【python】如何用 numpy 实现 CNN
【python】如何用 numpy 实现 CNN
文章目录
- 【python】如何用 numpy 实现 CNN
- 后续更新日志
- 前言
- gitee 仓库地址
- 设计约定
- numpy
- 损失函数
- Reshape 层
- 激活函数层
- 激活函数层
- 激活函数
- sigmoid
- ReLU
- softmax
- 全连接层
- 池化层
- 卷积层
- 卷积
- 卷积层的反向传播
- 多通道情况下卷积层的正向与反向传播
- stride 不为1的情况
- 代码
- 神经网络
- 测试
后续更新日志
- 2019-9-29 更新:
发现我以前对多通道卷积的理解有误
我之前以为输入 size 为 (inCh, width, height) ,输出通道为 outCh 的卷积层 使用 outCh 个 (kernelWidth,kernelHeight) 的卷积核,其中输入的的每一个通道共享同样的卷积核参数。在 MNIST 数据集上做测试,这样虽然参数少,但确实有一定效果。
但实际上,正确的理解是“使用 outCh 个 (inCh, kernelWidth, kernelHeight) 的卷积核”(Tensorflow,BigDL 里都是这样实现的,最近才注意到,于是我不得不重新思考),参数总数整整多了 inCh 倍。
看来卷积神经网络相对于对应的全连接神经网络,参数数量比应该为:(kW*kH / W*H),并没有我之前理解的那样有着极为夸张的参数量缩减率。如果是 FCN(全卷积网络),参数数量和对应全连接网络是同一个级别。
- 2020-5-23 更新:
这几个月折腾了保研、毕设等各种事情后,我终于想起填这个坑了(不鸽了不鸽了——指鸽了8个月)。
主要是修改之前卷积层出问题的部分。当时用BigDL写了个AlexNet在Spark集群上跑,发现占用的内存和我预计的差别很大,这才发现我一直理解错了。
另外,之后我又看到几篇不错的博客:
- 关于多通道卷积问题的,讲得简单易懂:卷积神经网络CNN(卷积池化、感受野、共享权重和偏置、特征图)
- 另一个人用numpy实现了CNN,并写了一系列博客。习惯直接看公式的可以看看,写的很不错:numpy实现神经网络系列
PS:
- 本科生活结束了,不想留下遗憾,所以计划在学期结束前改好。
- 因为新冠疫情宅在家中写毕设,前几天终于搞定了,现在相对有空。
前言
这篇博客适用于对神经网络概念有一定了解的同学。
https://blog.csdn.net/qq_36393962/article/details/99354969
+++++++++++++++++++++++++ 分割线 +++++++++++++++++++++++++
隔了好久没接触深度学习了,得重新理一理基础知识。顺便久违地认真写写博客 (✪ω✪)
之前只是使用 tensorflow 或者 pytorch 这样的深度学习框架。但对我来说,他们只是黑盒。我一直只是粗略地对其工作机制有所了解。一直想自己手写实现一个简单的网络框架,但由于很多事【懒】耽搁了。
这次在百度和google里广搜大量博客知乎,理清我以前没在意过的细节问题(期间发现我以前对某些细节概念是完全理解错了,比如矩阵求导)。然后花了2天终于用 numpy 实现了一个简单的 CNN。 其实我实现的是一个简单的神经网络框架,包括损失函数(sse),激活函数层(sigmoid, softmax, relu),全连接层,池化层(mean-pooling),卷积层。
gitee 仓库地址
https://gitee.com/bitosky/numpy_cnn
设计约定
- 只用 python + numpy
- 使用 numpy 行向量
- 输入张量各维度含义为 (rows, columns, channels)
- 设计上,把网络层单独抽象出来,作为一个编程单元。(以前没接触 DL 框架的时候把整个网络写成一个类,学长建议我把它拆开来| ・ω・ ))
- 激活函数单独作为一层
dc_dz表示C对z求偏导- 按照大部分公式的约定,c 表示代价,z 表示网络层输出,a 表示激活函数值,也是下一层网络层输入(也用 x 表示),w 为权重,b 为偏置
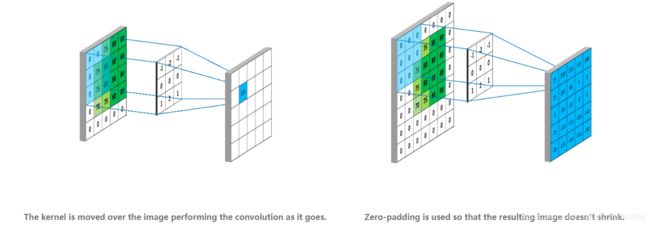
- 如果没有特别说明,卷积指的是"valid"卷积(下图描述了"valid"和"full"卷积的区别 https://mlnotebook.github.io/post/CNN1/)
- 尽量做到使用 layers 构建网络时,可以自动设定尺寸相关的超参数(如自动识别 input_size)
- 激活函数正向传播相对应的方法为
__call__,反向传播(求导)相应方法为derivate
# (funcs.py)
#激活函数
class Func:
def __init__(self,f:FunctionType,f_derivate:FunctionType,jacobin=False):
self.f = f
self.f_derivate = f_derivate
self.jacobin = jacobin # True 表明f导数将使用雅克比矩阵进行表示
def __call__(self,z):
return self.f(z)
def derivate(self,z):
return self.f_derivate(z)
- 网络层正向传播相对应的方法为
__call__,反向传播相应方法为backward
# (layers.py)
class Layer:
@abstractmethod
def __call__(self, x: np.ndarray) -> np.ndarray:
pass
@abstractmethod
def backward(self, d: np.ndarray) -> np.ndarray:
pass
numpy
- numpy 基础
菜鸟教程网址:https://www.runoob.com/numpy/numpy-tutorial.html
一般使用 numpy 用这一句: import numpy as np
关于 numpy 主要是掌握它的广播特性。
由于 numpy 底层是 C,用好广播特性可以代替 python for 循环做很多工作,而且性能提升极大。
- np.einsum
知乎网址:https://zhuanlan.zhihu.com/p/27739282
einsum 是 Einstein summation convention(爱因斯坦求和约定)的缩写。
这是一个极为方便的 api,用它可以实现一些难以描述的矩阵运算,可以用于卷积层的实现。
# 用 numpy 实现卷积神经网络的时候,需要涉及到多通道的卷积运算
# 但是 numpy 似乎没有直接提供相应 api
# np.convolve 只能用于简单的一维卷积
# 用纯 python 实现又非常慢
# 这时候可以想到用 np.einsum 实现这种比较复杂的矩阵运算
# 下面 mm 是一个卷积区域(2x2,2通道),nn 是卷积核 (2x2,3通道)
# 运算后得到(1x1,3通道)
mm = np.array(
[
[[1,2], [1,2]],
[[1,2], [1,2]]
]
)
nn = np.array(
[
[[1,2,3], [1,2,0]],
[[1,2,3], [1,2,3]]
]
)
print(np.einsum("ijk,ijl->l",mm,nn,dtype=np.float64))
# 结果: [12 24 27]
损失函数
我就实现了一个最简单,最基本的 sse
一般来说,应该使用交叉熵损失函数。
可以自己设计一个更好的,加快收敛或者提升准确度。
不过损失函数本身是非常讲究的,有时候会加个正则项来防止过拟合。相关的博客数不胜数,这里就不展开讲了。
某些特殊的网络会用一些比较特别的损失函数,比如 GAN(生成对抗网络)。有兴趣可以了解一下,这里是一篇知乎网址:https://zhuanlan.zhihu.com/p/27295635。
# 损失函数
class LossFunc:
def __init__(self,f:FunctionType,f_derivate:FunctionType):
self.f = f
self.f_derivate = f_derivate
def __call__(self,label,predict):
return self.f(label,predict)
def derivate(self,label,predict):
return self.f_derivate(label,predict)
# sse
def f_sum_of_squared_error(label,predict):
return (label-predict)**2
def f_sum_of_squared_error_derivate(label,predict):
return 2*(predict-label)
# 平方和误差
sse = LossFunc(
f_sum_of_squared_error,
f_sum_of_squared_error_derivate
)
Reshape 层
主要用于卷积层和全连接层的衔接
from_shape 可以为 None,在输入第一个 x 后自动获取 shape
to_shape 般就是 (1,-1) ,因为全连接层的输入就是一个 一维张量(表示成二维只是因为更方便使用 array.dot)
class ReshapeLayer(Layer):
def __init__(self, from_shape, to_shape):
self.from_shape = from_shape
self.to_shape = to_shape
def __call__(self, x: np.ndarray) -> np.ndarray:
if self.from_shape is None:
self.from_shape = x.shape
return x.reshape(self.to_shape)
def backward(self, d: np.ndarray) -> np.ndarray:
return d.reshape(self.from_shape)
激活函数层
激活函数层
- 正向公式:
a l = f ( z l ) a^{l} = f(z^{l}) al=f(zl) - 反向公式:
∂ C ∂ z l = ∂ C ∂ a l ∂ a l ∂ z l = ∂ C ∂ a l f ′ ( z l ) \frac{\partial{C}}{\partial{z^{l}}} = \frac{\partial{C}}{\partial{a^{l}}} \frac{\partial{a^{l}}}{\partial{z^{l}}} = \frac{\partial{C}}{\partial{a^{l}}} f^{'}(z^l) ∂zl∂C=∂al∂C∂zl∂al=∂al∂Cf′(zl) - 代码:
class FuncLayer(Layer):
def __init__(self, activate_fn: Func):
self.f = activate_fn
self.z: np.ndarray = None
