爬取拉勾网,并进行数据分析
拉勾网是现在互联网招聘比较火热的一个网站,本篇文章主要是爬取拉勾网“数据分析师”这个岗位,并且对所爬取到的信息,进行数据分析。
数据采集
拉勾网的岗位信息主要是用json文件存储,在position这个json文件中,我们找到了所需要的岗位信息
接着便开始写爬虫了:
# -*- coding: UTF-8 -*-
import json
import requests
headers = {
"Cookie": "user_trace_token=20171010163413-cb524ef6-ad95-11e7-85a7-525400f775ce; LGUID=20171010163413-cb52556e-ad95-11e7-85a7-525400f775ce; JSESSIONID=ABAAABAABEEAAJAA71D0768F83E77DA4F38A5772BDFF3E6; _gat=1; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=bzclk.baidu.com; PRE_SITE=http%3A%2F%2Fbzclk.baidu.com%2Fadrc.php%3Ft%3D06KL00c00f7Ghk60yUKm0FNkUsjkuPdu00000PW4pNb00000LCecjM.THL0oUhY1x60UWY4rj0knj03rNqbusK15yDLnWfkuWN-nj0sn103rHm0IHdDPbmzPjI7fHn3f1m3PDnsnH9anDFArH6LrHm3PHcYf6K95gTqFhdWpyfqn101n1csPHnsPausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4_myIEIi4WUvYE5LNYUNq1ULNzmvRqUNqWu-qWTZwxmh7GuZNxTAn0mLFW5HDLP1Rv%26tpl%3Dtpl_10085_15730_11224%26l%3D1500117464%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E3%252580%252591%2525E5%2525AE%252598%2525E7%2525BD%252591-%2525E4%2525B8%252593%2525E6%2525B3%2525A8%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E8%252581%25258C%2525E4%2525B8%25259A%2525E6%25259C%2525BA%2526xp%253Did%28%252522m6c247d9c%252522%29%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D220%26ie%3Dutf8%26f%3D8%26ch%3D2%26tn%3D98010089_dg%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26oq%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26rqlang%3Dcn%26oe%3Dutf8; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F%3Futm_source%3Dm_cf_cpt_baidu_pc; _putrc=347EB76F858577F7; login=true; unick=%E6%9D%8E%E5%87%AF%E6%97%8B; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=63; TG-TRACK-CODE=index_search; _gid=GA1.2.1110077189.1507624453; _ga=GA1.2.1827851052.1507624453; LGSID=20171011082529-afc7b124-ae1a-11e7-87db-525400f775ce; LGRID=20171011082545-b94d70d5-ae1a-11e7-87db-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507444213,1507624453,1507625209,1507681531; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507681548; SEARCH_ID=e420ce4ae5a7496ca8acf3e7a5490dfc; index_location_city=%E5%8C%97%E4%BA%AC",
"Host": "www.lagou.com",
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3408.400 QQBrowser/9.6.12028.400'}
post_data = {'first': 'false', 'kd':'数据分析师' }#这是请求网址的一些参数
def start_requests(pn):
html = requests.post(myurl + str(pn), data=post_data, headers=headers, verify=False)
