hadoop离线分析(简单版)-Hbase
目录
Hbase概述
Hbase与Hive、Pig、Impala、Tez对比
Hbase架构原理
Hbase逻辑模型
Hbase物理存储
HBase工作流程
HBase的高可用
HBase性能和优化
HBase shell访问
Hbase安装配置
Hbase简易测试
Hbase概述
HBase是一个分布式的、面向列的开源数据库,基于Hadoop架构的数据库系统。
Hbase两点不同:
1.它是一个适合于非结构化数据存储的数据库
2.HBase基于列的而不是基于行的模式
HBase–Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随机读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据。在需要实时读写,速记访问超大规模数据集时,可以使用Hbase。尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决方案,特别是一些关系类型的,在构建时并没有考虑超大规模和分布式的特点。许多商家通过复制和分区的方法来扩充数据库使其突破单个节点的界限,但这些功能通常都是事后增加的,安装和维护都和复杂。同时,也会影响RDBMS的特定功能,例如联接、复杂的查询、触发器、视图和外键约束这些操作在大型的RDBMS上的代价相当高,甚至根本无法实现。
HBase从另一个角度处理伸缩性问题。它通过线性方式从下到上增加节点来进行扩展。HBase不是关系型数据库,也不支持SQL,但是它有自己的特长,这是RDBMS不能处理的,HBase巧妙地将大而稀疏的表放在商用的服务器集群上。
Hbase特点:
1.Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力。
2.Zookeeper为HBase提供了稳定服务和failover机制。
3.Pig和hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。
4.Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
5.Hbase的大量☆:一个表可以有上亿行,上百万列。
6.面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
7.稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计得非常稀疏。
8.无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
9.数据多版本:每个单元中数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
10.数据类型单一:Hbase中数据都是字符串,没有类型。
Hbase与Hive、Pig、Impala、Tez对比
1)Hive:
基于Hbase的高层语言。类似于SQL --- 访问和处理关系型数据库的计算机语言。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件(例如xml)映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2)Pig:
一种操作hadoop的轻量级脚本语言,通常认为与其使用pig不如使用hive:
Pig包含两个部分:Pig Interface,Pig Latin,它一种数据流语言,用来快速轻松的处理巨大的数据。
Pig可以非常方便的处理HDFS和HBase的数据,和Hive一样,Pig可以非常高效的处理其需要做的,通过直接操作Pig查询可以节省大量的劳动和时间。当你想在你的数据上做一些转换,并且不想编写MapReduce jobs就可以用Pig。
Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。Pig最大的作用就是对mapreduce算法(框架)实现了一套shell脚本 ,类似我们通常熟悉的SQL语句,在Pig中称之为Pig Latin,在这套脚本中我们可以对加载出来的数据进行排序、过滤、求和、分组(group by)、关联(Joining),Pig也可以由用户自定义一些函数对数据集进行操作,也就是传说中的UDF(user-defined functions)。
3)Impala:
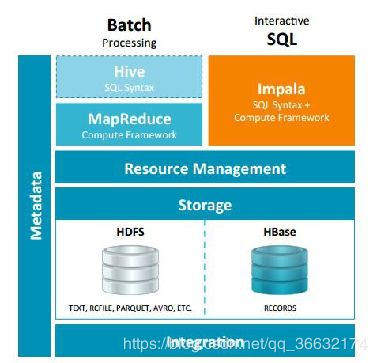
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。是对hive的一个补充,可以实现高效的SQL查询。
4)Tez:
Apache Tez是一个针对Hadoop数据处理应用程序的新分布式执行框架,是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。总结起来,Tez有以下特点:
①Apache二级开源项目
②运行在YARN之上
③适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
5)Hbase VS Pig VS Hive VS Impala VS Tez:
a.Hbase VS Pig VS Hive
Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使其成为Hadoop与其他BI工具结合的理想交集。
Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。
Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
Hive和Pig都可以与HBase组合使用,Hive和Pig还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变
的非常简单。
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目。想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
