Sharding-JDBC 3.x 原理篇之基本介绍(一)
简介
Sharding-JDBC是当当开源的数据库水平切分的中间件,其代表了客户端类的分库分表技术框架(这一点与MyCat不同,MyCat本质上是一种数据库代理)。Sharding-JDBC定位为轻量级数据库驱动,由客户端直连数据库,以jar包形式提供服务,未使用中间层,无需额外部署,无其他依赖,业务系统开发人员与数据库运维人员无需改变原有的开发与运维方式。因此Sharding-JDBC即为增强版的JDBC驱动,可以实现旧代码迁移零成本的目标。 目前社区较为活跃。目前已广泛应用于现各大互联网公司。通过社区得知,Sharding-JDBC的作者已去京东做全职的Sharding-JDBC开发,相信未来Sharding-JDBC社区的发展将会更好。
功能介绍
目前Sharding-JDBC共有3个主要模块,分别为Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar
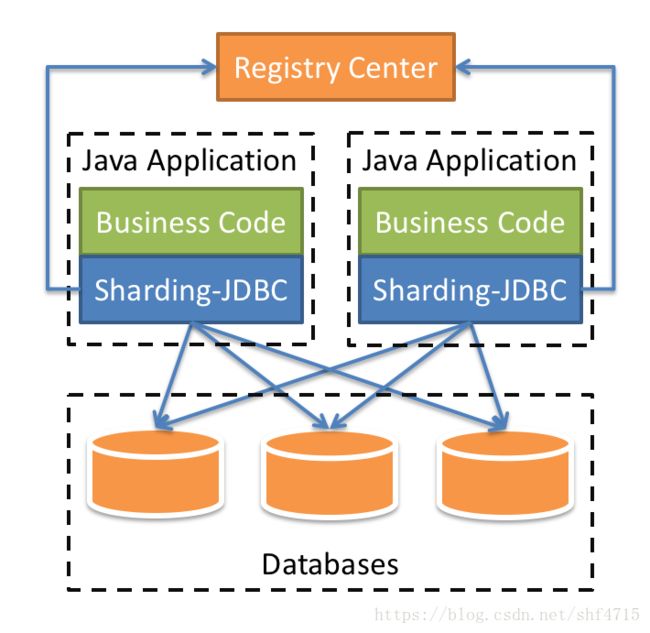
Sharding-JDBC
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL使用。
- 适用于任何兼容MySQL协议的客户端。

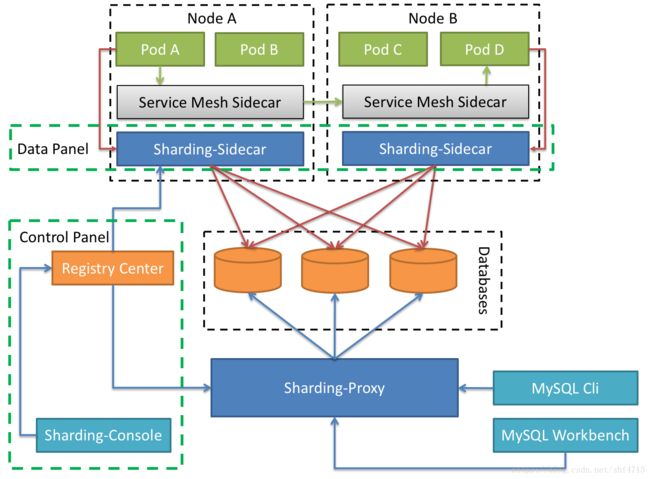
Sharding-Sidecar
定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
Database Mesh的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。使用Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
各大版本间的区别与变化
1.x
Sharding-JDBC是一款基于JDBC的数据库中间件产品,对Java的应用程序无任何改造成本,只需配置分片规则即可无缝集成进遗留系统,使系统在数据访问层直接具有分片化和分布式治理的能力。
Sharding-JDBC 1.x关注SQL兼容性、分库分表、读写分离、分布式主键、柔性事务等分片功能;Sharding-JDBC 2.x提供了全新的Orchestration模块,关注数据库和数据库访问层应用的治理。2.0.0在治理方面的主要更新是:
配置动态化。可以通过zookeeper或etcd作为注册中心动态修改数据源以及分片规则。
数据治理。提供熔断数据库访问程序对数据库的访问和禁用从库的访问的能力。
跟踪系统支持。可以通过sky-walking等基于Opentracing协议的APM系统中查看Sharding-JDBC的调用链,并提供sky-walking的自动探针。
提供Sharding-JDBC的spring-boot-starter。
2.x
通过2.x提供的数据治理能力,sharding-jdbc的架构图是:

2.x沿用了1.x的SQL解析、SQL路由、SQL改写、SQL执行以及结果归并的这一套分片化体系。与1.x的最大区别是增加了为数据治理使用的注册中心模块,目前支持最常用的zookeeper和etcd两种注册中心的实现。Sharding-JDBC对分布式配置、分布式治理以及调用链路追踪分析这几个分布式应用的几个核心关注点进行了实现,与服务治理框架类似,数据库访问层的治理可以提供更加细粒度的层级进行熔断等操作。
配置动态化将Sharding-JDBC的配置信息放入注册中心。Sharding-JDBC的配置较为灵活,同时支持Java Config、YAML、Spring命名空间和Spring-boot-starter四种方式。配置动态化模块将不同的配置方式统一转换为JSON,并存储至注册中心,并通过监听配置节点的来探知配置信息的修改。配置信息修改会触发Sharding-JDBC数据源的重建,可以在不重启应用的前提下刷新数据源配置,以动态增减数据库和修改分片策略。
数据治理部分,Sharding-JDBC目前主要提供熔断和禁用相关的能力,未来会做进一步的扩展。熔断是针对数据库访问的应用,可以通过设置注册中心相关节点达到熔断某一运行中的应用对数据库的访问,而不间断其其他行为。在实际应用场景中,对于某些对整体数据库带来操作压力的服务,可以采用该方式减轻数据库的压力,而相关服务会自动降级,所有对数据库的访问将返回空结果集,或通过订阅异常的方式自定义降级行为。禁用功能主要是针对于读写分离中的从库,Sharding-JDBC支持可支持分库分表+读写分离或独立使用读写分离的两种方式。读写分离目前采用一主多从的方式,可以通过对某个从库的禁用以做到从库的不停机动态切换。
和服务化调用链类似,数据库访问同样需要采集、追踪和分析其调用链路。Sharding-JDBC完全遵守Opentracing协议,将数据库的分片SQL和数据源发送至支持Opentracing协议的APM产品。Sharding-JDBC还与sky walking深度合作,提供了sky walking的自动探针,可以让使用Sharding-JDBC的应用自动将调用链路追踪对接至任何标准系统。
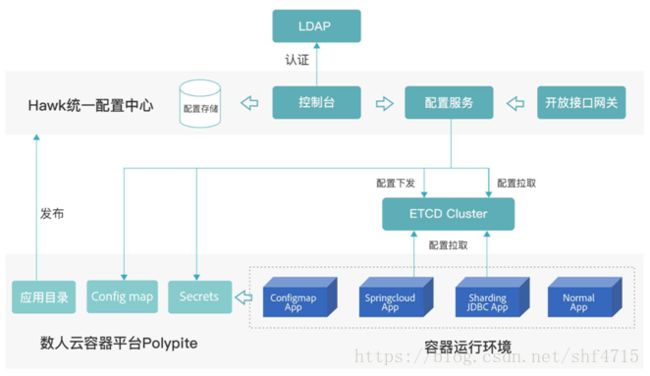
本次2.0版本的开发,受到了数人云的大力支持,他们不但贡献了Sharding-JDBC的核心代码,还提供了hawk的统一配置中心平台,也会于近期开源。通过对Sharding-JDBC注册中心的读写,提供了对配置的图形化界面支持。Hawk的架构图如下:
著名的apm开源软件Sky-walking也将于近期采用Sharding-JDBC作为其底层存储追踪日志的存储引擎。整合了Sharding-JDBC作为存储引擎的Sky-walking架构图如下:

Sharding-JDBC将与配置中心hawk,APM的sky-walking一起打造分布式服务的生态圈。
3.x
Sharding-Sphere正式发布
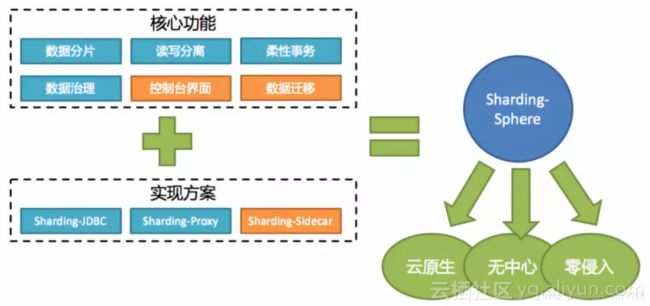
Sharding-Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。他们均提供标准化的数据分片、读写分离、柔性事务和数据治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-Sphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,是非常值得推荐的。而Sharding-Sphere关注未来不变的东西,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,我们目前阶段更加关注在原有基础上的增量,而非颠覆。其架构如下图所示:
Sharding-Sphere家族都有谁?
Sharding-JDBC, Sharding-Proxy以及Sharding-Sidecar 共同组成了Sharding-Sphere。他们分别定位、适用于不同的应用场景。您也可以将他们组合使用以得到增益的性能表现。