关于MySQL的索引机制
正确创建合适的索引是数据库优化的基础
全值匹配我最爱, 最左前缀要遵守
带头大哥不能死, 中间兄弟不能断
索引列上少计算, 范围之后全失效
Like百分写最后, 覆盖索引不写 *
不等空置还有or, 索引失效要少用
索引的本质
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
在关系型数据库管理系统( RDBMS )中, 数据的索引( 大部分 )都是硬盘级索引( InnoDB中少部分加载在内存中 )
索引的工作机制
数据结构的性能特点, 决定了数据的检索性能

若未创建索引, 就会执行全表扫描, 0(n) 的时间复杂度, 创建索引后可以根据id快速定位磁盘地址
数据结构:
hash表
hash索引( key进行hashcode 得到一个数组的下标 )的优劣势:
基于下标检索, 查询快( 时间复杂度为0(1), 要么命中要么不命中 )
hash冲突
不支持范围查询( like < > )
树形结构
- 二叉搜索树 -----不平衡
结构演示: https://www.cs.usfca.edu/~galles/visualization/BST.html
通过与每个值进行比对, 大于或者小于, 去向不同的分叉(小于该值去左叉, 大于该值去右叉, 若该值有分叉, 则也会比较该分叉上的值, 即新加入的值都在该树的最底端)
若查询38号, 则将55加入内存比较, 小于走左边, 再将30加入内存中比较, 大于走右边, …直到找到38号, 而55号的右分支则不会走, 大大加快检索速度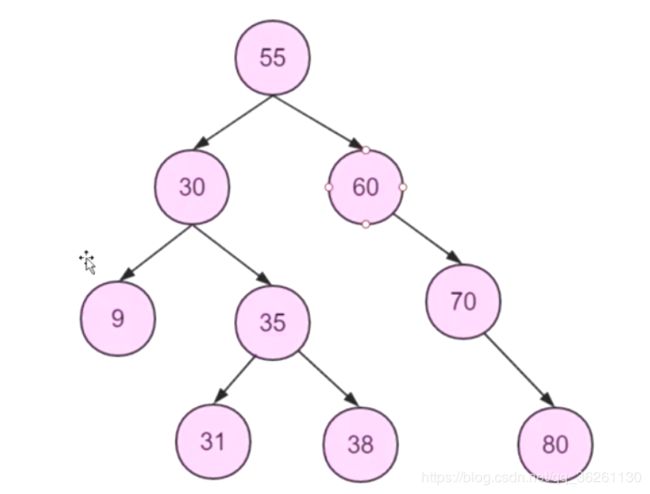
一颗特殊二叉树, 比如我们表中的自增ID主键, 若基于该列创建索引会形成下面这个递增树, 若查询ID为4 的数据, 则需要将该右支索引递归一边, 相当于全表扫描 
缺陷 :
- 二叉树结构作为索引机制会形成一个不稳定的树结构(链表结构), 数据的搜索过程相当于O(n)的时间复杂度, 不友好
- 平衡二叉搜索树 ----相对平衡
结构演示: https://www.cs.usfca.edu/~galles/visualization/AVLtree.html