Hive是支持SQL语句的,执行会调用mapreduce,所以延迟比较高;HBase是面向列的分布式数据库,使用集群环境的内存做处理,效率会比hive要高,但是不支持sql语句。Hadoop开发和运行处理大规模数据,需要用hbase做数据库,但由于hbase没有类sql查询方式,所以操作和计算数据非常不方便,于是整合hive,让hive支撑在hbase数据库层面的hql查询,hive也即做数据仓库。
b.Hive,Hbase和Impala
①不同点

②相同点
是NOSQL数据库。
可用作开源。
支持服务器端脚本。
按照ACID属性,如Durability和Concurrency。
使用分片进行分区。
c.Impala和Hive
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
Impala和Hive不同:
1)Hive有很多的特性:
1、对复杂数据类型(比如arrays和maps)和窗口分析更广泛的支持
2、高扩展性
3、通常用于批处理
2)Impala更快
1、专业的SQL引擎,提供了5x到50x更好的性能
2、理想的交互式查询和数据分析工具
3、更多的特性正在添加进来
Impala与Hive在Hadoop中的关系如下图:
Hbase架构原理
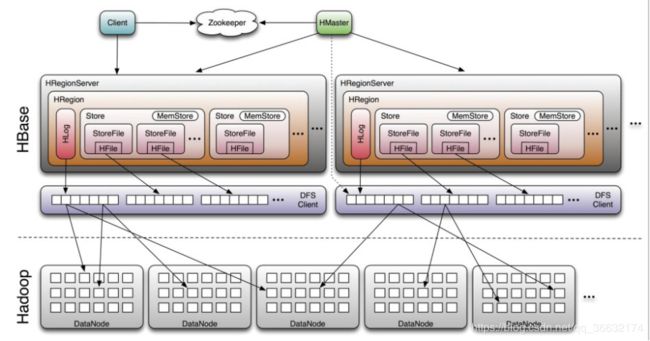
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、
Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作用。
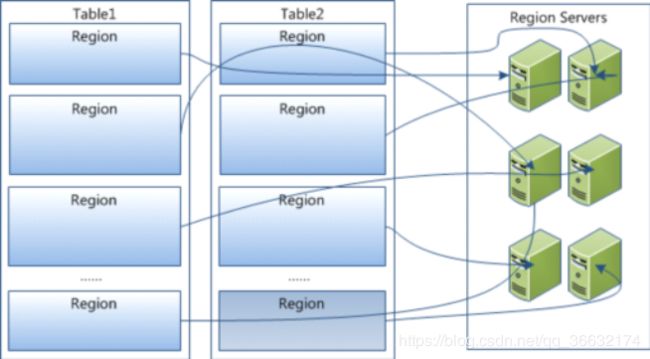
HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割
成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
1)Client
包含访问HBase的接口,并维护cache来加快对HBase的访问。比如cache的.META.元数据的信息。
2)Zookeeper
HBase依赖Zookeeper,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),Master与RegionServers启动
时会向Zookeeper注册。
1.保证任何时候,集群中只有一个Master
2.存储所有Rsgion的寻址入口
3.实时监控Region Server的上线和下线的信息,并实时通知给Master
4.存储Hbase的schema和table元数据
3)HMaster
1.为Region server分配region
2.管理HRegionServer,实现其负载均衡。
3.发现失效的Region,并将失效的Region分配到正常的RegionServer上
4.发现失效的Region server并重新分配其上的region。
5.当RegionSever失效的时候,协调对应Hlog的拆分
6.HDFS上的垃圾文件回收。
7.处理schema更新请求。
8.管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的
HRegion到其他HRegionServer上。
9.实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
10.管理namespace和table的元数据(实际存储在HDFS上)。
11.权限控制(ACL)。
4)HRegionServer
1.维护master分配给他的region,处理对这些region的io请求。
2.负责切分正在运行过程中变的过大的region。
3.处理来自客户端的读写请求
4.负责和底层HDFS的交互,存储数据到HDFS
5.读写HDFS,管理Table中的数据。
6.负责Storefile的合并工作
7.存放和管理本地HRegion。
8.Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的
HRegion/HRegionServer后)。
注意:client访问hbase上的数据时不需要master的参与,因为数据寻址访问zookeeper和region server,而数据读写访问region server。master仅仅维护table和region的元数据信息,而table的元数据信息保存在zookeeper上,因此master负载很低。
5)HRegion
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
每个region由以下信息标识:
< 表名,startRowkey,创建时间>
由目录表(-ROOT-和.META.)记录该region的endRowkey
Region被分配给哪个Region Server是完全动态的,所以需要机制来定位Region具体在哪个region server。
下面我们来看看Region是如何被定位的:
①通过zk里的文件/hbase/rs得到-ROOT-表的位置。
-ROOT-表只有一个region。
②通过-ROOT-表查找.META.表的第一个表中相应的region的位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个region在-ROOT-表中都是一行记录。
-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现 缓存失效,另外三次用来获取位置信息。
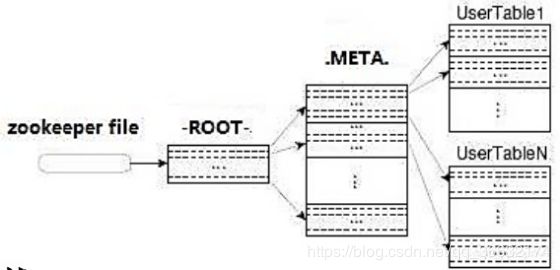
提示:
-ROOT-表:表包含.META.表所在的region列表,该表只有一个Region;Zookeeper中记录了-ROOT-表的location
.META.表:表包含所有的用户空间region列表,以及Region Server的服务器地址

HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。每个HRegionServer可以同时管理1000个左右的HRegion(这个数字怎么来的?没有从代码中看到限制,难道是出于经验?超过1000个会引起性能问题?来回答这个问题:感觉这个1000的数字是从
BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。
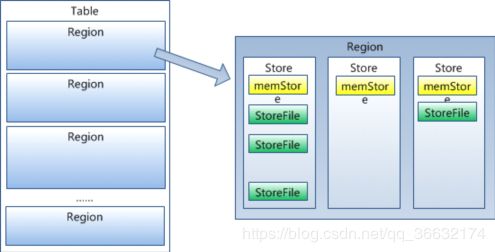
6)Store
每一个region由一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。 HBase以store的大小来判断是否需要切分region
7)MemStore
memStore是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。
8)StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
9)HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server
宕机,就可以从log中进行恢复。
HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。 Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。
10)LogFlusher
前面提到,数据以KeyValue形式到达HRegionServer,将写入WAL之后,写入一个SequenceFile。看过去没问题,但是因为数据流在写入文件系统时,经常会缓存以提高性能。这样,有些本以为在日志文件中的数据实际在内存中。这里,我们提供了一个LogFlusher的类。它调用 HLog.optionalSync(),后者根据hbase.regionserver.optionallogflushinterval (默认是10秒),定期调用Hlog.sync()。
另外,HLog.doWrite()也会根据hbase.regionserver.flushlogentries (默认100秒)定期调用Hlog.sync()。Sync() 本身调用HLog.Writer.sync(),它由SequenceFileLogWriter实现。
11)LogRoller
Log的大小通过$HBASE_HOME/conf/hbase-site.xml的hbase.regionserver.logroll.period限制,默认是一个小时。所以每60分钟,会打开一个新的log文件。久而久之,会有一大堆的文件需要维护。首先,LogRoller调用HLog.rollWriter(),定时滚动日志,之后,利用HLog.cleanOldLogs()可以清除旧的日志。它首先取得存储文件中的最大的sequence number,之后检查是否存在一个log所有的条目的“sequence number”均低于这个值,如果存在,将删除这个log。每个region server维护一个HLog,而不是每一个region一个,这样不同region(来自不同的table)的日志会混在一起,这样做的目的是不断追加 单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高table的写性能。带来麻烦的时,如果一个region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其他region server上进行恢复。
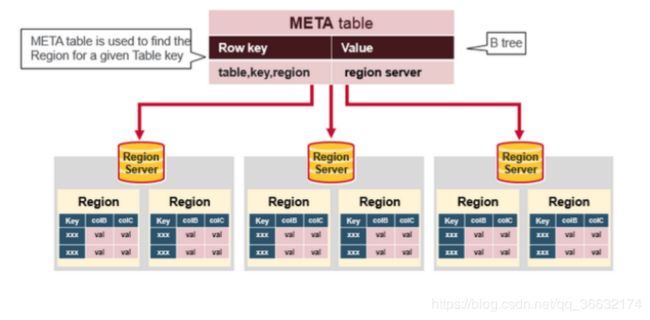
12)hbase:meta表
hbase:meta表存储了所有用户HRegion的位置信息,它的RowKey是:tableName,regionStartKey,regionId,replicaId等,它只有info列族,这个列族包含三个列,他们分别是:info:regioninfo列是RegionInfo的proto格式:regionId,tableName,startKey,endKey,offline,split,replicaId;info:server格式:HRegionServer对应的server:port;info:serverstartcode格式是HRegionServer的启动时间戳。
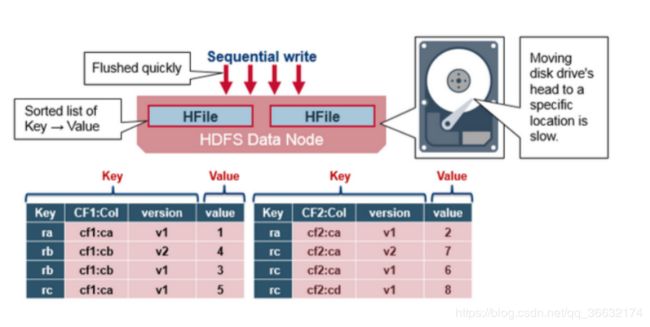
13)HFile格式
HBase的数据以KeyValue(Cell)的形式顺序的存储在HFile中,在MemStore的Flush过程中生成HFile,由于MemStore中存储的Cell遵循相同的排列顺序,因而Flush过程是顺序写,我们知道磁盘的顺序写性能很高,因为不需要不停的移动磁盘指针。
14)Column Family
Column Family又叫列族,Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。想到了一个非常类似的概念,理解起来就非常容易了。那就是家族的概念,我们知道一个家族是由于很多个的家庭组成的。列族也类似,列族是由一个一个的列组成(任意多)。Hbase表的创建的时候就必须指定列族。就像关系型数据库创建的时候必须指定具体的列是一样的。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。
15)Rowkey
Rowkey的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
由于Hbase只支持3种查询方式:
基于Rowkey的单行查询
基于Rowkey的范围扫描
全表扫描
因此,Rowkey对Hbase的性能影响非常大,Rowkey的设计就显得尤为的重要。设计的时候要兼顾基于Rowkey的单行查询也要键入Rowkey的范围扫描。
16)Region
