一、在线日志分析
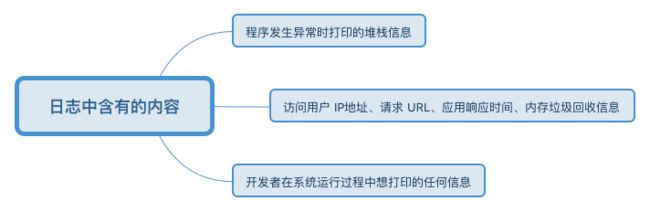
日志中所包含的内容如下图:
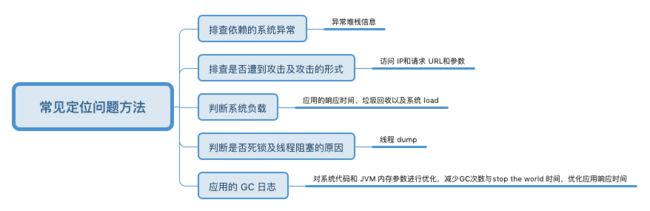
常见定位问题的方法如下图:
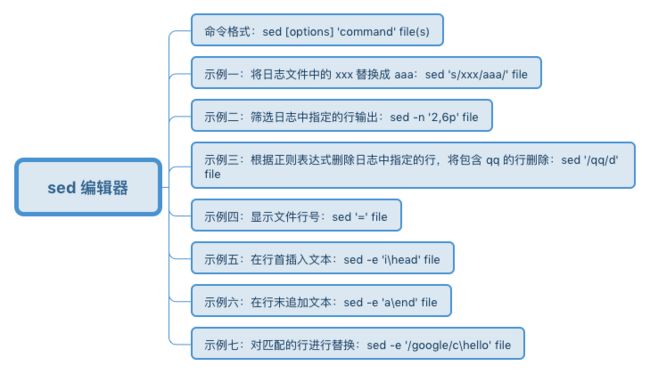
1. 日志分析常用命令

2. 日志分析脚本

二、集群监控
1. 监控指标
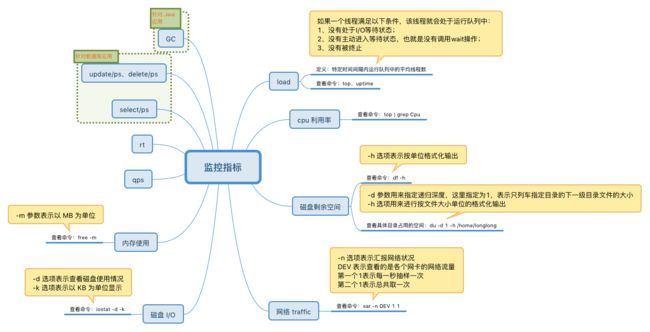
1.1 load
系统的load被定义为特定时间间隔内运行队列中的平均线程数,如果一个线程满足以下条件,该线程就会处于运行队列中:
- 没有处于I/O等待状态;
- 没有主动进入等待状态,也就是没有调用wait操作;
- 没有被终止。
每个CPU的核都维护了一个运行队列,系统的load主要由运行队列来决定。load的值越大,也就意味着系统的CPU越繁忙,这样线程运行完以后等待操作系统分配下一个时间片段的时间也就越长。一般来说,只要每个CPU当前的活动线程数不大于3,我们认为它的负载是正常的,如果每个CPU的线程数大于5,则表示当前系统的负载已经非常高了,需要采取措施来减低系统的负载,以提高响应速度。
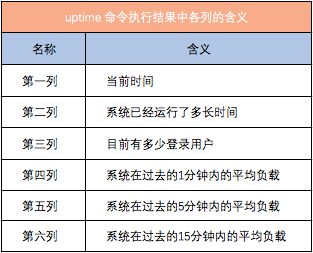
使用uptime命令查看系统的load:
[log@www ~]$ uptime
08:44:47 up 260 days, 20:31, 1 user, load average: 7.07, 6.13, 5.93
各个列的含义如下:
1.2 CPU利用率
在 Linux 系统下,CPU 的时间消耗主要在这几个方面,即用户进程、内核进程、中断处理、I/O 等待、Nice 时间、丢失时间、空闲等几个部分,而 CPU 的利用率则为这些时间所占总时间的百分比。通过 CPU 的利用率,能够反映出CPU 的使用和消耗情况。
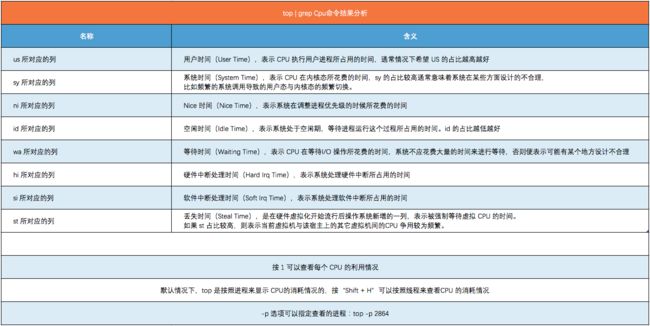
可以通过top 命令来查看Linux系统的 CPU 消耗情况:
[log@www ~]$ top | grep Cpu
%Cpu(s): 5.4 us, 1.4 sy, 0.0 ni, 92.9 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu(s): 4.5 us, 1.2 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
%Cpu(s): 3.8 us, 1.1 sy, 0.0 ni, 94.9 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
其中,CPU 后面跟的各个列便是各种状态下 CPU所消耗的时间占比。
1.3 磁盘剩余空间
通过df 命令,能够看到磁盘的剩余空间。
[log@www ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 49G 3.1G 46G 7% /
devtmpfs 16G 0 16G 0% /dev
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 16G 1.6G 15G 10% /run
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/sda2 494M 123M 372M 25% /boot
/dev/sda6 488G 206G 283G 43% /app
tmpfs 3.2G 0 3.2G 0% /run/user/1003
tmpfs 3.2G 0 3.2G 0% /run/user/0
tmpfs 3.2G 0 3.2G 0% /run/user/1000
-h 选项表示按单位格式化输出。该命令显示 sda3一共有49GB 的空间,3.1G 已用,剩余46GB 空间可用。
如果需要查看具体目录所占用的空间,分析大文件所处位置,可以使用 du 命令来进行查看:
[log@www ~]$ du -d 1 -h /app
208G /app/test
944K /app/scripts
208G /app
其中-d 参数用来指定递归深度,这里指定为1,表示只列出指定目录的下一级目录文件的大小,-h 选项用来进行按文件大小单位的格式化输出。
1.4 网络 traffic
通过 sar 命令,可以看到系统的网络状况:
[log@www ~]$ sar -n DEV 1 1
Linux 3.10.0-327.el7.x86_64 (www.www) 10/23/2017 _x86_64_ (32 CPU)
