Linux网络协议栈之数据包处理过程
Linux网络协议栈之数据包处理过程
来源:http://blog.csdn.net/wangxing1018/article/details/4224129
1 前言
本来是想翻译《 The journey of a packet through the linux 2.4 network stack 》 这篇文章的。但在查阅相关的资料时,发现需要补充一些技术细节,才使得我这种菜鸟理解更加深刻,所以综合了上面两篇文档,在加上自己的裁减和罗嗦,就有了下面的文字。我不知道这是否侵犯了作者权益。如果有的话,请告知,我会及时删除这篇拼凑起来的文档。
引用作者 Harald Welte 的话:我毫无疑问不是内核导师级人物,也许此文档的信息是错误的。所以不要对此期望太高了,我也感激你们的批评和指正。
这篇文档是基于 x86 体系结构和转发 IP 分组的。
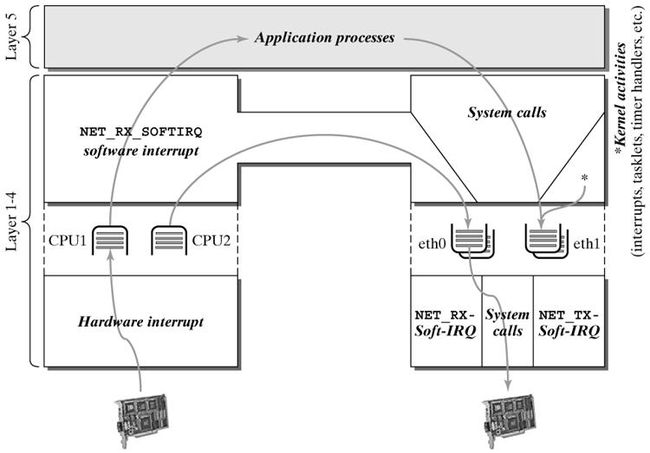
数据包在 Linux 内核链路层路径
2 接收分组
2.1 接收中断
如果网卡收到一个和自己 MAC 地址匹配或链路层广播的以太网帧,它就会产生一个中断。此网卡的驱动程序会处理此中断:
- 从 DMA/PIO 或其他得到分组数据,写到内存里去;
- 接着,会分配一个新的套接字缓冲区 skb ,并调用与协议无关的、网络设备均支持的通用网络接收处理函数 netif_rx(skb) 。 netif_rx() 函数让内核准备进一步处理 skb 。
- 然后, skb 会进入到达队列以便 CPU 处理(对于多核 CPU 而言,每个 CPU 维护一个队列)。如果 FIFO队列已满,就会丢弃此分组。在 skb 排队后,调用 __cpu_raise_softirq() 标记 NET_RX_SOFTIRQ 软中断,等待 CPU 执行。
- 至此, netif_rx() 函数调用结束,返回调用者状况信息(成功还是失败等)。此时,中断上下文进程完成任务,数据分组继续被上层协议栈处理。
2.2 softirq 和 bottom half
内核 2.4 以后,整个协议栈不再使用 bottom half (下半文,没找到好的翻译),而是被软中断 softirq 取代。软中断 softirq 优势明显,可以同时在多个 CPU 上执行;而 bottom half 一次只能在一个 CPU 上执行,即在多个CPU 执行时严格保持串行。
