python(协程)
协程理解
1. 协程概念
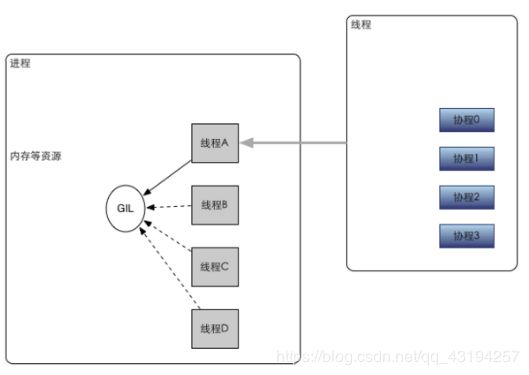
协程,又称微线程,纤程,英文名Coroutine。协程的作用,是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行。
2. 协程优势
- 执行效率极高,因为子程序切换(函数)不是线程切换,由程序自身控制,没有切换线程的开销。所以与多线程相比,线程的数量越多,协程性能的优势越明显。
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁,因此执行效率高很多。
- 说明:协程可以处理 IO 密集型程序的效率, 但是处理 CPU 密集型不是它的长处,如要充分发挥 CPU 利用率可以结合多进程 + 协程。
from collections import Iterable
def job():
for i in range(10):
print(i)
yield "result: %s" %(i)
# 函数里面包含yield关键字, 调用函数返回的是生成器对象;
# yield工作原理: 如果遇到yield就停止运行, 调用next方法, 从yield停止的地方继续运行;
j = job()
# j.__next__()
# print(next(j))
# print(isinstance(j, Iterable))
for i in j:
print(i)
协程实现方法_与多线程对比
- gevent是第三方库,通过greenlet实现协程,其基本思想:当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
- Gevent使用说明
monkey: 可以使一些阻塞的模块变得不阻塞,机制:遇到IO操作则自动切换,
手动切换可以用gevent.sleep()或者yield;
gevent.sleep(0) (将爬虫代码换成这个,效果一样可以达到切换上下文)
gevent.spawn 启动协程,参数为函数名称,参数名称
gevent.joinall 等待所有的协程执行结束;
gevent.join()
import threading
from gevent import monkey
import gevent
# 可以使一些阻塞的模块变得不阻塞,x修改python内置的标准库;
monkey.patch_all()
def job(n):
for i in range(n):
print(gevent.getcurrent(), i, n)
print("当前线程数:", threading.active_count())
gevent.sleep(1)
def main():
# 创建协程, 分配任务;
g1 = gevent.spawn(job, 1)
g2 = gevent.spawn(job, 2)
g3 = gevent.spawn(job, 3)
# #
# g1.join()
# g2.join()
# g3.join()
print("当前线程数:", threading.active_count())
gevent.joinall([g1, g2, g3])
print("任务执行结束.....")
if __name__ == '__main__':
main()
协程案例
import threading
from urllib.request import urlopen
from urllib.error import HTTPError
import gevent
from gevent import monkey
from concurrent.futures import ThreadPoolExecutor, wait
from mytimeit import timeit
monkey.patch_all()
def get_page_length(url):
try:
urlObj = urlopen(url)
except HTTPError as e:
print("捕获失败.....")
else:
pageContent = urlObj.read()
# print("%s长度为%d" %(url, len(pageContent)))
# 做实验, 访问本地url, 因为获取网络的url与网速有关(网速不稳定)
urls = ['file:///usr/share/doc/HTML/en-US/index.html', 'file:///usr/share/doc/HTML/en-US/index.html',
'file:///usr/share/doc/HTML/en-US/index.html', 'file:///usr/share/doc/HTML/en-US/index.html', ] * 30000
@timeit
def use_gevent():
gevents = [gevent.spawn(get_page_length, url) for url in urls]
gevent.joinall(gevents)
print("协程执行结束.....")
@timeit
def use_thread():
threads = []
for url in urls:
t = threading.Thread(target=get_page_length, args=(url,))
t.start()
threads.append(t)
[thread.join() for thread in threads]
if __name__ == '__main__':
use_thread()
use_gevent()

线程_协程与进程的关系图