制作目标检测数据集(通过鼠标事件)
文章目录
- 制作目标检测数据集(通过鼠标事件)
- 前言
- 通过鼠标事件框定目标
- txt文件转化为xml文件
- 结果可视化
制作目标检测数据集(通过鼠标事件)
前言
当我们在做目标检测的实验时,我们可能需要自己制作一个数据集。且这些目标检测有关的数据集很多通过xml文件进行保存。
之前在做简单的图像分割时,使用过鼠标事件来进行‘抠图’,所以想着能不能将鼠标事件应用到目标检测数据的获取上呢?
本文通过鼠标标定,获取数据并打印到txt文件中,再将txt文件转换为xml文件,以便后续实验进行操作。
通过鼠标事件框定目标
首先我们介绍两个处理鼠标动作的函数
-
回调函数(自己构造):
#event指鼠标操作控制,(x,y)指图片中标定的坐标位置,flags指鼠标和键盘合作命令效果 def on_Event(event,x,y,flags,param): -
setMouseCallback()函数
cv2.setMouseCallback('image',on_Event)
| Event | 操作 |
|---|---|
| EVENT_MOUSEMOVE | 滑动 |
| EVENT_LBUTTONDOWN | 左键点击 |
| EVENT_RBUTTONDOWN | 右键点击 |
| EVENT_MBUTTONDOWN | 中键点击 |
| EVENT_LBUTTONUP | 左键放开 |
| EVENT_RBUTTONUP | 右键放开 |
| EVENT_MBUTTONUP | 中键放开 |
| EVENT_LBUTTONDBLCL | 左键双击 |
| EVENT_RBUTTONDBLCL | 右键双击 |
| EVENT_MBUTTONDBLCL | 中键双击 |
# coding: utf-8
import cv2
import numpy as np
import glob
import os
#img = cv2.imread("D:/desktop/data/images/P0007_0512_0000.png")
# 图像存储位置(文件夹)
src_img_dir = "D:/desktop/333/images"
#这是txt文件的储存位置(标注后自动生成)
src_txt_dir = 'D:/desktop/333/annotations'
'''
filenum = 0
for lists in os.listdir(src_img_dir):
filenum += 1
print(lists)
print(filenum)
'''
#找该文件下的图片文件
img_Lists = glob.glob(src_img_dir + '/*.png')
print(img_Lists)
img_basenames = [] #文件名加文件类型
for item in img_Lists:
img_basenames.append(os.path.basename(item))
img_names = [] #文件名
for item in img_basenames:
temp1, temp2 = os.path.splitext(item)
img_names.append(temp1)
def on_EVENT_LBUTTONDOWN(event, x, y, flags, param):
#打开txt文件,在txt中存放坐标信息
file_handle=open(src_txt_dir + '/' + im +'.txt',mode='a')
#这里左击保存信息
if event == cv2.EVENT_LBUTTONDOWN:
xy = "%d,%d" % (x, y)
print(x,y) #(x,y)分别为目标框的左上和右下坐标
file_handle.write("%d %d\n"%(x,y))
cv2.circle(img, (x, y), 1, (255, 0, 0), thickness = -1)
cv2.putText(img, xy, (x, y), cv2.FONT_HERSHEY_PLAIN,
1.0, (0,0,0), thickness = 1)
cv2.imshow("image", img)
file_handle.close()
for im in img_names:
img = cv2.imread(src_img_dir + '/' + im + '.png')
cv2.namedWindow("image")
cv2.setMouseCallback("image", on_EVENT_LBUTTONDOWN) #cv2.setMouseCallback
cv2.imshow("image", img)
while(True):
try:
cv2.waitKey(100)
except Exception:
cv2.destroyWindow("image")
break
cv2.waitKey(0)
cv2.destroyAllWindow()
效果如图:

txt文件转化为xml文件
# ! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
from PIL import Image
#图像存储位置
src_img_dir = "D:/desktop/333/images/"
#图像的ground truth的txt 文件存放位置
src_txt_dir = "D:/desktop/333/annotations/"
# 生成xml文件存放位置
src_xml_dir = "D:/desktop/333/"
img_Lists = glob.glob(src_img_dir + '/*.png')