Region的概念和关系型数据库的分区或者分片差不多。Hbase会将一个大表的数据基于Rowkey的不同范围分配到不同的Region中,每个Region负责一定范围的数据访问和存储。这样即使是一张巨大的表,由于被切割到不同的region,访问起来的时延也很低。
17)TimeStamp
TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不同版本的数据。在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp和服务器时间保持一致。在Hbase中,相同rowkey的数据按照timestamp倒序排列。默认查询的是最新的版本,用户可同指定timestamp的值来读取旧版本的数据。
Hbase逻辑模型
HBase 以表的形式存储数据。表由行和列组成。列划分为若干个列族(row family),如下图所示:
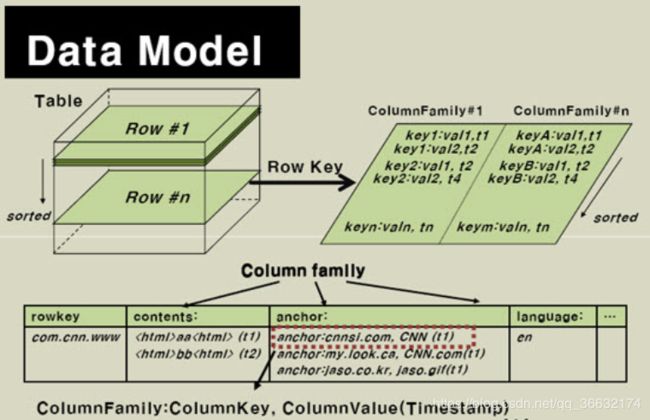
HBase的逻辑数据模型:
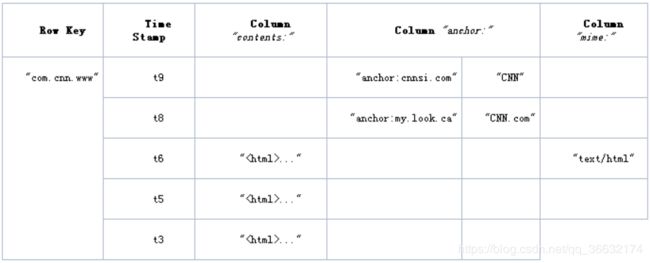
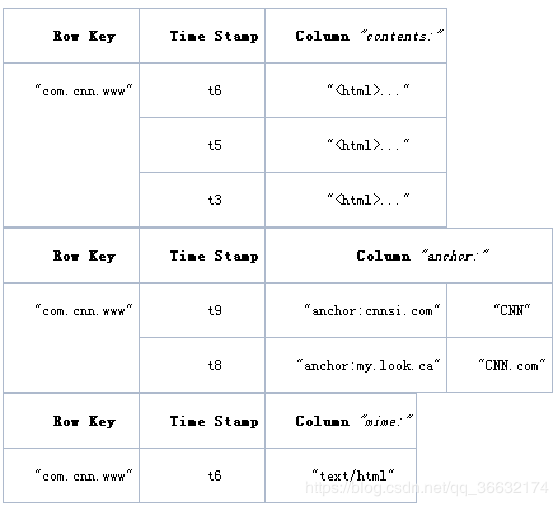
Hbase物理数据模型(实际存储的数据模型):
逻辑数据模型中空白cell在物理上是不存储的,因为根本没有必要存储,因此若一个请求为要获取t8时间的contents:html,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回。
Cell:
Cell 是由
{row key,column(=< family> + < label>),version}
唯一确定的单元。Cell 中的数据是没有类型的,全部是字节码形式存储。
Hbase物理存储
Table在行的方向上分割为多个HRegion,每个HRegion分散在不同的RegionServer中。
每个HRegion由多个Store构成,每个Store由一个memStore和0或多个StoreFile组成,每个Store保存一个Columns Family
HBase工作流程
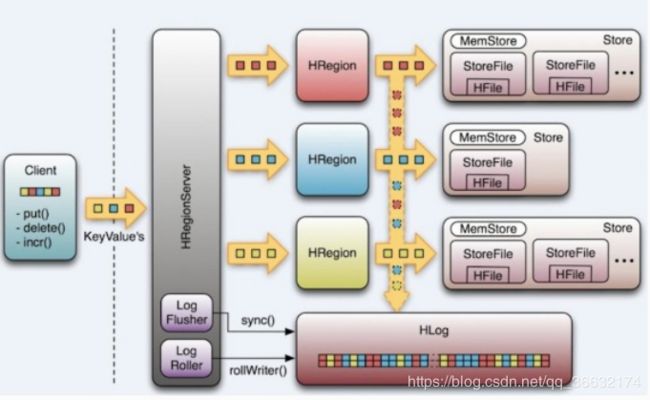
①Client
首先当一个请求产生时,HBase Client使用RPC(远程过程调用)机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写操作,Client与HRegionServer进行RPC。
②Zookeeper
HBase Client使用RPC(远程过程调用)机制与HMaster和HRegionServer进行通信,但如何寻址呢?由于Zookeeper中存储了-ROOT-表的地址和HMaster的地址,所以需要先到Zookeeper上进行寻址。HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点故障。
③HMaster
当用户需要进行Table和Region的管理工作时,就需要和HMaster进行通信。HBase中可以启动多个HMaster,通过Zookeeper的Master Eletion机制保证总有一个Master运行。
管理用户对Table的增删改查操作
管理HRegionServer的负载均衡,调整Region的分布
在Region Split后,负责新Region的分配
在HRegionServer停机后,负责失效HRegionServer上的Regions迁移
④HRegionServer
当用户需要对数据进行读写操作时,需要访问HRegionServer。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个 MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。一个HRegionServer会有多个HRegion和一个HLog。当HStore存储是HBase的核心了,其中由两部分组成:MemStore和StoreFiles。 MemStore是Sorted Memory Buffer,用户写入数据首先 会放在MemStore,当MemStore满了以后会Flush成一个 StoreFile(实际存储在HDHS上的是HFile)当StoreFile文件数量增长到一定阀值,就会触发Compact合并操作,并将多个StoreFile合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的读写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
HBase Put流程:
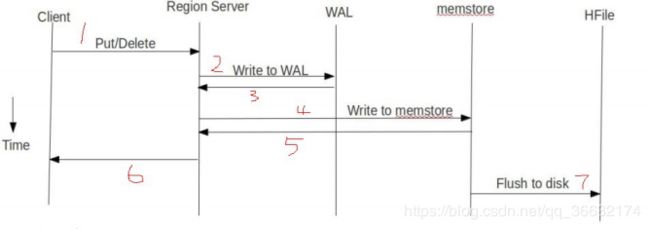
客户端:
客户端发起Put写请求,讲put写入writeBuffer,如果是批量提交,写满缓存后自动提交
根据rowkey将put吩咐给不同regionserver
服务端:
RegionServer将put按rowkey分给不同的region
Region首先把数据写入wal
wal写入成功后,把数据写入memstore
Memstore写完后,检查memstore大小是否达到flush阀值
如果达到flush阀值,将memstore写入HDFS,生成HFile文件
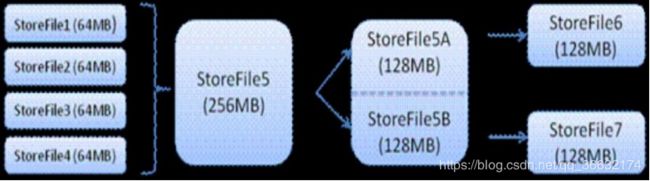
HBase Compact &&Split(合并和分割)
当StoreFile文件数量增长到一定阀值,就会触发Compact合并操作,并将多个StoreFile合并成一个StoreFile,当这个StoreFile大小超过一定阀值后,会触发Split操作,同时把当前Region Split成2个Region,这时旧的Region会下线,新Split出的2个Region会被HMaster分配到相应的HregionServer上,使得原先1个Region的压力得以分散到2个Region上。
