https://leetcode.windliang.cc/ 第一时间发布
题目描述(中等难度)
给定一个字符串,输出最长的回文子串。回文串指的是正的读和反的读是一样的字符串,例如 "aba","ccbbcc"。
解法一 暴力破解
暴力求解,列举所有的子串,判断是否为回文串,保存最长的回文串。
public boolean isPalindromic(String s) {
int len = s.length();
for (int i = 0; i < len / 2; i++) {
if (s.charAt(i) != s.charAt(len - i - 1)) {
return false;
}
}
return true;
}
// 暴力解法
public String longestPalindrome(String s) {
String ans = "";
int max = 0;
int len = s.length();
for (int i = 0; i < len; i++)
for (int j = i + 1; j <= len; j++) {
String test = s.substring(i, j);
if (isPalindromic(test) && test.length() > max) {
ans = s.substring(i, j);
max = Math.max(max, ans.length());
}
}
return ans;
}
时间复杂度:两层 for 循环 O(n²),for 循环里边判断是否为回文,O(n),所以时间复杂度为 O(n³)。
空间复杂度:O(1),常数个变量。
解法二 最长公共子串
根据回文串的定义,正着和反着读一样,那我们是不是把原来的字符串倒置了,然后找最长的公共子串就可以了。例如,S = " caba",S' = " abac",最长公共子串是 "aba",所以原字符串的最长回文串就是 "aba"。
关于求最长公共子串(不是公共子序列),有很多方法,这里用动态规划的方法,可以先阅读下边的链接。
https://blog.csdn.net/u010397369/article/details/38979077
https://www.kancloud.cn/digest/pieces-algorithm/163624
整体思想就是,申请一个二维的数组初始化为 0,然后判断对应的字符是否相等,相等的话
arr [ i ][ j ] = arr [ i - 1 ][ j - 1] + 1 。
当 i = 0 或者 j = 0 的时候单独分析,字符相等的话 arr [ i ][ j ] 就赋为 1 。
arr [ i ][ j ] 保存的就是公共子串的长度。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString(); //字符串倒置
int length = s.length();
int[][] arr = new int[length][length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
for (int j = 0; j < length; j++) {
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[i][j] = 1;
} else {
arr[i][j] = arr[i - 1][j - 1] + 1;
}
}
if (arr[i][j] > maxLen) {
maxLen = arr[i][j];
maxEnd = i; //以 i 位置结尾的字符
}
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
再看一个例子,S = "abc435cba",S’ = "abc534cba" ,最长公共子串是 "abc" 和 "cba" ,但很明显这两个字符串都不是回文串。
所以我们求出最长公共子串后,并不一定是回文串,我们还需要判断该字符串倒置前的下标和当前的字符串下标是不是匹配。
比如 S = " caba ",S' = " abac " ,S’ 中 aba 的下标是 0 1 2 ,倒置前是 3 2 1,和 S 中 aba 的下标符合,所以 aba 就是我们需要找的。当然我们不需要每个字符都判断,我们只需要判断末尾字符就可以。