html_text = html.text
content = json.loads(html_text) #loads()暂时可以理解为把json格式转为字典格式,而dumps()则是相反的
pagesize = content.get('content').get('pageSize') #这是Pytho字典中的get()用法
return pagesize
def get_result(pagesize):
for page in range(1, pagesize+1):
content_next = json.loads(requests.post(myurl + str(page), data=post_data, headers=headers, verify=False).text)
company_info = content_next.get('content').get('positionResult').get('result')
if company_info:
for p in company_info:
line = str(p['city']) + ',' + str(p['companyFullName']) + ',' + str(p['companyId']) + ',' + \
str(p['companyLabelList']) + ',' + str(p['companyShortName']) + ',' + str(p['companySize']) + ',' + \
str(p['businessZones']) + ',' + str(p['firstType']) + ',' + str(
p['secondType']) + ',' + \
str(p['education']) + ',' + str(p['industryField']) +',' + \
str(p['positionId']) +',' + str(p['positionAdvantage']) +',' + str(p['positionName']) +',' + \
str(p['positionLables']) +',' + str(p['salary']) +',' + str(p['workYear']) + '\n'
file.write(line)
if __name__ == '__main__':
title = 'city,companyFullName,companyId,companyLabelList,companyShortName,companySize,businessZones,firstType,secondType,education,industryField,positionId,positionAdvantage,positionName,positionLables,salary,workYear\n'
file = open('%s.txt' % '爬虫拉勾网', 'a') #创建爬虫拉勾网.txt文件
file.write(title) #把title部分写入文件作为表头
cityList = [u'北京', u'上海',u'深圳',u'广州',u'杭州',u'成都',u'南京',u'武汉',u'西安',u'厦门',u'长沙',u'苏州',u'天津',u'郑州'] #这里只选取了比较热门的城市,其他城市只几个公司提供职位
for city in cityList:
print('爬取%s' % city)
myurl = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false&pn='.format(
city)
pagesize=start_requests(1)
get_result(pagesize)
file.close()值得说明的是header()里面需要添加所有的header信息,不然拉勾网的反爬虫会让程序报错。

数据清洗
在上面的数据中,我们发现了一些缺失数据以及脏数据,因此,在数据分析之前,首先应该把数据进行清洗。
在数据清洗之前,我把刚刚的txt文件转换成CSV UTF-8格式,名字改成英文格式,以便于pycharm的读取。
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
df=pd.read_csv('C:\\Users\\Administrator\\Desktop\\DataAnalyst .csv')
print(df.head())#读取前五行
从上面的图中,我们能看出关于工资方面应该做出处理,这里只是一个工资的区间,下面我们把工资清理成平均值形式,并且以数据可视化显示出来:
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')
def cut_word(word,method):
position=word.find('-')
length=len(word)
if position !=-1:
bottomsalary=word[:position-1]
topsalary=word[position+1:length-1]
else:
bottomsalary=word[:word.upper().find('K')]
topsalary=bottomsalary
if method=="bottom":
