CVPR 2020 多目标跟踪算法JDE 训练
数据集:
MOT17,取其中的MOT17-13-DPM,MOT17-13-FRCNN,MOT17-13-SDP三个文件夹
检测目标:
人,车,自行车,摩托车
原始数据标注:


数据处理:
(1)按照原始数据集标注,gt.txt中的倒数第三列是目标轨迹是否进入考虑范围的标志,这里将我们需要的四个类别(人,车,自行车,摩托车)的这个标志设置为1,可以用notepad++打开,查找,替换,这里以替换第三类也就是上表中的car类的标记为例,如下图:

同理,将上表中类别为4(bicycle),5(motorbike),7(static person)的标志位都设置为1。
(2)调用脚本生成JDE训练需要的如下标注格式:
![]()

这里的x_center,y_center,width,height都是经过原图宽高归一化的。
生成上面格式的脚本(修改自FairMOT中的脚本):
import os.path as osp
import os
import numpy as np
import shutil
def mkdirs(d):
if not osp.exists(d):
os.makedirs(d)
seq_root = 'F:/dataset/MOT/MOT17/images/train'
label_root = 'F:/dataset/MOT/JDE/labels_with_ids'
img_root="F:/dataset/MOT/JDE/images"
mkdirs(label_root)
seqs = [s for s in os.listdir(seq_root)]
seqs=["MOT17-13-DPM","MOT17-13-FRCNN","MOT17-13-SDP"]
tid_curr = 0
tid_last = -1
for seq in seqs:
print(seq)
seq_info = open(osp.join(seq_root, seq, 'seqinfo.ini')).read()
seq_width = int(seq_info[seq_info.find('imWidth=') + 8:seq_info.find('\nimHeight')])
seq_height = int(seq_info[seq_info.find('imHeight=') + 9:seq_info.find('\nimExt')])
gt_txt = osp.join(seq_root, seq, 'gt', 'gt.txt')
gt = np.loadtxt(gt_txt, dtype=np.float64, delimiter=',')
seq_label_root = osp.join(label_root)
if not os.path.exists(label_root):
mkdirs(seq_label_root)
for fid, tid, x, y, w, h, mark, label, _ in gt:
label=int(label)
print(" ",fid,label)
if mark == 0 or (label != 1 and label!=3 and label!=4 and label!=5 and label!=7): #只保留行人,汽车,自行车,摩托车
#print ("imgnored label:",str(label))
continue
final_label=0
if label==1 or label==7: # Pedestrain
final_label=0
if label==3: # Car
final_label=1
if label==4: # Bicycle
final_label=2
if label==5: # Motorbike
final_label=3
fid = int(fid)
tid = int(tid)
if not tid == tid_last:
tid_curr += 1
tid_last = tid
x += w / 2
y += h / 2
img_src_fpath=osp.join(seq_root,seq,"img1")
img_fpath=osp.join(img_root, '{}_{:06d}.jpg'.format(seq,fid))
label_fpath = osp.join(seq_label_root, '{}_{:06d}.txt'.format(seq,fid))
label_str = '{:d} {:d} {:.6f} {:.6f} {:.6f} {:.6f}\n'.format(int(final_label),
tid_curr, x / seq_width, y / seq_height, w / seq_width, h / seq_height)
with open(label_fpath, 'a') as f:
f.write(label_str)
if not os.path.exists(img_fpath):
shutil.copy(img_src_fpath+"/{:06d}.jpg".format(fid),img_fpath)
生成的数据及标注:



标注的内容:

这时可以写一个脚本显示出这些标注框,看看是否有错:
脚本:
#-*- coding:utf-8 -*-
import os
import cv2
'''
显示跟踪训练数据集标注
'''
root_path="F:/dataset/MOT/JDE"
img_dir="images"
label_dir="labels_with_ids"
imgs=os.listdir(root_path+"/"+img_dir)
for i,img in enumerate(imgs) :
img_name=img[:-4]
label_f=open(root_path+"/"+label_dir+"/"+img_name+".txt","r")
lines=label_f.readlines()
img_data=cv2.imread(root_path+"/"+img_dir+"/"+img)
H,W,C=img_data.shape
for line in lines:
line_list=line.strip().split()
class_num=int(line_list[0]) #类别号
obj_ID=int(line_list[1]) #目标ID
x,y,w,h=line_list[2:] #中心坐标,宽高(经过原图宽高归一化后)
x=int(float(x)*W)
y=int(float(y)*H)
w=int(float(w)*W)
h=int(float(h)*H)
left=int(x-w/2)
top=int(y-h/2)
right=left+w
bottom=top+h
cv2.circle(img_data,(x,y),1,(0,0,255))
cv2.rectangle(img_data, (left,top),(right,bottom), (0,255,0), 2)
cv2.putText(img_data, str(obj_ID), (left,top), cv2.FONT_HERSHEY_COMPLEX, 0.5, (0,0,255), 1)
resized_img=cv2.resize(img_data,(800,416))
cv2.imshow("label",resized_img)
cv2.waitKey(1)
显示标注结果:

(3)生成训练文件。
由于代码中读取训练图片和标签是通过一个xxx.train文件来读取的,形式如下:
所以写脚本,生成训练的xxx.train文件,脚本:
import os
image_flder="images"
imgs=os.listdir(image_flder)
train_f=open("jde_mot17.train","w")
for img in imgs:
save_str=image_flder+'/'+img+"\n"
train_f.write(save_str)
train_f.close()
生成的训练文件:

训练

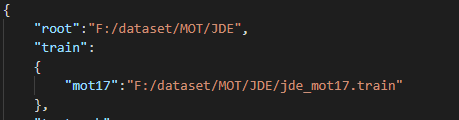
修改cfg/ccmcpe.json文件:

修改数据集路径为前面生成的xxx.train文件路径:
在保存模型和配置文件之前,漏了判断文件夹是否存在的操作,会报错。

去掉中途的验证:

修改网络定义文件中分类的类别数,这里我需要分4个类:人,车,自行车,摩托车,所以设置yolo层的classes=4,此外还要将yolo层的输入层维度进行修改,这里的yolo层有两个分支的输入:(1)分类和回归分支(2)特征提取分支,而特征提取分支不因类别而改变,一直是固定的512维,不用修改。因为yolo层的输出通道数是(C+5)*A,这里的C指的是类别数,A指的是anchor的个数。这里C=4,A默认是4,所以YOLO层输入层的维度是(4+5)*4=36,修改如下:

此外还需修改YOLOlayer层的forward方法,修改如下,将原来的定值24修改成根据类别自动计算的变量split,就可以适应不同的类别数了。这个值主要是用来切分分类回归值和特征值的维度分割点,前面的split个通道是类别和坐标回归,split到最后是特征。
开始训练:

但是训练过程中出现了loss突然变很大的情况,感觉是数据哪里出了问题,标签原来作者只有行人一类,类别全部为0。

原因分析:(1)脏数据,可能是训练数据不够好,其中有些标签没处理正确。(2)数据量不够,只用了MOT中一个场景的数据。(3)仔细研究代码,看看哪里设置不正确。训练成功之后再来更新...