【吴恩达deeplearning.ai】深度学习(7):卷积神经网络
计算机视觉(Computer Vision)是一门研究如何教机器“看”的科学,计算机视觉研究相关的理论和技术,试图创建能够从图像或者多维数据中获取“信息”的人工智能系统。
随着深度学习技术的发展,计算机视觉领域的研究也得到了快速的发展。在对各种图像进行处理的过程中,往往在少量的图像中便蕴含着大量的数据,难以用一般的DNN进行处理。而卷积神经网络(Convolutional Neural Network, CNN)作为一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,在图像处理工作上有着出色的表现。
卷积神经网络
前面在神经网络中提到过,构建一个深度神经网络来进行人脸识别时,深度神经网络的前面一层可以用来进行边缘探测,其次一层用来探测照片中组成面部的各个特征部分,到后面的一层就可以根据前面获得的特征识别不同的脸型等等。其中的这些工作,都是依托CNN实现的。
基本概念
以下通过边缘检测的例子来阐述深度学习中卷积的基本概念。
如上图中,最左边是一张用大小为6×6的矩阵表示的存在明显分界线的灰度图,矩阵中的值大于“1”则代表白色,等于“0”则代表灰色,小于“0”则代表黑色。
通过与中间的大小为3×3的矩阵进行卷积(Convolution)运算,得到的大小为4×4的矩阵,就是图片中的存在的边缘。其中,中间这个矩阵 ⎡⎣⎢1 1 1000−1−1−1⎤⎦⎥ [ 1 0 − 1 1 0 − 1 1 0 − 1 ] 被称为滤波器(Filter)。
在数学领域,“*”号是标准的卷积运算符号,但在计算机里通常用这个符号代表一般的乘法,要注意加以区分。
深度学习里面所称的卷积运算,和泛函分析中的卷积运算有所不同,它的求解过程只是简单将图像矩阵中,从左到右,由上到下,取与滤波器同等大小的一部分,每一部分中的值与滤波器中的值对应相乘后求和,最后的结果组成一个矩阵,其中没有经过翻转、反褶等过程。其运算过程如下面的卷积运算所示:
将这个灰度图左右的颜色进行翻转再与之前的滤波器进行卷积:
得到的结果中,原来的“30”也会变为“-30”,表示这时的图片是左灰右白,与原来相反。
上面的这个滤波器 ⎡⎣⎢1 1 1000−1−1−1⎤⎦⎥ [ 1 0 − 1 1 0 − 1 1 0 − 1 ] 可以用来探测垂直方向的边缘,那么只要把这个滤波器翻转下,变成 ⎡⎣⎢1 0 −110−110−1⎤⎦⎥ [ 1 1 1 0 0 0 − 1 − 1 − 1 ] ,则这个新的滤波器就可以用来探测水平方向的边缘。如下图:
所以,不同的滤波器有着不同的作用。滤波器矩阵的大小和其中的值也都不是固定不变的,可以根据需求来选择。其中, ⎡⎣⎢1 2 1000−1−2−1⎤⎦⎥ [ 1 0 − 1 2 0 − 2 1 0 − 1 ] 叫Sobel滤波器,它增加了中间行的权重,这样可能更稳健些。计算机视觉的研究中还会用到 ⎡⎣⎢3 10 3000−3−10−3⎤⎦⎥ [ 3 0 − 3 10 0 − 10 3 0 − 3 ] ,它叫Scharr滤波器。滤波器中的值还可以作为参数,通过训练来得到。
填充和步长
前面可以看到,大小为6×6的矩阵与大小为3×3的滤波器进行卷积运算,得到的结果是大小为4×4的矩阵。假设矩阵的大小为 n×n n × n ,而滤波器的大小为 f×f f × f , f f 一般是个奇数,则卷积后结果的大小就为 (n−f+1)×(n−f+1) ( n − f + 1 ) × ( n − f + 1 ) 。
