并发编程学习笔记3——ReadWriteLock、StampedLock、CountDownLatch 和 CyclicBarrier
文章目录
- 一、ReadWriteLock
- 1.使用读写锁实现一个懒加载缓存
- 2.读写锁的升级与降级
- 二、StampedLock
- 三、CountDownLatch 和 CyclicBarrier
- 1.用 CountDownLatch 实现线程等待
- 2.用 CyclicBarrier 实现线程同步
- 3. CountDownLatch 和 CyclicBarrier 用法的区别
- 思考题
一、ReadWriteLock
读写锁类似于 ReentrantLock,也支持公平模式和非公平模式。读锁和写锁都实现了 java.util.concurrent.locks.Lock 接口,所以除了支持 lock() 方法外,tryLock()、lockInterruptibly() 等方法也都是支持的。但是有一点需要注意,那就是只有写锁支持条件变量,读锁是不支持条件变量的。
读多写少的场景,经常会使用缓存提升性能,此时读写锁往往比互斥锁性能高得多,所有的读写锁都遵守以下三条基本原则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。
1.使用读写锁实现一个懒加载缓存
class Cache<K,V> {
final Map<K, V> m =
new HashMap<>();
final ReadWriteLock rwl =
new ReentrantReadWriteLock();
final Lock r = rwl.readLock();
final Lock w = rwl.writeLock();
V get(K key) {
V v = null;
//读缓存
r.lock();
try {
v = m.get(key);
} finally{
r.unlock();
}
//缓存中存在,返回
if(v != null) {
return v;
}
//缓存中不存在,查询数据库
w.lock();
try {
//再次验证
//其他线程可能已经查询过数据库
v = m.get(key);
if(v == null){
//查询数据库
v=省略代码无数
m.put(key, v);
}
} finally{
w.unlock();
}
return v;
}
// 写缓存
V put(K key, V value) {
w.lock();
try { return m.put(key, v); }
finally { w.unlock(); }
}
}
在获取写锁之后重新验证缓存,可以避免高并发场景下重复查询数据的问题。
2.读写锁的升级与降级
读写锁不支持升级。降级是允许的。
//读缓存
r.lock();
try {
v = m.get(key);
if (v == null) {
w.lock();
try {
//再次验证并更新缓存
//省略详细代码
} finally{
w.unlock();
}
}
} finally{
r.unlock();
}
读锁还没有释放,此时获取写锁,会导致写锁永久等待,最终导致相关线程都被阻塞,永远也没有机会被唤醒。
锁的降级示例:
class CachedData {
Object data;
volatile boolean cacheValid;
final ReadWriteLock rwl =
new ReentrantReadWriteLock();
// 读锁
final Lock r = rwl.readLock();
//写锁
final Lock w = rwl.writeLock();
void processCachedData() {
// 获取读锁
r.lock();
if (!cacheValid) {
// 释放读锁,因为不允许读锁的升级
r.unlock();
// 获取写锁
w.lock();
try {
// 再次检查状态
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 释放写锁前,降级为读锁
// 降级是可以的
r.lock(); ①
} finally {
// 释放写锁
w.unlock();
}
}
// 此处仍然持有读锁
try {use(data);}
finally {r.unlock();}
}
}
这里没有解决缓存数据与源头数据的同步问题,解决数据同步问题的一个最简单的方案就是超时机制。还有一些方案采取的是数据库和缓存的双写方案。
二、StampedLock
StampedLock 支持三种模式,分别是:写锁、悲观读锁 和 乐观读。其中,写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的语义非常类似。相关的示例代码如下。
final StampedLock sl =
new StampedLock();
// 获取/释放悲观读锁示意代码
long stamp = sl.readLock();
try {
//省略业务相关代码
} finally {
sl.unlockRead(stamp);
}
// 获取/释放写锁示意代码
long stamp = sl.writeLock();
try {
//省略业务相关代码
} finally {
sl.unlockWrite(stamp);
}
