python数据分析与挖掘实战第六章拓展思考题
拓展思考题是汽车是否偷漏税识别问题。文中代码有借鉴网友和书中代码。查看数据后进行以下分析
1、数据探索
对数据进行简单分析,看销售模式和销售类别对偷漏税是否有影响
import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False df=pd.read_excel('E:/WTTfiles/自我学习/机器学习/python数据分析与挖掘实战/chapter6/拓展思考/拓展思考样本数据.xls') fig=plt.figure() fig.set(alpha=0.2) plt.subplot2grid((1,2),(0,0)) df_type=df[u'销售类型'][df[u'输出']=='异常'].value_counts() df_type.plot(kind='bar',color='blue') plt.title(u'不同销售类型下的偷漏税情况') plt.xlabel(u'销售类型') plt.ylabel(u'异常数') plt.subplot2grid((1,2),(0,1)) df_model=df[u'销售模式'][df[u'输出']=='异常'].value_counts() df_model.plot(kind='bar',color='green') plt.title(u'不同销售模式下的偷漏税情况') plt.xlabel(u'销售类型') plt.ylabel(u'异常数') plt.subplots_adjust(wspace=0.3) plt.show()

可以看到国产轿车的异常数较多,4s店销售模式下的异常数也较多。
下面对数据进行统计分析,看正常和异常情况下数据的分布情况
df_normal=df.iloc[:,3:][df[u'输出']=='正常'].describe().T df_normal=df_normal[['count','mean','max','min','std']] print(df_normal) df_abnormal=df.iloc[:,3:][df[u'输出']=='异常'].describe().T df_abnormal=df_abnormal[['count','mean','max','min','std']] print(df_abnormal)count mean max min std
汽车销售平均毛利 71.0 0.038646 0.1774 -0.0047 0.029867
维修毛利 71.0 0.304539 1.0000 0.0000 0.195691
企业维修收入占销售收入比重 71.0 0.087654 1.0000 0.0000 0.125578
增值税税负 71.0 0.008455 0.0684 0.0000 0.011799
存货周转率 71.0 10.380742 31.4656 0.0000 7.156308
成本费用利润率 71.0 0.177197 6.9651 -0.3159 0.860881
整体理论税负 71.0 0.011794 0.0680 -0.0143 0.011766
整体税负控制数 71.0 0.011379 0.0570 0.0000 0.009103
办牌率 71.0 0.153535 0.7890 0.0000 0.228608
单台办牌手续费收入 71.0 0.016218 0.1300 0.0000 0.026999
代办保险率 71.0 0.240732 1.5297 0.0000 0.404804
保费返还率 71.0 0.054280 0.2700 -0.0148 0.073982
count mean max min std
汽车销售平均毛利 53.0 0.003698 0.1663 -1.0646 0.153516
维修毛利 53.0 -0.045575 0.6924 -3.1255 0.532060
企业维修收入占销售收入比重 53.0 0.043349 1.0000 0.0000 0.192004
增值税税负 53.0 0.008062 0.0770 0.0000 0.015379
存货周转率 53.0 11.915060 96.7461 0.0000 18.124865