中断服务程序往往都是在 CPU 关中断的条件下执行的,以避免中断嵌套而使控制复杂化。但是 CPU 关中断的时间不能太长,否则容易丢失中断信号。为此, Linux 将中断服务程序一分为二,各称作“ Top Half ”和“Bottom Half ”。前者通常对时间要求较为严格,必须在中断请求发生后立即或至少在一定的时间限制内完成。因此为了保证这种处理能原子地完成, Top Half 通常是在 CPU 关中断的条件下执行的。具体地说, Top Half 的范围包括:从在 IDT 中登记的中断入口函数一直到驱动程序注册在中断服务队列中的 ISR 。而 Bottom Half 则是Top Half 根据需要来调度执行的,这些操作允许延迟到稍后执行,它的时间要求并不严格,因此它通常是在 CPU开中断的条件下执行的,比如网络底层操作就是这样,由于某些原因,中断并没有立刻响应,而是先记录下来,等到可以处理这些中断的时候就一块处理了。但是, Linux 的这种 Bottom Half (以下简称 BH )机制有两个缺点,也即:( 1 )在任意一时刻,系统只能有一个 CPU 可以执行 Bottom Half 代码,以防止两个或多个 CPU 同时来执行 Bottom Half 函数而相互干扰。因此 BH 代码的执行是严格“串行化”的。( 2 ) BH 函数不允许嵌套。这两个缺点在单 CPU 系统中是无关紧要的,但在 SMP 系统中却是非常致命的。因为 BH 机制的严格串行化执行显然没有充分利用 SMP 系统的多 CPU 特点。为此, Linux2.4 内核在 BH 机制的基础上进行了扩展,这就是所谓的“软中断请求”( softirq )机制。 Linux 的 softirq 机制是与 SMP 紧密不可分的。为此,整个 softirq 机制的设计与实现中自始自终都贯彻了一个思想:“谁触发,谁执行 ”( Who marks , Who runs ),也即触发软中断的那个 CPU 负责执行它所触发的软中断,而且每个 CPU 都由它自己的软中断触发与控制机制。这个设计思想也使得 softirq 机制充分利用了 SMP 系统的性能和特点。
2.3 NET_RX_SOFTIRQ 网络接收软中断
这两篇文档描述的各不相同,侧重不一。在这里,只好取重避轻。
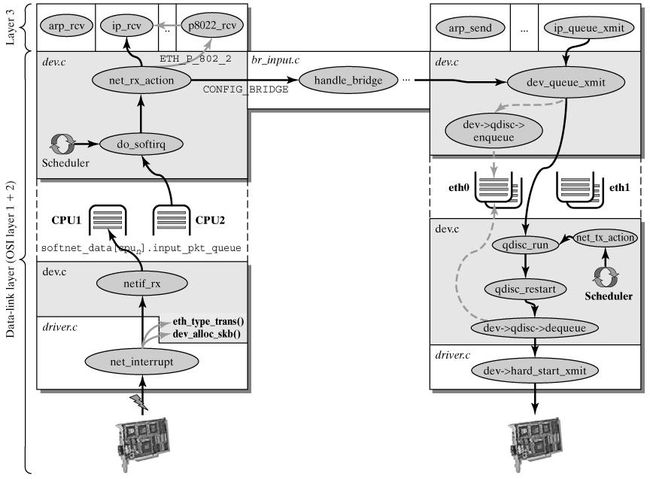
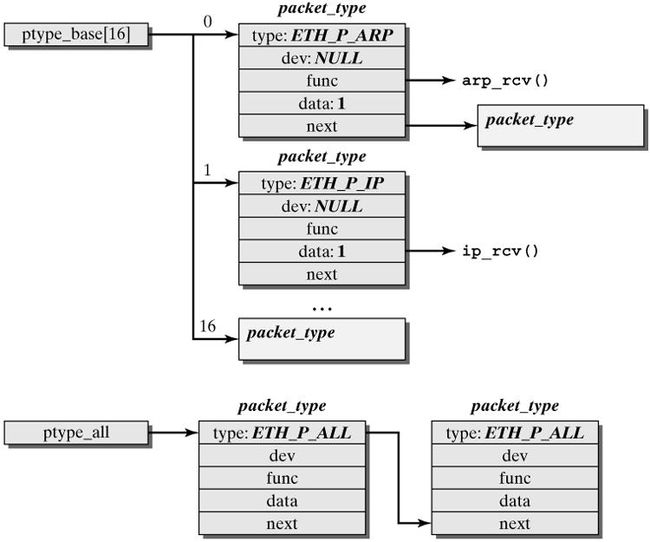
这一阶段会根据协议的不同来处理数据分组。 CPU 开始处理软中断 do_softirq() ,,接着 net_rx_action() 处理前面标记的 NET_RX_SOFTIRQ ,把出对列的 skb 送入相应列表处理(根据协议不同到不同的列表)。比如,IP 分组交给 ip_rcv() 处理, ARP 分组交给 arp_rcv() 处理等。
2.4 处理 IPv4 分组