img_basenames = [] # e.g. 100.jpg
for item in img_Lists:
img_basenames.append(os.path.basename(item))
img_names = [] # e.g. 100
for item in img_basenames:
temp1, temp2 = os.path.splitext(item)
img_names.append(temp1)
for img in img_names:
im = Image.open((src_img_dir + '/' + img + '.png'))
try:
gt = open(src_txt_dir + '/' + img + '.txt').read().splitlines()
except:
continue #跳过这次循环,进入下一张图片循环
myfile = open(src_txt_dir + '/' + img + '.txt')
lines = len(myfile.readlines())
print(lines)
xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')
xml_file.write('\n')
xml_file.write('\n' )
xml_file.write('VOC2007 \n')
xml_file.write('' + '000024' + '.jpg' + '\n')
xml_file.write('\n' )
xml_file.write('The VOC2007 Database \n')
xml_file.write('PASCAL VOC2007 \n')
xml_file.write('flickr \n')
xml_file.write('322409915 \n')
xml_file.write('\n')
xml_file.write('\n' )
xml_file.write('knautia \n')
xml_file.write('yang \n')
xml_file.write('\n')
xml_file.write('\n' )
xml_file.write('' + '800' + '\n')
xml_file.write('' + '800' + '\n')
xml_file.write('0 \n')
xml_file.write('\n')
xml_file.write('0 \n')
i=0
for i in range(lines):
spt = gt[i].split(' ')
print(spt)
#由于制作的txt奇数行是xmin和ymin,偶数行是xmax和ymax,所以这里我们用 i%2 判断一下
if i%2 == 0:
xml_file.write(')
xml_file.write('' + 'large-vehicle' + '\n') #类别名称
xml_file.write('Unspecified \n')
xml_file.write('1 \n')
xml_file.write('0 \n')
xml_file.write('\n' )
xml_file.write('' + str(spt[0]) + '\n')
xml_file.write('' + str(spt[1]) + '\n')
i += 1
else:
xml_file.write('' + str(spt[0]) + '\n')
xml_file.write('' + str(spt[1]) + '\n')
xml_file.write('\n')
xml_file.write('\n')
i += 1
xml_file.write('')
print('finish {}'.format(img))
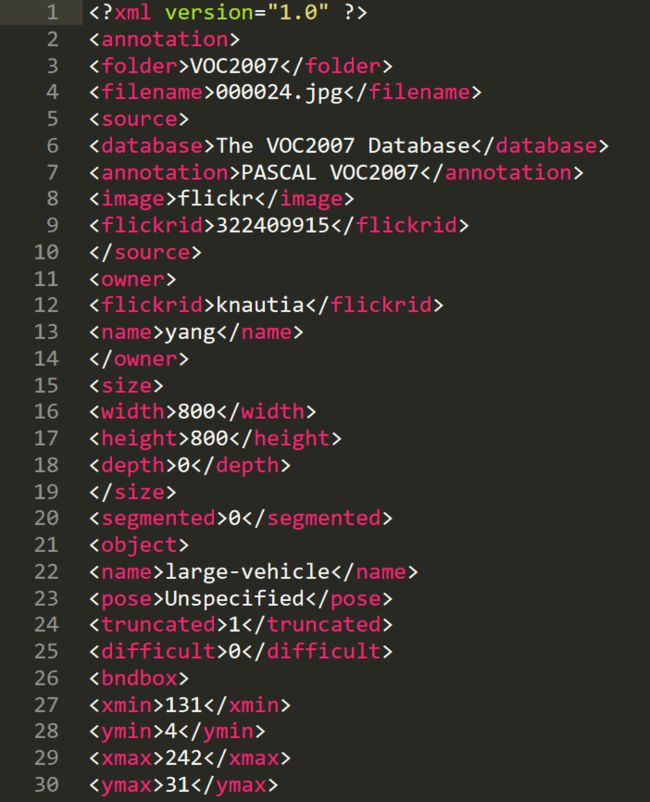
结果可视化
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os,cv2
#xml文件
xml_file='D:/desktop/Pretreatment/xml/P0004_0000_0000.xml'
tree=ET.parse(xml_file)
root=tree.getroot()
#图片文件
imgfile='D:/desktop/data/images/P0004_0000_0000.png'
im = cv2.imread(imgfile)
for object in root.findall('object'):
#找xml内的数据
object_name=object.find('name').text
Xmin=int(object.find('bndbox').find('xmin').text)
Ymin=int(object.find('bndbox').find('ymin').text)
Xmax=int(object.find('bndbox').find('xmax').text)
Ymax=int(object.find('bndbox').find('ymax').text)
#cv2框定的基本操作
color = (4, 250, 7)
cv2.rectangle(im,(Xmin,Ymin),(Xmax,Ymax),color,2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(im, object_name, (Xmin,Ymin - 7), font, 0.5, (6, 230, 230), 2)
cv2.imshow('2',im)
cv2.imwrite('D:/desktop/5.png', im)