NLP:win10+pycharm+tensorflow-gpu+bert吐血整理
从几天前说起,开始学习使用bert,首先这里有两种,一种是google开源的原版的bert,一种是pytorch版的,这里主要介绍原版的bert,原版的提供了更大的控制性,如果想省事可以直接用第二种。
一,python要求
这里需要注意的是tensorflow-gpu目前只支持2.7,3.3-3.6,如果你的python版本不对,自行重装(或者使用下面的虚拟环境)。
二,安装Anaconda3+tensorflow-gpu
安装这东西,自行随意,我安装是为了更快的安装tensorflow-gpu。 pip install的话是从外网安装,速度慢不说,更容易挂掉,所以用这个,安装过程自行百度。
一,创建一个自定义环境python版本(版本限制如上)
打开Anaconda Prompt,位置在开始的Anaconda文件夹下。
conda create -n learn python=3.6
learn:环境名字,自定义
python=3.6:python版本号二,安装tensorflow-gpu
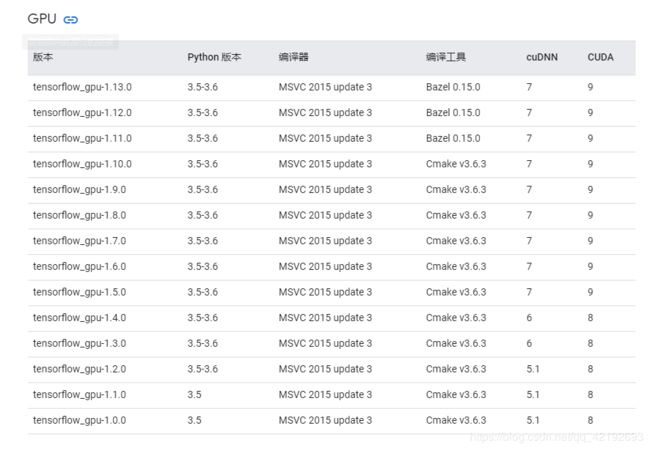
这里还要提醒,最新版的bert需要tensorflow-gpu>1.10.0,否则会报如下错误
AttributeError: module 'tensorflow.contrib.tpu' has no attribute 'InputPipelineConfig'这里不能直接pip,因为会直接装最新的,参考:https://www.tensorflow.org/install/source_windows,翻不了墙的参考:
====接上面创建完环境===
activate learn 激活环境
pip install tensorflow-gpu==1.10.0 安装安装好还不能直接用,需要安装cuDNN,CUDA
三,安装cuDNN+CUDA
两个的版本参考上面,这里用的是CUDA9+cuDNN7
一,安装CUDA9
地址:https://developer.nvidia.com/cuda-toolkit-archive
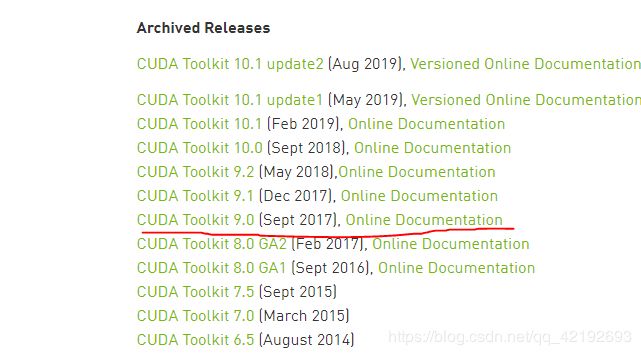
之后选择local,其实没大区别一个在线安装,一个离线安装。
安装过程中默认就不说了,如果选择了自定义,三个文件切记不要放一个文件夹中!!!一定要区别出来!!!