下面以 IPv4 为例,讲解 IPv4 分组在高层的处理。
linux 内核协议栈之网络层
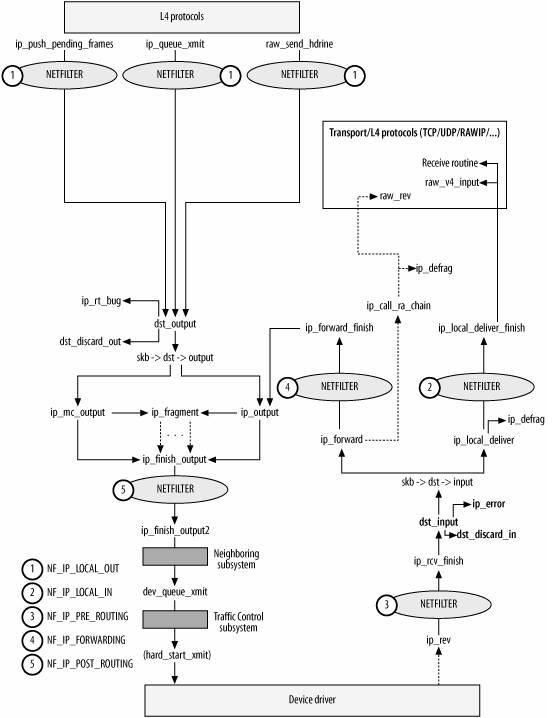
以上两个图都是一个意思,可以对比着看。
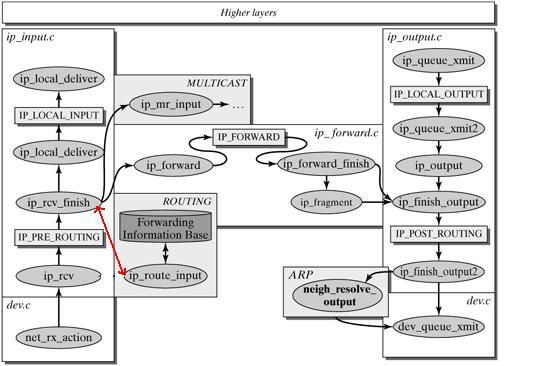
ip_rcv() 函数验证 IP 分组,比如目的地址是否本机地址,校验和是否正确等。若正确,则交给 netfilter 的NF_IP_PRE_ROUTING 钩子(关于netfilter细节可以参考 Hacking the Linux Kernel Network Stack );否则,丢弃。
到了 ip_rcv_finish() 函数,数据包就要根据 skb 结构的目的或路由信息各奔东西了。
- 判断数据包的去向, ip_local_deliver() 处理到本机的数据分组、 ip_forward() 处理需要转发的数据分组、 ip_mr_input() 转发组播数据包。如果是转发的数据包,还需要找出出口设备和下一跳。
-
分析和处理 IP 选项。(并不是处理所有的 IP 选项)。
具体来说,从 skb->nh ( IP 头,由 netif_receive_skb 初始化)结构得到 IP 地址: struct net_device *dev = skb->dev; struct iphdr *iph = skb->nh.iph;
而 skb->dst 或许包含了数据分组到达目的地的路由信息,如果没有,则需要查找路由,如果最后结果显示目的地不可达,那么就丢弃该数据包:
if (skb->dst == NULL) {
if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev))
goto drop;
}
ip_rcv_finish() 函数最后执行 dst_input ,决定数据包的下一步的处理。
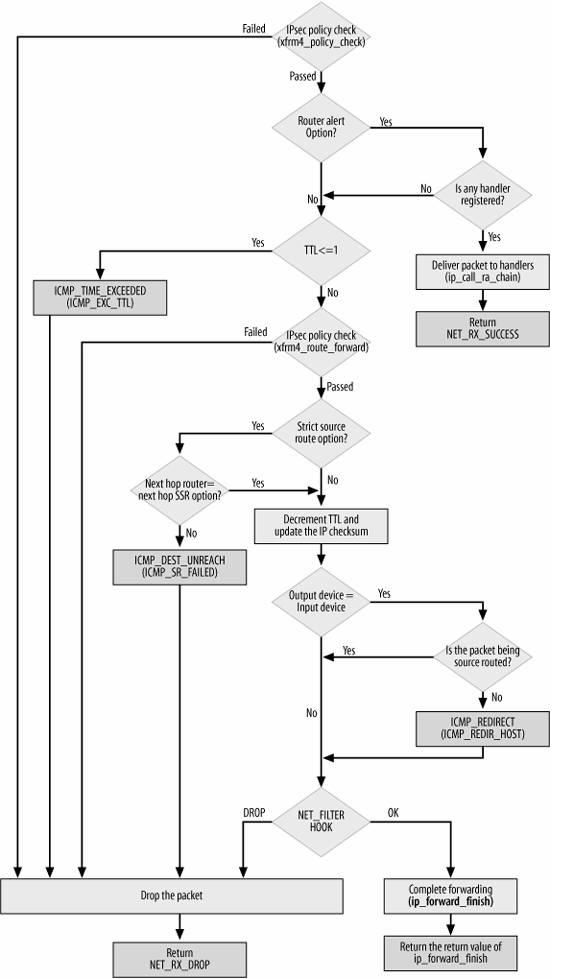
2.4.1 转发数据包
转发数据包主要包括一下步骤:
- l 处理 IP 头选项。如果需要的话,会记录本地 IP 地址和时间戳;
- l 确认分组可以被转发;
- l 将 TTL 减一,如果 TTL 为 0 ,则丢弃分组;
- l 根据 MTU 大小和路由信息,对数据分组进行分片,如果需要的话;
- l 将数据分组送往外出设备。