成本费用利润率 53.0 0.171679 9.8272 -1.0000 1.406692
整体理论税负 53.0 0.008613 0.1593 -0.1810 0.048427
整体税负控制数 53.0 0.001043 0.0147 -0.0070 0.003816
办牌率 53.0 0.136085 0.8775 0.0000 0.247557
单台办牌手续费收入 53.0 0.016613 0.2000 0.0000 0.038970
代办保险率 53.0 0.075189 0.6324 0.0000 0.175527
保费返还率 53.0 0.018917 0.1687 0.0000 0.046666
2、在进行模型训练前,对数据中的属性值进行虚拟化处理。
type_dummies=pd.get_dummies(df[u'销售类型'],prefix='type') model_dummies=pd.get_dummies(df[u'销售模式'],prefix='model') result_dummies=pd.get_dummies(df[u'输出'],prefix='result') df=pd.concat([df,type_dummies,model_dummies,result_dummies],axis=1) df.drop([u'销售类型',u'销售模式',u'输出'],axis=1,inplace=True) #正常列去除,异常列作为结果 df.drop([u'result_正常'],axis=1,inplace=True) df.rename(columns={u'result_异常':'result'},inplace=True)
3、数据划分,20%作为测试集,80%作为训练集
# 数据划分 from random import shuffle data=df.as_matrix()#将表格转换为矩阵 shuffle(data)#随机打乱数据 p=0.8 train=data[:int(len(data)*p),:] test=data[int(len(data)*p):,:]
4、进行模型的训练和结果对比
我们选择3种不同的模型进行训练
(1)决策树,使用CART方法
from sklearn.tree import DecisionTreeClassifier treefile='E:/WTTfiles/自我学习/机器学习/python数据分析与挖掘实战/chapter6/拓展思考/tree.pkl' tree=DecisionTreeClassifier()#构建决策树模型 tree.fit(train[:,1:-1],train[:,-1])#训练 #保存模型 from sklearn.externals import joblib joblib.dump(tree,treefile) from cm_plot import * cm_plot(train[:,-1],tree.predict(train[:,1:-1])).show()#显示混淆矩阵可视化结果 cm_plot(test[:,-1],tree.predict(test[:,1:-1])).show() from sklearn.metrics import roc_curve fpr,tpr,thresholds=roc_curve(test[:,-1],tree.predict_proba(test[:,1:-1])[:,-1],pos_label=1) plt.plot(fpr,tpr,linewidth=2,label='ROC of CART') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.ylim(0,1.05) plt.xlim(0,1.05) plt.legend(loc=4) plt.show()
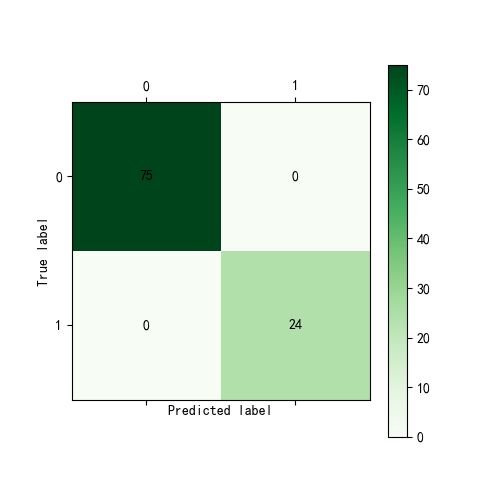
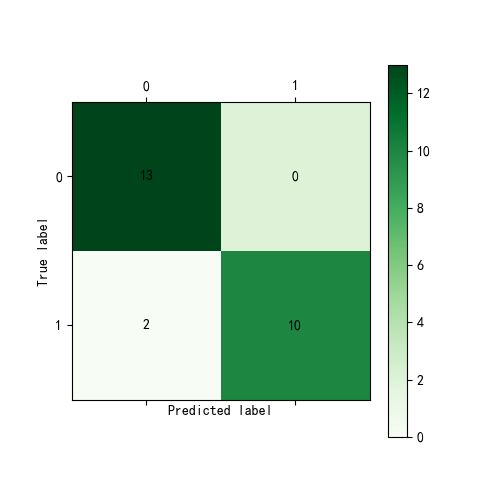
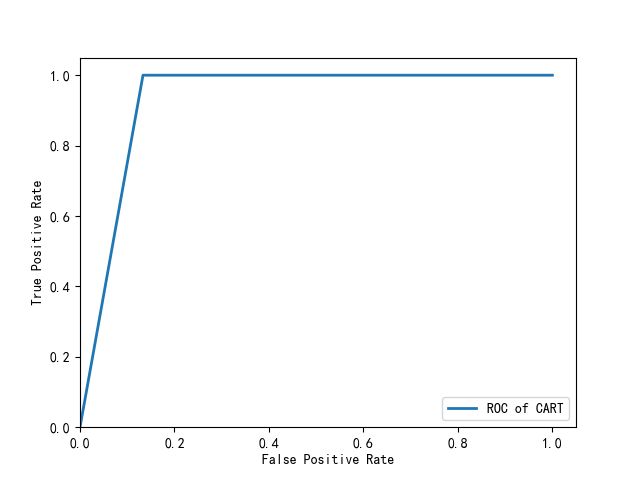
从混淆矩阵可以计算出,训练时模型达到100%的正确率,测试时模型正确率=23/25=92%。但是由于数据较少,每次训练结果都会有所差别。
