JVM 类加载子系统、运行时数据区、 执行引擎
目录
概要
一、类加载子系统(Class Loader)
1.类加载子系统执行流程
2.全盘委派机制
3.双亲委派:
二、运行时数据区(Runtime Data Area)
1.运行时数据区结构
2.线程处理数据时,栈的处理流程示意图
3.JVM 对象的创建过程
4.JVM对象内存结构
三、垃圾收集器及内存分配策略
1.可达性分析算法
2.回收方法区
2.1废弃的常量
2.2 不再使用的类型
3.垃圾收集算法
3.1 分代收集理论
3.2 标记-清楚算法(Mark-Sweep)
3.3 标记-复制算法
3.4 标记整理算法(Mark Compact)
四、经典垃圾收集器
1.Serial收集器(新生代:标记-复制)
2.ParNew收集器(新生代:标记-复制)
3.Parallel Scavenge收集器(新生代:标记-复制)
4.Serial Old/PS MarkSweep收集器(老年代:标记-整理)
5.Parallel Old收集器(老年代:标记-整理)
6.G1收集器(新生代老年代通用)
概要
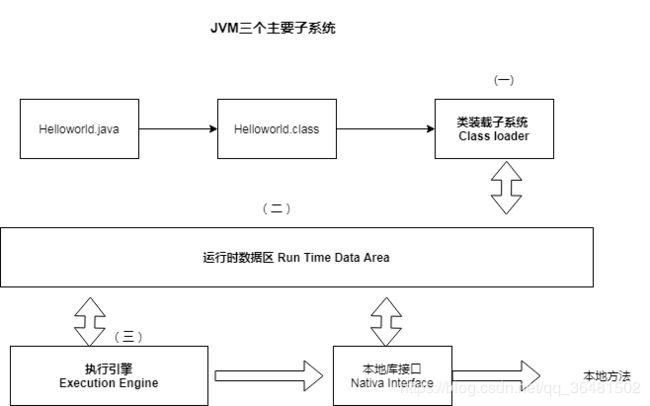
JVM由三个主要子系统组成
- 类加载子系统(Class Loader)
- 类加载子系统(Runtime Data Area)
- 执行引擎(Execution Engine)
一、类加载子系统(Class Loader)
1.类加载子系统执行流程

2.全盘委派机制
当一个ClassLoader加载一个类的时候,除非显示的使用另外一个ClassLoader,该类所依赖和引用的类也由这个ClassLoader载入
3.双亲委派:
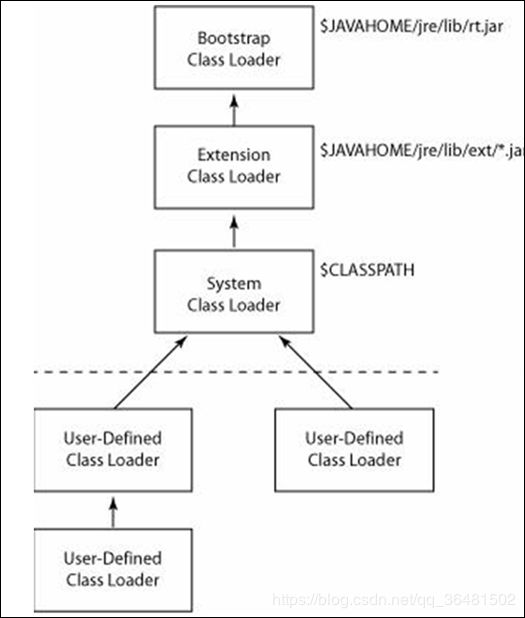
为什么要使用双亲委派:
1.防止重复加载同一个类,并且类信息不同
2.沙箱机制,让虚拟机更安全
从反向思考这个问题,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,多个类加载器都去加载这个类到内存中,系统中将会出现多个不同的Object类,那么类之间的比较结果及类的唯一性将无法保证,而且如果不使用这种双亲委派模型将会给虚拟机的安全带来隐患。所以,要让类对象进行比较有意义,前提是他们要被同一个类加载器加载。
二、运行时数据区(Runtime Data Area)