08:21:22 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
08:21:23 AM eth0 55716.00 55578.00 11306.84 9979.24 0.00 0.00 0.00
08:21:23 AM eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:21:23 AM eth2 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:21:23 AM eth3 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:21:23 AM lo 4511.00 4511.00 1282.70 1282.70 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: eth0 55716.00 55578.00 11306.84 9979.24 0.00 0.00 0.00
Average: eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth2 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth3 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: lo 4511.00 4511.00 1282.70 1282.70 0.00 0.00 0.00
-n 选项表示汇报网络状况,而 DEV 则表示查看的是各个网卡的网络流量,第一个1表示每1秒抽样一次,第二个1表示总共取一次。输出结果的含义如下:

1.5 磁盘 I/O
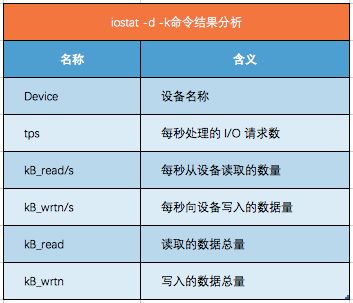
查看系统的I/O 状况:
[log@www ~]$ iostat -d -k
Linux 3.10.0-327.el7.x86_64 (www.www) 10/24/2017 _x86_64_ (32 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 17.12 1412.58 1728.90 32444667123 39710079394
使用iostat 工具能够看到磁盘的I/O 情况,其中-d选项表示查看磁盘使用情况,-k 选项表示以 KB为单位显示。输出结果含义如下:
1.6 内存使用
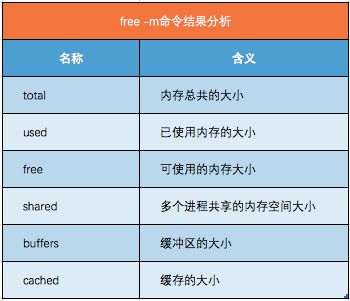
通过 free 命令可以查看内存的使用情况,加上-m 参数表示以 MB 为单位:
[log@www ~]$ free -m
total used free shared buff/cache available
Mem: 31890 18587 3234 297 10068 12551
Swap: 19999 5767 14232
Linux 的内存包括物理内存Mem 和虚拟内存swap,下面介绍下每一列的含义:
对应用来说,更值得关注的应该是虚拟内存swap 的消耗,swap 内存使用的过多,表示物理内存已经不够用了,操作系统将本应该物理内存存储的一部分内存页调度到磁盘上,以腾出足够的空间给当前的进程使用。当其他进程需要运行时,再从磁盘将内存的页调度到物理内存当中,以恢复进程的运行。而这个调度的过程,则会产生swap I/O,如果 swap I/O较为频繁,将严重地影响系统性能。
通过 vmstat命令,可以查看到swap I/O 的情况:
[log@www ~]$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
20 0 5905120 2246828 4 11370556 0 0 44 54 0 0 5 2 93 0 0
其中,swap 列的 si 表示每秒从磁盘交换到内存的数据量,单位是KB/s,so 表示每秒从内存交换到磁盘的数据量,单位也是KB/s。
1.7 qps
qps 是 query per second 的缩写,即每秒查询数。qps 在很大程度上代表了系统在业务上的繁忙程度,而每次请求的背后,可能对应着多次磁盘I/O、多次网络请求,以及多个 CPU 时间片。
通过关注系统的qps 数,我们能够非常直观地了解到当前系统业务情况,一旦当前系统的 qps值超过所设置的预警阈值,即可考虑增加机器以对集群进行扩容,以免因压力过大而导致宕机。集群预警阈值的设定,可以根据当前压测得出的值,综合后期的运维经验,评估一个较为合理的数值。
1.8 rt