def __call__(self, x: np.ndarray) -> np.ndarray:
self.z = x
return self.f(x)
def backward(self, dc_da: np.ndarray) -> np.ndarray:
da_dz = self.f.derivate(self.z)
if self.f.jacobin:
# 如果求导结果只能表示成雅克比矩阵,得使用矩阵乘法
dc_dz = dc_da.dot(da_dz.T)
else:
# 求导结果为对角矩阵,可以采用哈达马积(逐值相乘)来简化运算
dc_dz = dc_da * da_dz
return dc_dz
激活函数
激活函数非常多,我这里只讨论3个: sigmoid、relu、softmax
sigmoid
-
正向公式:
a = 1 1 + e − z a = \frac{1}{1+e^{-z}} a=1+e−z1 -
求导公式:
由正向传播公式可知,z_i 只与 a_i 有关,所以 ∂ a ∂ z \frac{\partial{a}}{\partial{z}} ∂z∂a 一定是一个对角雅克比矩阵,可以简化。把对角线上元素拿出来构造一个向量,作为 ∂ a ∂ z \frac{\partial{a}}{\partial{z}} ∂z∂a 的结果,参与运算。不过矩阵乘法要换成哈达马积(Hadamard product),“逐值相乘”。像这个公式里出现的圆形符号就表示哈达马积: W T ( ∂ C ∂ a i ⊙ f ′ ( z i ) ) W^{T} (\frac{\partial{C}}{\partial{a_{i}}} \odot f^{'}(z_i)) WT(∂ai∂C⊙f′(zi))。
sigmoid 的导数很独特,可以用 a 来表示:
∂ a ∂ z = ( 1 1 + e − z ) ⊙ ( 1 − 1 1 + e − z ) = a ⊙ ( 1 − a ) \frac{\partial{a}}{\partial{z}} = (\frac{1}{1+e^{-z}})\odot(1-\frac{1}{1+e^{-z}})=a\odot(1-a) ∂z∂a=(1+e−z1)⊙(1−1+e−z1)=a⊙(1−a)
- 代码
# (funcs.py)
# sigmomid
def f_sigmoid(z):
return 1.0/(1.0 + np.exp(-z))
def f_sigmoid_derivate(z):
y = f_sigmoid(z)
return y*(1-y)
sigmoid = Func(f_sigmoid,f_sigmoid_derivate)
ReLU
百度百科:线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
-
正向公式:
a = m a x i u m ( 0 , z ) a = maxium(0,z) a=maxium(0,z) -
求导公式:
和 sigmoid 同理,可以从对角雅克比矩阵简化为和 z 同维向量
( ∂ a ∂ z ) i = { 0 , z i < 0 0.5 , z i = 0 1 , z i > 0 (\frac{\partial{a}}{\partial{z}})_i = \begin{cases} 0, &z_i \lt 0 \cr 0.5, &z_i = 0 \cr 1, &z_i \gt 0 \end{cases} (∂z∂a)i=⎩⎪⎨⎪⎧0,0.5,1,zi<0zi=0zi>0
- 代码
# (funcs.py)
# relu
def f_relu(z):
return np.maximum(z, 0)
def f_relu_derivate(z):
return np.heaviside(z,0.5)
relu = Func(f_relu,f_relu_derivate)
softmax
推荐看博客 Softmax函数及其导数 ,里面有关于向量对向量求导、向量对矩阵求导的雅克比矩阵形式的描述: https://blog.csdn.net/cassiePython/article/details/80089760
- 正向公式:
a = e z ∑ i n e z i a = \frac{e^{z}}{\sum\limits_{i}^{n}{e^{z_i}}} a=i∑neziez
不过由于 exp(x) 具有指数级增长性,计算结果容易超出浮点数的表示范围(比如 exp(500)),numpy 会将这种结果表示为 nan (not a number)。解决办法是分子分母同时乘以一个数,压低数值大小。比如,使用 -exp(max(z))。
a = e z − m a x ( z ) ∑ i n e z i − m a x ( z ) a = \frac{e^{z-max(z)}}{\sum\limits_{i}^{n}{e^{z_i-max(z)}}} a=i∑nezi−max(z)ez−max(z) - 求导公式:
softmax 的求导结果不是一个对角矩阵,所以无法像上面两个激活函数一样写成简化后的形式。
∂ a j ∂ z i = { a i ( 1 − a j ) , i = j − a i a j , i ≠ j = a i ( 1 ( i = j ) − a j ) \begin{aligned} \frac{\partial{a_j}}{\partial{z_i}} &= \begin{cases} a_i(1-a_j), &i = j \cr -a_ia_j, &i \neq j \end{cases}\\ &= a_i(1(i=j)-a_j) \end{aligned} ∂zi∂aj={ai(1−aj),−aiaj,i=ji=j=ai(1(i=j)−aj)
或写成矩阵形式:
∂ a ∂ z = a I − a T a \frac{\partial{a}}{\partial{z}} = aI-a^Ta ∂z∂a=aI−aTa - 代码
# (funcs.py)
# softmax
def f_softmax(z):
# 直接使用np.exp(z)可能产生非常大的数以至出现nan
# 所以分子分母同时乘以一个数来限制它
# 这里用 exp(-np.max(z))
exps = np.exp(z-np.max(z))
exp_sum = np.sum(exps)
return exps/exp_sum
def f_softmax_derivate(z):
y = f_softmax(z).reshape((-1,))
return np.diag(y)-y.reshape((-1,1)).dot(y.reshape(1,-1))
# softmax 导数只能用雅克比矩阵表示,无法简化
softmax = Func(f_softmax,f_softmax_derivate,True)
全连接层
- 正向公式:
x = a l − 1 z l = x W l + b l x = a^{l-1} \\ z^l = xW^l + b^l x=al−1zl=xWl+bl - 反向公式:
∂ C ∂ x = ∂ C ∂ z l ∂ z l ∂ x = ∂ C ∂ z l ( W l ) T \frac{\partial{C}}{\partial{x}} = \frac{\partial{C}}{\partial{z^{l}}} \frac{\partial{z^{l}}}{\partial{x}} = \frac{\partial{C}}{\partial{z^{l}}} (W^l)^T ∂x∂C=∂zl∂C∂x∂zl=∂zl∂C(Wl)T - 参数更新公式:
偏 置 : ∂ C ∂ b l = ∂ C ∂ z l ∂ z l ∂ b l = ∂ C ∂ z l 偏置: \frac{\partial{C}}{\partial{b^l}} = \frac{\partial{C}}{\partial{z^{l}}} \frac{\partial{z^{l}}}{\partial{b^l}} = \frac{\partial{C}}{\partial{z^{l}}} 偏置:∂bl∂C=∂zl∂C∂bl∂zl=∂zl∂C
权 重 : ∂ C ∂ W l = ∂ C ∂ z l ∂ z l ∂ W l = x T ∂ C ∂ z l 权重: \frac{\partial{C}}{\partial{W^l}} = \frac{\partial{C}}{\partial{z^{l}}} \frac{\partial{z^{l}}}{\partial{W^l}} = x^T \frac{\partial{C}}{\partial{z^{l}}} 权重:∂Wl∂C=∂zl∂C∂Wl∂zl=xT∂zl∂C
注意权重公式也是被化简过的。因为一个 T 维行向量对一个 MxN 矩阵求导后得到的是一个 MNxT 雅克比矩阵(其实是把 MxN 矩阵一维展开成 MN 维行向量后,再求导) ,所以上面公式实际上应该写成如下形式(注意这里所有向量为行向量形式):
权 重 ( 一 维 展 开 ) : ∂ C ∂ W l = ∂ C ∂ z l ∂ z l ∂ W l = ∂ C ∂ z l × [ x T ⋱ x T ] T 权重(一维展开): \frac{\partial{C}}{\partial{W^l}} = \frac{\partial{C}}{\partial{z^{l}}} \frac{\partial{z^{l}}}{\partial{W^l}} = \frac{\partial{C}}{\partial{z^{l}}} \times \left[ \begin{matrix} x^T& & \\ & \ddots & \\ & & x^T \end{matrix} \right]^T 权重(一维展开):∂Wl∂C=∂zl∂C∂Wl∂zl=∂zl∂C×⎣⎡xT⋱xT⎦⎤T
但细心计算可以发现:
v 0 × [ v T ⋱ v T ] T = 一 维 展 开 ( v 0 T × v ) v_0 \times \left[ \begin{matrix} v^T& & \\ & \ddots & \\ & & v^T \end{matrix} \right]^T = 一维展开(v_0^T \times v) v0×⎣⎡vT⋱vT⎦⎤T=一维展开(v0T×v)
所以能写成简化形式(同时极大地减小了运算量):
一 维 展 开 ( ∂ C ∂ W l ) = ∂ C ∂ z l × [ x T ⋱ x T ] T = 一 维 展 开 ( x T ∂ C ∂ z l ) 一维展开(\frac{\partial{C}}{\partial{W^l}}) = \frac{\partial{C}}{\partial{z^{l}}} \times \left[ \begin{matrix} x^T& & \\ & \ddots & \\ & & x^T \end{matrix} \right]^T= 一维展开(x^T \frac{\partial{C}}{\partial{z^{l}}}) 一维展开(∂Wl∂C)=∂zl∂C×⎣⎡xT⋱xT⎦⎤T=一维展开(xT∂zl∂C)
- 代码:
(1) 注意一个问题:如何对网络参数进行随机初始化?