可以发现,原来的矩阵与滤波器进行卷积后的结果中损失了部分值,而且用滤波器处理一张图片时,往往在边角处只检测了部分像素点,丢失了图片边界处的众多信息。为解决这个问题,可以在进行卷积操作前,对原矩阵进行边界填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常都用“0”作为填充值。
如上图中,设填充数量为 p p ,当 p=1 p = 1 时,就是在原来大小为6×6的矩阵的边界上填充一个像素,就得到一个大小为8×8的矩阵,再与滤波器卷积,最后得到的结果就会是一个大小为6×6的矩阵。填充后,卷积后结果的大小就为 (n+2p−f+1)×(n+2p−f+1) ( n + 2 p − f + 1 ) × ( n + 2 p − f + 1 ) 。
这样,在进行卷积运算时,就存在两种选择:
- Valid 卷积:不进行任何处理,直接卷积卷积后结果的大小就为 (n−f+1)×(n−f+1) ( n − f + 1 ) × ( n − f + 1 ) 。
- Same 卷积:进行填充,并使得卷积后结果的大小与原来的一致,这时 p=f−12 p = f − 1 2 。
卷积过程中,有时需要通过填充来避免信息损失,有时也要在卷积时通过设置的步长(Stride)来压缩一部分信息。
如上图中所示,设卷积的步长为 s s ,当 s=2 s = 2 时,就是在卷积运算时,每次滤波器在原矩阵中向右或向下移动一次的距离从原来的1变成2,这样最后得到的结果大小会是3×3,比一般的卷积结果还小。设置卷积步长为s后,卷积后的结果大小为 ⌊n+2p−fs+1⌋×⌊n+2p−fs+1⌋ ⌊ n + 2 p − f s + 1 ⌋ × ⌊ n + 2 p − f s + 1 ⌋ 。” ⌊ ⌋ ⌊ ⌋ ”是向下取整符号,用于结果不是整数时进行向下取整。
高维卷积
进行高维度的卷积运算,需要注意一些问题。
如上图,要处理一张有三个信道(Channel)RGB图片,也就是一个大小为6×6×3的矩阵,其中每一个信道为一个特征图(Feature Map),那么滤波器也要有三个信道,即滤波器矩阵大小为3×3×3的。计算的过程是将矩阵与滤波器对应的每一信道进行卷积运算,最后相加,得到的结果就还是个只有一个信道的大小为4×4矩阵。而且三层滤波器中,每一层中的值可以根据需求来设定。例如只想用滤波器来检测图中红色层的边缘,那么只要将后面两层滤波器的值全部置为0即可。
此外,还可以同时用多个滤波器来处理一个矩阵,以检测多个特征。如上图中第一个可以是用来检测检测图像矩阵的垂直边缘的滤波器,第二个可以是用来检测图像矩阵的水平边缘,把得到的两个结果组合在一起,结果是一个大小为4×4×2的矩阵。
符号约定
简单来说,对于一个卷积神经网络,滤波器组成参数 w[l] w [ l ] ,将它与输入 a[l−1] a [ l − 1 ] 卷积之后,再加上一个为实数的参数 b[l] b [ l ] ,就组成一般的神经网络中 z[l]=w[l]a[l−1]+b[l] z [ l ] = w [ l ] a [ l − 1 ] + b [ l ] 的形式。此外,还需要进行一些符号的约定。
一般情况下使用到的滤波器都是个方形矩阵,也就是大小为 n×n n × n 。在此,用 f[l] f [ l ] 表示神经网络的第 l l 层使用的滤波器大小, p[l] p [ l ] 表示对第 l l 层的填充数, s[l] s [ l ] 表示第 l l 层的卷积步长。