rt 是response time 的缩写,即请求的响应时间。响应时间是一个非常关键的指标,直接关系到前端的用户体验。因此,任何开发人员和设计师都想尽可能地降低系统的rt 时间。对于Web 应用来说,如果响应太慢而导致用户失去耐心,将损失大量的用户。降低rt 时间需要从各个方面入手,找到应用的瓶颈,对症下药。例如,通过部署 CDN 边缘节点来缩短用户请求的物理路径;通过内容压缩来减少传输的字节数;使用缓存来减少磁盘I/O和网络请求等。
而通过Apache或者Nginx的访问日志,便能够得知每个请求的响应时间。以 Nginx 为例,在访问日志的输出格式中,增加$request_time的输出,便能够获得响应时间。
CPU、内存、网络、磁盘、qps 和 rt。这些对于所有类型的应用都需要关注,也有一些指标只针对某一类型的应用,如select/ps、update/ps、delete/ps只针对数据库应用,thread running只针对MySQL数据库应用,FullGC只针对Java 应用。
1.9 select/ps
select/ps记录了数据库每秒处理的 select语句的数量。对于 MySQL数据库来说,如果select请求数量过多,则可以适当地增加读库,以降低系统读的压力。
1.10 update/ps、delete/ps
update/ps 记录了数据库每秒处理 update语句的数量,相应地,delete/ps则记录了数据库每秒处理 delete语句的数量。对于MySQL 数据库来说,如果 update/delete这样的写入请求过多,单单增加读的slave已经解决不了问题,这时需要对响应的库进行拆分,将请求分散到其它集群。
1.11 GC
可以对 JVM的一些内存参数进行调整和优化,以降低 GC时应用停止响应的时间。如果一个 Java 应用频繁地进行Full GC,我们认为它的性能是有问题的。
2. 心跳检测
1、ping
2、应用层检测
3、业务检测
3. 容量评估及应用水位
三、流量控制
1. 流量控制实施
2. 服务稳定性
1、依赖管理
2、优雅降级
3、服务分级
4、开关
5、应急预案
3. 高并发系统设计
1、操作原子性
2、多线程同步
3、数据一致性
4、系统可扩展性
5、并发减库存
四、性能优化
1. 如何寻找性能瓶颈
1、前端优化工具——YSlow
2、页面响应时间
3、方法响应时间
4、GC 日志分析
5、数据库查询
6、系统资源使用
2. 性能测试工具
2.1 ab
ab 的全称为 ApacheBench,用来对 HTTP 服务器进行性能测试的小工具,可以模拟多个并发请求来对服务器进行压力测试,得出服务器在高负载下能够支持的 qps 及应用的响应时间,为系统设计者提供参考依据。
ab的使用:
ab [options] [http[s]://]hostname[:port]/path
常用参数:
-n 总的请求数;
-c 并发用户数量。
假设并发数为5,一共执行100次请求,目标服务器为ab -n 100 -c 5 http://www.cnblogs.com,则对应的命令为:
ab -n 100 -c 5 http://www.cnblogs.com/mongo/p/4910249.html
执行后的结果如下:
Server Software:
Server Hostname: www.cnblogs.com
Server Port: 80
Document Path: /mongo/p/4910249.html
Document Length: 15723 bytes
Concurrency Level: 5
Time taken for tests: 0.599 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 1605900 bytes
HTML transferred: 1572300 bytes
Requests per second: 167.03 [#/sec] (mean)
Time per request: 29.935 [ms] (mean)
Time per request: 5.987 [ms] (mean, across all concurrent requests)
Transfer rate: 2619.42 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 2 4 2.9 3 14
Processing: 13 25 31.3 16 231
Waiting: 11 16 10.4 14 77
Total: 15 29 31.6 20 234
Percentage of the requests served within a certain time (ms)
50% 20
66% 26
75% 31
80% 32
90% 40
95% 70
98% 229
99% 234
100% 234 (longest request)