StampedLock 提供的乐观读,不是乐观读锁,乐观读这个操作是无锁的,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞,所以相比较 ReadWriteLock 的读锁,乐观读的性能更好一些。
乐观读之后,通常需要再次验证一下是否存在写操作,这个验证操作是通过调用 validate(stamp) 来实现的。
/**
* 计算到原点距离
*/
class Point {
private int x, y;
final StampedLock sl =
new StampedLock();
//计算到原点的距离
int distanceFromOrigin() {
// 乐观读
long stamp =
sl.tryOptimisticRead();
// 读入局部变量,
// 读的过程数据可能被修改
int curX = x, curY = y;
//如果存在写操作
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
curX = x;
curY = y;
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(
curX * curX + curY * curY);
}
}
数据库的乐观锁:
乐观锁的实现很简单,在表里增加了一个数值型版本号字段 version,每次查询的时候把version查出来,更新这个表的时候,都将 version 字段加 1。如果这条 SQL 语句执行成功并且返回的条数等于 1,那么说明从执行查询操作到执行保存操作期间,没有其他人修改过这条数据。这个 version 字段就类似于 StampedLock 里面的 stamp。
StampedLock特性:
- StampedLock 不支持重入
- StampedLock 的悲观读锁、写锁都不支持条件变量
- 如果线程阻塞在 StampedLock 的 readLock() 或者 writeLock() 上时,此时调用该阻塞线程的 interrupt() 方法,会导致 CPU 飙升。如果需要支持中断功能,一定使用可中断的悲观读锁
readLockInterruptibly()和写锁writeLockInterruptibly()
三、CountDownLatch 和 CyclicBarrier
1.用 CountDownLatch 实现线程等待
假设有如下的对账流程:
while(存在未对账订单){
// 查询未对账订单
pos = getPOrders();
// 查询派送单
dos = getDOrders();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
这个形式是单线程执行,假设两个查询操作很费时,那么性能就会很差,大多数时间都阻塞在等待查询结果。
因为两个查询操作并没有先后顺序的依赖,所以可以并行。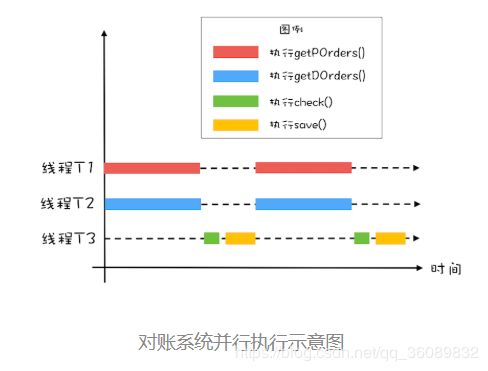
主线程需要等待线程 T1 和 T2 执行完才能执行 check() 和 save() 这两个操作,为此我们通过调用 T1.join() 和 T2.join() 来实现等待,当 T1 和 T2 线程退出时,调用 T1.join() 和 T2.join() 的主线程就会从阻塞态被唤醒,从而执行之后的 check() 和 save()。
while(存在未对账订单){
// 查询未对账订单
Thread T1 = new Thread(()->{
pos = getPOrders();
});
T1.start();
// 查询派送单
Thread T2 = new Thread(()->{
dos = getDOrders();
});
T2.start();
// 等待T1、T2结束
T1.join();
T2.join();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
while 循环里面每次都会创建新的线程,而创建线程可是个耗时的操作。可以利用线程池优化:
// 创建2个线程的线程池
Executor executor =
Executors.newFixedThreadPool(2);
while(存在未对账订单){
// 查询未对账订单
executor.execute(()-> {
pos = getPOrders();
});
// 查询派送单
executor.execute(()-> {
dos = getDOrders();
});
/* ??如何实现等待??*/
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
在线程池的方案里,线程根本就不会退出,所以 join() 方法已经失效了。可以使用 CountDownLatch 来实现线程等待。
// 创建2个线程的线程池
Executor executor =
Executors.newFixedThreadPool(2);
while(存在未对账订单){
// 计数器初始化为2
CountDownLatch latch =
new CountDownLatch(2);
// 查询未对账订单
executor.execute(()-> {
pos = getPOrders();
latch.countDown();
});
// 查询派送单
executor.execute(()-> {
dos = getDOrders();
latch.countDown();
});
// 等待两个查询操作结束
latch.await();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