 这个是我自定义的文件夹。
这个是我自定义的文件夹。
二,安装cuDNN7
地址:https://developer.nvidia.com/cudnn,这个需要登录,不过可以用微信,用QQ需要验证邮箱,但是你就是收不到邮件。
一定要注意版本!!!,然后选择window10,就可以了。
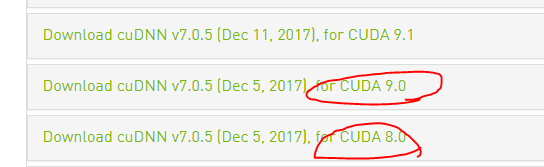
下载完是个压缩包这里的9不是cudnn版本,而是cuda的版本,后面的v7才是,里面是:
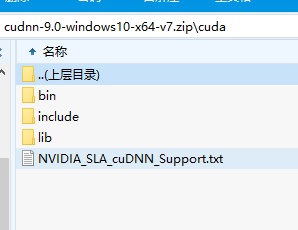
前方高能!!!
这里的三个文件先不动,之前安装CUDA的三个文件夹如果默认是在
![]()
如果自定义就是:这里的文件夹名字我自定义的,自定义一定要区别,Sample,Documentation和最后一个,为了区别。
把压缩包的cuDNN的三个文件夹下(每个文件夹下各一个)放到Toolkit里面的对应的三个文件夹下,切记不是Sample和Documentation,这里是把压缩包的文件,不是文件夹,拷贝到对应目录下。
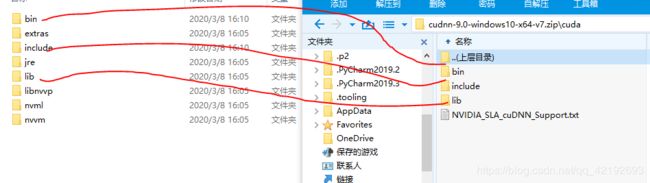
三,定义环境变量
将下面环境变量变为一行添加到path里面。
E:\GPU\NVIDIA GPU Computing Toolkit\bin\cudart64_90.dll;
E:\GPU\NVIDIA GPU Computing Toolkit\lib\x64;
E:\GPU\NVIDIA GPU Computing Toolkit\include;
E:\GPU\NVIDIA GPU Computing Toolkit\extras\CUPTI\libx64;
E:\GPU\NVIDIA Corporation Samples\bin\win64;
E:\GPU\NVIDIA Corporation Samples\common\lib\x64;
E:\GPU\NVIDIA GPU Computing Toolkit\bin;
E:\GPU\NVIDIA GPU Computing Toolkit\libnvvp;这时候你会发现还是运行不了tensorflow-gpu,这时候你保存一切,重启电脑,就可以用了。需要NAVIDA重新识别。
四,坑!
一,运行bert你会发现:INFO:tensorflow:Running train on CPU,卧槽,神奇吧,其实没关系的,它意思只是不是在TPU上,而是包括CPU和GPU,你之后会发现:
name: GeForce GTX 960M major: 5 minor: 0 memoryClockRate(GHz): 1.176
pciBusID: 0000:01:00.0
totalMemory: 4.00GiB freeMemory: 3.35GiB这不就跑到GPU上了吗,这点让我重装了好多。
二,如果出现:No registered '_CopyFromGpuToHost' OpKernel for CPU devices compatible with node
tensorflow.python.framework.errors_impl.NotFoundError: No registered '_CopyFromGpuToHost' OpKernel for CPU devices compatible with node swap_out_gradients/bert/encoder/layer_0/attention/output/dense/MatMul_grad/MatMul_1_0 = _CopyFromGpuToHost[T=DT_FLOAT, _class=["[email protected]_1_0"], _device="/job:localhost/replica:0/task:0/device:CPU:0"](bert/encoder/layer_0/attention/self/Reshape_5/_4869)
. Registered: device='GPU'
[[Node: swap_out_gradients/bert/encoder/layer_0/attention/output/dense/MatMul_grad/MatMul_1_0 = _CopyFromGpuToHost[T=DT_FLOAT, _class=["[email protected]_1_0"], _device="/job:localhost/replica:0/task:0/device:CPU:0"](bert/encoder/layer_0/attention/self/Reshape_5/_4869)]]
卸载原tensorflow-gpu-1.10.0切换到1.12.0
三,如果出现:Hint: If you want to see a list of allocated tensors when OOM happens
原因:GPU使用率太高了,承受不住,然后进行新的运算时就崩溃了。
解决办法:减小batch_size,尽量关闭其他无关程序。