如果由于某种原因,数据分组不能被转发,那么就回应 ICMP 消息来说明不能转发的原因。在对转发的分组进行各种检查无误后,执行 ip_forward_finish ,准备发送。然后执行 dst_output(skb) 。无论是转发的分组,还是本地产生的分组,都要经过 dst_output(skb) 到达目的主机。 IP 头在此时已经完成就绪。dst_output(skb) 函数要执行虚函数 output (单播的话为 ip_output ,多播为 ip_mc_output )。最后,ip_finish_output 进入邻居子系统。
下图是转发数据包的流程图:
2.4.1 本地处理
int ip_local_deliver(struct sk_buff *skb)
{
if (skb->nh.iph->frag_off & htons(IP_MF|IP_OFFSET)) {
skb = ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER);
if (!skb)
return 0;
}
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
最后执行 ip_local_deliver_finish 。
以下属 ip_local_deliver_finish 函数流程图:
在 L4 协议中, TCP 和 UDP 是运行在内核空间的,而 RAW 则可以运行在用户空间中。
TCP 处理见下图:
UDP 处理略。
数据分组的发送:
ip_queue_xmit 检查 socket 结构体中是否含有路由信息,如果没有则执行 ip_route_output_flow 查找,并存储到 sk 数据结构中。如果找不到,则丢弃数据包。
至此,数据分组的接受和处理工作就告一段落了,至于于此相对的数据分组的发送,我就贴个图吧,具体细节可参考 The Linux® Networking Architecture: Design and Implementation of Network Protocols in the Linux Kernel Prentice Hall August 01, 2004
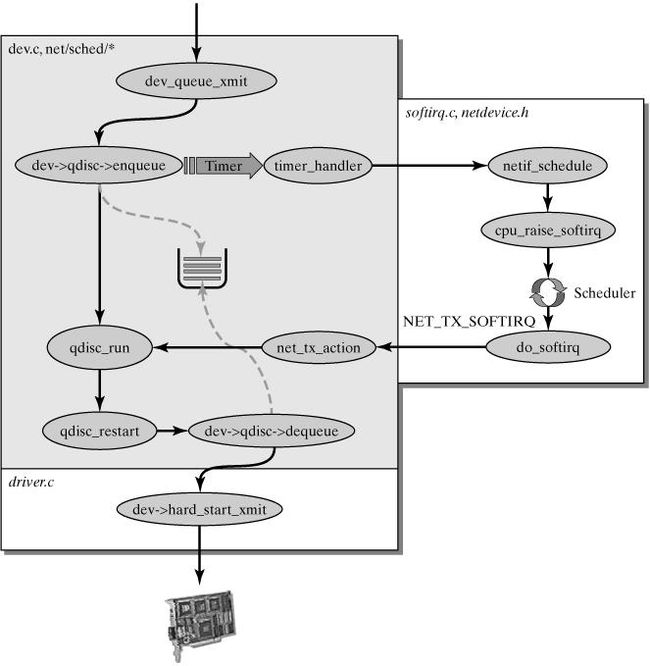
dev_queue_xmit() 处理发送分组
附一张 Linux 2.4 核的 netfilter 框架下分组的走向图:
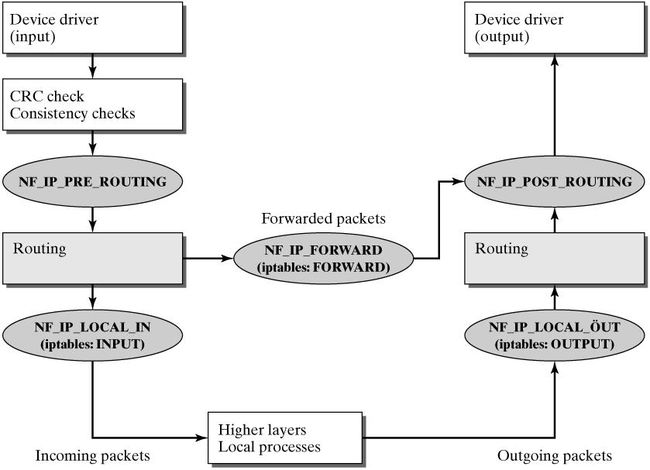
来自链接:
http://ftp.gnumonks.org/pub/doc/packet-journey-2.4.html
http://m.linuxjournal.com/article/4852
这篇文档描述了网络分组在 linux 内核 2.4 协议栈的处理过程。