如下图四个Storefile文件(从memstore文件经过flush而得到,默认64M的storefile文件)经过Compact合并成一个大的256M storefile文件,当设定的Region阀值为128M时,就会Split为两个128M的Storefile文件,然后 HMaster再把这两个storefile文件分配到不停地Regionserver上。
HFile
HBase中所有的数据文件都存储在Hadoop HDFS上,主要包括两种文件类型:
Hfile:HBase中KeyValue数据的存储格式,HFile是Hadoop的 二进制格式文件,实际上StoreFile就是对Hfile做了轻量级包装,即StoreFile底层就是HFile。
HLog File:HBase中WAL(write ahead log)的存储格式,物理上是Hadoop的Sequence File
HFile的存储格式如下:
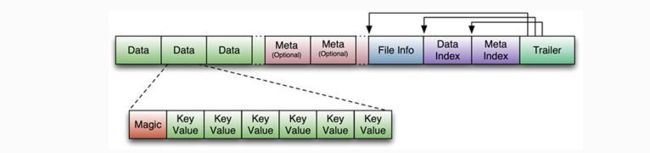
HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。 Data Block是hbase io的基本单元,为了提高效率,HRegionServer中有基于LRU的block cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的 Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。

上图可知,开始是两个固定长度的数值,分别表示key的长度和value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有那么复杂的结构,就是纯粹的二进制数据。
HBase的三维有序(即字典顺序)存储
Hfile是HBase中KeyValue数据的存储格式。从上面的 HBase物理数据模型中可以看出,HBase是面向列表(簇)的存储。每个Cell由 {row key,column(=< family> + < label>),version} 唯一确定的单元,他们组合在一起就是一个KeyValue。根据上述描述,这个KeyValue中的key就是{row key,column(=< family> + < label>),version} ,而value就是cell中的值。
HBase的三维有序存储中的三维是指:rowkey(行主键),column key(columnFamily+< label>),timestamp(时间戳或者版本号)三部分组成的三维有序存储。
rowkey是行的主键,它是以字典顺序排序的。所以 rowkey的设计是至关重要的,关系到你应用层的查询效率。我们在根据rowkey范围查询的时候,我们一般是知道startRowkey,如果我们通过scan只传startRowKey:d开头的,那么查询的是所有比d大的都查了,而我们只需要d开头的数据,那就要通过endRowKey来限制。我们可以通过设定endRowKey为:d 开头,后面的根据你的rowkey组合来设定,一般是加比startKey大一位。
column key是第二维,数据按rowkey字典排序后,如果rowkey相同,则是根据column key来排序的,也是按字典排序。
我们在设计table的时候要学会利用这一点。比如我们的收件箱。我们有时候需要按主题排序,那我们就可以把主题这设置为我们的column key,即设计为columnFamily+主题.,这样的设计。
timestamp时间戳,是第三维,这是个按降序排序的,即最新的数据排在最前面。
HLog Replay
根据以上的叙述,我们已经了解了关于HStore的基本原理,但我们还必须要了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因为一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog。有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每一次用户操作写入MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期(当文件已持久化到StoreFile中的数据)会滚出新的,并且删除旧的文件。当HRegionServer意外终止 后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的Hlog文件,将其中不同Region的Log数据进行拆分,分别放到相应Region的目录下,然后再将失效的Region重新分配,领取到这些Region的Regionserver在Load Region的过程中,会发现历史HLog需要处理,因此Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HLog存储格式
WAL(Write Ahead Log):RegionServer在处理插入和删除过程中,用来记录操作内容的日志,只有日志写入成功,才会通知客户端操作成功。
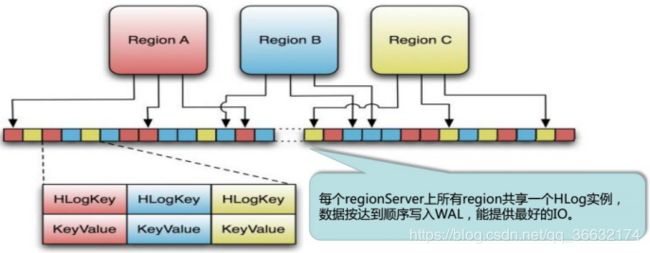
上图中是HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和Region名字外,同时还包括sequence number和timestamp,timestamp是”写入时间”,sequence number 的起始值为0,或者是最近一次存入文件系统中的sequence number。
HLog Sequence File 的Value是HBase的KeyValue对象昂,即对应HFile中的KeyValue。
HBase的高可用
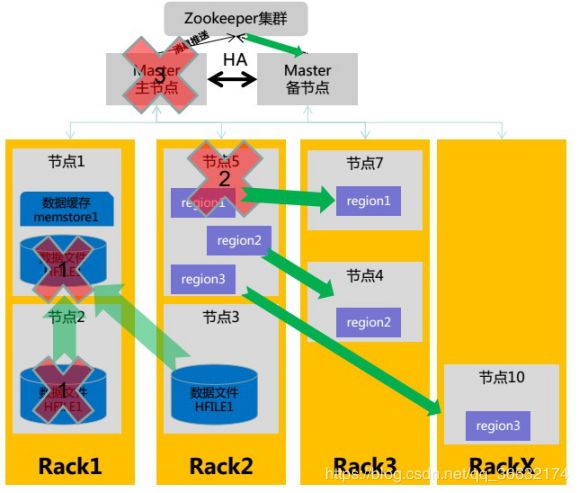
当出现右图三种情况的高可用策略:
1.HDFS机架识别策略:当数据文件损坏时,会找相同机架上备份的数据文件,如果相同机架上的数据文件也损坏会找不同机架备份数据文件。
2.HBase的Region快速恢复:当节点损坏时,节点上的丢失region,
会在其他节点上均匀快速恢复。