对计数器减 1 的操作是通过调用 latch.countDown(); 来实现的。在主线程中,我们通过调用 latch.await() 来实现对计数器等于 0 的等待。
2.用 CyclicBarrier 实现线程同步
前面我们将 getPOrders() 和 getDOrders() 这两个查询操作并行了,但这两个查询操作和对账操作 check()、save() 之间还是串行的。很显然,这两个查询操作和对账操作也是可以并行的。
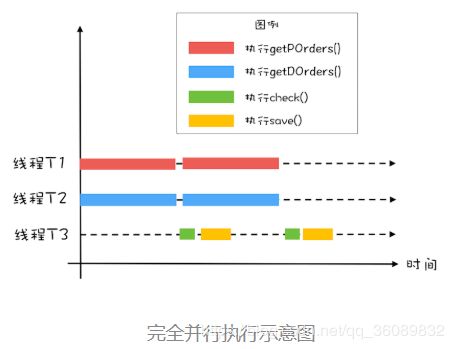
这明显有点生产者 - 消费者的意思,两次查询操作是生产者,对账操作是消费者。既然是生产者 - 消费者模型,那就需要有个队列,来保存生产者生产的数据,而消费者则从这个队列消费数据。
这里设计了两个队列,便于有一一对应的关系。这里还隐藏着一个条件,当线程 T1 和 T2 都生产完一条数据的时候,还要能够通知线程 T3 执行对账操作。而且线程 T1 和线程 T2 的工作要步调一致,不能一个跑得太快,一个跑得太慢,只有这样才能做到各自生产完 1 条数据的时候,通知线程 T3。
首先创建了一个计数器初始值为 2 的 CyclicBarrier,创建 CyclicBarrier 的时候,还传入了一个回调函数,当计数器减到 0 的时候,会调用这个回调函数。
- 线程 T1 负责查询订单,当查出一条时,调用
barrier.await()来将计数器减 1,同时等待计数器变成 0; - 线程 T2 负责查询派送单,当查出一条时,也调用
barrier.await()来将计数器减 1,同时等待计数器变成 0; - 当 T1 和 T2 都调用
barrier.await()的时候,计数器会减到 0,此时会调用 barrier 的回调函数来执行对账操作,然后 CyclicBarrier 的计数器有自动重置的功能,会自动重置你设置的初始值。此时 T1 和 T2 就会执行下一条语句了,
// 订单队列
Vector<P> pos;
// 派送单队列
Vector<D> dos;
// 执行回调的线程池
Executor executor =
Executors.newFixedThreadPool(1);
final CyclicBarrier barrier =
new CyclicBarrier(2, ()->{
executor.execute(()->check());
});
void check(){
P p = pos.remove(0);
D d = dos.remove(0);
// 执行对账操作
diff = check(p, d);
// 差异写入差异库
save(diff);
}
void checkAll(){
// 循环查询订单库
Thread T1 = new Thread(()->{
while(存在未对账订单){
// 查询订单库
pos.add(getPOrders());
// 等待
barrier.await();
}
});
T1.start();
// 循环查询运单库
Thread T2 = new Thread(()->{
while(存在未对账订单){
// 查询运单库
dos.add(getDOrders());
// 等待
barrier.await();
}
});
T2.start();
}
3. CountDownLatch 和 CyclicBarrier 用法的区别
- CountDownLatch 主要用来解决一个线程等待多个线程的场景
- CyclicBarrier 是一组线程之间互相等待
- CountDownLatch 的计数器是不能循环利用的,也就是说一旦计数器减到 0,再有线程调用 await(),该线程会直接通过。但 CyclicBarrier 的计数器是可以循环利用的,而且可以设置回调函数。
注:CyclicBarrier 计数器变为0 时,先执行回调函数,然后再执行各个线程 await 语句之后的内容。
思考题
1、StampedLock 支持锁的降级(通过 tryConvertToReadLock() 方法实现)和升级(通过 tryConvertToWriteLock() 方法实现),但是建议你要慎重使用。下面的代码隐藏了一个 Bug,你来看看 Bug 出在哪里吧。
private double x, y;
final StampedLock sl = new StampedLock();
// 存在问题的方法
void moveIfAtOrigin(double newX, double newY){
long stamp = sl.readLock();
try {
while(x == 0.0 && y == 0.0){
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
x = newX;
y = newY;
break;
} else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
答:锁升级成功时,没有释放最新的写锁,可以再break语句前加 stamp = ws;
2、上面 CyclicBarrier 的示例代码中,回调函数里使用了一个固定大小的线程池,你觉得是否有必要呢?
答:有必要。回调函数是在 使得计数器变为0 的那个线程中同步执行的,执行完回调函数,两个查询线程才会继续执行await 之后的语句,所以如果不使用线程池,就等于没有完全并行。
参考资料:王宝令----Java并发编程实战