万无一失:网站的高可用架构
一、网站的高可用架构
2011年4月12曰,亚马逊计算服务EC2 ( Elastic Computer Cloud )发生故障,其 ESB( Elastic Block Storage)服务不可用,故障持续了数天,最终还是有部分数据未能恢复。这一故障导致美国许多使用亚马逊石服务的知名网站(如:Foursquare,Quora)受 到影响,并引发了人们对使用云计算安全性、可靠性的大规模讨论。
EC2 ( Elastic Computer Cloud ):弹性计算机云ESB( Elastic Block Storage):弹性块存储
2010年1月12日,百度被黑客攻击,其DNS域名被劫持,导致百度全站长达数小时不可访问。该事件一时成为新闻焦点,各种媒体争相报道。
网站的可用性(Availability )描述网站可有效访问的特性(不同于另一个网站运营指标:Usability,通常也被译作可用性,但是后者强调的是网站的有用性,即对最终用户的 使用价值),相比于网站的其他非功能特性,网站的可用性更牵动人们的神经,大型网站 的不可用事故直接影响公司形象和利益,许多互联网公司都将网站可用性列入工程师的 绩效考核,与奖金升迁等利益挂钩。
1.1、网站可用性的度量与考核
网站的页面能完整呈现在最终用户面前,需要经过很多个环节,任何一个环节出了 问题,都可能导致网站页面不可访问。DNS会被劫持、CDN服务可能会挂掉、网站服务 器可能会宕机、网络交换机可能会失效、硬盘会损坏、网卡会松掉、甚至机房会停电、 空调会失灵、程序会有Bug、黑客会攻击、促销会引来大量访问、第三方合作伙伴的服务 会不可用……要保证一个网站永远完全可用几乎是一件不可能完成的使命。
1.1.1、网站可用性度量
网站不可用也被称作网站故障,业界通常用多少个9来衡量网站的可用性,如QQ的 可用性是4个9,即QQ服务99.99%可用,这意味着QQ服务要保证其在所有运行时间中, 只有0.01 %的时间不可用,也就是一年中大约最多53分钟不可用。
网站不可用时间(故障时间)=故障修复时间点-故障发现(报告)时间点
网站年度可用性指标=(1-网站不可用时间/年度总时间)x 100%
对于大多数网站而目,2个9是基本可用,网站年度不可用时间小于88小时;3个9 是较高可用,网站年度不可用时间小于9小时;4个9是具有自动恢复能力的高可用,网 站年度不可用时间小于53分钟;5个9是极高可用性,网站年度不可用时间小于5分钟。
由于可用性影响因素很多,对于网站整体而言,达到4个9,乃至5个9的可用性, 除了过硬的技术、大量的设备资金投入和工程师的责任心,还要有个好运气。
常使用Twitter的用户或多或少遇到过那个著名的服务不可用的鲸鱼页面,事实上, Twitter网站的可用性不足2个9。
1.1.2、网站可用性考核
可用性指标是网站架构设计的重要指标,对外是服务承诺,对内是考核指标。从管 理层面,可用性指标是网站或者产品的整体考核指标,具体到每个工程师的考核,更多 的是使用故障分。
所谓故障分是指对网站故障进行分类加权计算故障责任的方法。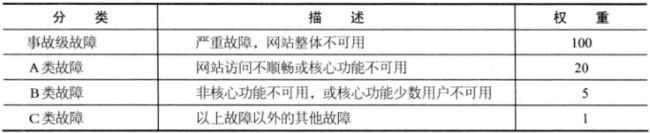
在年初或者考核季度的开始,会根据网站产品的可用性指标计算总的故障分,然后根据团队和个人的职责角色分摊故障分,这个可用性指标和故障分是管理预期。在实际发生故障的时候,根据故障分类和责任划分将故障产生的故障分分配给责任者承担。等年末或者考核季度末的时候,个人及团队实际承担的故障分如果超过了年初分摊的故障分,绩效考核就会受到影响。
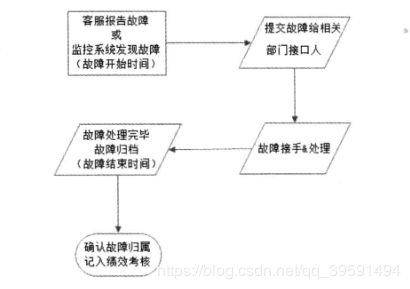
