(4、Selenium抓取电商网站数据)Python爬虫与数据清洗的进化
1、使用Selenium模块爬取去哪儿网度假信息,此文笔者主要使用XPATH进行节点元素定位。
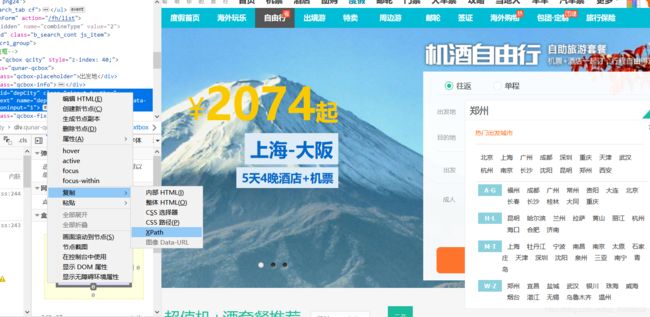
2、首先selenium使用需要安装对应浏览器的驱动,并将驱动放入浏览器根目录,并将驱动路径加入系统环境变量。ok开始吧!
以下是笔者写的例子,后面具体会讲解每个部分的作用和容易出现的坑。
import requests,urllib.request,time,random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_url(url):
time.sleep(2)
return(requests.get(url))
if __name__=='__main__':
driver=webdriver.Firefox()
url = 'https://m.dujia.qunar.com/depCities.qunar'
strhtml = get_url(url)
dep_dict = strhtml.json()
a=[]
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a.append(dep)
for dep_1 in a[1:]:
strhtml = get_url(
'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(
urllib.request.quote(dep_1)))
arrive_dict = strhtml.json()
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
driver.get('https://fh.dujia.qunar.com/?tf=package')
WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, "depCity")))
driver.find_element_by_xpath('//*[@id="depCity"]').clear()
driver.find_element_by_xpath('//*[@id="depCity"]').send_keys(dep_1)
driver.find_element_by_xpath('//*[@id="arrCity"]').send_keys(query['query'])
driver.find_element_by_xpath('/html/body/div[2]/div[1]/div[2]/div[3]/div/div[2]/div/a').click()
print('dep:%s arr:%s' % (dep_1, query['query']))
for i in range(100):
time.sleep(random.uniform(5, 6))
wrong = driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[6]/div[2]/div')
if wrong == []:
break
routes = driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[6]/div[2]/div')
for route in routes:
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep_1,
'arrive': query['query'],
'result': route.text
}
print(result)
if i < 1:
btns = driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[7]/div/div/a')
for a in btns:
if a.text == u"下一页":
a.click()
break
else:
break
driver.close()
exit()0x01:使用selenium的webdriver库,初始化一个火狐浏览器对象。弹出一个火狐浏览器窗口。
from selenium import webdriver
driver=webdriver.Firefox()0x02:使用get方法打开网页
driver.get('https://fh.dujia.qunar.com/?tf=package')0x03:实现等待需要用到下面三个库:By库用于指定HTML文件中DOM标签元素;WebDriverWait库用于等待网页加载完成;expected_conditions库(下面用as EC作为这个库的简称)用于指定网页加载结束的条件。这里的输入框是异步加载的,需要一定时间,所以需要写一条等待语句。此处等待id="depCity"的出现。
WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, "depCity")))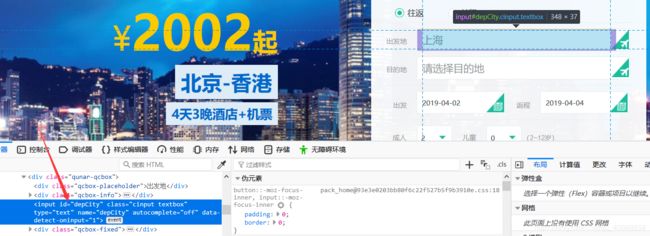
0x04:接下来如果搜索不出产品怎么办呢,此处使用以下代码,如果内容块没有信息,则break到下一地址。
wrong = driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[6]/div[2]/div')
if wrong == []:
break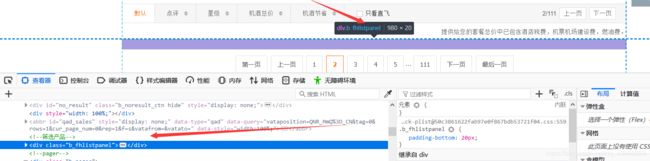
0x05:这一部分作用是设置页码,因为i属于(0,100),所以此处只翻一次页。然后break到下一地址。
if i < 1:
btns = driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[7]/div/div/a')
for a in btns:
if a.text == u"下一页":
a.click()
break主要注意的是 driver.find_elements_by_xpath是查找可迭代的dom节点,driver.find_element_by_xpath查找不可迭代的dom节点。中文字符串前面加u是规定使用utf-8编码,避免出错。以及学习一下break的用法。