3.Master节点的HA机制:Master为一主多备。当Master主节点宕机后,剩下的备节点通过选举,产生主节点。
HBase性能和优化
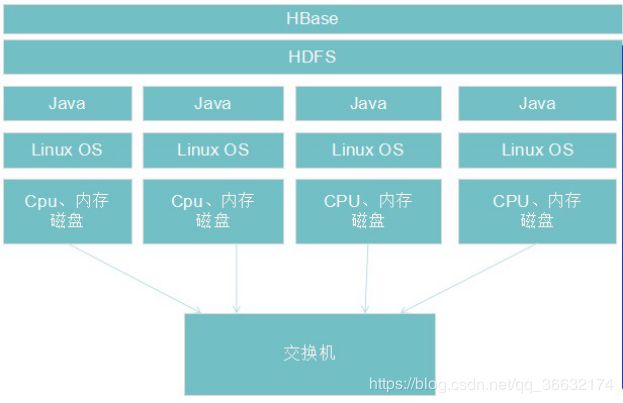
影响HBase性能的因素:
图中,从HDFS以下都属于HBase的支撑系统。从构成集群机器的底层硬件到把硬件和操作系统(尤其是文件系统),JVM,HDFS连接起来的网络之间的所有部件都会影响到HBase的性能。HBase系统的状态也会影响到HBase的系统。
例如,在集群中执行合并的时候或者Memstore刷写的时候与什么都没有做的时候相比,其性能表现是不同的。应用系统的性能还取决于它和HBase的交互方式,所以模式设计和其他环节一样起到了必不可少的作用。在评判HBase性能时,所有这些因素都有影响;在优化集群时,需要查看所有这些因素。
优化HBase支撑系统
(1)硬件选择
总的原则是,根据业务情况和集群规模大小选择合理的硬件。
(2)网络☆☆配置
基于当前阶段硬件的典型分布式系统都会受到网络的限制,HBase也不例外。在节点和机架顶置交换机之间建议采用10Gb以太网交换机。千万不要过于满额配置地使用网络,否则在高负载时,会影响HBase应用系统的性能。
(3)操作系统
一般情况下,只要使用Hadoop和HBase,操作系统通常选择Linux。可以选择Red Hat Enterprise Linux,CentOS,也可以选择成功部署过的其他操作系统。
(4)本地文件系统
本地Linux文件系统在HBase集群体系里起到了重要作用,并且严重影响到HBase的性能。虽然EXT4是推荐使用的本地文件系统,但没有大规模使用,相反EXT3和XFS已经在生产系统里得到成功使用,建议使用EXT3和XFS作为本地文件系统。
(5)HDFS
根据业务访问特点优化根据业务访问特点,将Hbase的工作负载大致分为以下四类:
(1)随机读密集型
对于随机读密集型工作负载,高效利用缓存和更好地索引会给HBase系统带来更高的性能。
(2)顺序读密集型
对于顺序读密集型工作负载,读缓存不会带来太多好处;除非顺序读的规模很小并且限定在一个特定的行键范围内,否则很可能使用缓存会比不使用缓存需要更频繁地访问硬盘。
(3)写密集型
写密集型工作负载的优化方法需要有别于读密集型负载。缓存不再起到重要作用。写操作总是进入MemStore,然后被刷写生成新的Hfile,以后再被合并。获得更好写性能的办法是不要太频繁刷写、合并或者拆分,因为在这段时间里IO压力上升,系统会变慢。
(4)混合型
对于完全混合型工作负载,优化方法会变得复杂些。优化时,需要混合调整多个参数来得到一个最优的组合。
其它角度来优化HBase性能
(1)JVM垃圾回收优化
(2)本地memstore分配缓存优化
(3)Region拆分优化
(4)Region合并优化
(5)Region预先加载优化
(6)负载均衡优化
(7)启用压缩
(8)GZIP、snappy、lzo,推荐snappy,压缩比稍差于lzo;但是压缩速度高于lzo,并且与lzo有差不多的 解压缩速度。
(9)进行预分区,从而避免自动split,提高hbase响应速度
(10)避免出现region热点现象,启动按照table级别进行balance
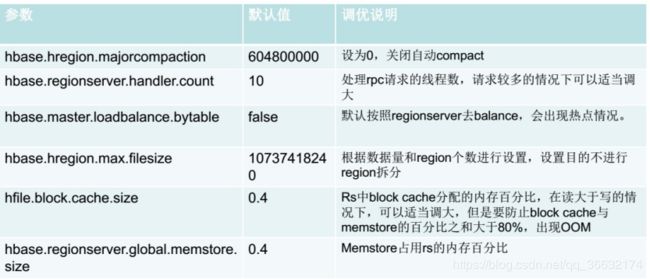
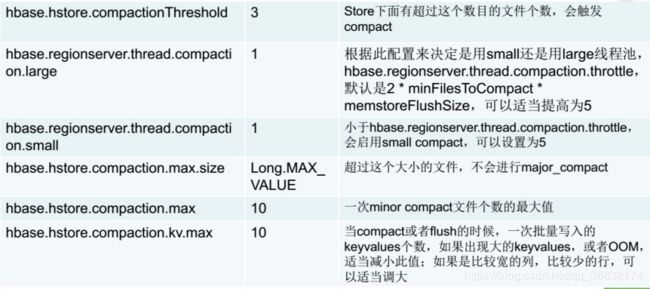
HBase常见的调优参数

HBase shell访问
HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建、删除及修改表, 还可以向表中
添加数据、列出表中的相关信息等。
在启动 HBase 之后,用户可以通过下面的命令进入 HBase Shell 之中,命令如下所示:
[hadoop@CDHNode1 ~]$hbase shell
输入 help 可以看到命令分组。(注意命令都是小写,有大小写的区分)

部分命令

general操作
查询 HBase 服务器状态 status。
查询hbase版本 version
ddl操作
1、 创建一个表
create ‘table1’, ‘tab1_id’, ‘tab1_add’, ‘tab1_info’
2、 列出所有的表

3、 获得表的描述
describe “table1”
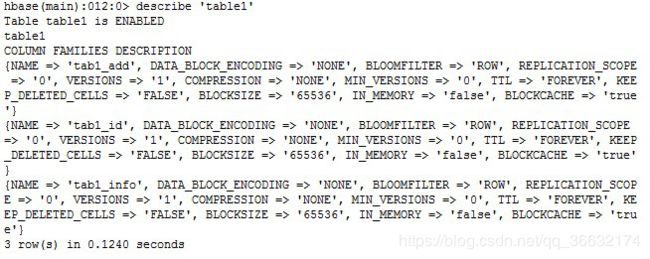
4、 删除一个列族 disable alter enable 注意删除前,需要先把表disable
disable ‘table1’
alter ‘table1’, {NAME=>’tab1_add’, METHOD=>’delete’}
enable ‘table1’
5、 查看表是否存在
exists ‘table2’
6、 判断表是否为‘enable’
is_enabled ‘table1’
7、 删除一个表
disable ‘table1’
drop ‘table1’
dml操作
1、 插入几条记录
put ‘member’, ‘scutshuxue’, ‘info:age’, ‘24’
put ‘member’, ‘scutshuxue’, ‘info:birthday’, ‘1987-06-17’
put ‘member’, ‘scutshuxue’, ‘info:company’, ‘alibaba’
put ‘member’, ‘scutshuxue’, ‘address:contry’, ‘china’
put ‘member’, ‘scutshuxue’, ‘address:province’, ‘zhejiang’
put ‘member’, ‘scutshuxue’, ‘address:city’, ‘hangzhou’
put命令比较简单,只有这一种用法:
hbase> put ‘t1′, ‘r1′, ‘c1′, ‘value’, ts1
t1指表名,r1指行键名,c1指列名,value指单元格值。ts1指时间戳,一般都省略掉了。
2、 全表扫描 scan
scan member
3、 获得数据 get