有时候一个故障责任可能由多个部门或团队来承担,故障分也会相应按责任分摊到 不同的团队和个人。
不同于其他架构指标,网站可用性更加看得见摸得着,跟技术、运营、相关各方的 绩效考核息息相关,因此在架构设计与评审会议上,关于系统可用性的讨论与争执总是 最花费时间与精力的部分。
当然,不同的公司有不同的企业文化和市场策略,这些因素也会影响到系统可用性 的架构决策,崇尚创新和风险的企业会对可用性要求稍低一些;业务快速增长的网站忙 于应对指数级增长的用户,也会降低可用性的标准;服务于收费用户的网站则会比服务 于免费用户的网站对可用性更加敏感,服务不可用或关键用户数据丢失可能会导致收费 用户的投诉甚至引来官司。
1.2、网站的高可用架构
通常企业级应用系统为提高系统可用性,会采用较昂贵的软硬件设备,如IBM的小 型机乃至中型机大型机及专有操作系统、Oracle数据库、EMC存储设备等。互联网公司 更多地采用PC级服务器、开源的数据库和操作系统,这些廉价的设备在节约成本的同时 也降低了可用性,特别是服务器硬件设备,低价的商业级服务器一年宕机一次是一个大 概率事件,而那些高强度频繁读写的普通硬盘,损坏的概率则要更高一些。
既然硬件故障是常态,网站的高可用架构设计的主要目的就是保证服务器硬件故障 时服务依然可用、数据依然保存并能够被访问。
实现上述高可用架构的主要手段是数据和服务的冗余备份及失效转移,一旦某些服 务器宕机,就将服务切换到其他可用的服务器上,如果磁盘损坏,则从备份的磁盘读取 数据。
一个典型的网站设计通常遵循如图:
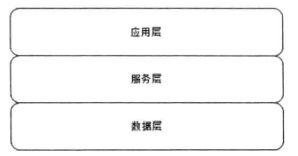
典型的分层模型是三层,即应用层、服务层、数据层;各层之间具有相对独立性, 应用层主要负责具体业务逻辑处理;服务层负责提供可复用的服务;数据层负责数据的 存储与访问。中小型网站在具体部署时,通常将应用层和服务层部署在一起,而数据层 则另外部署
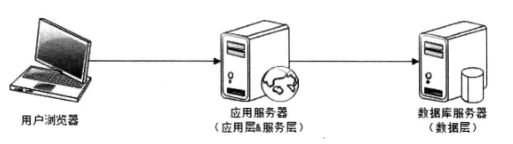
在复杂的大型网站架构中,划分的粒度会更小、更详细,结构更加复杂,服务器规 模更加庞大,但通常还是能够把这些服务器划分到这三层中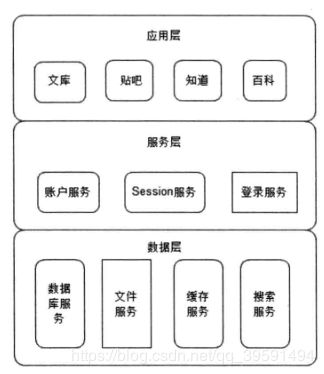
不同的业务产品会部署在不同的服务器集群上,如某网站的文库、贴吧、百科等属 于不同的产品,部署在各自独立的服务器集群上,互不相干。这些产品又会依赖一些共 同的复用业务,如注册登录服务、Session管理服务、账户管理服务等,这些可复用的业 务服务也各自部署在独立的服务器集群上。至于数据层,数据库服务、文件服务、缓存 服务、搜索服务等数据存储与访问服务都部署在各自独立的服务器集群上。
大型网站的分层架构及物理服务器的分布式部署使得位于不同层次的服务 器具有不同的可用性特点。关闭服务或者服务器岩机时产生的影响也不相同, 尚可用的解决方案也差异甚大。
位于应用层的服务器通常为了应对高并发的访问请求,会通过负载均衡设备将一组 服务器组成一个集群共同对外提供服务,当负载均衡设备通过心跳检测等手段监控到某 台应用服务器不可用时,就将其从集群列表中剔除,并将请求分发到集群中其他可用的 服务器上,使整个集群保持可用,从而实现应用高可用。
位于服务层的服务器情况和应用层的服务器类似,也是通过集群方式实现高可用, 只是这些服务器被应用层通过分布式服务调用框架访问,分布式服务调用框架会在应用 层客户端程序中实现软件负载均衡,并通过服务注册中心对提供服务的服务器进行心跳检 测,发现有服务不可用,立即通知客户端程序修改服务访问列表,剔除不可用的服务器。