首先 i ,j 始终指向子串的末尾字符。所以 j 指向的红色的 a 倒置前的下标是 beforeRev = length - 1 - j = 4 - 1 - 2 = 1,对应的是字符串首位的下标,我们还需要加上字符串的长度才是末尾字符的下标,也就是 beforeRev + arr[ i ] [ j ] - 1 = 1 + 3 - 1 = 3,因为 arr[ i ] [ j ] 保存的就是当前子串的长度,也就是图中的数字 3 。此时再和它与 i 比较,如果相等,则说明它是我们要找的回文串。
之前的 S = "abc435cba",S' = "abc534cba" ,可以看一下图示,为什么不符合。
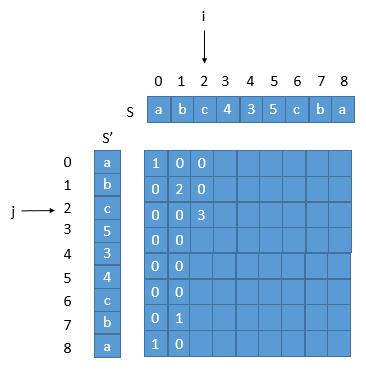
当前 j 指向的 c ,倒置前的下标是 beforeRev = length - 1 - j = 9 - 1 - 2 = 6,对应的末尾下标是 beforeRev + arr[ i ] [ j ] - 1 = 6 + 3 - 1 = 8 ,而此时 i = 2 ,所以当前的子串不是回文串。
代码的话,在上边的基础上,保存 maxLen 前判断一下下标匹不匹配就可以了。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString();
int length = s.length();
int[][] arr = new int[length][length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
for (int j = 0; j < length; j++) {
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[i][j] = 1;
} else {
arr[i][j] = arr[i - 1][j - 1] + 1;
}
}
/**********修改的地方*******************/
if (arr[i][j] > maxLen) {
int beforeRev = length - 1 - j;
if (beforeRev + arr[i][j] - 1 == i) { //判断下标是否对应
maxLen = arr[i][j];
maxEnd = i;
}
/*************************************/
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
时间复杂度:两层循环,O(n²)。
空间复杂度:一个二维数组,O(n²)。
空间复杂度其实可以再优化一下。
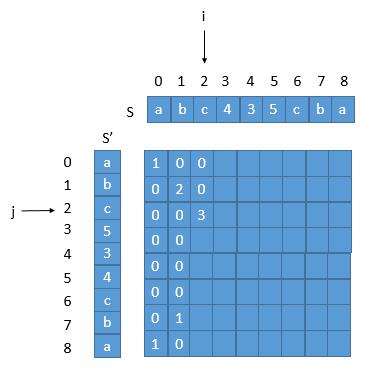
我们分析一下循环,i = 0 ,j = 0,1,2 ... 8 更新一列,然后 i = 1 ,再更新一列,而更新的时候我们其实只需要上一列的信息,更新第 3 列的时候,第 1 列的信息是没有用的。所以我们只需要一个一维数组就可以了。但是更新 arr [ i ] 的时候我们需要 arr [ i - 1 ] 的信息,假设 a [ 3 ] = a [ 2 ] + 1,更新 a [ 4 ] 的时候, 我们需要 a [ 3 ] 的信息,但是 a [ 3 ] 在之前已经被更新了,所以 j 不能从 0 到 8 ,应该倒过来,a [ 8 ] = a [ 7 ] + 1,a [ 7 ] = a [ 6 ] + 1 , 这样更新 a [ 8 ] 的时候用 a [ 7 ] ,用完后才去更新 a [ 7 ],保证了不会出错。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString();
int length = s.length();
int[] arr = new int[length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
/**************修改的地方***************************/
for (int j = length - 1; j >= 0; j--) {
/**************************************************/
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[j] = 1;
} else {
arr[j] = arr[j - 1] + 1;
}
/**************修改的地方***************************/
//之前二维数组,每次用的是不同的列,所以不用置 0 。
} else {
arr[j] = 0;
}
