Scrapy - Spiders详解
Spiders是Scrapy中最重要的地方,它定义了如何爬取及解析数据,可以说Spiders是Scrapy框架中的核心所在。
对Spiders来说,一般工作的步骤如下:
- 根据初始的URLs生成Requests对象并指定处理requests对象response的回调方法。初始的URLs是由spider的start_urls属性指定的,然后默认调用start_requests方法生成对应的Requests对象,处理requests对象response的默认回调方法是parse。
- 在回调方法里,解析response的内容并返回希望提取的数据,可以返回字典格式的数据,Item对象,Request对象或者是这些对象的迭代器。如果是返回的Request对象,同样也要指定其的回调方法(可以是当前的这一个),然后Scrapy也会同样的处理这些Request对象:获取他们的response,使用回调方法解析并返回数据。
- 在回调方法里,使用Scrapy的Selector(选择器)来提取response里的数据并返回(也可以使用其他的解析工具,如BeautifulSoup、lxml等)。
- 最后从spider返回的数据,我们可以通过Item Pipeline写入数据库或使用feed exports保存到文件中。
最简单的spider:scrapy.spiders.Spider
scrapy中所有的spider都继承的它。它提供了spider最主要的属性和功能 - start_urls,start_requests(),parse()。
name - 用于定义spider名字的字符串。spider的名字是scrapy用于定位spider的,因此它的名字必须是唯一的。但是scrapy中没有任何机制可以防止你多次实例化同一个spider。所以名字是spider最重要的属性且是必须的。按惯例,如果spider是只爬取单一的域名,那spider名字就以域名来命名。如:爬取mywebsite.com的spider,通常取名为mywebsite。
allowed_domains - 用于定义spider可以爬取的域名的字符串列表。如果OffsiteMiddleware被启用了,则不属于这个列表里的域名的URL scrapy不会发送请求及进行相关处理。
start_urls - 定义spider开始爬取数据的URL列表。随后生成的其它需要爬取的URL都会是从这些URL对应的页面中提取数据生成出来的。
custom_settings - 定义该spider配置的字典。这个配置会在项目范围内运行这个spider的时候生效。
crawler - 定义spider实例绑定的crawler对象。这个属性是在初始化spider类时由from_crawler()方法设置的。crawler对象概括了许多项目的组件。
settings - 运行spider的配置。这是一个settings对象的实例。
logger - 用spider名字创建的python记录器。可以用来发送日志消息。
from_crawler(crawler, *args, **kwargs) - scrapy用于创建spiders的类方法。一般都不需要重写这个方法,因为默认的实现是作为一个__init__()方法的代理,传参数args和kwargs来调用它。这个方法就是用来在新的spider实例中设置crawler和settings属性的,以便之后在spider的代码中可以访问。
参数:
- crawler(crawler实例)- spider将绑定的crawler
- args(list)- 传递给__init__()方法的参数
- kwargs(字典)- 传递给__init__()方法的关键字参数
start_requests() - 这个方法必须返回该spider的可迭代的初始requests对象供后续爬取。Scrapy会在该spider开始爬取数据时被调用,且只会被调用一次,因此可以很安全的将start_requests()做为一个生成器来执行。默认的执行会生成每一个在start_urls中的url对应的request对象。
如果想修改开始爬取一个域名的requests对象,以下是重写的方法(你需要开始用POST请求先登录系统):
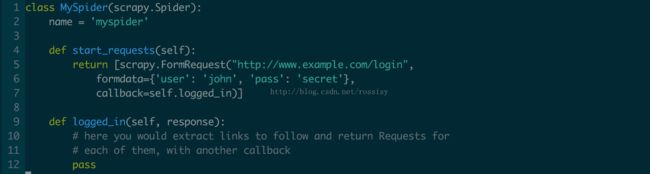
parse(response) - Scrapy默认的回调用来处理下载的response。parse方法负责处理response,返回爬取的数据或者还有继续爬取的URL(request对象)。其他Requests回调方法与Spider类有相同的要求。这个方法与其它的Request回调一样,必须返回可迭代的Request对象、字典或Item对象。
参数:
- response(Response对象)- 需要解析的response
log(message[, level, component]) - 通过Spider的记录器包装发送的日志信息,保持与之前的兼容性。
closed(reason) - 当Spider关闭的时候调用的方法。这个方法为spider_closed提供了一个信号给signals.connect()。
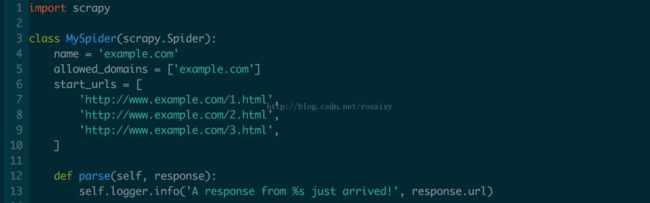
看个例子:
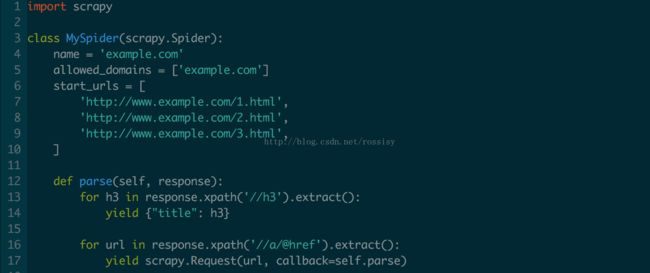
一个回调方法返回多个Requests对象和items:
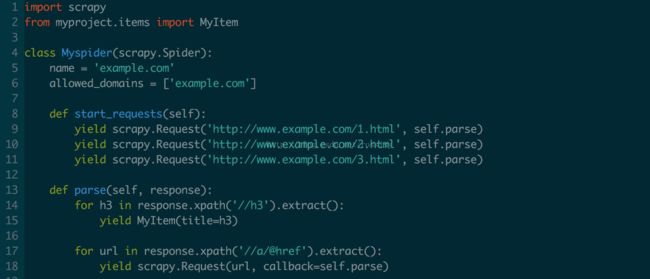
如果不使用start_urls,还可以直接使用start_requests()方法;要使数据更具结构化可以使用Items:
Spider的参数
可以通过设置Spider的参数来修改它的某些属性。一般的用法是定义Spider开始爬取数据的URL或限制爬取网站的指定部分的数据,但是它其实还可以用于设置Spider的任何功能。Spider的参数是通过crawl命令的-a选项来传递给Spider的,如:
(scrapyEnv) MacBook-Pro:~ $ scrapy crawl myspider -a category=electronics
这些参数都可以在Spider的__init__方法中访问到:

默认的__init__方法会将传递来的参数作为Spider的属性,所以还可以通过Spider的属性访问命令行中设置的Spider参数,如:

注意:Spider的参数只能是字符串格式,对于参数Spider是不会进行任何解析的。如果你在命令行中设置了start_urls参数,那你必须手动的在Spider中将它转换成list然后把list设置为Spider的属性,否则Spider会将字符串格式的参数start_urls中的每一个字符当成一个单独的url去生成Request对象。
一个通过HttpAuthMiddleWare设置http认证证书还有通过UserAgentMiddleware设置user agent的例子:
(scrapyEnv) MacBook-Pro:~ $ scrapy crawl myspider -a http_user=myuser -a http_pass=mypassword -a user_agent=mybot
Spider的参数也可以通过Scrapyd的schedule.json API来传递。