return bottomsalary
else:
return topsalary
df_duplicates['topsalary']=df_duplicates.salary.apply(cut_word, method="top")
df_duplicates['bottomsalary']=df_duplicates.salary.apply(cut_word, method="bottom")
df_duplicates['topsalary']=df_duplicates.salary.apply(cut_word,method="top") # apply()函数形式:apply(func,*args,**kwargs),*args相当于元组,**kwargs相当于字典
df_duplicates["bottomsalary"]=df_duplicates.salary.apply(cut_word,method="bottom")#apply()函数作用:用来间接的调用一个函数,并把参数传递给函数
df_duplicates.bottomsalary.astype('int')# 字符串转为数值型
df_duplicates.topsalary.astype('int')
df_duplicates["avgsalary"]=df_duplicates.apply(lambda x:(int(x.bottomsalary)+int(x.topsalary))/2,axis=1) #lambda是一种函数,举例:lambda x:x+1,x是参数,x+1是表达式;axis=1表示作用于行
#选出我们想要的内容进行后续分析
df_clean=df_duplicates[['city','companyShortName','companySize','education','positionName','positionLables','workYear','avgsalary','industryField']]
import matplotlib.pyplot as plt
plt.style.use("ggplot") #使用R语言中的ggplot2配色作为绘图风格,为好看
from matplotlib.font_manager import FontProperties #matplotlib.Font_manager 是一种字体管理工具
zh_font = FontProperties(fname="C:\\WINDOWS\\Fonts\\simsun.ttc")#matplotlib.Font_manager.FontProperties(fname) 是指定一种字体,C:\\WINDOWS\\Fonts\\simsun.ttc 是字体路径,直接复制到电脑搜索,你看能不能找到
fig=plt.figure(figsize=(8,5)) #关于绘图方面,文末放了一个链接,讲述的比较详细
ax=plt.subplot(111)
rect=ax.hist(df_duplicates["avgsalary"],bins=30)
ax.set_title(u'薪酬分布',fontProperties=zh_font)
ax.set_xlabel(u'K/月',fontProperties=zh_font)
plt.show(plt.xticks(range(5,100,5)) ) #xticks为x轴主刻度和次刻度设置颜色、大小、方向,以及标签大小。
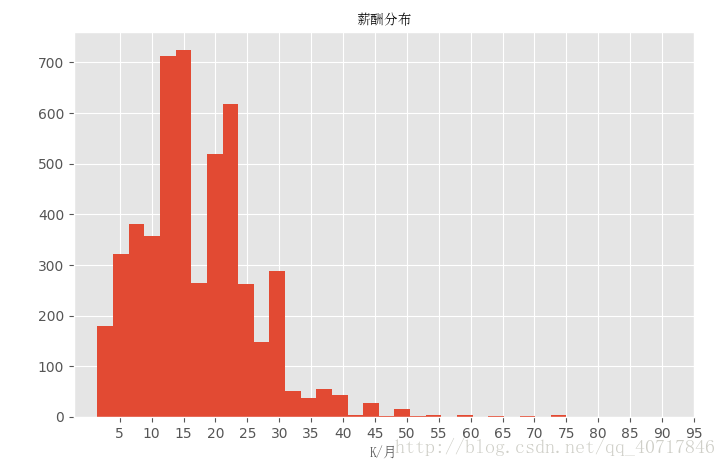
从上面的图可以看出数据是偏右分布,其中大多数据集中在10K~20K,也有极少数人获得高薪。
不同城市的薪酬分布情况:
ax=df_clean.boxplot(column='avgsalary',by='city',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)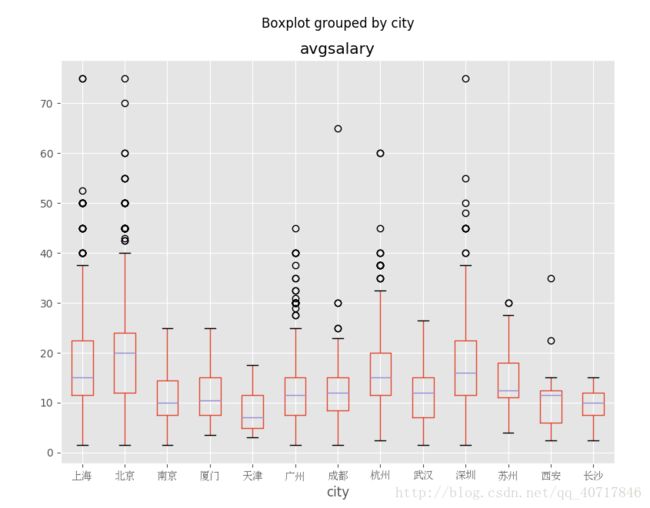
北京市薪酬分布中位数大约在20k,居全国首位。其次是上海、杭州、深圳,中位数大约为15k左右,而广州中位数只大约为12k。
不同学历的薪酬分布
ax=df_clean.boxplot(column='avgsalary',by='education',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)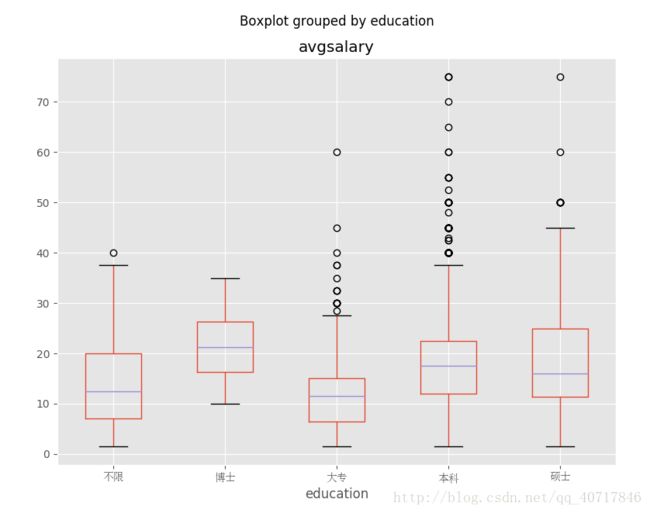
北京上海工作经验不同薪酬分布情况
df_bj_sh=df_clean[df_clean['city'].isin(['上海','北京'])]
ax=df_bj_sh.boxplot(column='avgsalary',by=['workYear','city'],figsize=(19,6))
for label_x in ax.get_xticklabels():
label_x.set_fontproperties(zh_font)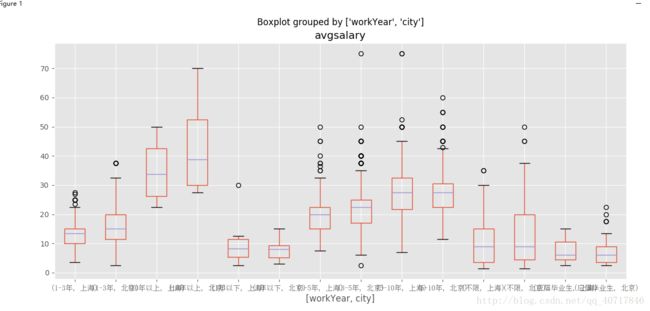
从图中我们能够得出,对于工作一年以下的,上海和北京两个地方薪资基本一致,但是有能力的人在北京能够得到较高的薪水。对于工作1-3年的人,北京工资的中位数都要比上海的上四分位数要大了。如果你的工作经验还不大充足,你想好去哪里发展了吗?