/**************************************************/
if (arr[j] > maxLen) {
int beforeRev = length - 1 - j;
if (beforeRev + arr[j] - 1 == i) {
maxLen = arr[j];
maxEnd = i;
}
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
时间复杂度:O(n²)。
空间复杂度:降为 O(n)。
解法三 暴力破解优化
解法一的暴力解法时间复杂度太高,在 leetCode 上并不能 AC 。我们可以考虑,去掉一些暴力解法中重复的判断。我们可以基于下边的发现,进行改进。
首先定义 P(i,j)。
接下来
所以如果我们想知道 P(i,j)的情况,不需要调用判断回文串的函数了,只需要知道 P(i + 1,j - 1)的情况就可以了,这样时间复杂度就少了 O(n)。因此我们可以用动态规划的方法,空间换时间,把已经求出的 P(i,j)存储起来。

如果 是回文串,那么只要 S [ i ] == S [ j ] ,就可以确定 S [ i , j ] 也是回文串了。
求 长度为 1 和长度为 2 的 P ( i , j ) 时不能用上边的公式,因为我们代入公式后会遇到 中 i > j 的情况,比如求 的话,我们需要知道 ,而 代表着 是不是回文串,显然是不对的,所以我们需要单独判断。
所以我们先初始化长度是 1 的回文串的 P [ i , j ],这样利用上边提出的公式 ,然后两边向外各扩充一个字符,长度为 3 的,为 5 的,所有奇数长度的就都求出来了。
同理,初始化长度是 2 的回文串 P [ i , i + 1 ],利用公式,长度为 4 的,6 的所有偶数长度的就都求出来了。
public String longestPalindrome(String s) {
int length = s.length();
boolean[][] P = new boolean[length][length];
int maxLen = 0;
String maxPal = "";
for (int len = 1; len <= length; len++) //遍历所有的长度
for (int start = 0; start < length; start++) {
int end = start + len - 1;
if (end >= length) //下标已经越界,结束本次循环
break;
P[start][end] = (len == 1 || len == 2 || P[start + 1][end - 1]) && s.charAt(start) == s.charAt(end); //长度为 1 和 2 的单独判断下
if (P[start][end] && len > maxLen) {
maxPal = s.substring(start, end + 1);
}
}
return maxPal;
}
时间复杂度:两层循环,O(n²)。
空间复杂度:用二维数组 P 保存每个子串的情况,O(n²)。
我们分析下每次循环用到的 P(i,j),看一看能不能向解法二一样优化一下空间复杂度。
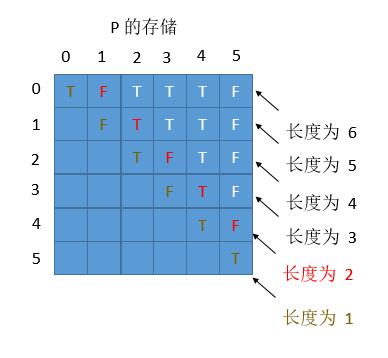
当我们求长度为 6 和 5 的子串的情况时,其实只用到了 4 , 3 长度的情况,而长度为 1 和 2 的子串情况其实已经不需要了。但是由于我们并不是用 P 数组的下标进行的循环,暂时没有想到优化的方法。
之后看到了另一种动态规划的思路
https://leetcode.com/problems/longest-palindromic-substring/discuss/2921/Share-my-Java-solution-using-dynamic-programming 。
公式还是这个不变
首先定义 P(i,j)。
接下来
递推公式中我们可以看到,我们首先知道了 i +1 才会知道 i ,所以我们只需要倒着遍历就行了。
public String longestPalindrome(String s) {
int n = s.length();
String res = "";
boolean[][] dp = new boolean[n][n];
for (int i = n - 1; i >= 0; i--) {
for (int j = i; j < n; j++) {
