【干货】用mmdetection,在COCO数据集上跑通faster R-CNN(测试、训练)
注:刚接触R-CNN、Fast R-CNN、Faster R-CNN,就尝试用mmdetection,在coco数据集上跑Faster R-CNN,训练测试完就来记录一下这个过程的一些坑
参考
- mmdetection github网址
- 跑通mmdetection
- 安装Anaconda3遇到的几个问题
关于跑通mmdetection,建议主要看第一个网址,第二个网址参考为主,因为我按原博的步骤,跑了两次都没跑出来(可能是我太菜了)
2020.06.03更新:
- 【干货】:配置环境anaconda3并安装最新版mmdetection
这是我最近使用新版的mmdetection的时候,又重新记录了安装的过程。安装mmdetection具体可以参考该博客,但是下面的记录也是有些值得借鉴的意义的,可以互相借鉴学习。
安装教程
本人系统环境:
- Ubuntu 16.04
- Cuda 9.0 + Cudnn 7.0.5
- Python 3.7 (mmdetection要求Python版本需要3.4+)
- Anaconda 3
几个依赖库的安装:
- PyTorch 1.1(很多地方都是1.0+版本,但博主跑1.0.1的时候,不行???)
- mmcv
- cython
Anaconda3安装、环境配置
这个安装过程其实没有什么讲的,就是一直回车回车(还有yes/no的时候,多看两眼)。
但是博主在安装后,出现了几个小问题,可以参考下面两篇博客
- 安装Anaconda3遇到的几个问题
- Linux设置anaconda3的环境变量
注:因为在实验室服务器跑,时常清理,比较懒,就没有创建虚拟环境了。自行csdn一下。
安装pytorch
强烈建议去官网看具体的命令,根据自己的各个版本选择相应的命令。
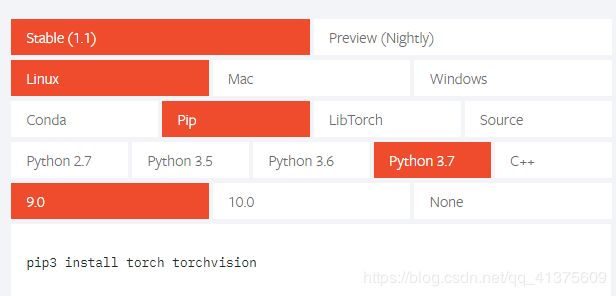
博主在这安装这一步时,一直出错,在github网址上的pytorch要求的版本时1.0+。但是我在安装1.0.1的版本后,训练的时候出现了下面的问题

然后又自己试了下这个属性有没有,果真:

AttributeError: module 'torch.nn' has no attribute 'SyncBatchNorm'
torch1.0.1的版本没有SyncBatchNorm。博主找了各种解决办法,也没找到(网上关于这一块的问题解决好像没有)。又去升级了版本。然后也不行(不知道是不是我自己升级的问题)
最后就卸载重装了。
卸载的话,可能会遇到说,没有安装这个库,但是你明明有这个库啊?
pip uninstall pytorch
解决办法:
你用conda安装,就要有conda卸载
用pip安装,就用pip卸载(这我之前还真不知道,记录一下)
然后安装:
pip install torch torchvision #自己参考官网给的命令
到这,pytorch就好了!
注:参考网址说1.0.1的版本能跑通,我觉得蛮奇怪的,如果有哪位大佬知道是什么原因的话,还望告知,感激不尽
安装cython
conda install cython
安装mmcv
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
pip install . #注意有一个点(.)
安装mmdetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
./compile.sh
python setup.py develop # or "pip install -e ."
在跑下面命令的时候,会出现的问题
./compile.sh
博主出现了下面的问题,但只是警告而已
DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=roi_align_cuda -D_GLIBCXX_USE_CXX11_ABI=0 -std=c++11
cc1plus: warning: command line option ‘-Wstrict-prototypes’ is valid for C/ObjC but not for C++
packages/torch/include/ATen/cuda/NumericLimits.cuh(83): warning: calling a constexpr host function("from_bits") from a host device function("lowest") is not allowed. The experimental flag '--expt-relaxed-constexpr' can be used to allow this.
如果你的是error的话,可以直接 mmdetection 的GitHub网址里的 issue 去找答案,我看过了,蛮多的,其中一个可能的解决方案是gcc的版本问题,可以自己去找找。
测试demo
测试命令:
# single-gpu testing
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
# multi-gpu testing
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
CONFIG_FILE:配置文件的地址,在mmdetection/configs/下,比如我用的配置文件路径就是:configs/faster_rcnn_r50_fpn_1x.py
python tools/test.py configs/faster_rcnn_r50_fpn_1x.py ${CHECKPOINT_FILE}
CHECKPOINT_FILE:检查点模型的路径,没有的话,看文章开头的第二篇文章,里面有百度云链接。
后面几个参数,可选
- RESULT_FILE: Filename of the output results in pickle format. If not
specified, the results will not be saved to a file. - EVAL_METRICS: Items to be evaluated on the results. Allowed values
are: proposal_fast, proposal, bbox, segm, keypoints. - –show: If specified, detection results will be ploted on the images and shown in a new window. (Only applicable for single GPU testing.)
本来在网上找了几个测试代码,都会报以下的错误,这些文章下好多评论报的也是这个错误(具体的错误代码可以看这篇博客里的):

也就是说 inference_detector()函数只有两个形参,却给了三个,找了好多解决办法都不行,就放弃了。
但下面代码博主亲测有用。
from mmdet.apis import init_detector, inference_detector, show_result
config_file = 'faster_rcnn_r50_fpn_1x.py' #根据自己的路径写
checkpoint_file = 'faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth' #根据自己的路径写
# build the model from a config file and a checkpoint file
model = init_detector(config_file, checkpoint_file, device='cuda:0')
# test a single image and show the results
img = 'test.jpg' # or img = mmcv.imread(img), which will only load it once
result = inference_detector(model, img)
show_result(img, result, model.CLASSES)
# test a list of images and write the results to image files
imgs = ['test1.jpg', 'test2.jpg']
for i, result in enumerate(inference_detector(model, imgs)):
show_result(imgs[i], result, model.CLASSES, out_file='result_{}.jpg'.format(i))
输出图片显示:

可能图片原因,所以细看图片会发现,好多识别有问题(笑哭)
COCO数据集的准备
官方推荐coco数据集按照以下的目录形式存储,以coco2017数据集为例
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
推荐以软连接的方式创建data文件夹,下面是创建软连接的步骤
cd mmdetection
mkdir data
ln -s $COCO_ROOT data
其中,$COCO_ROOT需改为你的coco数据集根目录
训练Faster R-CNN
不想采用分布式的训练方式,或者你只有一块显卡,则运行下方的代码
python tools/train.py ${CONFIG_FILE}
官方推荐使用分布式的训练方式,这样速度更快,如果是coco训练集,修改CONFIG_FILE中的pretrained参数,改为你的模型路径,然后运行下方代码
./tools/dist_train.sh <CONFIG_FILE> <GPU_NUM> [optional arguments]
训练截图:
下面这张截图,是博主第一次训练,然后loss居然无穷大,一下子给懵了,代码数据什么的都是mmdetection 的GitHub上的,按理说应该没错吧???
无穷大后,本着试一试的想法,停止训练,又重新跑了一下,就没有无穷大了???
博主刚开始这一块的学习,经验尚浅,后面会针对这一问题,好好研究一下具体的原因。如果有哪位大佬也遇到这种情况,且解决了的,还望能够指教一下,互相学习。

到此成功完成faster R-CNN在coco数据集上的训练和测试啦。
注:博主也是刚开始学习这一块领域的内容,如有表述不对的地方,还望指出,共同进步。