【机器学习】基于SVM人脸识别算法的一些对比探究(先降维好还是先标准化好等对比分析)
一、数据集介绍
可选取 ORL 人脸数据库作为实验样本,总共 40 个人,每人 10 幅图像,图像大小为
112*92 像素。图像本身已经经过处理,不需要进行归一化和校准等工作。实验样本分为训练样本和测试样本。首先设置训练样本集,选择 40 个人前 5 张图片作为训练样本,进行训练。然后设置测试样本集,将 40 个人后 5 张图片作为测试样本,进行选取识别。
二、对比探究实验
(一)对比不同核函数对训练结果准确性的差异
1、sklearn.svm.SVC中kernel参数说明
常用核函数
线性核函数kernel=‘linear’
多项式核函数kernel=‘poly’
径向基核函数kernel=‘rbf’
sigmod核函数kernel=‘sigmod’
#建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
2、代码放在了最后面
3、对比运行结果
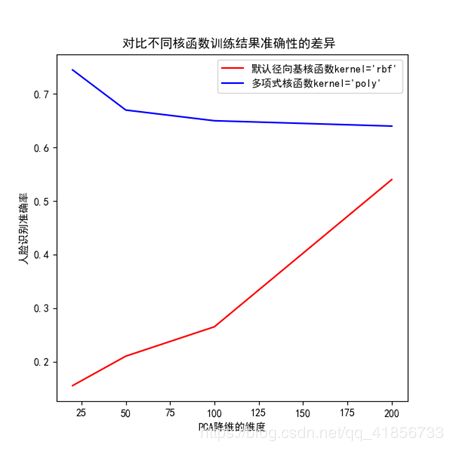
①降维维度为dimension=[20,50,100,200]时
径向基函数:
[0.155, 0.21, 0.265, 0.54]
多项式核函数
[0.745, 0.67, 0.65, 0.64]
①降维维度为 (200以内所有5的倍数)
for i in range(1,40):
dimension.append(i*5)
径向基函数:
[0.175, 0.16, 0.17, 0.145, 0.155, 0.16, 0.17, 0.185, 0.2, 0.205, 0.195, 0.21, 0.21, 0.23, 0.235, 0.24, 0.235, 0.25, 0.265, 0.265, 0.285, 0.29, 0.285, 0.315, 0.325, 0.34, 0.35, 0.365, 0.37, 0.375, 0.39, 0.405, 0.415, 0.425, 0.435, 0.46, 0.49, 0.51, 0.535]
多项式核函数
[0.68, 0.765, 0.775, 0.755, 0.735, 0.745, 0.72, 0.715, 0.69, 0.68, 0.66, 0.67, 0.665, 0.665, 0.645, 0.645, 0.645, 0.65, 0.65, 0.65, 0.65, 0.65, 0.645, 0.65, 0.645, 0.645, 0.645, 0.645, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64, 0.64]

4、小结:
可见,径向基函数大体呈现随着所降维度的增加而准确率不断上升的趋势;而多项式核函数大约在降维为20左右达到准确率的高峰,之后随着所降维度的增加,而准确率对应下降,最后趋于平缓
顺便一提,默认为径向基核函数kernel=‘rbf’ 可以降维到2维;多项式核函数kernel='poly’降维到2维,运行很长时间也没出结果
(二)关于先标准化还是先降维的探究
1、代码在最后
2、实验结果
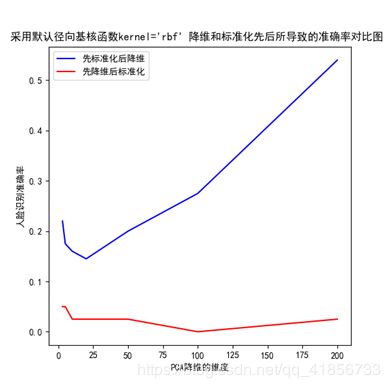
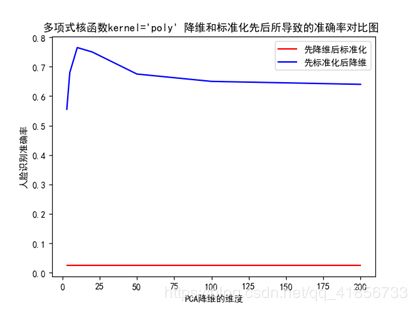
3、结论
由此可知,确实是先标准化再降维效果更好!