针对树中的某个节点, 其子节点的高度差不超过1, 即左右分支的层高相差不允许超过1, 例如20节点, 该节点左支高度为1, 右支高度为0, 差值为1
新增树节点时, 会先按照二叉树方式进行插入, 当左右分支高度差大于1时, 再通过节点的旋转等操作来保证树的相对平衡
若搜索8号, 先将10号(磁盘块1)加入内存, 关键字进行比对, 小于则通过P1节点引用到左分支, 再将5号(磁盘块2)加入内存并比对, …匹配到8号后找数据区(可以存指针地址, 也可以存相应具体的数据)
缺陷:
- 树的高度太高, 磁盘IO操作频繁, 每次比对都要将磁盘块加入内存中, 硬盘级索引影响性能
- 没有利用好操作系统跟磁盘的交互特性, 造成空间浪费( 操作系统与磁盘交互, 去磁盘读数据以页为单位, 一页至少4KB空间, 所以每做一次IO交互就是操作4KB的数据内容, 而且每个节点块只存储一个关键字, 一个数据区, 两个子节点, 大部分空间浪费)==
- 多路平衡树( B树 ) ----绝对平衡
结构演示: https://www.cs.usfca.edu/~galles/visualization/BTree.html
所有子节点的高度都在同一水平线上, 每个节点有两个或者两个以上的支路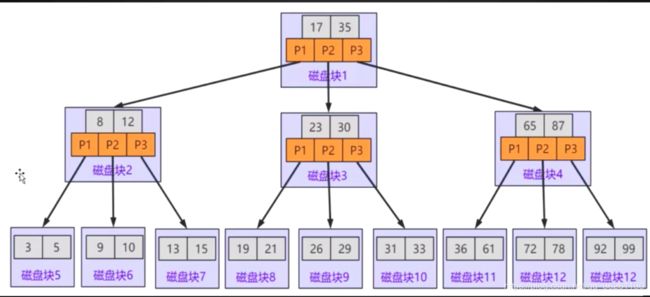
以根节点为例:
基于两个关键字, 将数据区间划分5个:
无穷小---->17
17
17------>35
35
35-------->无穷大
若查询19号, 先将磁盘块1写入内存, 与区间进行比对, 在17-35区间, 通过P2子节点引用到中间分支, 再将磁盘块3写入内存, 区间比对,…匹配到19号后找到磁盘块中的数据区拿内容
该节点关键字的个数 = 该节点的分支路数 - 1
优点:
- B树将二叉树的瘦高型变成了矮胖型, 关键字更多, 支路更多, 层数也更少,
- 操作系统跟磁盘IO交互以页为单位( 一页至少4KB ), 一个int类型的关键字是4byte, 假设数据区和引用区为4byte, 则一页可以存储( 4096byte / 8 byte ) 500多个关键字, 即500多个支路数
通过节点的分裂合并操作来保证树的绝对平衡
不要在经常变化的列上建立索引, 因为频繁添加或者修改数据时, 要不断去分裂合并去改变结构, 来保证树的平衡
- 加强版多路平衡树( B+树 )
结构演示: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
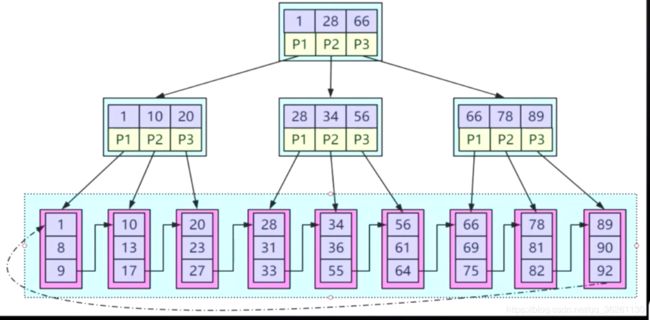
以根节点为例:
基于三个关键字, 将数据区间划分3个:
左闭合
1 <= X < 28
28 <= X < 66
66 <= X
因为在MySQL定制的B+数中, 根节点和支节点没有数据区, 所有数据区都在最后一层的叶子节点上, 所以即使在根节点或者支节点匹配到该关键字, 也不会停留, 会一直往下查找到叶子节点数据区获取内容
优点:
- IO能力强于B树, 每个节点块可以存储更多的关键字, 操作一次磁盘IO更易精准获取到内容
- 基于索引结构, 扫库扫表能力强于B树, 在B树中根节点, 支节点, 叶子节点都需要扫描, 因为每个节点块都有数据区, 而B+树只需要扫描叶子节点
- 范围查询, 强于B树, 叶子节点末尾形成天然有序的链表结构
- 查询性能稳定度强于B树, 在B+树中, 由于数据区都在叶子节点, 所以操作IO的次数一定是固定的, 而B树则不一定, 有时候一次, 有时候多次
插拔式存储引擎
--查看数据库的存储地址
SHOW VARIABLES LIKE 'datadir'