网络参数在训练过程中会向“好”的方向转变,但如果一开始就错的离谱,则需要更多轮迭代。
我曾经写神经网络(尤其是卷积神经网络),参数随便初始化(比如取 0-1 均匀分布),结果总是难以收敛。有时候出现输出全 0.999…,还以为是网络结构或者代价函数写错了。
一般来说,网络参数初始化选的是 均值为 0 的正态分布,标准差我一般用1(也就是标准正态分布)。
(2) 别忘了对输入进行 标准化(standardization)或者归一化(normalization)
神经网络本质上就是将一个分布转化为另个一分布的过程,如果分布差的远,转化的难度自然上升很多。道理和上面的一样,但是后果一般更严重。
输入在放缩(scaling)之前往往范围比较大,有的全是比较大的正数(最典型的是图像,全是 0-255 的正数,当然,这不算大),经过矩阵乘法后很容易出现大的离谱的数。这对训练很不利。比如使用 sigmoid 激活函数,sigmoid(10000) 处,斜率已经很接近0了,需要多轮迭代才能调好。
总之,入深度学习的坑,一定要对 “分布” 这词特别敏感。(最好把概率论学好来。。我就没咋学好,准备补一补 --------- 感觉他们数学系是真的吃香啊 (╯°Д°)╯︵┻━┻ )
class FullConnectedLayer(Layer):
def __init__(self, input_size, output_size):
self.i_size = input_size
self.o_size = output_size
if self.i_size is not None:
self.__init(self.i_size)
def __init(self, input_size):
self.i_size = input_size
self.w = np.random.normal(
loc=0.0, scale=1.0, size=(self.i_size, self.o_size))
self.b = np.random.normal(loc=0.0, scale=1.0, size=(1, self.o_size))
self.x: np.ndarray = None # input
def __call__(self, x: np.ndarray) -> np.ndarray:
x = x.reshape(1, -1)
# 如果 self.i_size 还没有确定,则根据x.shape来初始化
if self.i_size is None:
self.__init(x.shape[1])
self.x = x
self.z = x.dot(self.w)+self.b
return self.z
def backward(self, dc_dz: np.ndarray) -> np.ndarray:
dc_dx = dc_dz.dot(self.w.T)
self.w += self.x.T.dot(dc_dz)
self.b += dc_dz
return dc_dx
池化层
池化层原理比较简单,但代码实现的时候要处理输入索引与输出索引之间的对应关系,有点烦人。
max-pooling 用 numpy 实现起来比 mean-pooling 麻烦很多,所以我只实现了 mean-pooling
- 有关博客:
https://blog.csdn.net/googler_offer/article/details/81208413
https://blog.csdn.net/m_buddy/article/details/80426531
-
反向传播:
以下反向传播公式通过对矩阵逐元素求导很容易证明。- mean pooling
假设要在某一通道下对一个 nxn 的子矩阵区域进行池化,则:
y = ∑ i n ∑ i n x i j n 2 y = \frac{\sum_i^n\sum_i^nx_{ij}}{n^2} y=n2∑in∑inxij
求导易得:
∂ y ∂ x i j = 1 n 2 \frac{\partial{y}}{\partial{x_{ij}}} = \frac{1}{n^2} ∂xij∂y=n21
所以有反向传播公式:
∂ C ∂ x i j = ∂ C ∂ y s u b m a t r i x ∂ y s u b m a t r i x ∂ x i j = ∂ C ∂ y s u b m a t r i x 1 n 2 \frac{\partial{C}}{\partial{x_{ij}}} = \frac{\partial{C}}{\partial{y_{submatrix}}}\frac{\partial{y_{submatrix}}}{\partial{x_{ij}}} = \frac{\partial{C}}{\partial{y_{submatrix}}}\frac{1}{n^2} ∂xij∂C=∂ysubmatrix∂C∂xij∂ysubmatrix=∂ysubmatrix∂Cn21

- max pooling
假设要在某一通道下对一个 nxn 的子矩阵区域进行池化,则:
y = m a x ( x i j ) y = max({x_{ij}}) y=max(xij)
求导易得:
∂ y ∂ x i j = { 1 , x i j 是 当 前 子 矩 阵 的 最 大 值 0 , x i j 不 是 当 前 子 矩 阵 的 最 大 值 \frac{\partial{y}}{\partial{x_{ij}}} = \begin{cases} 1, &x_{ij} 是当前子矩阵的最大值 \cr 0, &x_{ij} 不是当前子矩阵的最大值 \end{cases}\\ ∂xij∂y={1,0,xij是当前子矩阵的最大值xij不是当前子矩阵的最大值
所以有反向传播公式:
∂ C ∂ x i j = ∂ C ∂ y s u b m a t r i x ∂ y s u b m a t r i x ∂ x i j = { ∂ C ∂ y s u b m a t r i x , x i j 是 当 前 子 矩 阵 的 最 大 值 0 , x i j 不 是 当 前 子 矩 阵 的 最 大 值 \frac{\partial{C}}{\partial{x_{ij}}} = \frac{\partial{C}}{\partial{y_{submatrix}}}\frac{\partial{y_{submatrix}}}{\partial{x_{ij}}} = \begin{cases} \frac{\partial{C}}{\partial{y_{submatrix}}}, &x_{ij} 是当前子矩阵的最大值 \cr 0, &x_{ij} 不是当前子矩阵的最大值 \end{cases}\\ ∂xij∂C=∂ysubmatrix∂C∂xij∂ysubmatrix={∂ysubmatrix∂C,0,xij是当前子矩阵的最大值xij不是当前子矩阵的最大值

- mean pooling
-
代码:
# 池化层
# 池化层的难点在于处理正反向传播时索引的对应关系
# 均值池化层实现起来比最大值池化层更简单(尤其是涉及到多个channel的)
class MeanPoolingLayer(Layer):
def __init__(self, kernel_size: int, stride: int):
self.ks = kernel_size
self.kernel_shape = (kernel_size, kernel_size)
self.channels: int = None
self.stride = stride
self.input_shape: tuple = None # row_cnt,col_cnt,channels
self.target_shape: tuple = None # 目标的shape
def __call__(self, mat: np.ndarray) -> np.ndarray:
self.input_shape = mat.shape
self.channels = mat.shape[2]
row, col = mat.shape[0], mat.shape[1]
(kr, kc), s = self.kernel_shape, self.stride
self.target_shape = ((row-kr)//s+1, (col-kc)//s+1, self.channels)
target = np.zeros(self.target_shape)
for i in range(self.target_shape[0]):
for j in range(self.target_shape[1]):
r, c = i*s, j*s
target[i, j] = np.average(mat[r:r+kr, c:c+kc], axis=(0, 1))
return target
def backward(self, d_out: np.ndarray) -> np.ndarray:
d_input = np.zeros(self.input_shape)
n = self.kernel_shape[0]*self.kernel_shape[1]
d_mat = d_out/n # mean-pooling 求导后恰好是 1/n
(kr, kc), s = self.kernel_shape, self.stride
for i in range(self.target_shape[0]):
for j in range(self.target_shape[1]):
r, c = i*s, j*s
d_input[r:r+kr, c:c+kc] += d_mat[i, j]
return d_input
卷积层
卷积
什么是卷积?
