【windows10】自定义数据集训练yolact实例分割
目录
- 序言
- 一、开发环境
- 二、制作数据集
- 三、修改配置
- 四、开始训练
- 五、demo测试
- 六、可能出现的问题:
序言
在实例分割中,比较出名的是mask RCNN,尽管精度很高,但是因为基于二阶段,速度比较慢,达不到实时性要求,所以提出了Yolact实例分割算法,使得实例分割能够达到实时性,并且有着不错的精度,如果在项目中,对于一些比较简单的数据集而言,yolact是完全可以胜任的,而且速度很快,相对于mask rcnn而言,yolact除了速度快以外,在一定程度上,实例分割结果&掩码质量要优于mask rcnn,这得益于较大的mask尺寸和没有特征repooling带来的信息损失。如果你项目需要的用到实例分割,不妨试一试yolact。

一、开发环境
- windows10
- pytorch1.2
- pychram
- python3.7
- GTX 2070
我使用的代码是这个yolact_mini,首先将代码下载到本地并解压,安装所需要的依赖,缺什么装什么就好了。
将作者提供的预训练权重下载下来,这里作者提供了百度云,当然本人也整理好了,可以直接点击这里保存下载:
链接: yolact权重百度云
提取码:ld21
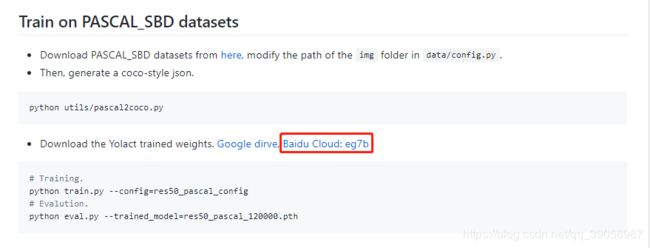
下载下来后在程序中创建一个weights文件夹,将预训练权重存到里面:

整个文件夹目录如下,这里的images文件夹是存放用于测试的图片,results文件夹存放的是测试后保存的图片,tersorboard_log是记录训练过程日志文件,test.py是我写的无关脚本,这几个都可以先不用管。
二、制作数据集
数据集的制作使用的是labelme,这里怎么安装和使用就不再描述了,这里介绍一下标注需要注意的几个点:
-
同一张图片中如果有多个同类物体的实例目标,应该在实例标签后添加“-1,-2,-3…”等,例如:
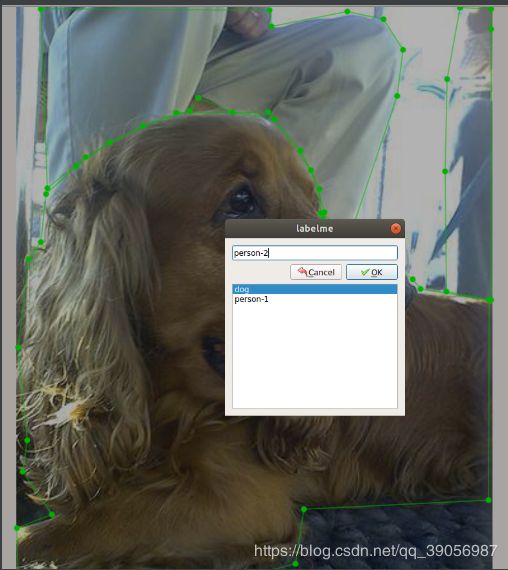
上图中有两个person实例,所以应该用-1,-2区分,如果只有一个,比如dog,可以不添加区分。 -
标注完后,会在文件夹中生成对应的json文件,然后我们需要将每个图片json转换为coco格式,首先创建一个label.txt,内容如下,其中后面四个为自己的实例分割目标,前面两个是必须的,不可以删掉,只需修改添加自己的实例目标即可:

-
在pycharm自带的终端中运行labelme2coco.py文件,命令如下:
python utils/labelme2coco.py your-image-and-labelme-json-path your-expected-output-folder --labels the-path-of-labels.txt
其中:
- your-image-and-labelme-json-path :是你刚才标注好的json文件和图片的文件夹;
- your-expected-output-folder :是你要输出的数据集保存的文件夹;
- the-path-of-labels.txt : 是你刚才写的label.txt文件。
作为参考,我的命令行格式为:
python utils/labelme2coco.py G:\fapiao\json_train G:\fapiao\coco_trian_image --labels G:\fapiao\label.txt
python utils/labelme2coco.py G:\fapiao\json_val G:\fapiao\coco_val_image --labels G:\fapiao\label.txt
这里要注意的是,因为要划分训练集和验证集,所以我是分开运行的,验证集也需要另外生成。
最后得到两个文件夹:G:\fapiao\coco_trian_image、G:\fapiao\coco_val_image,然后同级目录下新建另一个文件夹:json_to_coco,把这两个文件夹内的内容复制到这个文件夹中,最后得到:

因为会有冲突,两个annotations名字做了修改,得到train和val,JPEGImages里面存放的是所有训练要用到的图片。
数据集制作完成,记住这个地址,一会要用到:
G:\fapiao\json_to_coco
三、修改配置
要用自己数据集训练,还需要做以下几个修改:
- 修改data\config.py文件,把作者的注释掉,修改成自己数据集,如果你的目标只有一类的话,需要在后面添加一个“,”区分开,例如(“dog”,),否则程序会将d,o,g三个字母作为你的实例目标,得到的分类是错误的,如果是多类则可以不用管;


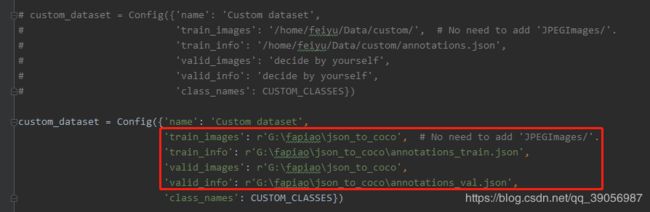
- 然后同文件下修改数据集配置,把刚才制作好的数据集地址填进去,将作者的注释掉或者删掉:
- 最后再修改res50_custom_config/res101_custom_config,可以自定义迭代轮次和优化区间,这里你用哪个就修改哪个,因为我两个(res50、res101)都跑过了,所以都做了修改:

这里需要说明的是,程序中没有提供轮次的修改,可根据最大迭代次数进行计算。比如我的数据集只有2000张左右,批次给的是4,我设置了25000,大概迭代轮次为50轮,可以根据自己数据集数量依次类推设置,lr_steps是学习率衰减区间,也可以根据自己设置的最大迭代次数进行设置。至此,配置也修改完成了。
四、开始训练
在pychram终端中输入:python train.py --config=res50_custom_config --batch_size 4
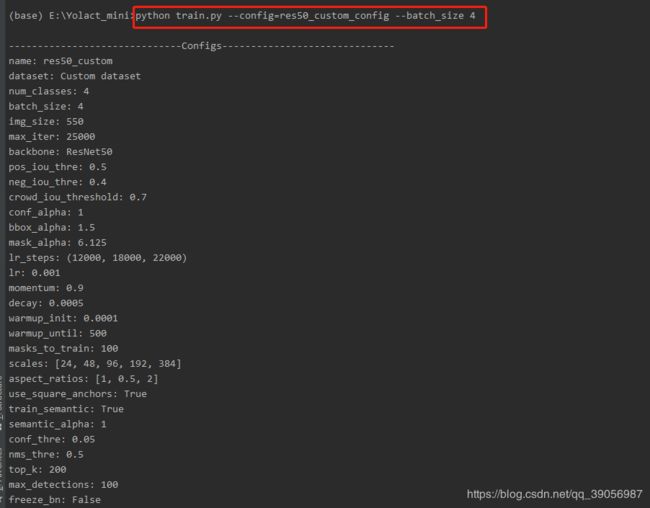
成功开始训练会出现以下信息:

默认迭代10000次会保存一次模型,可以在传参时进行修改。如果训练中断可以使用–resume进行恢复训练:
python train.py --config=res50_custom_config --batch_size 4 --resume (最后一次保存的权重地址)
训练结束后会输出评估的结果,权重保存在weights文件夹中:

五、demo测试
需要新建一个文件夹images,将需要测试的图片放在文件夹中,就如我前面介绍的目录结构那样。
在测试部分,我修改了以下程序,使得处理后的图片可以按照我如下展示的格式输出,如果不修改的话好像是无法将处理后的图片保存的:
- 对utils/output_utils.py的draw_img()函数做了以下修改,输出mask图(.png):

- 在detect.py中,修改保存:
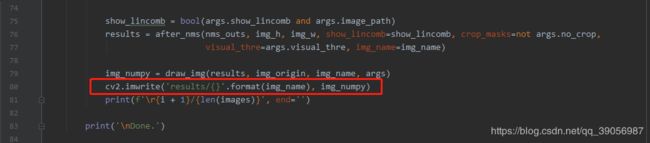
修改完后,然后运行:
python detect.py --trained_model=best_32.2_res50_custom_20000.pth --image images
得到的结果会输出到results/images文件夹中,总体来说,效果还是不错的:


六、可能出现的问题:
在训练过程中遇到最多的问题还是显存爆掉和多进程加载数据集时意外退出的问题,显存爆的问题解决方法是将批次调小;多进程读取意外退出有可能是因为你电脑开了多个应用程序,导致进程被占用,需要把其他程序关掉。还有就是检查自己的数据集图片像素是不是太大,如果数据集像素普遍太大的话CPU在加载数据的时候也会报错,就比如我最开始用的是手机拍照的图片(4000*3000的像素)进行训练,没训练几个轮次就报错意外退出了,后来是将图片缩小了一倍再送入程序中训练才得以解决。

上面都是一些比较普遍的问题,还有一些代码上运行的小问题博主也记得不是太清楚了,如果不是意外退出的可以试着自己排查。
整体训练过程大致就这些,如果博主表述的不是很明确的话可以结合作者提供的README.md文件一起看,相信对你的理解会更有帮助。