其中,几个比较重要的指标包括:
- Requests per second为每秒处理的请求数量,即吞吐量;
- Time per request 第一个 Time per request 的值为每次并发所消耗的平均时间,即请求平均等待时间,第二个Time per request 的值为每次请求所消耗的平均时间;
- Complete requests为完成的请求数量;
- Failed requests为失败的请求数量。
2.2 Apache JMeter
JMeter 的功能比 ab更为强大,采用纯 Java 实现,支持多种协议的性能基准测试,如 HTTP、SOAP、FTP、TCP、SMTP、POP3等;可以用于模拟在服务器、网络或者其他对象上施加高负载,以测试他们的压力承受能力,或者分析他们在不同负载的情况下的性能表现;能够灵活地进行插件化的扩展;支持通过脚本方式的回归测试,并且提供各项指标的图形化展示。
2.3 HP LoadRunner
LoadRunner 是一款功能极为强大的商业付费性能测试工具,它通过模拟大量实际用户的操作行为和实时性能检测的方式,帮助用户更加快速地查找和确认问题。
2.4 反向代理引流
在分布式环境下,流量真正到达服务器之前,一般会经过负载均衡设备进行转发,通过修改负载均衡的策略,可以改变后端服务器所承受的压力。在新版本发布之前,可以先对少部分机器进行灰度发布,以验证程序的正确性和稳定性,并且通过修改负载均衡策略,可以改变机器所承受的负载,达到对在线机器进行性能基准测试的目的。
2.5 TCPCopy
TCPCopy是一款请求复制工具,能够将在线请求复制到测试机器,模拟真实环境,达到程序在不上线的情况下承担线上真实流量的效果。
TCPCopy 分为TCPCopy Client 和 TCPCopy Server,其中TCPCopy Client运行在真实环境的线上服务器之上,用来捕获在线请求数据包,而TCPCopy Server则运行在测试机上,用来捕获响应包,并将响应包的头部信息传递给TCPCopy Client,以完成 TCP 交互。
3. 性能优化措施
3.1 前端性能优化
(1)减少页面的 HTTP 请求数量
(2)使用 CDN 网络
(3)使用压缩
3.2 Java 程序优化
(1)单例
(2)Future 模式
假设一个任务 执行起来需要花费一些时间,为了省去不必要的等待时间,可以先获取一个“提货单”,即 Future,然后继续处理别的任务,直到“货物”到达,即任务执行完得到结果,此时便可以用“提货单”进行提货,即通过Future 对象得到返回值。
如下面的代码所示,加载数据可能需要花费一定的时间,此时可以先开始任务,随后处理其他事情,等其它事情都处理完后再取结果:
static class JobFutureTask 类实现了Future 和Runnable 接口,FutureTask开始后,loadData()执行时间可能较长,因此可以先处理其他事情,等其它事情处理好后,再通过future.get()来获取结果,如果loadData()还未执行完毕,则此时线程会阻塞等待。
(3)线程池
(4)选择就绪——NIO
(5)减少上下文切换
(6)降低锁竞争
3.3 压缩
3.4 结果缓存
3.5 数据库查询性能优化
(1)合理使用索引
MySQL 提供了explain 命令,用来解释和分析SQL 查询语句,通过explain 命令,可以模拟查询优化器来执行 SQL 语句,从而知道 MySQL是如何执行你的语句的。
举例来说,现有如下一张表,用来存放用户的订单信息:
create table order_info(
order_id int primary key auto_increment,
user_id int,
price int,
good_id int,
good_title varchar(100),
good_info varchar(500)
);
假设通过order_id(即表的主键)来进行查询,explain的结果是这样的:
explain select * from order_info where order_id =1 ;
explain 详细的解释见:mysql explain执行计划详解
(2)反范式设计
(3)使用查询缓存
(4)使用搜索引擎
(5)使用key-value 数据库
3.6 GC 优化
3.7 硬件提升性能
五、Java 应用故障的排查
1. 常用的工具
1、jps
2、jstat
3、jinfo
4、jstack
5、jmap
6、BTrace
7、JConsole
8、Memory Analyzer(MAT)
9、VisualVM
2. 典型案例分析
六、参考文献
性能测试-ApacheBench
Jmeter使用入门
mysql explain执行计划详解
大型分布式网站架构设计与实践——陈康贤著