看这篇知乎:https://www.zhihu.com/question/22298352/answer/228543288
-
卷积是一种数学运算,一般用编程里的乘号(星号,asterisk)表示,一维卷积公式(连续)如下:
( f ∗ g ) ( x ) = ∫ − ∞ ∞ f ( τ ) g ( x − τ ) d z (f*g)(x) = \int_{-\infty}^{\infty} f(\tau)g(x-\tau) \, dz (f∗g)(x)=∫−∞∞f(τ)g(x−τ)dz
离散定义如下:
( f ∗ g ) ( n ) = ∑ − ∞ ∞ f ( τ ) g ( n − τ ) (f*g)(n) = \sum_{-\infty}^{\infty} f(\tau)g(n-\tau) (f∗g)(n)=−∞∑∞f(τ)g(n−τ) -
numpy 有现成的卷积 api, 叫 np.convolve,不过似乎只对一维有用(不知道是不是因为我操作错误)。
-
数字图像处理时经常遇到二维离散卷积操作 ,我们叫那个移动扫描的小矩阵为“卷积核”。
不过需要注意的是卷积看似是卷积核与子矩阵的对应位置相乘,再求和,其实不然。别忘了公式里的 g(n-t),这意味着卷积核其实已经被“旋转了180度”(rot180 操作)。
这样处理只是方便计算机的运算,毕竟每次都要旋转180度是多余的,一开始存旋转后的卷积核就行了。所以图像卷积运算就成了常见的逐位相乘再相加。
只有使用 opencv 等库的 api 时,可能偶尔会碰到这个旋转180度的问题。

(下面几张图出处为:https://mlnotebook.github.io/post/CNN1/ )


(下图出处:https://blog.csdn.net/weixin_40519315/article/details/105115657)

深度学习里为什么要卷积运算?
按我的理解,应该有下面几点:
- 减少参数
假如要一个网络层将784维的输入转为196维。
一个全连接层存 784*196+196 个参数,而卷积层只要一个 2x2 以 2 的 步长(stride)对 28x28 矩阵扫一遍就得到了,所以只要 4 个参数。
当然,这样没有可比性。实际上卷积层的参数数量主要是靠通道数(channel)撑起来的。一个 3x3,1输入通道(其实对于多通道卷积,一个卷积核尺寸应该写成 Row x Column x InputChannels,即3x3x1),64输出通道,带偏置的卷积层有 3*3*1*64+64 = 640 个参数,相比一般的全连接层是很少的了。
原因出在卷积层采取的是“局部连接”,也就是说输出张量的某一个元素只与输入张量的一小部分元素有关,对应关系矩阵是一个稀疏矩阵;而全连接层的则是与全部输入元素有关(所以才叫“full connected”),关系矩阵满是1。所以一般情况下,同规模的全连接层参数数量多出卷积层很多。不过如果是全卷积神经网络(全卷积网络 FCN 详解),一个卷积核的尺寸和输入张量尺寸完全一样,这样就和全连接层的参数量相当了。现在FCN经常用来在一些特殊网络中替代全连接层。
- 图像特征的局部性
之所以可以用卷积减少参数,就是因为某些问题具有特征局部性,这样可以确定输入张量到输出张量的关系矩阵某些位置可以事先置0(如果用正常的全连接层,则得经过漫长的参数优化才能确定,而且大量无用的关系占用计算资源)。
图像和音频信息是典型的具有特征局部性的数据,所以用卷积层来 提取特征 是再自然不过的事情了。
+++++++++
有人(过去的我(✪ω✪))可能会问:我怎么知道局部特征和输出间的关系是 (x * kernel)+b 呢?就不能是 exp(-exp(fxxx(x))kernel)+fxx(bx)… 这样的奇葩函数吗?
其实这个问题和 “为什么神经网络能以任意精度拟合任意复杂度的函数?”一样。
https://www.jianshu.com/p/9ed784e7557b
神经网络通过简单地组合众多的参数,经过多轮优化参数的迭代之后,可以变得很强大。那些奇葩函数不经没有起到实际作用,还拖慢了运算。不过有时候还是必要的,比如激活函数的非线性化功能。
卷积层的反向传播
看一篇博客:https://blog.csdn.net/qq_16137569/article/details/81477906
如果一定要张量来表示,卷积运算反向传播的结果是什么样的?
答案:还是卷积
如果要用原先的加减乘逆,想破脑袋也不知道怎么表示,毕竟卷积的局部性摆在那里。
这时候,应该承认 卷积是一种新概念的矩阵运算。
应该尝试用 用卷积表示卷积反向传播结果
(下面各式源于上面提到的博客)
这里只考虑一个通道,卷积步长为1,没有zero-padding
- 反向传播
b 是标量(卷积核共有), ⊕ \oplus ⊕表示将与 b 相加广播到张量每一个元素。
z l + 1 = a l ∗ w l + 1 ⊕ b l + 1 z^{l+1}=a^l*w^{l+1}\oplus b^{l+1} zl+1=al∗wl+1⊕bl+1
[ z 11 z 12 z 21 z 22 ] = [ a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 ] ∗ [ w 11 w 12 w 21 w 22 ] ⊕ b l + 1 \begin{bmatrix} z_{11} & z_{12} \\ z_{21} & z_{22} \end{bmatrix} = \, \begin{bmatrix} a_{11} & a_{12} & a_{13}\\ a_{21} & a_{22} & a_{23}\\ a_{31} & a_{32} & a_{33}\\ \end{bmatrix} * \begin{bmatrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{bmatrix} \oplus b^{l+1} [z11z21z12z22]=⎣⎡a11a21a31a12a22a32a13a23a33⎦⎤∗[w11w21w12w22]⊕bl+1
z 11 = a 11 w 11 + a 12 w 12 + a 21 w 21 + a 22 w 22 + b l + 1 z 12 = a 12 w 11 + a 13 w 12 + a 22 w 21 + a 23 w 22 + b l + 1 z 21 = a 21 w 11 + a 22 w 12 + a 31 w 21 + a 32 w 22 + b l + 1 z 22 = a 22 w 11 + a 23 w 12 + a 32 w 21 + a 33 w 22 + b l + 1 z_{11}=a_{11}w_{11}+a_{12}w_{12}+a_{21}w_{21}+a_{22}w_{22}+b^{l+1} \\ z_{12}=a_{12}w_{11}+a_{13}w_{12}+a_{22}w_{21}+a_{23}w_{22}+b^{l+1} \\ z_{21}=a_{21}w_{11}+a_{22}w_{12}+a_{31}w_{21}+a_{32}w_{22}+b^{l+1} \\ z_{22}=a_{22}w_{11}+a_{23}w_{12}+a_{32}w_{21}+a_{33}w_{22}+b^{l+1} z11=a11w11+a12w12+a21w21+a22w22+bl+1z12=a12w11+a13w12+a22w21+a23w22+bl+1z21=a21w11+a22w12+a31w21+a32w22+bl+1z22=a22w11+a23w12+a32w21+a33w22+bl+1
反向传播要求我们根据 C 对 z[l+1] 的偏导求出 C 对 a[l] 的偏导
▽ a l = ∂ C ∂ a l = ∂ C ∂ z l + 1 ∂ z l + 1 ∂ a l = δ l + 1 ∂ z l + 1 ∂ a l \bigtriangledown a^{l} = \frac{\partial{C}}{\partial{a^l}} = \frac{\partial{C}}{\partial{z^{l+1}}} \frac{\partial{z^{l+1}}}{\partial{a^l}} = \delta^{l+1} \frac{\partial{z^{l+1}}}{\partial{a^l}} ▽al=∂al∂C=∂zl+1∂C∂al∂zl+1=δl+1∂al∂zl+1