位于数据层的服务器情况比较特殊,数据服务器上存储着数据,为了保证服务器宕 机时数据不丢失,数据访问服务不中断,需要在数据写入时进行数据同步复制,将数据 写入多台服务器上,实现数据冗余备份。当数据服务器宕机时,应用程序将访问切换到 有备份数据的服务器上。
网站升级的频率一般都非常高,大型网站一周发布一次,中小型网站一天发布几次。 每次网站发布都需要关闭服务,重新部署系统,整个过程相当于服务器宕机。因此网站 的可用性架构设计不但要考虑实际的硬件故障引起的宕机,还要考虑网站升级发布引起 的宕机,而后者更加频繁,不能因为系统可以接受偶尔的停机故障就降低可用性设计的标准。
1.3、高可用的应用
应用层主要处理网站应用的业务逻辑,因此有时也称作业务逻辑层,应用的一个显 著特点是应用的无状态性。
所谓无状态的应用是指应用服务器不保存业务的上下文信息,而仅根据每次请求提 交的数据进行相应的业务逻辑处理,多个服务实例(服务器)之间完全对等,请求提交
1.3.1、通过负载均衡进行无状态服务的失效转移
不保存状态的应用给高可用的架构设计带来了巨大便利,既然服务器不保存请求的 状态,那么所有的服务器完全对等,当任意一台或多台服务器宕机,请求提交给集群中 其他任意一台可用机器处理,这样对终端用户而言,请求总是能够成功的,整个系统依 然可用。对于应用服务器集群,实现这种服务器可用状态实时监测、自动转移失败任务 的机制是负载均衡。
负载均衡,顾名思义,主要使用在业务量和数据量较高的情况下,当单台服务器不 足以承担所有的负载压力时,通过负载均衡手段,将流量和数据分摊到一个集群组成的 多台服务器上,以提高整体的负载处理能力。目前,不管是幵源免费的负载均衡软件还 是昂贵的负载均衡硬件,都提供失效转移功能。在网站应用中,当集群中的服务是无状 态对等时,负载均衡可以起到事实上高可用的作用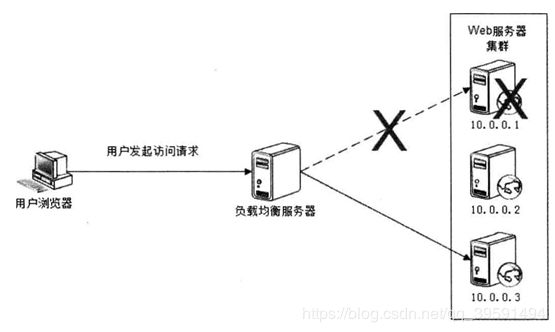
当Web服务器集群中的服务器都可用时,负载均衡服务器会把用户发送的访问请求 分发到任意一台服务器上进行处理,而当服务器10.0.0.1宕机时,负载均衡服务器通过心 跳检测机制发现该服务器失去响应,就会把它从服务器列表中删除,而将请求发送到其 他服务器上,这些服务器是完全一样的,请求在任何一台服务器中处理都不会影响最终 的结果。
由于负载均衡在应用层实际上起到了系统高可用的作用,因此即使某个应用访问量 非常少,只用一台服务器提供服务就绰绰有余,但如果需要保证该服务高可用,也必须 至少部署两台服务器,使用负载均衡技术构建一个小型的集群。
1.3.2、应用服务器集群的Session管理
应用服务器的高可用架构设计主要基于服务无状态这一特性,但是事实上,业务总 是有状态的,在交易类的电子商务网站,需要有购物车记录用户的购买信息,用户每次 购买请求都是向购物车中增加商品;在社交类的网站中,需要记录用户的当前登录状态、 最新发布的消息及好友状态等,用户每次刷新页面都需要更新这些信息。
Web应用中将这些多次请求修改使用的上下文对象称作会话(Session ),单机情况下, Session可由部署在服务器上的Web容器(如JBoss )管理。在使用负载均衡的集群环境 中,由于负载均衡服务器可能会将请求分发到集群任何一台应用服务器上,所以保证每次请求依然能够获得正确的Session比单机时要复杂很多。
集群环境下,Session管理主要有以下几种手段。
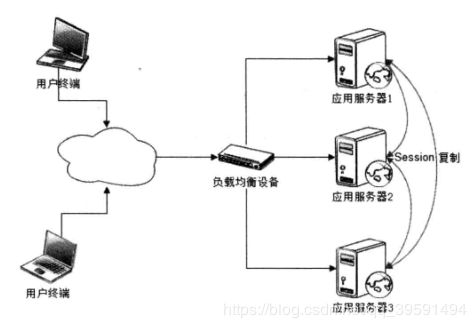
1、Session复制