dp[i][j] = s.charAt(i) == s.charAt(j) && (j - i < 2 || dp[i + 1][j - 1]); //j - i 代表长度减去 1
if (dp[i][j] && j - i + 1 > res.length()) {
res = s.substring(i, j + 1);
}
}
}
return res;
}
时间复杂度和空间复杂和之前都没有变化,我们来看看可不可以优化空间复杂度。

当求第 i 行的时候我们只需要第 i + 1 行的信息,并且 j 的话需要 j - 1 的信息,所以和之前一样 j 也需要倒叙。
public String longestPalindrome7(String s) {
int n = s.length();
String res = "";
boolean[] P = new boolean[n];
for (int i = n - 1; i >= 0; i--) {
for (int j = n - 1; j >= i; j--) {
P[j] = s.charAt(i) == s.charAt(j) && (j - i < 3 || P[j - 1]);
if (P[j] && j - i + 1 > res.length()) {
res = s.substring(i, j + 1);
}
}
}
return res;
}
时间复杂度:不变,O(n²)。
空间复杂度:降为 O(n ) 。
解法四 扩展中心
我们知道回文串一定是对称的,所以我们可以每次循环选择一个中心,进行左右扩展,判断左右字符是否相等即可。
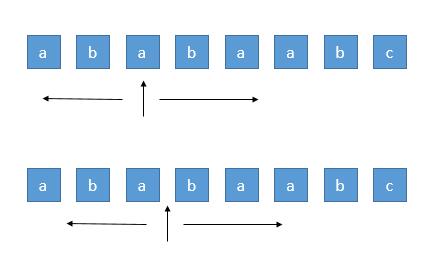
由于存在奇数的字符串和偶数的字符串,所以我们需要从一个字符开始扩展,或者从两个字符之间开始扩展,所以总共有 n + n - 1 个中心。
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expandAroundCenter(String s, int left, int right) {
int L = left, R = right;
while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) {
L--;
R++;
}
return R - L - 1;
}
时间复杂度:O(n²)。
空间复杂度:O(1)。
解法五 Manacher's Algorithm 马拉车算法。
马拉车算法 Manacher‘s Algorithm 是用来查找一个字符串的最长回文子串的线性方法,由一个叫Manacher的人在1975年发明的,这个方法的最大贡献是在于将时间复杂度提升到了线性。
主要参考了下边链接进行讲解。
https://segmentfault.com/a/1190000008484167
https://blog.crimx.com/2017/07/06/manachers-algorithm/
http://ju.outofmemory.cn/entry/130005
https://articles.leetcode.com/longest-palindromic-substring-part-ii/
首先我们解决下奇数和偶数的问题,在每个字符间插入"#",并且为了使得扩展的过程中,到边界后自动结束,在两端分别插入 "^" 和 "$",两个不可能在字符串中出现的字符,这样向解法四那样中心扩展的时候,判断两端字符是否相等的时候,如果到了边界就一定会不相等,从而出了循环。经过处理,字符串的长度永远都是奇数了。

首先我们用一个数组 P 保存从中心扩展的个数,巧合的它也是去掉 "#" 的字符串的总长度,可以看下边的图。

用 P 的下标 i 减去 P[i],再除以 2 ,就是原字符串的开头下标了。
例如我们找到 P[i] 的最大值为 5 ,也就是回文串的最大长度是 5 ,对应的下标是 6 ,所以原字符串的开头下标是 (6 - 5 )/ 2 = 0 。所以我们只需要返回原字符串的第 0 到 第 (5 - 1)位就可以了。
接下来是算法的关键了,它充分利用了回文串的对称性。
我们用 C 表示回文串的中心,用 R 表示回文串的右边半径。所以 R = C + P[i] 。C 和 R 所对应的回文串是当前循环中 R 最靠右的回文串。
用 i_mirror 表示当前扩展的第 i 个字符关于 C 对应的下标。
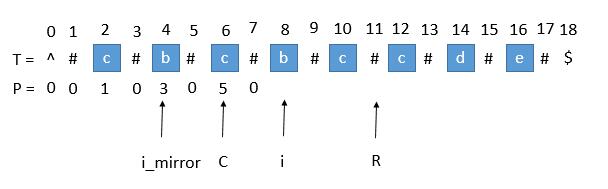
我们现在要求 P [ i ] 如果是解法四,那就向两边扩展就行了。但是我们其实可以利用回文串 C 的对称性。i 关于 C 的对称点是 i_mirror ,P [ mirror ] = 3,所以 P [ i ] 也等于 3 。