这 ∂ z l + 1 ∂ a l \frac{\partial{z^{l+1}}}{\partial{a^l}} ∂al∂zl+1与 w l + 1 w^{l+1} wl+1有关,只知道一点点普通矩阵运算的求导法则,这是没法算的。但是我们可以傻一点,对每个元素分别计算一下。
假设 δ l + 1 \delta^{l+1} δl+1是这样的:
δ l + 1 = [ δ 11 δ 12 δ 21 δ 22 ] , δ i j 与 z i j 相 对 应 \delta^{l+1} = \begin{bmatrix} \delta_{11} & \delta_{12} \\ \delta_{21} & \delta_{22} \end{bmatrix} , \delta_{ij} 与 z_{ij} 相对应 δl+1=[δ11δ21δ12δ22],δij与zij相对应
那么,求导易得:
{ ▽ a 11 = δ 11 w 11 ▽ a 12 = δ 11 w 12 + δ 12 w 11 ▽ a 13 = δ 12 w 12 ▽ a 21 = δ 11 w 21 + δ 21 w 11 ▽ a 22 = δ 11 w 22 + δ 12 w 21 + δ 21 w 12 + δ 22 w 11 ▽ a 23 = δ 12 w 22 + δ 22 w 12 ▽ a 31 = δ 21 w 21 ▽ a 32 = δ 21 w 22 + δ 22 w 21 ▽ a 33 = δ 22 w 22 \begin{cases} \bigtriangledown a_{11} = \delta_{11} w_{11} \\ \bigtriangledown a_{12} = \delta_{11} w_{12}+\delta_{12} w_{11} \\ \bigtriangledown a_{13} = \delta_{12} w_{12} \\ \bigtriangledown a_{21} = \delta_{11} w_{21}+\delta_{21} w_{11} \\ \bigtriangledown a_{22} = \delta_{11} w_{22} +\delta_{12} w_{21}+\delta_{21} w_{12}+\delta_{22} w_{11}\\ \bigtriangledown a_{23} = \delta_{12} w_{22} +\delta_{22} w_{12}\\ \bigtriangledown a_{31} = \delta_{21} w_{21} \\ \bigtriangledown a_{32} = \delta_{21} w_{22} +\delta_{22} w_{21}\\ \bigtriangledown a_{33} = \delta_{22} w_{22} \\ \end{cases}\\ ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧▽a11=δ11w11▽a12=δ11w12+δ12w11▽a13=δ12w12▽a21=δ11w21+δ21w11▽a22=δ11w22+δ12w21+δ21w12+δ22w11▽a23=δ12w22+δ22w12▽a31=δ21w21▽a32=δ21w22+δ22w21▽a33=δ22w22
这恰好是:
[ ▽ a 11 ▽ a 12 ▽ a 13 ▽ a 21 ▽ a 22 ▽ a 23 ▽ a 31 ▽ a 32 ▽ a 33 ] = [ 0 0 0 0 0 δ 11 δ 12 0 0 δ 21 δ 22 0 0 0 0 0 ] ∗ [ w 22 w 21 w 12 w 11 ] \begin{bmatrix} \bigtriangledown a_{11} & \bigtriangledown a_{12} & \bigtriangledown a_{13}\\ \bigtriangledown a_{21} & \bigtriangledown a_{22} & \bigtriangledown a_{23}\\ \bigtriangledown a_{31} & \bigtriangledown a_{32} & \bigtriangledown a_{33}\\ \end{bmatrix}= \, \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & \delta_{11} & \delta_{12} & 0 \\ 0 & \delta_{21} & \delta_{22} & 0\\ 0 & 0 & 0 & 0 \end{bmatrix} * \begin{bmatrix} w_{22} & w_{21} \\ w_{12} & w_{11} \end{bmatrix} ⎣⎡▽a11▽a21▽a31▽a12▽a22▽a32▽a13▽a23▽a33⎦⎤=⎣⎢⎢⎡00000δ11δ2100δ12δ2200000⎦⎥⎥⎤∗[w22w12w21w11]
如果把 δ l + 1 \delta^{l+1} δl+1 补充 0 后的矩阵称为 δ e x l + 1 \delta_{ex}^{l+1} δexl+1,矩阵旋转180度的操作为 rot180(matrix),则上面式子可表示为下式(卷积stride为1):
▽ a l = δ e x l + 1 ∗ r o t 180 ( w l + 1 ) \bigtriangledown a^{l} = \delta_{ex}^{l+1} * rot180(w^{l+1}) ▽al=δexl+1∗rot180(wl+1)
(我在这篇博客里找到了两张比较好的图:https://blog.csdn.net/zy3381/article/details/44409535)
正向:

反向:

- 参数更新
- 卷积核:w:
和 C 对 a 求导会得到卷积(以 rot180(w) 为卷积核)一样,C 对 w 求导也会得到一个包含卷积运算的式子。且由于卷积元素的二者拥有 同等地位 (回想一下高中物理和高数(多元函数积分),是不是经常碰到 | ・ω・ )),C 对 w 求导的结果一定是以 rot180(a) 为卷积核(从通道数对应的角度看,说 δ e x l + 1 \delta_{ex}^{l+1} δexl+1为卷积核应该更准确,详情可以看下面关于多通道卷积的部分),且 stride 为 1,卷积的对象还是 δ e x l + 1 \delta_{ex}^{l+1} δexl+1。
(不过要说是“地位相等”推出来的有点勉强,因为 a 对 w 的卷积其实是 “full” 卷积,w 对 a 是 “valid” 卷积,除非把 a 和 w 都 zero-padding 到无限广,这时从离散卷积公式上看才是地位同等的。另外,经过无限zero-padding后,卷积运算是可交换的(卷积在数学上是可交换的,但在实现时因为张量尺寸有限,变得不可交换)。)
▽ w l + 1 = δ e x l + 1 ∗ r o t 180 ( a l ) \bigtriangledown w^{l+1} = \delta_{ex}^{l+1}* rot180(a^l) ▽wl+1=δexl+1∗rot180(al) - 偏置:b:
C 对 b 的求导就简单了,按下面式子计算后就能发现,答案就是把该通道下的所有 δ i j \delta_{ij} δij 加起来。