(2)Logistic回归模型
前面分析部分内容一样,主要放上模型训练代码以及结果图
# logistic回归 from sklearn import linear_model from cm_plot import * clf=linear_model.LogisticRegression(C=1.0,penalty='l1',tol=1e-6) clf.fit(train[:,1:-1],train[:,-1]) xishu=pd.DataFrame({"columns":list(df.columns)[1:-1],"coef":list(clf.coef_.T)}) print(xishu) cm_plot(train[:,-1],clf.predict(train[:,1:-1])).show() predictions=clf.predict(test[:,1:-1]) cm_plot(test[:,-1],predictions).show() from sklearn.metrics import roc_curve predict_result=clf.predict(test[:,1:-1]).reshape(len(test)) fpr,tpr,thresholds=roc_curve(test[:,-1],predict_result,pos_label=1) plt.plot(fpr,tpr,linewidth=2,label='ROC of LR') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.ylim(0,1.05) plt.xlim(0,1.05) plt.legend(loc=4) plt.show()



训练集正确率=(29+66)/99=95.95%,测试集正确率=(14+7)/25=84%
(3)LM神经网络模型
# 神经网络 from keras.models import Sequential from keras.layers.core import Dense,Activation netfile='E:/WTTfiles/自我学习/机器学习/python数据分析与挖掘实战/chapter6/拓展思考/net.model' net=Sequential() net.add(Dense(input_dim=14,units=10)) net.add(Activation('relu')) net.add(Dense(input_dim=10,units=1)) net.add(Activation('sigmoid')) net.compile(loss='binary_crossentropy',optimizer='adam') net.fit(train[:,:14],train[:,14],nb_epoch=1000,batch_size=1) net.save_weights(netfile) predict_result=net.predict_classes(train[:,:14]).reshape(len(train)) from cm_plot import* cm_plot(train[:,14],predict_result).show() from sklearn.metrics import roc_curve predict_result=net.predict(test[:,:14]).reshape(len(test)) fpr,tpr,thresholds=roc_curve(test[:,14],predict_result,pos_label=1) plt.plot(fpr,tpr,linewidth=2,label='ROC of LM') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.ylim(0,1.05) plt.xlim(0,1.05) plt.legend(loc=4) plt.show()
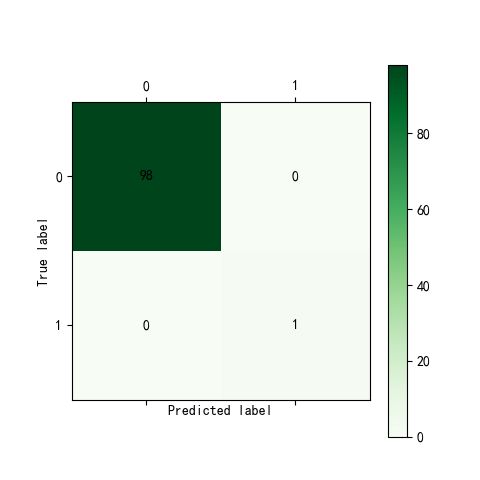

经过模型的训练和测试,可以看出LM神经网络模型的效果不如logistic和决策树的效果,不过鉴于数据集较小,每次跑的情况都不一样,因此结果也不是唯一的,有时候LM的效果更好一些。