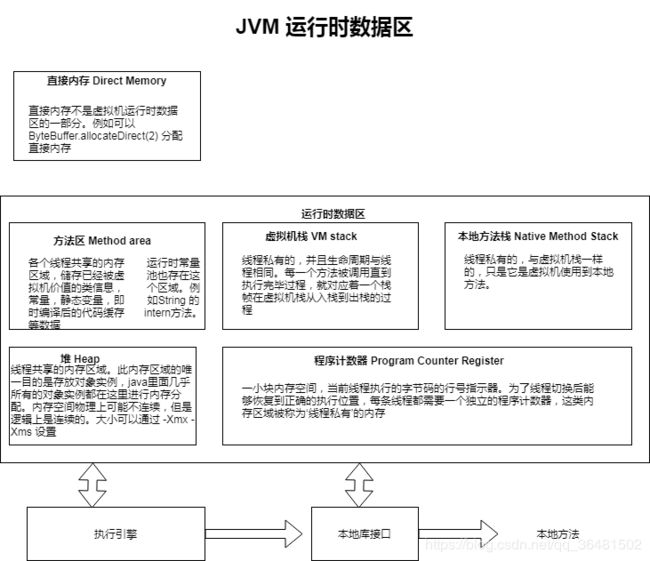
1.运行时数据区结构
2.线程处理数据时,栈的处理流程示意图
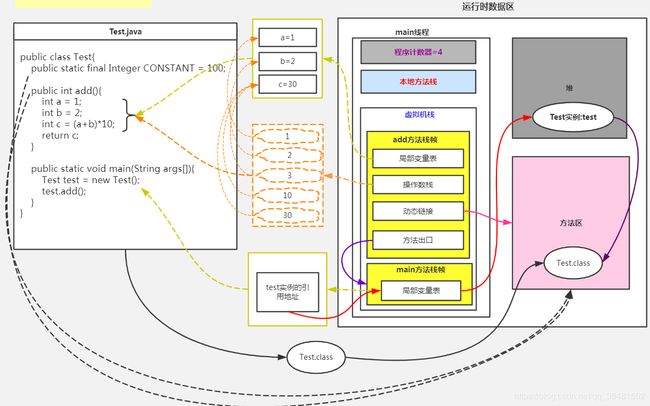
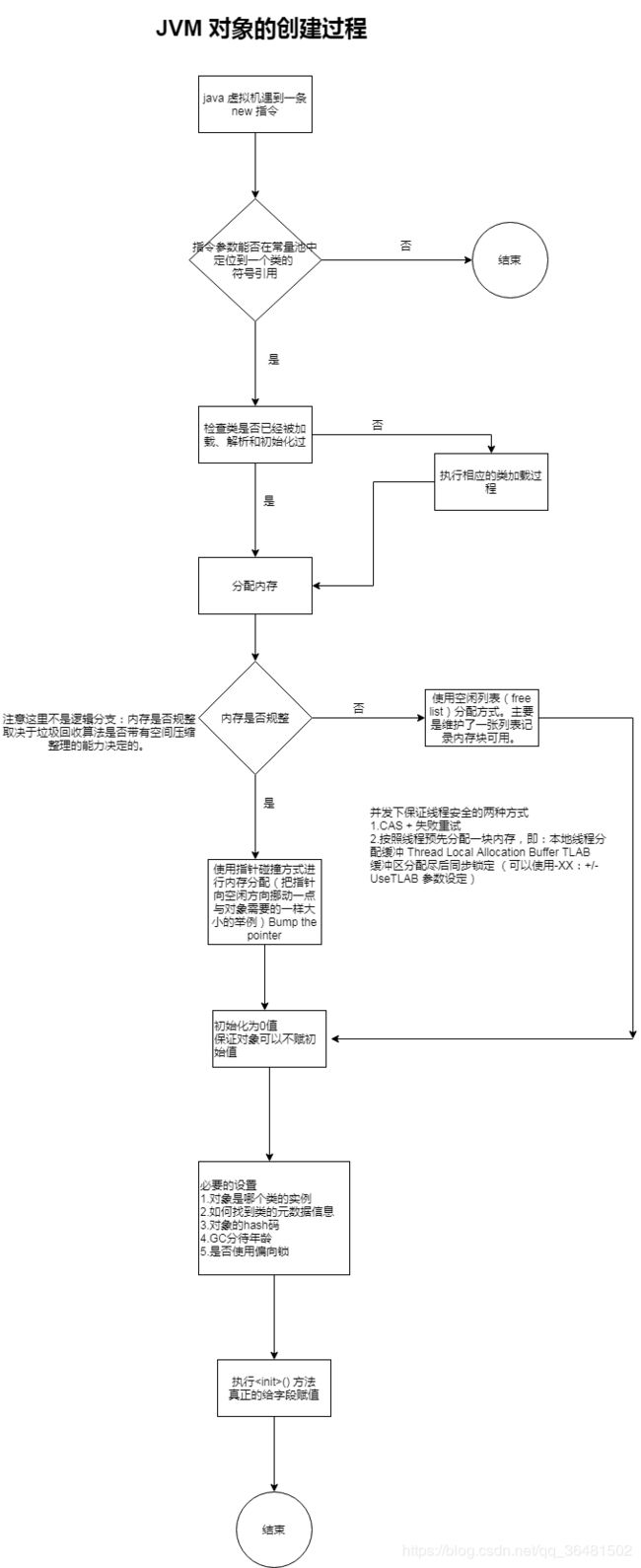
3.JVM 对象的创建过程
4.JVM对象内存结构

三、垃圾收集器及内存分配策略
1.可达性分析算法
目前主流的商用程序语言都是使用可达性分析算法(Reachbility Analysis)来判定对象是否存活。
通过GC roots的根对象作为起始节点,按照引用关系一直向下搜索,搜索做过的路径称为“引用链”,被引用链孤立的对象就是被回收的对象。
GC roots 包含:
- 虚拟机栈中的引用对象
- 方法区中类静态属性引用变量
- 方法区常量引用对象
- 本地方法栈中JNI (即native方法)引用的对象
- java虚拟机内部的引用:基本数据类型对应的Class对象、常驻异常对象、系统类加载器
- 所有被同步锁持有的对象
- 反映java虚拟机内部情况的JMXbean JVMTI中注册的回调、本地代码缓存等
2.回收方法区
2.1废弃的常量
例如通过String.intern() 入常量池的String常量已经没有任何地方引用
2.2 不再使用的类型
- 该类所有的实例都被回收了
- 该类对应的Class对象没在任何地方被引用
- 加载该类的类加载器已经被回收
规范里面并没对方法区垃圾回收做要求。但是大量使用反射、动态代理、CGlib等字节码框架动态生成jsp以及OSGi这类频繁自定义类加载器的场景中,通常需要虚拟机具备类型卸载的能力
3.垃圾收集算法
3.1 分代收集理论
分代收集建立在两个假说之上
- 弱分代假说:绝大多数对象都是朝生夕灭
- 强分代说:熬过越多次的垃圾收集对象就越难以消灭
所以一般垃圾收集器都划分为不同区域:新生代和老生代(yong generation、old generation)
3.2 标记-清楚算法(Mark-Sweep)
两步走:标记存活或已死的对象,回收
缺点:
- 执行效率不稳定,效率随着对象数量增长而降低
- 内存空间碎片化
3.3 标记-复制算法
把存活是对象复制到另外一片特定划定的区域(包括担保区域),来回倒腾。HotSpot的Serial 及 PreNew新生代采用的就是这种方法。因为如果对象存活较多的情况下会进行较多复制效率降低,所以一般用于新生代。