▽ b l + 1 = ∂ C ∂ z l + 1 ∂ z l + 1 ∂ b l + 1 = ∂ C ∂ z 11 ∂ z 11 ∂ b l + 1 + ∂ C ∂ z 12 ∂ z 12 ∂ b l + 1 + ∂ C ∂ z 21 ∂ z 21 ∂ b l + 1 + ∂ C ∂ z 22 ∂ z 22 ∂ b l + 1 = ∂ C ∂ z 11 + ∂ C ∂ z 12 + ∂ C ∂ z 21 + ∂ C ∂ z 22 = δ 11 + δ 12 + δ 21 + δ 22 = ∑ i ∑ j δ i j \begin{aligned} \bigtriangledown b^{l+1} &= \frac{\partial{C}}{\partial{z^{l+1}}} \frac{\partial{z^{l+1}}}{\partial{b^{l+1}}} \\ &= \frac{\partial{C}}{\partial{z_{11}}} \frac{\partial{z_{11}}}{\partial{b^{l+1}}} + \frac{\partial{C}}{\partial{z_{12}}} \frac{\partial{z_{12}}}{\partial{b^{l+1}}} + \frac{\partial{C}}{\partial{z_{21}}} \frac{\partial{z_{21}}}{\partial{b^{l+1}}} + \frac{\partial{C}}{\partial{z_{22}}} \frac{\partial{z_{22}}}{\partial{b^{l+1}}} \\ &= \frac{\partial{C}}{\partial{z_{11}}} + \frac{\partial{C}}{\partial{z_{12}}} + \frac{\partial{C}}{\partial{z_{21}}} + \frac{\partial{C}}{\partial{z_{22}}} \\ &= \delta_{11} + \delta_{12} + \delta_{21} + \delta_{22} \\ &= \sum_{i}\sum_{j}\delta_{ij} \end{aligned} ▽bl+1=∂zl+1∂C∂bl+1∂zl+1=∂z11∂C∂bl+1∂z11+∂z12∂C∂bl+1∂z12+∂z21∂C∂bl+1∂z21+∂z22∂C∂bl+1∂z22=∂z11∂C+∂z12∂C+∂z21∂C+∂z22∂C=δ11+δ12+δ21+δ22=i∑j∑δij
多通道情况下卷积层的正向与反向传播
到这里为止,要写出卷积层其实还不够。
我们常见到的 CNN 是这样的:

还有这样的:
所以为了实现 CNN,多通道条件是一定得考虑的。
数学好的同学看这篇,里面有多通道卷积的反向传播公式(不过我不喜欢看这种展开式 (╯°Д°)╯︵┻━┻):https://blog.csdn.net/imgosty/article/details/82286916
关于多通道卷积的规则可以看这篇博客:卷积神经网络CNN(卷积池化、感受野、共享权重和偏置、特征图)
多通道卷积规则为:
- 输入有多个通道(设有input_channel个输入通道),每个通道是一个矩阵。因此可以将输入看成 (row, col, input_channel) 大小的张量 A A A。
- 每个卷积核不再是一个矩阵了,而是一个(k_row, k_col, input_channel) 大小的张量。input_channel 就是输入通道数。
- 卷积核有多个通道(或者说有多个等大的单通道卷积核),每个通道的卷积核单独作用于输入张量。整体可以看成(k_row, k_col, input_channel, output_channel) 大小的张量 W W W。
- 偏置的通道数和卷积核的通道数一致,且各通道相对应。即每个卷积核对应一个偏置值。
- 取出第 k k k个(本来想用 l l l的,但是它看起来像1,不容易分辨)输出通道的卷积核 W [ ⋅ , ⋅ , ⋅ , k ] W[\cdot,\cdot,\cdot,k] W[⋅,⋅,⋅,k],用 W [ ⋅ , ⋅ , ⋅ , k ] W[\cdot,\cdot,\cdot,k] W[⋅,⋅,⋅,k]对输入张量 A A A进行卷积。即用 W [ ⋅ , ⋅ , m , k ] W[\cdot,\cdot,m,k] W[⋅,⋅,m,k]对 A [ ⋅ , ⋅ , m ] A[\cdot,\cdot,m] A[⋅,⋅,m]进行卷积(即上文提到的单通道卷积),然后对卷积结果按input_channel维进行加和,得到结果 Z [ ⋅ , ⋅ , k ] Z[\cdot,\cdot,k] Z[⋅,⋅,k]。完成所有output_channel的卷积操作后,将结果合成为一个张量,即 Z Z Z,它的大小为(z_row, z_col, output_channel),z_row和z_col的计算之后再提。
对于每个卷积核,卷积操作如下,其中 c 表示输入通道数。
v 1 = a 111 w 111 k + a 121 w 121 k + a 211 w 211 k + a 221 w 221 k v 2 = a 112 w 112 k + a 122 w 122 k + a 212 w 212 k + a 222 w 222 k v 3 = a 113 w 113 k + a 123 w 123 k + a 213 w 213 k + a 223 w 223 k z i j k = ∑ c v c + b k l + 1 v_{1}=a_{111}w_{111k}+a_{121}w_{121k}+a_{211}w_{211k}+a_{221}w_{221k} \\ v_{2}=a_{112}w_{112k}+a_{122}w_{122k}+a_{212}w_{212k}+a_{222}w_{222k} \\ v_{3}=a_{113}w_{113k}+a_{123}w_{123k}+a_{213}w_{213k}+a_{223}w_{223k} \\ \\ z_{ijk} = \sum_c{v_c} +b_k^{l+1} v1=a111w111k+a121w121k+a211w211k+a221w221kv2=a112w112k+a122w122k+a212w212k+a222w222kv3=a113w113k+a123w123k+a213w213k+a223w223kzijk=c∑vc+bkl+1
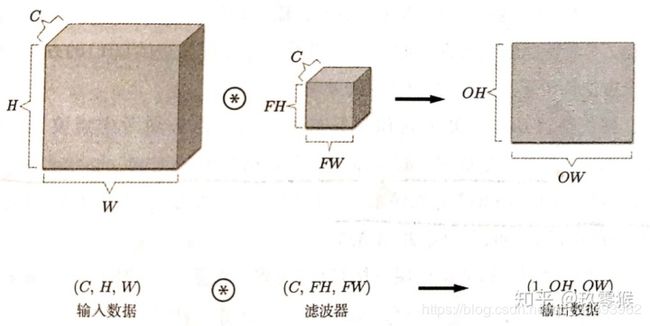
借用一下别人的图描述一下单核卷积(https://blog.csdn.net/weixin_40519315/article/details/105115657):
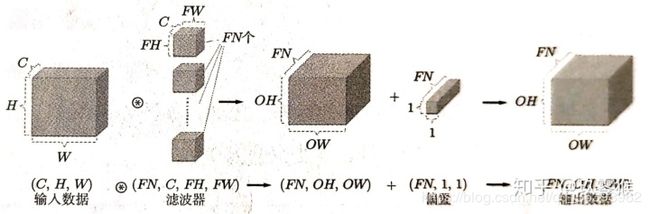
多核卷积示意图如下:
通过计算(式子太多,略)发现,反向传播和参数更新的公式稍微变了一点。下面 c 表示输入通道下标,k 表示输出通道下标,i 和 j 分别表示行和列的下标, w c , k w_{c,k} wc,k 表示在第 c 个输入通道且在第 k 个输出通道的单层卷积核:
{ ( ▽ a l ) c = ∑ k ( ( δ e x l + 1 ) k ∗ r o t 180 ( w c , k l + 1 ) ) , ( 1 ) ( ▽ w l + 1 ) c , k = ( δ e x l + 1 ) k ∗ r o t 180 ( a c l ) , ( 2 ) ( ▽ b l + 1 ) k = ∑ i ∑ j δ i j k , ( 3 ) \begin{cases} (\bigtriangledown a^{l})_c = \sum_{k}( (\delta_{ex}^{l+1} )_k * rot180(w^{l+1}_{c,k})) ,&(1) \\ \, \\ (\bigtriangledown w^{l+1})_{c,k}= (\delta_{ex}^{l+1})_k * rot180(a^l_c) ,&(2) \\ \, \\ (\bigtriangledown b^{l+1} )_k = \sum_{i}\sum_{j}\delta_{ijk} ,&(3) \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧(▽al)c=∑k((δexl+1)k∗rot180(wc,kl+1)),(▽wl+1)c,k=(δexl+1)k∗rot180(acl),(▽bl+1)k=∑i∑jδijk,(1)(2)(3)
其实按照每一个值的推导链是可以猜出这些式子的(即根据正向推导结果张量中的每一个值对其余张量里各值的依赖关系来猜),具体我就不多说了(其实是绕到我不知道怎么讲清楚| ・ω・ )。
看到式子这么复杂,心里都感觉有些慌了。在编程时如何表示这些运算呢?