Session复制是早期企业应用系统使用较多的一种服务器集群Session管理机制。应用 服务器开启Web容器的Session复制功能,在集群中的几台服务器之间同步Session对象, 使得每台服务器上都保存所有用户的Session信息,这样任何一台机器宕机都不会导致 Session数据的丢失,而服务器使用Session时,也只需要在本机获取即可。
这种方案虽然简单,从本机读取Session信息也很快速,但只能使用在集群规模比较 小的情况下。当集群规模较大时,集群服务器间需要大量的通信进行Session复制,占用 服务器和网络的大量资源,系统不堪负担。而且由于所有用户的Session信息在每台服务 器上都有备份,在大量用户访问的情况下,甚至会出现服务器内存不够Session使用的情况。
2、Session绑定
Session绑定可以利用负载均衡的源地址Hash算法实现,负载均衡服务器总是将来源 于同一 IP的请求分发到同一台服务器上(也可以根据Cookie信息将同一个用户的请求总 是分发到同一台服务器上,当然这时负载均衡服务器必须工作在HTTP协议层上这样在整个会话期间,用户所有的请 求都在同一台服务器上处理,即Session绑定在某台特定服务器上,保证Session总能在 这台服务器上获取。这种方法又被称作会话黏滞
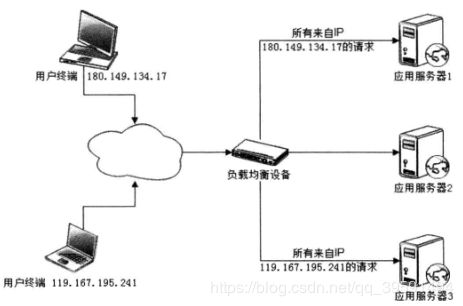
但是Session绑定的方案显然不符合我们对系统高可用的需求,因为一旦某台服务器 宕机,那么该机器上的Session也就不复存在了,用户请求切换到其他机器后因为没有 Session而无法完成业务处理。因此虽然大部分负载均衡服务器都提供源地址负载均衡算 法,但很少有网站利用这个算法进行Session管理。
3、利用Cookie记录Session
早期的企业应用系统使用C/S (客户端/服务器)架构,一种管理Session的方式是将 Session记录在客户端,每次请求服务器的时候,将Session放在请求中发送给服务器,服 务器处理完请求后再将修改过的Session响应给客户端。
网站没有客户端,但是可以利用浏览器支持的Cookie记录Session
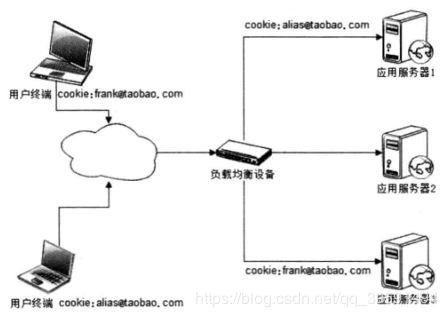
利用Cookie记录Session也有一些缺点,比如受Cookie大小限制,能记录的信息有 限;每次请求响应都需要传输Cookie,影响性能;如果用户关闭Cookie,访问就会不正 常。但是由于Cookie的简单易用,可用性高,支持应用服务器的线性伸缩,而大部分应 用需要记录的Session信息又比较小。因此事实上,许多网站都或多或少地使用Cookie 记录 Session
4、Session服务器
那么有没有可用性高、伸缩性好、性能也不错,对信息大小又没有限制的服务器集群Session管理方案呢?
答案就是Session服务器。利用独立部署的Session服务器(集群)统一管理Session, 应用服务器每次读写Session时,都访问Session服务器,如图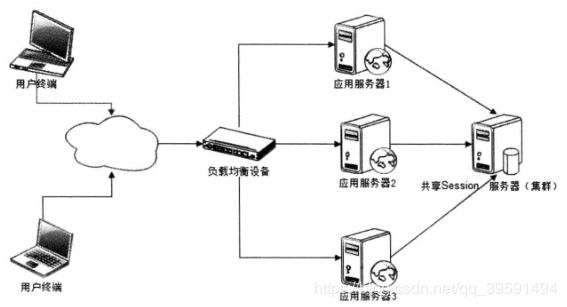
这种解决方案事实上是将应用服务器的状态分离,分为无状态的应用服务器和有状 态的Session服务器,然后针对这两种服务器的不同特性分别设计其架构。
对于有状态的Session服务器,一种比较简单的方法是利用分布式缓存、数据库等, 在这些产品的基础上进行包装,使其符合Session的存储和访问要求。如果业务场景对 Session管理有比较高的要求,比如利用Session服务集成单点登录(SSO )、用户服务等 功能,则需要开发专门的Session服务管理平台。
声明:以上内容来自:《大型网站技术架构:核心原理与案例分析书籍》
下一章:网站的高可用架构(下)