1) 获得一行的所有数据
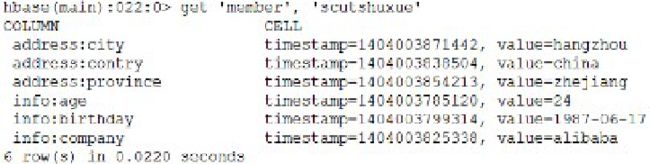
2) 获得某行,某列族的所有数据

3) 获得某行,某列族,某列的所有数据

4、 更新一条记录 put(把scutshuxue年龄改为99)
put ‘member’, ‘scutshuxue’, ‘info:age’, 99
5、 删除 delete、 deleteall
1) 删除行’scutshuxue’, 列族为‘info’ 中age的值
delete ‘member’, ‘scutshuxue’, ‘info:age’
2) 删除整行
deleteall ‘member’, ‘scutshuxue’
6、 查询表中有多少行
count ‘member’
7、 给‘xiaoming’这个id增加’info:age’字段,并使用counter实现递增
incr ‘member’, ‘xiaoming’, ‘info:age’
8、 将整个表清空
truncate ‘member’
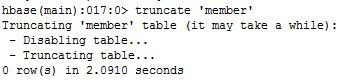
可以看出,HBase 是通过先对表执行 disable,然后再执行 drop 操作后重建表来实现 truncate 的功能的。
Hbase安装配置
1)Hbase安装前需要的环境:
JDK+hadoop+zookeeper
2)修改ulimit
在Apache HBase官网的介绍中有提到,使用 HBase 推荐修改ulimit,以增加同时打开文件的数量,推荐nofile至少
10,000但最好10,240(It is recommended to raise the ulimit to at least 10,000, but more likely
10,240, because the value is usually expressed in multiples of 1024.)
修改 /etc/security/limits.conf 文件,在最后加上nofile(文件数量)、nproc(进程数量)属性,如下:
vim /etc/security/limits.conf
* soft nofile 40960 * 代表针对所有用户
* hard nofile 40960 noproc 是代表最大进程数
* soft nproc 40960 nofile 是代表最大文件打开数
* hard nproc 40960
重启服务器
reboot
重启之后检查:jdk,scala,tomcat,zookeeper是否启动
启动hadoop和spark
2)安装配置Hbase(每台机器)
上传离线压缩包hbase-1.4.3-bin.tar.gz到/home/hadoop01
mv /home/hadoop01/hbase-1.4.3-bin.tar.gz /usr/software
tar -xvf hbase-1.4.3-bin.tar.gz
解压后出现目录:hbase-1.4.3
重命名:mv hbase-1.4.3-bin hbase
配置环境变量:
vim /etc/profile
export HBASE_HOME=/usr/software/hbase
export PATH=${HBASE_HOME}/bin:$PATH

复制hdfs-site.xml配置文件:
复制$HADOOP_HOME/etc/hadoop/hdfs-site.xml到$HBASE_HOME/conf目录下,这样以保证hdfs与hbase两边一致,
这也是官网所推荐的方式。在官网中提到一个例子,例如hdfs中配置的副本数量为5,而默认为3,如果没有将最新
的hdfs-site.xml复制到$HBASE_HOME/conf目录下,则hbase将会按3份备份,从而两边不一致,导致会出现异常。
cp /usr/software/hadoop-3.0.1/etc/hadoop/hdfs-site.xml /usr/software/hbase/conf/
配置hbase-env.sh:
cd /usr/software/hbase/conf
vim hbase-env.sh
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export HBASE_MANAGES_ZK=false
编辑 $HBASE_HOME/conf/hbase-env.sh 配置环境变量,由于本实验是使用单独配置的zookeeper,
因此,将其中的 HBASE_MANAGES_ZK 设置为 false
配置hbase-site.xml:
注意这里的zookeeper数据目录与hadoop ha的共用,也即要与 zoo.cfg 中配置的一致
Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
官网多次强调这个目录不要预先创建,hbase会自行创建,否则会做迁移操作,引发错误
至于端口,有些是8020,有些是9000,看 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 里面的配置,本实验配置的是
dfs.namenode.rpc-address.mycluster1.nn1,dfs.namenode.rpc-address.mycluster1.nn2的端口,hadoop3.0rpc端口已改成9820
因为hadoop的core-site.xml中没有配置mycluster1的端口号,所以此处也不需要配置
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
配置regionserver
vim /usr/software/hbase/conf/regionservers
hadoop01
hadoop02
hadoop03
hadoop04
hadoop05
把配置完的hbase复制到其它节点
scp -r hbase hadoop02@hadoop02:/home/hadoop02
3)启动hbase
启动hbase之前确定zookeeper和hdfs已经启动!!