好处:
- 解决了大量独享执行效率底问题
- 解决了内存空间碎片化问题
坏处:
- 带来了一定空间浪费问题
3.4 标记整理算法(Mark Compact)
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
经典是排除了试验阶段的 jdk11以后的收集器能够放心在生产环境使用
四、经典垃圾收集器
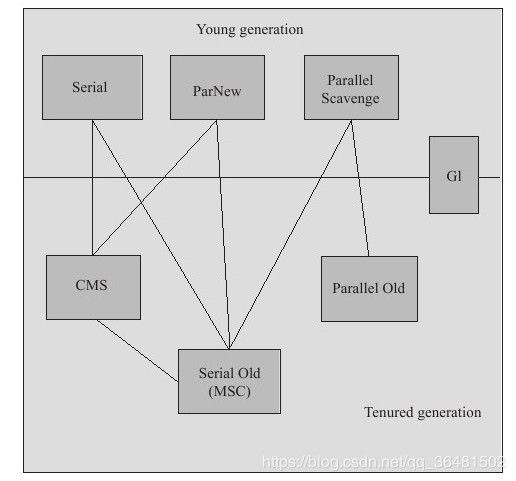
1.Serial收集器(新生代:标记-复制)
不并发
不并行
适合内存小(额外内存最小),单核处理器
2.ParNew收集器(新生代:标记-复制)
不并发
默认开启的收集线程数与处理器核心数量相同
Serial的并行版本
经典里面只有它是能配CMS的并行, 唯一优点
3.Parallel Scavenge收集器(新生代:标记-复制)
不并发
并行
和ParNew比 增加了
- 关注吞吐量
- 自适应的调节策略
目标:
达到一个可控制的吞吐量(Throughput)
也经常被称作“吞吐量优先收集器”
提供了参数控制 吞吐量 和 最大停顿时间
停顿时间:
不是限制得越小越好, 因为, 内存小 多收几次 没错停顿的时间就少了, 那样牺牲了吞吐量
4.Serial Old/PS MarkSweep收集器(老年代:标记-整理)
不并发
不并行
Serial Old是Serial收集器的老年
用处:
作为CMS收集器发生失败时的后备预案,在并发收集发生Concurrent Mode Failure时使用。
Parallel Scavenge收集器架构中本身有PS MarkSweep收集器来进行老年代收集,但是这个PS MarkSweep收集器与Serial Old的实现几乎是一样的
5.Parallel Old收集器(老年代:标记-整理)
不并发
并行
吞吐量优先组合:
在注重吞吐量或者处理器资源较为稀缺的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器这个组合
6.G1收集器(新生代老年代通用)
可预测的垃圾收集时间,G1在后台维护了一个优先列表,每次以目标时间回收价值最大对象。
分代理论上存在,但是在物理上是以region的形式存在。
除了有eden survivor old 增加了humongous概念,用以存放短期巨型对象