MyISAM
每个叶子节点的数据区保存的是数据所在的地址
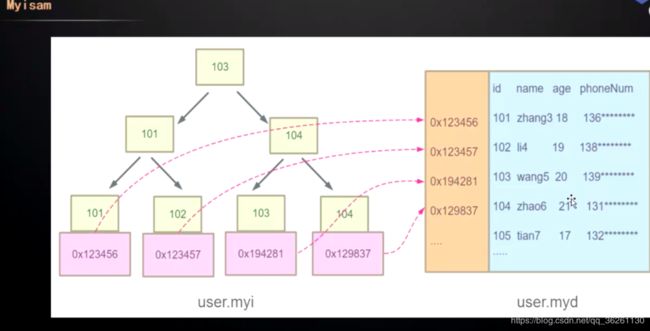
MyISAM引擎有两个文件, .myi为索引文件, .myd为数据文件, 若创建索引, 则会在myi文件中生成基于该字段为关键字的B+树
主键索引与辅助索引没有主次之分, 搜索过程都一样,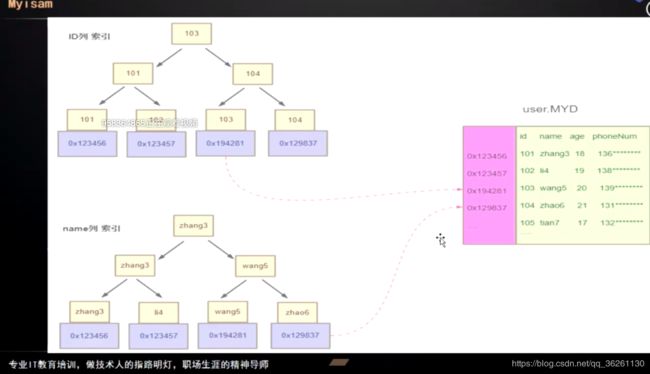
InnoDB
每个叶子节点的数据区保存的是具体的内容
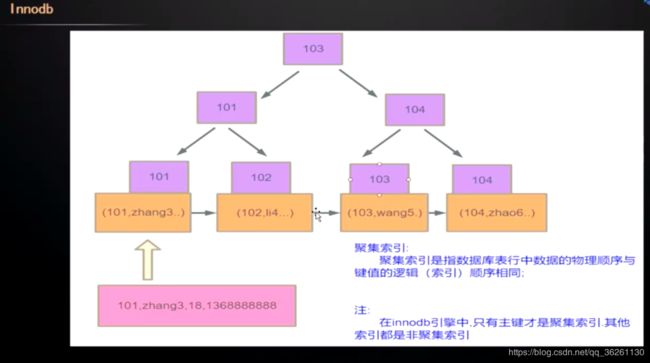
- 只有主键索引的叶子节点数据区存储的才是该行的所有数据, 关键字是索引列, 像这种数据组织方式被称为聚集索引
- 辅助索引的叶子节点数据区存储的是主键值, 关键字是索引列, 会基于主键值二次搜寻找到其他值( 回表 )
- 为什么辅助索引的叶子节点不存储地址, 直接获取内容而不是再根据主键查找, 因为B+树是绝对平衡树, 索引树中节点会为了保持平衡而不断分裂合并, 使结构不断变化, 若是这样, 那要不断去维护更新辅助列的地址值, 主键索引是最主要的, 不能去一直维护其他辅助索引
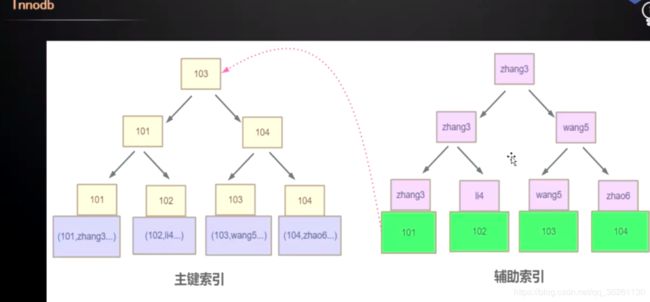
innoDB支持BTree索引不支持hash索引, 但是该引擎可以自适应hash索引