北上广深对数据分析职位需求量
def topN(df,n=5):
counts=df.value_counts() #value_counts()统计所有非零元素的个数
return counts.sort_values(ascending=False)[:n] #sort_values()对数据进行排序,ascending是设置升序和降序
df_bj_sh_gz_sz=df_clean[df_clean['city'].isin(['上海','北京','广州','深圳'])]
df_bj_sh_gz_sz.groupby('city').positionName.apply(topN)city
上海 数据分析师 79
大数据开发工程师 37
数据产品经理 31
大数据工程师 26
高级数据分析师 20
北京 数据分析师 238
数据产品经理 121
大数据开发工程师 69
分析师 49
数据分析 42
广州 数据分析师 31
需求分析师 23
大数据开发工程师 13
数据分析专员 10
数据分析 9
深圳 数据分析师 52
大数据开发工程师 32
数据产品经理 24
需求分析师 21
大数据架构师 11
Name: positionName, dtype: int64
我们现在可以看出,虽然想抓取的是数据师职位的情况,但得到的是和数据分析相关的职位,自己还是要在获取数据、数据清理方面多下功夫啊。
不管怎样我们还是能够得出来,观察北上广深的数据分析师职位数量,还是北京力压群雄啊。
公司所处行业领域词云图分析
import re #re模块提供了对正则表达式的支持
import jieba as jb
from wordcloud import WordCloud
word_str = ','.join(df_clean['industryField']) # 以','为分隔符,将所有的元素合并成一个新的字符串,注意:csv文件中,单元格之间有逗号。
#对文本进行分词
word_split = jb.cut(word_str) #精确模式
#使用|作为分隔符
word_split1 = "|".join(word_split)
pattern=re.compile("移动|互联网|其他|金融|企业|服务|电子商务|O2O|数据|服务|医疗健康|游戏|社交网络|招聘|生活服务|文化娱乐|旅游|广告营销|教育|硬件|信息安全")
#匹配所有文本字符;pattern 我们可以理解为一个匹配模式,用re.compile()方法来获得这个模式
word_w=pattern.findall(word_split1) #搜索word_split1,以列表形式返回全部能匹配的子串
word_s = str(word_w)
my_wordcloud = WordCloud(font_path="C:\\WINDOWS\\Fonts\\simsun.ttc",width=900,height=400,background_color="white").generate(word_s)
plt.imshow(my_wordcloud)
plt.axis("off") #取出坐标轴
plt.show()
如图所示:对于数据分析这一职位需求量大的主要是在互联网、移动互联网、金融、电子商务这些方面,所以找工作的话去这几个领域获得职位的几率估计是比较大的。我想这可能还有另一方面的原因:拉勾网本身主要关注的就是互联网领域,等自己技术成熟了,要爬虫获得一份包含所有行业的数据进行一次分析。
分析结论
从总体薪酬分布情况上,数据分析这一职业工资普遍较高的,大多人是在10k-25之间每月,但这只是拉勾网显示的工资,具体的就不太清楚了。
从不同城市薪资分布情况得出,在北京工作的数据分析师工资中位数在20k左右,全国之首。其次是上海、杭州、深圳,如果要发展的话,还是北、上、深、杭比较好啊。
从不同学历薪资情况得出,学历越高发展所获得工资是越高,其中专科生略有劣势,我想的是数据分析应该对数学有一定要求,毕竟大学是学了数理统计、高等数学还线性代数的。
根据北京上海工作经验不同薪酬分布情况,得出如果有些工作经验去北京比上海获得的工资要高一些。
分析北上广深的数据分析师职位需求数量,北京以238个获得最高。
根据公司所处行业领域词云图分析,对于数据分析师需求量大的行业主要是互联网、电子商务、金融等领域。