(用 C/C++ 或者 cython 的就当我没说吧,反正这些语言的运行效率够高了,沉下心来把逻辑理清楚,再加一些耐心不难写出来;python 就只好借助 numpy api 了)
这时候就该想到 numpy 的 einsum (Einstein summation convention 爱因斯坦求和约定) 了。(喜欢看数学公式的,下面内容可以跳过)
我先作一些说明:
- 下面 einsum 字符串参数只用于表明计算规则,其中 i, j, k, l 和字符串外的索引不对应
- 3维张量每个维度的含义为 rows(行数), columns(列数), channels(通道数)
- 4维张量每个维度的含义为 rows(行数), columns(列数), input_channels(输入通道数), output_channels(输出通道数)
- 定义一个 c o n v ( S t r i n g e i n s u m , A , K ) conv(String_{einsum}, A, K) conv(Stringeinsum,A,K) 函数,用于声明具体的卷积操作:
- S t r i n g e i n s u m String_{einsum} Stringeinsum 表示用于爱因斯坦求和的字符串, A A A是输入张量, K K K是卷积核。 K K K在扫过 A A A时,每移动一个stride都要对 K K K所覆盖的 A A A的子矩阵使用 S t r i n g e i n s u m String_{einsum} Stringeinsum 进行计算(全卷积),得到一个局部结果张量或者一个数值(比如下面权重梯度矩阵的每个元素就是一个二维张量)。
- 该函数的输出是一个矩阵,它的每个元素是数值,或者等大的张量。这些元素表示了卷积过程中每次使用 S t r i n g e i n s u m String_{einsum} Stringeinsum 进行计算的结果。因为每个元素都是等大的张量,所以这个矩阵可以看成一个数值张量。
那么,公式如下:
- 正向推导中的卷积(取某一个被卷积的局部区域讨论;局部区域输入和输出张量标为 sub)
z l + 1 = c o n v ( " i j k , i j k l → l " , a l , w l + 1 ) z^{l+1}= conv(" ijk,ijkl \rightarrow l",a^{l},w^{l+1}) zl+1=conv("ijk,ijkl→l",al,wl+1) - 反向传播
▽ a l = c o n v ( " i j l , i j k l → k " , δ e x l + 1 , r o t 180 ( w l + 1 ) ) \bigtriangledown a^{l}= conv("ijl,ijkl \rightarrow k",\delta_{ex}^{l+1},rot180(w^{l+1})) ▽al=conv("ijl,ijkl→k",δexl+1,rot180(wl+1)) - 参数更新
▽ w l + 1 = c o n v ( " i j l , i j k → k l " , δ e x l + 1 , r o t 180 ( a l ) ) \bigtriangledown w^{l+1} = conv("ijl,ijk \rightarrow kl",\delta_{ex}^{l+1},rot180(a^{l})) ▽wl+1=conv("ijl,ijk→kl",δexl+1,rot180(al))
▽ b l + 1 = e i n s u m ( " i j k → k " , δ l + 1 ) \bigtriangledown b^{l+1} = einsum("ijk \rightarrow k",\delta^{l+1}) ▽bl+1=einsum("ijk→k",δl+1)
上面几个式子除了 b 的更新公式以外,都是卷积操作。我的实现是在局部进行全卷积,将这个过程嵌套进两个 for 循环让卷积核扫过整个二维平面,得到最终输出。
(我不知道 numpy 有没有代替 for 循环的 api,这样可以大幅提速,如果各位有知道的,请指出 | ・ω・ )
到这里,实现最基础 cnn 的基础知识就讲完了,以后看 AlexNet,ResNet,EfficientNet,GAN 之类的是不是就更有底了 | ・ω・ )
stride 不为1的情况
用过 tensorflow 就知道,如果构造卷积层,除了尺寸等基本参数以外,还需要传入 stride(卷积核移动的步长) 参数,另外还有 padding(输入张量的边缘填充,填充0;卷积两种模式 “full”,“valid”;“full” 表示需要 padding),dilation(卷积核的膨胀系数,看这篇博客)等参数的设置选项,详情可见 tensorflow 文档。
这里只讨论 stride 的影响。(以下用 ∗ m *_{m} ∗m 表示 stride=m 的卷积,不写 m 则是 stride=1 的普通卷积)
z l + 1 = a l ∗ w l + 1 ⊕ b l + 1 z^{l+1}=a^l*w^{l+1}\oplus b^{l+1} zl+1=al∗wl+1⊕bl+1
[ z 11 z 12 z 13 z 21 z 22 z 23 z 31 z 32 z 33 ] = [ a 11 a 12 a 13 a 14 a 15 a 16 a 21 a 22 a 23 a 24 a 25 a 26 a 31 a 32 a 33 a 34 a 35 a 36 a 41 a 42 a 43 a 44 a 45 a 46 a 51 a 52 a 53 a 54 a 55 a 56 a 61 a 62 a 63 a 64 a 65 a 66 ] ∗ 2 [ w 11 w 12 w 21 w 22 ] ⊕ b l + 1 \begin{bmatrix} z_{11} & z_{12} & z_{13} \\ z_{21} & z_{22} & z_{23} \\ z_{31} & z_{32} & z_{33} \\ \end{bmatrix} = \, \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} & a_{15} & a_{16}\\ a_{21} & a_{22} & a_{23} & a_{24} & a_{25} & a_{26}\\ a_{31} & a_{32} & a_{33} & a_{34} & a_{35} & a_{36}\\ a_{41} & a_{42} & a_{43} & a_{44} & a_{45} & a_{46}\\ a_{51} & a_{52} & a_{53} & a_{54} & a_{55} & a_{56}\\ a_{61} & a_{62} & a_{63} & a_{64} & a_{65} & a_{66}\\ \end{bmatrix} *_{2} \begin{bmatrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{bmatrix} \oplus b^{l+1} ⎣⎡z11z21z31z12z22z32z13z23z33⎦⎤=⎣⎢⎢⎢⎢⎢⎢⎡a11a21a31a41a51a61a12a22a32a42a52a62a13a23a33a43a53a63a14a24a34a44a54a64a15a25a35a45a55a65a16a26a36a46a56a66⎦⎥⎥⎥⎥⎥⎥⎤∗2[w11w21w12w22]⊕bl+1
z 11 = a 11 w 11 + a 12 w 12 + a 21 w 21 + a 22 w 22 + b l + 1 z 12 = a 13 w 11 + a 14 w 12 + a 23 w 21 + a 24 w 22 + b l + 1 ⋮ z 33 = a 55 w 11 + a 56 w 12 + a 65 w 21 + a 66 w 22 + b l + 1 z_{11} = a_{11}w_{11}+a_{12}w_{12}+a_{21}w_{21}+a_{22}w_{22}+b^{l+1} \\ z_{12} = a_{13}w_{11}+a_{14}w_{12}+a_{23}w_{21}+a_{24}w_{22}+b^{l+1} \\ \vdots \\ z_{33} = a_{55}w_{11}+a_{56}w_{12}+a_{65}w_{21}+a_{66}w_{22}+b^{l+1} \\ z11=a11w11+a12w12+a21w21+a22w22+bl+1z12=a13w11+a14w12+a23w21+a24w22+bl+1⋮z33=a55w11+a56w12+a65w21+a66w22+bl+1
接下来的思路和之前讲的一样,式子太多就省略了,直接说结论:
▽ a l = δ e x l + 1 ∗ 1 r o t 180 ( w l + 1 ) = [ 0 0 0 0 0 0 0 0 δ 11 0 δ 12 0 δ 13 0 0 0 0 0 0 0 0 0 δ 21 0 δ 22 0 δ 23 0 0 0 0 0 0 0 0 0 δ 31 0 δ 32 0 δ 33 0 0 0 0 0 0 0 0 ] ∗ 1 [ w 22 w 21 w 12 w 11 ] \bigtriangledown a^l = \delta_{ex}^{l+1} *_1 rot180(w^{l+1}) = \, \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & \delta_{11} & 0 & \delta_{12} & 0 & \delta_{13} & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & \delta_{21} & 0 & \delta_{22} & 0 & \delta_{23} & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & \delta_{31} & 0 & \delta_{32} & 0 & \delta_{33} & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{bmatrix} *_{1} \begin{bmatrix} w_{22} & w_{21} \\ w_{12} & w_{11} \end{bmatrix} ▽al=δexl+1∗1rot180(wl+1)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡00000000δ110δ210δ31000000000δ120δ220δ32000000000δ130δ230δ3300000000⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤∗1[w22w12w21w11]
这次的 δ e x l + 1 \delta_{ex}^{l+1} δexl+1 除了 padding(边缘填充) 外,还多了 dilation(扩大)
- padding 宽度(以横向为例)= w l + 1 . c o l u m n s − 1 w^{l+1}.columns- 1 wl+1.columns−1 (其实用"full"卷积来思考,根本没有padding)
- 膨胀间隙宽度(以横向为例)= stride(横向) - 1
- rot180(w) 卷积步长 = 1
- δ e x l + 1 \delta_{ex}^{l+1} δexl+1 宽度为:
δ e x l + 1 . c o l = 2 × ( w l + 1 . c o l − 1 ) + ( δ l + 1 . c o l − 1 ) × ( s t r i d e − 1 ) + δ l + 1 . c o l = 2 × w l + 1 . c o l + ( δ l + 1 . c o l − 1 ) × s t r i d e − 1 \begin{aligned} \delta_{ex}^{l+1}.col &= 2\times(w^{l+1}.col- 1)+(\delta^{l+1}.col-1) \times (stride -1) + \delta^{l+1}.col \\ &= 2\times w^{l+1}.col + (\delta^{l+1}.col-1) \times stride -1 \end{aligned} δexl+1.col=2×(wl+1.col−1)+(δl+1.col−1)×(stride−1)+δl+1.col=2×wl+1.col+(δl+1.col−1)×stride−1
数学公式是这样,怎么用代码实现呢?