用 nH n H 、 nW n W 、 nC n C 表示一张图片的长、宽、信道数,则对神经网络的第 l l 层,输入矩阵 a[l−1] a [ l − 1 ] 的大小将是 n[l−1]H×n[l−1]W×n[l−1]C n H [ l − 1 ] × n W [ l − 1 ] × n C [ l − 1 ] ,使用的每个滤波器 w[l] w [ l ] 的大小都应该是 f[l]×f[l]×n[l−1]C f [ l ] × f [ l ] × n C [ l − 1 ] ,输出矩阵 z[l] z [ l ] 以及激活 a[l] a [ l ] 的大小都将是 n[l]H×n[l]W×n[l]C n H [ l ] × n W [ l ] × n C [ l ] ,由之前得出的公式:
由对高维卷积中的讲解中可知, n[l]C n C [ l ] 就等于卷积过程中用到的滤波器的个数,所以整个 w[l] w [ l ] 的大小就应该是 n[l−1]H×n[l−1]W×n[l−1]C×n[l]C n H [ l − 1 ] × n W [ l − 1 ] × n C [ l − 1 ] × n C [ l ] ,而 b[l] b [ l ] 的大小就将是 1×1×1×n[l]C 1 × 1 × 1 × n C [ l ] 。
卷积神经网络的结构
通常一个卷积神经网络是由输入层(Input)、卷积层(Convolution)、池化层(Pooling)、全连接层(Fully Connected)组成。
在输入层输入原始数据,卷积层中进行的是前面所述的卷积过程,用它来进行提取特征。全连接层就是将识别到的所有特征全部连接起来,并输出到分类器(如Softmax)。
池化层
通常池化层都是用于对卷积层输出特征进行压缩,以加快运算速度,也可以对于一些特征的探测过程变得更稳健。
采用较多的一种池化过程叫最大池化(Max Pooling),其具体操作过程如下:
池化过程类似于卷积过程,且池化过程中没有需要进行学习的参数。把一个大小为4×4的矩阵分成四个等块,经过Max Pooling,取每一个区域中的最大值,输出一个大小为2×2的矩阵。这个池化过程中相当于使用了一个大小 f=2 f = 2 的滤波器,且池化步长 s=2 s = 2 。卷积过程中的几个计算大小的公式在此也都适用。
池化过程在一般卷积过程后,而卷积过程是个提取特征的过程。把上面的例子中这个4×4的输入看作某些特征的集合,则数字大就意味可能提取到了某些特定特征,Max池化的功能提取出这些特定特征,将它们保留下来。
也还有一种平均池化(Average Pooling),就是从从以上取某个区域的最大值改为求这个区域的平均值:
采用卷积神经网络能够建立出更好的模型,获得更为出色的表现,在于其拥有的一些突出的优点。
对于大量的输入数据,卷积过程有效地减少了参数数量,而这主要归功于以下两点:
- 参数共享(Parameter Sharing):在卷积过程中,不管输入有多大,一个特征探测器也就前面所说的滤波器就能对整个输入的特征进行探测。
- 局部感知(Local Perception):在每一层中,输入和输出之间的连接是稀疏的,每个输出值只取决于输入的一小部分值。
池化过程则在卷积后很好地聚合了特征,通过降维而减少了运算量。
示例结构
一种典型卷积网络结构是LeNet-5,它是由用LeCun在上世纪九十年代提出的用来识别数字的卷积网络,下图的卷积网络结构与它类似:
其中,一个卷积层和一个池化层组成整个卷积神经网络中的一层,图中所示整个过程为Input->Conv->Pool->Conv->Pool->FC->FC->FC—>Softmax。
下面各层中的数据:
可以看出,激活的大小随着向卷积网络深层的递进而减小,参数的数量在不断增加后在几个全连接过程后将逐渐减少。