有三种情况将会造成直接赋值为 P [ mirror ] 是不正确的。
超出了 R

当我们要求 P[i] 的时候,P [ mirror ] = 7,而此时 P [ i ] 并不等于 7 ,为什么呢,因为我们从 i 开始往后数 7 个,等于 22 ,已经超过了最右的 R ,此时不能利用对称性了,但我们一定可以扩展到 R 的,所以 P [i] 至少等于 R - i = 20 - 15 = 5,会不会更大呢,我们只需要比较 T[R+1] 和 T[R+1]关于 i 的对称点就行了,像解法四一样一个个扩展。
P [ mirror ] 遇到了左边界
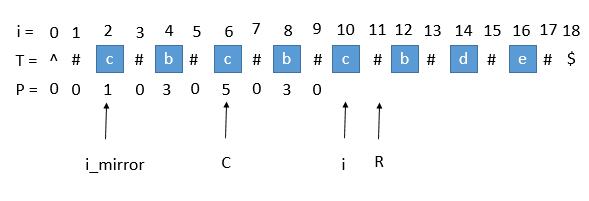
此时 P [ i ] 赋值成 1 是不正确的,出现这种情况的原因是 P [ i_mirror ] 在扩展的时候首先是 "#" == "#" ,之后遇到了 "^"和另一个字符比较,也就是到了边界,才终止循环的。而 P [ i ] 并没有遇到边界,所以我们可以接着扩展,就像之前一样。
i 等于了 R
此时我们先把 P [ i ] 赋值为 0 ,然后一步一步扩展就行了。
就这样一步一步的求出每个 P [ i ],当求出的 P [ i ] 的右边界大于当前的 R 时,我们就需要更新 C 和 R 为当前的回文串了。因为我们必须保证 i 在 R 里面,所以一旦有更右边的 R 就要更新 R。
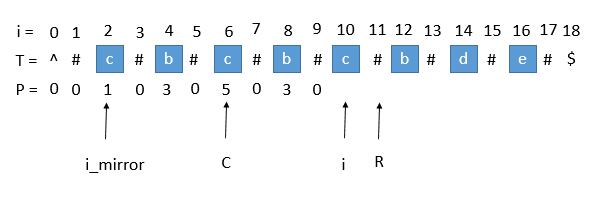
此时的 P [ i ] 求出来将会是 3 ,P [ i ] 对应的右边界将是 10 + 3 = 13,所以大于当前的 R ,我们需要把 C 更新成 i 的值,也就是 10 ,R 更新成 13。继续下边的循环。
public String preProcess(String s) {
int n = s.length();
if (n == 0) {
return "^$";
}
String ret = "^";
for (int i = 0; i < n; i++)
ret += "#" + s.charAt(i);
ret += "#$";
return ret;
}
// 马拉车算法
public String longestPalindrome2(String s) {
String T = preProcess(s);
int n = T.length();
int[] P = new int[n];
int C = 0, R = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * C - i;
if (R > i) {
P[i] = Math.min(R - i, P[i_mirror]);// 防止超出 R
} else {
P[i] = 0;// 等于 R 的情况
}
// 碰到之前讲的三种情况时候,需要继续扩展
while (T.charAt(i + 1 + P[i]) == T.charAt(i - 1 - P[i])) {
P[i]++;
}
// 判断是否需要更新 R
if (i + P[i] > R) {
C = i;
R = i + P[i];
}
}
// 找出 P 的最大值
int maxLen = 0;
int centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2; //最开始讲的
return s.substring(start, start + maxLen);
}
时间复杂度:for 循环里边套了一层 while 循环,难道不是 O ( n² ),不!其实是 O(n)。我们想象一下整个过程,首先外层有一个 for 循环,所以每个字符会遍历一次,而当我们扩展的时候,每次都是从 R + 1 开始扩展,之后又会更新 R 。所以一些字符会遍历两次,但此时这些字符变到 R 的左边,所以不会遍历第三次了,因为我们每次从 R 的右边开始扩展。综上,每个字符其实最多遍历 2 次,所以依旧是线性的,当然如果字符串成为 len ,这里的 n 其实是 2 * len + 3 。所以时间复杂度是 O(n)。
空间复杂度:O(n)。
总结
时间复杂度从三次方降到了一次,美妙!这里两次用到了动态规划去求解,初步认识了动态规划,就是将之前求的值保存起来,方便后边的计算,使得一些多余的计算消失了。并且在动态规划中,通过观察数组的利用情况,从而降低了空间复杂度。而 Manacher 算法对回文串对称性的充分利用,不得不让人叹服,自己加油啦!