我是只想到用先构造一个全 0 张量,然后向里面填 δ \delta δ (不知道用 numpy 有没有更巧妙的办法)。这样做空间复杂度和时间复杂度都很高(用过 python 的都知道, for 循环非常慢)。
但如果是用 C/C++,语言本身就很快,完全可以采用控制索引访问来代替傻傻地填 0 ,而不用过于担心索引计算的时间消耗。
代码
做了这么多铺垫(接近一半的篇幅),终于到了贴代码的时候了。
可以说卷积层是这里最难最麻烦的了。
# 卷积层
class ConvolutionLayer(Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride):
self.in_channels = in_channels
self.out_channels = out_channels
self.ks = kernel_size
self.kernel_shape = (kernel_size, kernel_size)
self.stride = stride
self.x: Optional[np.ndarray] = None # input
# 卷积核: row,col,channel 顺序
# 共有 out_channels 个 (row,col,in_channel) 的 kernels
self.kernel = np.random.normal(loc=0.0, scale=1.0, size=(
kernel_size, kernel_size, in_channels, out_channels,))
# 每个卷积核共用一个 bias, 总共有 out_channels 个 biases
self.bias = np.random.normal(loc=0.0, scale=1.0, size=(out_channels,))
def check_x_mat_shape(self, x_mat):
'''
要求卷积核在卷积过程中可以把矩阵铺满(stride空隙不算)
右侧(下侧)不能有多余的列(行)
如 28x28 不能用(5x5,stride=2)的卷积核,因为它只能覆盖(27x27)
'''
row, col = x_mat.shape[0], x_mat.shape[1]
k, s = self.ks, self.stride
assert (row - k) // s * s + k == row
assert (col - k) // s * s + k == col
def __call__(self, x_mat: np.ndarray) -> np.ndarray:
self.check_x_mat_shape(x_mat)
self.x = x_mat
return self.__conv(
stride=self.stride,
mat=x_mat,
kernel=self.kernel,
bias=None,
einsum_formula="ijk,ijkl->l",
out_ele_shape=[self.out_channels]
)
def backward(self, dc_dz: np.ndarray) -> np.ndarray:
# 反向卷积的目标是dc_dz补0之后的矩阵(张量)
# (padding + dilation)
# 补0规则为:边缘padding kernel_size-1 层0;间隔处补 stride-1 层0
# 只看横向,如果dc_dz有c列,那该矩阵有 2kernel_size+(m-1)stride-1 列
# 反向卷积的stride固定为1
(kr, kc, in_ch, out_ch), s = self.kernel.shape, self.stride
dc_dz_with_zeros_shape = (
2 * kr + (dc_dz.shape[0] - 1) * s - 1,
2 * kc + (dc_dz.shape[1] - 1) * s - 1,
dc_dz.shape[2]
)
D = np.zeros(dc_dz_with_zeros_shape) # 为了简化,用D表示补充0之后的张量
for i in range(dc_dz.shape[0]):
for j in range(dc_dz.shape[1]):
D[kr + i * s - 1, kc + j * s - 1] = dc_dz[i, j]
# 求 dc_da(a指的是该层的输入self.x,因为习惯上称呼上一层的激活值为a[l-1])
# 注意stride(步长)是1
# kernel[i,j,k,l]在正向推导时i表示row,j表示col,k表示in_ch,l表示out_ch
# 反向推导时i表示row,j表示col,l表示in_ch,k表示out_ch,其余计算步骤和正向推导一致
dc_da = self.__conv(
stride=1,
mat=D,
kernel=self.kernel[::-1, ::-1], # 注意不能漏了反向传播中卷积核的180度旋转 rot180(w)
bias=None,
einsum_formula="ijl,ijkl->k",
out_ele_shape=[in_ch])
# 求 dc_dw(即dc_d kernel)
# 也是卷积,只不过是用 rot180(a_input) 对 D 卷积
dc_dw = self.__conv(
stride=1,
mat=D,
kernel=self.x[::-1, ::-1],
bias=None,
einsum_formula="ijl,ijk->kl",
out_ele_shape=[in_ch, out_ch])
# 求 dc_db
dc_db = np.einsum("ijk->k", dc_dz)
# 更新w(kernel)和b(bias),并返回 dc_da
self.kernel += dc_dw
self.bias += dc_db
return dc_da
def __conv(self,
stride: int,
mat: np.ndarray, # shape=(row, col, in_ch)
kernel: np.ndarray, # shape=(k_row, k_col, in_ch, out_ch)
bias: np.ndarray = None, # shape=(out_ch,)
einsum_formula: str = "ijk,ijkl->l",
out_ele_shape: Iterable[int] = None) -> np.ndarray:
'''
einsum_formula:
卷积核kernel对mat的某个子矩阵进行全卷积要使用这个爱因斯坦求和约定式子进行计算。
卷积结束后得到一个 shape=(I,J) 的结果矩阵。
矩阵的每一个元素不一定是值,有可能是一个张量,这需要要看 einsum_formula 的设置。
结果矩阵本质上可以写成 shape=(I,J,...) 的张量
out_ele_shape:
注意 out_ele_shape 要与 einsum_formula 相对应
out_ele_shape 表示作卷积后,结果矩阵中每个元素的shape
out_ele_shape 会被用来构造结果张量。
-------------------------------------------------------------
举个例子:
"ijk,ijl->kl",用这个式子卷积后结果矩阵的每个元素都是 shape=(K,L)
的矩阵,那么结果其实是一个 (I,J,K,L) 的4维张量,此时应该设置
out_ele_shape=[K,L]
-------------------------------------------------------------
如果是单通道卷积,则每个元素就是一个数值,应该设置 out_ele_shape=[]
默认设置是针对正向传播的,此时out_ele_shape可以设置为None(只是为了方便)
'''
# 卷积运算 sub_np_tensor * kernel_np_tensor + bias
if bias is None:
def f(m):
return np.einsum(
einsum_formula, m, kernel)
else:
def f(m):
return np.einsum(einsum_formula, m, kernel) + bias
row, col = mat.shape[0], mat.shape[1]
s = stride # 简写
(kr, kc, *omit), s = kernel.shape, stride
# out_ele_shape 默认为 (kernel.shape[2],)
# 针对正向推导
if out_ele_shape is None:
assert len(kernel.shape) == 3
out_ch = kernel.shape[-1]
out_ele_shape = (out_ch,)
target_shape = ((row - kr) // s + 1, (col - kc) // s + 1, *out_ele_shape)
target = np.zeros(target_shape)
for i in range(target_shape[0]):
for j in range(target_shape[1]):
r, c = i * s, j * s
target[i, j] = f(mat[r:r + kr, c:c + kc])
return target
神经网络
# (nn.py)
# 神经网络
class NN:
def __init__(self,input_shape=(1,-1),output_shape=(1,-1)):
self.layers = list()
self.input_shape = input_shape
self.output_shape = output_shape
def forward(self,x:np.ndarray)->np.ndarray:
a = x.reshape(self.input_shape)
for layer in self.layers:
a = layer(a)
return a
def backward(self,dc_da_last:np.ndarray)->np.ndarray:
d = dc_da_last.reshape(self.output_shape)
for layer in self.layers[::-1]:
d = layer.backward(d)
return d
def train(self,input_vec,label,loss_func:LossFunc,lr):
y = self.forward(input_vec)
loss = loss_func.derivate(label,y)
self.backward(loss * -lr)
def set_layers(self,layers):
self.layers = layers
def append(self,layer):
self.layers.append(layer)
测试
我没有做 归一化 normalization 或者 标准化 standardization,只是测试我正反向传播有没有写对。
就不多说了
def test_conv():
'''
测试卷积层
可以很明显的发现,经过training后,输出和正确答案变得非常接近
'''
a = np.array(
[
[[1, 1, 3], [2, 2, 3], [3, 3, 5], [4, 4, 5]],
[[0, 0, 3], [1, 1, 3], [0, 0, 5], [1, 1, 5]],
[[5, 5, 3], [0, 0, 3], [9, 9, 5], [1, 1, 5]],
[[6, 6, 3], [3, 3, 3], [7, 7, 5], [1, 1, 5]]
]
)
label = np.array([[1, 0, 1, 1]])
from funcs import sigmoid
from lossfuncs import sse
from nn import NN
# conv = ConvolutionLayer(2,1,2,1)
my_nn = NN((4, 4, 3), (1, 4))
my_nn.set_layers([
ConvolutionLayer(3, 6, 1, 1),
FuncLayer(sigmoid),
MeanPoolingLayer(2,2),
FuncLayer(relu),
ConvolutionLayer(6, 5, 2, 1),
FuncLayer(sigmoid),
ReshapeLayer(None,(1,-1)),
FullConnectedLayer(None, 4),
FuncLayer(sigmoid),
])
y1 = my_nn.forward(a)
for i in range(20000):
my_nn.train(a, label, sse, 0.1)
y2 = my_nn.forward(a)
print("训练前:",y1) # 训练前: [[0.77564924 0.91641117 0.37085342 0.2824503 ]]
print("训练后:",y2) # 训练后: [[0.99345597 0.00654098 0.99345575 0.9934803 ]]
print("答案:",label) # 答案: [[1 0 1 1]]