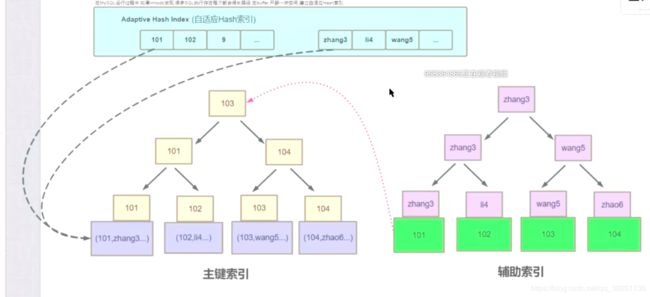
在MySQL运行过程中, 如果InnoDB发现很多SQL执行时, 存在每次都会访问很长的路径(层数过多, 每次执行都是固定次数的IO操作), 会在buffer开辟一块空间, 建立自适应Hash索引, 即将该值与真正的地址做一个对应, 当下次访问发现已经存在自适应Hash索引中, 就会基于该值快速定位而不是再进行查
其他
列的离散性
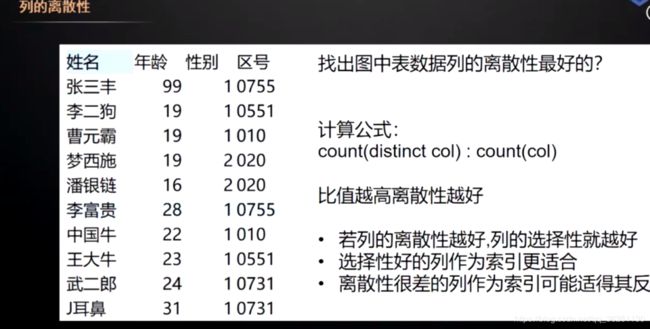
- 重复率越高, 离散性越差, 离散性很差的列作为索引可能会适得其反
- 离散性越好, 选择性越好(查询时, 到每一个节点, 去哪个方向很明确, 而不是模糊的去哪边都可以), 选择性好的列更适合做索引
explain 执行计划 type=range, 基于索引的范围查询都会考虑离散性
例如: 语句 select * from where name like ‘123%’, 能用索引吗 ?
用离散性去分析, 则不一定, 若有100万数据, 90万的name都是以123开头的, 则全表扫描比, 先基于索引树找到主键, 再根据主键去主键索引树查询值, 更有效
最左匹配
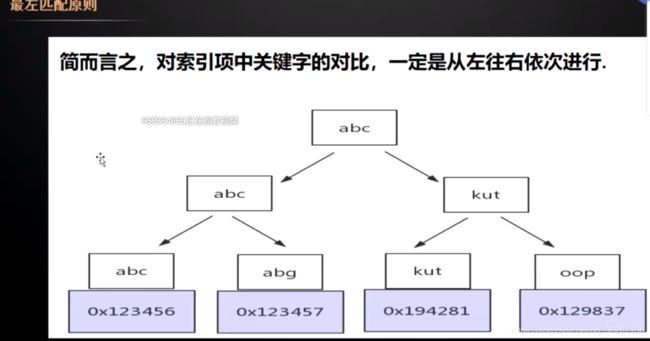
从左往右, 一个字符一个字符的去比对
联合索引

例如:
create index (name)
则索引树中的节点关键字为单列
张三
李四
…
create index(name, phoneNum)
则则索引树中的节点关键字为多列
张三, 13574987451
李四, 14787562112
…
思考题: 会匹配联合索引中的name, phoneNum列, 而不会用到age列, 因为后边的phoneNum是范围查询,age的选择性就会很差, 离散性很差, 就不会用到索引

第一个索引是冗余索引, 因为第二个联合索引已经包含第一个索引
覆盖索引

三星索引

第一: 联合索引, 覆盖索引
第二: 排序尽量使用叶子节点天然有序的结构
第三: 避免回表
每一条SQL语句, 一般都只会用一个索引进行搜索
name = ’ *** ’ OR age = **
OR的条件, 在MySQL中, 有可能存在合并, type = index_merage, 即会先将通过name索引查询到的数据放在内存中, 再通过age索引去查询