在主节点上运行启动hbase:
cd /usr/software/hbase
bin/start-hbase.sh
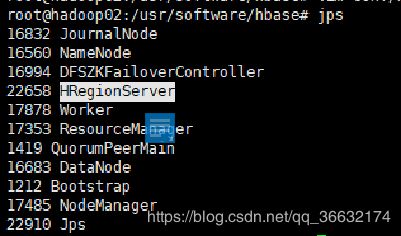
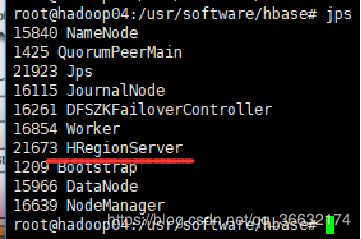
主节点加入:HMaster和HRegionServer进程,副节点加入:HRegionServer
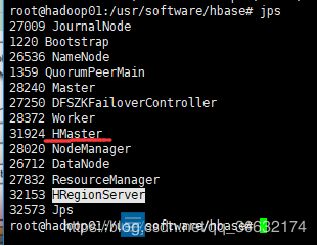
通过浏览器访问:
http://hadoop01:16010
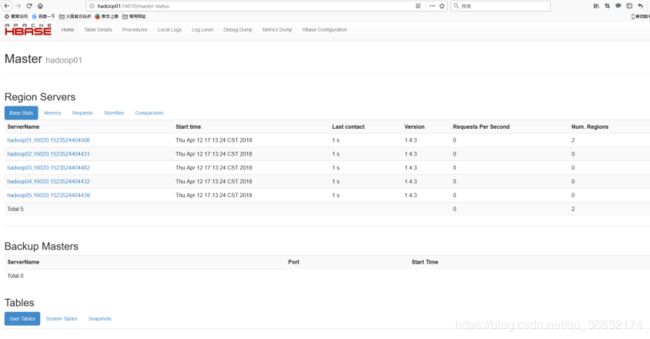
为了保证集群的可靠性,可以启动多个HMaster
bin/hbase-daemon.sh start master
目前启动hadoop01和hadoop02作为Master
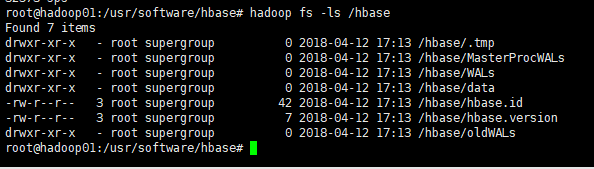
查看hbase的目录:hadoop fs -ls /hbase
Hbase简易测试
使用hbase shell进入到 hbase 的交互命令行界面,这时可进行测试使用
cd /usr/software/hbase
bin/hbase shell
1.查看集群状态和节点数量
hbase(main):001:0> status
2.创建表
create 'testtable','c1','c2'
hbase创建表create命令语法为:表名、列名1、列名2、列名3
3.查看表
list 'testtable'
4.导入数据
put 'testtable','row1','c1','row1_c1_value'
put 'testtable','row2','c2:s1','row1_c2_s1_value'
put 'testtable','row2','c2:s2','row1_c2_s2_value'
导入数据的命令put的语法为表名、行值、列名(列名可加冒号,表示这个列簇下面还有子列)、列数据
5.全表扫描数据
scan 'testtable'
6.根据条件查询数据
get 'testtable','row1'
7.表失效
使用 disable 命令可将某张表失效,失效后该表将不能使用,例如执行全表扫描操作,会报错,如下
disable 'testtable'
0 row(s) in 2.3090 seconds
hbase(main):011:0> scan 'testtable'
ERROR: testtable is disabled.
Here is some help for this command:
Scan a table; pass table name and optionally a dictionary of scanner
specifications. Scanner specifications may include one or more of:
TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, ROWPREFIXFILTER, TIMESTAMP,
MAXLENGTH or COLUMNS, CACHE or RAW, VERSIONS, ALL_METRICS or METRICS
8.表重新生效
使用 enable 可使表重新生效,表生效后,即可对表进行操作,例如进行全表扫描操作
enable 'testtable'
0 row(s) in 1.2800 seconds
hbase(main):013:0> scan 'testtable'
ROW COLUMN+CELL
row1 column=c1:, timestamp=1499225862922, value=row1_c1_value
row2 column=c2:s1, timestamp=1499225869471, value=row1_c2_s1_value
row2 column=c2:s2, timestamp=1499225870375, value=row1_c2_s2_value
2 row(s) in 0.0590 seconds
9.删除数据表
使用drop命令对表进行删除,但只有表在失效的情况下,才能进行删除,否则会报错,如下
hbase(main):014:0> drop 'testtable'
ERROR: Table testtable is enabled. Disable it first.
先对表失效,然后再删除,则可顺序删除表
hbase(main):008:0> disable 'testtable'
0 row(s) in 2.3170 seconds
hbase(main):012:0> drop 'testtable'
0 row(s) in 1.2740 seconds
10.退出 hbase shell
quit