一定程度上的理论参考链接
如果数据其中某一特征(矩阵的某一列)的数值特别大,那么它在整个误差计算的比重上就很大,那么可以想象在投影到低维空间之后,为了使低秩分解逼近原数据,整个投影会去努力逼近最大的那一个特征,而忽略数值比较小的特征。因为在建模前我们并不知道每个特征的重要性,这很可能导致了大量的信息缺失。
当我们使用梯度下降等算法进行PCA的时候,我们最好先要对数据进行标准化,这是有利于梯度下降法的收敛。
(三)对比标准化测试数据集,标准化模型是采用训练集训练的还是测试集训练的差异
1、起因
常见的标准化语句如下:
#数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
这时,就可能让人产生一个疑惑:为什么标准化测试集时,要采用标准化训练集的时候所训练出的标准化模型?
2、实验代码在后面第三部分
3、对比结果

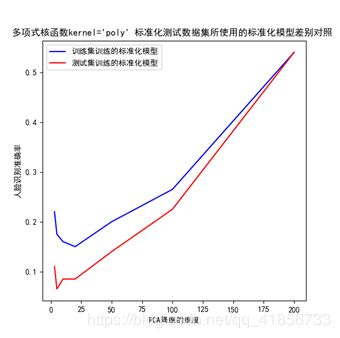
4、结论
可见,采用标准化训练集的时候所训练出的标准化模型,来标准化测试集数据效果更好一点!这里的原因可能涉及:svm模型训练的时候是采用训练集训练的,预测测试集结果是采用训练集训练出来的模型实现的。当然,具体原因还有待证实和研究。
三、一堆代码
(内容没整理,但对应基本功能可实现!)
1、对比不同核函数对训练结果准确性的差异
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def draw_chart(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('对比不同核函数训练结果准确性的差异 ')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
#plt.show()
def draw_chart1(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
#plt.figure(figsize=(10,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('多项式核函数kernel=\'poly\' 降维和标准化先后所导致的准确率对比图 ')
#plt.savefig("./tmp/多项式核函数kernel=\'poly\' 先降维后标准化.png")
#plt.show()
def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
dimension=[3,5,10,20,50,100,200]
#dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC().fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
draw_chart(dimension,accuracy)
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
dimension=[3,5,10,20,50,100,200]
#dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
#svm = SVC().fit(face_trainPca,face_target_train)
svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
plt.plot(dimension,accuracy,"b-")
plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])
#draw_chart1(dimension,accuracy)
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型
face_fuc(face_data_train,face_target_train,face_data_test,face_target_test)
face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)
2、关于先标准化还是先降维的探究
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def draw_chart(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"b-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('采用默认径向基核函数kernel=\'rbf\' 降维和标准化先后所导致的准确率对比图 ')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
#plt.show()
def draw_chart1(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
#plt.figure(figsize=(10,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
#plt.title('多项式核函数kernel=\'poly\' 先降维后标准化 ')
#plt.savefig("./tmp/多项式核函数kernel=\'poly\' 先降维后标准化.png")
plt.show()
#先标准化,后降维
def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
dimension=[3,5,10,20,50,100,200]
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC().fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
draw_chart(dimension,accuracy)
#先降维,后标准化
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
dimension=[3,5,10,20,50,100,200]
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_data_train)
face_trainPca = pca.transform(face_data_train)
face_testPca = pca.transform(face_target_test)
#2、标准化
stdScaler = StandardScaler().fit(face_trainPca)
face_trainStd = stdScaler.transform(face_trainPca)
face_testStd = stdScaler.transform(face_testPca)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC().fit(face_trainStd,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainStd,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testStd)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
plt.plot(dimension,accuracy,"r-")
plt.legend(['先标准化后降维','先降维后标准化'])
#draw_chart1(dimension,accuracy)
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型
face_fuc(face_data_train,face_target_train,face_data_test,face_target_test)
face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)
3、对比标准化测试数据集,标准化模型是采用训练集训练的还是测试集训练的差异
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def draw_chart(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"b-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('核函数kernel=\'rbf\' 标准化测试数据集所使用的标准化模型差别对照 ')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
#plt.show()
def draw_chart1(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"b-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('多项式核函数kernel=\'poly\' 标准化测试数据集所使用的标准化模型差别对照 ')
#plt.savefig("./tmp/多项式核函数kernel=\'poly\' 先降维后标准化.png")
plt.show()
#测试集标准化采用训练集训练的标准化模型
def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
dimension=[3,5,10,20,50,100,200]
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC().fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
draw_chart1(dimension,accuracy)
#测试集标准化采用测试集训练的标准化模型
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
stdScaler1 = StandardScaler().fit(face_data_test)
face_testStd = stdScaler1.transform(face_data_test)
dimension=[3,5,10,20,50,100,200]
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC().fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
#draw_chart1(dimension,accuracy)
plt.plot(dimension,accuracy,"r-")
plt.legend(['训练集训练的标准化模型','测试集训练的标准化模型'])
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型
face_fuc(face_data_train,face_target_train,face_data_test,face_target_test)
face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)