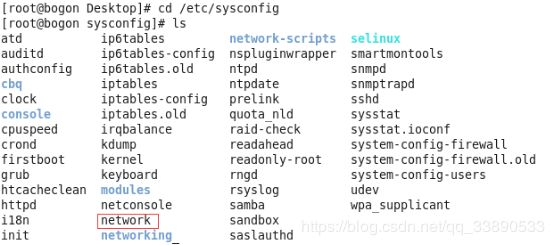
在/etc/sysconfig目录下找到文件 network,然后执行命令 vim network,按“i”进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出,后面两台也都这样,如下图所示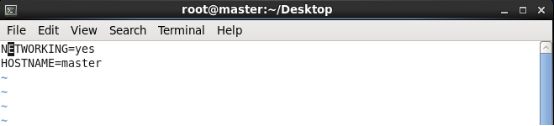
修改主机名和iP地址具有映射关系,执行命令vim/ etc/hosts,按“i”进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出,把三台的ip和主机名都编辑,如图所示
scp命令传送文件
scp /etc/hosts root@slave1:/etc/hosts
scp /etc/hosts root@slave2:/etc/hosts
把修改好的发送给slave1,再用相同的方法,发送给slave2
scp命令
scp /源文件完整路径 远程用户名@机器名: /目标文件完整路径
scp /home/space/music/1.mp3 root@slave1:/home/root/others/music
从远程复制到本地,只要将从本地复制到远程的命令的后2个参数调换顺序即可。
scp root@slave3:/home/root/others/music/1.mp3 /home/space/music
参数:

第五步、为Linux安装Java
-
启动 Linux命令终端,分别在三台虚拟机上创建目录,执行命令mkdir
/usr/java,切换到该目录下执行命令cd/usr/java -
把JDK文件jdk-8u181-linux-x64.tar.gz上传到该目录下
-
然后对/usr/java目录下的JDK压缩文件jdk-8u181-linux-x64.tar.gz,执行命令
-
对jdk-8u181-linux-x64.tar.gz进行解压
[root@hadoop java]#tar -xzvf jdk-8u181-linux-x64.tar.gz
解压之后,执行命令 Il,可以看到该目录下多了一个解压后的Jdk文件,如图

- 然后到slave1和slave2的/usr目录下看,是否有java这个目录
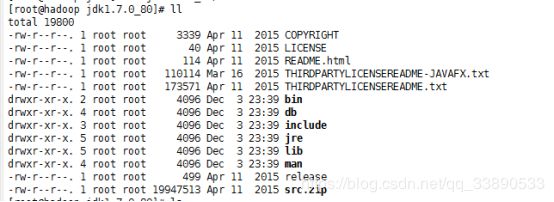
确定解压无误之后,此时需要配置JDK环境变量,执行命令 vim /etc/profile单击”i“进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出。如图
编辑完后进行配置文件刷新,执行命令 source /etc/profile,刷新配置,配置的信息才会生效,如图所示

第六步、关闭防火墙
关闭Linux防火墙有以下3个步骤:
1.查看防火墙状态
service iptables status
2. 关闭防火墙
service iptables stop
3. 永久性关闭防火墙
chkconfig iptables off
第七步、设置SSH免密
在Linux系统的终端的任何目录下通过切换cd ~/.ssh,进入到.ssh目录下,如图
~表示当前用户的home目录,通过cd ~可以进入到你的home目录。.开头的文件表示隐藏文件,这里.ssh就是隐藏目录文件。
在Linux系统命令框的.ssh目录下
[root@root .ssh]# ssh-keygen -t rsa

执行完上面命令后,会生成两个id_rsa(私钥)、id_rsa.pub(公钥)两个文件,如图所示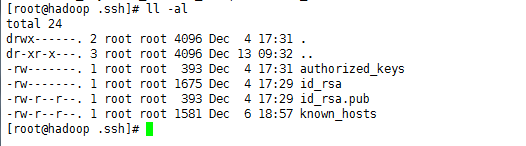
授权SSH免密码
[root@master .ssh]# ssh-copy-id master
[root@master .ssh]# ssh-copy-id slave1
[root@master .ssh]# ssh-copy-id slave2
给当前主机和其他两台都设置免密码登录,这样三台可以互通。

在master主机上执行下面的3条命令。
[root@master .ssh]# ssh master
[root@master .ssh]# ssh slave1
[root@slave1 ~]# exit
[root@master .ssh]# ssh slave2
发现不需要密码就能连接任意一台虚拟机,如图所示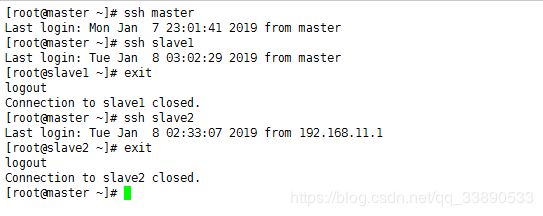
注意:当执行ssh slave1命令后,就以SSH免密方式登录到slave1。必须使用exit命令退出登录slave1,再尝试执行ssh slave2。
第八步、配置时间同步服务
NTP是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源做同步化,提供高精准度的时间校正。Hadoop集群对时间要求很高,主节点与各从节点的时间都必须要同步。配置时间同步服务主要是为了进行集群间的时间同步。Hadoop集群配置时间同步服务的步骤如下
安装NTP服务
- 在各节点执行命令 yum install -y ntp即可。若是最终出现了“Complete”信息,就说明安装NTP服务成功
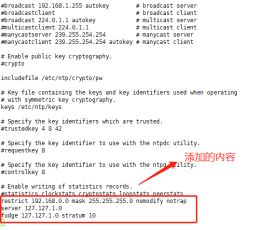
- 设置 master节点为NTP服务主节点,那么其配置如下。 使用命令“ vim /etc/ntp.conf”来打开/etc/ntp.conf文件,注释掉以 server开头的行,并添加代码所示的内容。
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
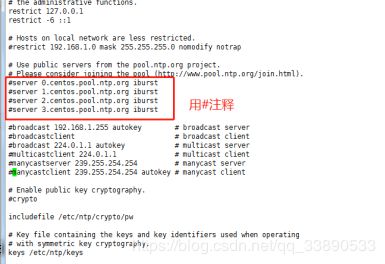
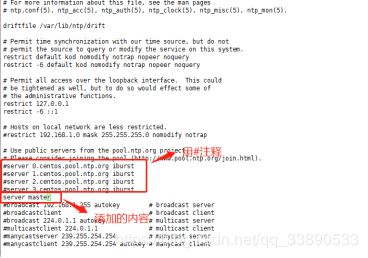
分别在slave1,slave2中配置NTP,同样修改/etc/ntp.conf文件,注释掉server开头的行,并添加下面代码所示的内容
server master
启动NTP服务
在 master节点执行命令“ service ntpd start& chkconfig ntpd on”,如下图所示,说明NTP服务启动成功

在slave1、slave2上同步时间。执行命令
ntpdate master
![]()
在 slave1、slave2上分别执行“ service ntpd start& chkconfig ntpd on”,即永久启动NTP服务,如下图所示
![]()
分别在master、slave1、slave2上分别输入date,看时间是否一致