经典的卷积网络
LeNet-5
LeNet-5是LeCun等人1998年在论文[Gradient-based learning applied to document recognition]中提出的卷积网络。其结构如下图:
LeNet-5卷积网络中,总共大约有6万个参数。随着深度的增加, nH n H 、 nW n W 的值在不断减小, nC n C 却在不断增加。其中的Conv-Pool-Conv-Pool-FC-FC-Output是现在用到的卷积网络中的一种很常见的结构。
AlexNet
AlexNet是Krizhevsky等人2012年在论文[ImageNet classification with deep convolutional neural networks]中提出的卷积网络。其结构如下图:
AlexNet卷积网络和LeNet-5有些类似,但是比后者大得多,大约有6千万个参数。
VGG-16
VGG-16是Simonyan和Zisserman 2015年在论文[Very deep convolutional networks for large-scale image recognition]中提出的卷积网络。其结构如下图:
VGG-16卷积网络的结构比较简单,其只要通过池化过程来压缩数据。VGG-16中的16指的是它有16个有权重的层。它是个比上面两个大得多的卷积网络,大约有13800万个参数。
ResNets
当一个神经网络某个深度时,将会出现梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)等问题。而ResNets能很好得解决这些问题。
ResNets全称为残差网络(Residual Networks),它是微软研究院2015年在论文[Deep Residual Learning for Image Recognition]中提出的卷积网络。
如上图是一个神经网络中的几层,它一般的前向传播的过程,也称为“主要路径(main path)”为 a[l] a [ l ] -linear-ReLU-linear-ReLU- a[l+2] a [ l + 2 ] ,计算过程如下:
在残差网络中,通过“捷径(short cut)”直接把 a[l] a [ l ] 添加到第二个ReLu过程里,也就是最后的计算过程中:
其中 a[l] a [ l ] 需要乘以一个矩阵 Ws W s 使得它的大小和 z[l+2] z [ l + 2 ] 匹配。
深度神经网络通过这种跳跃网络层的方式能获得更好的训练效果。上面这种结构被称为一个残差块(Residual Blocks)。
在普通神经网络(Plain NetWork)中使用多个这种残余块的结构,就组成了一个残差网络。两者的成本曲线分别如下:
普通的神经网络随着梯度下降的进行,理论上成本是不断下降的,而实际上当神经网络达到一定的深度时,成本值降低到一定程度后又会趋于上升,残差神经网络则能解决这个问题。
对于一个神经网络中存在的一些恒等函数(Identity Function),残差网络在不影响这个神经网络的整体性能下,使得对这些恒等函数的学习更加容易,而且很多时候还能提高整体的学习效率。
Network In NetWork
2013年新加坡国立大学的林敏等人在论文[Network In NetWork]中提出了1×1卷积核及NIN网络。
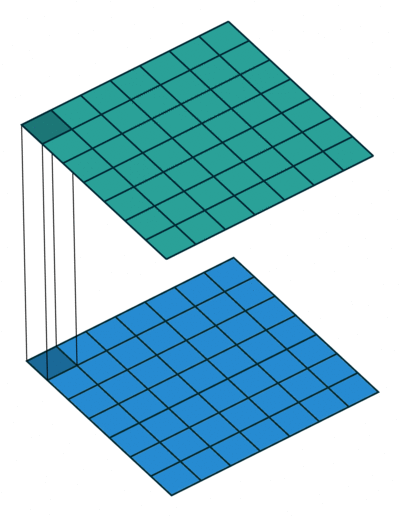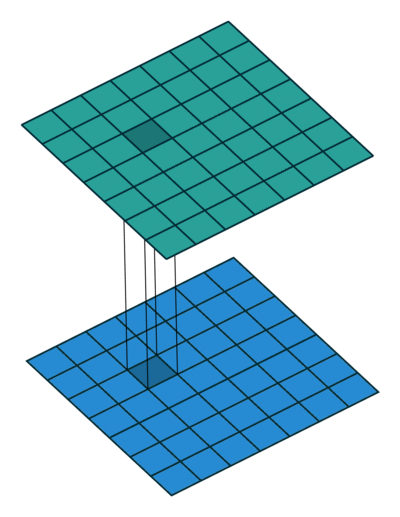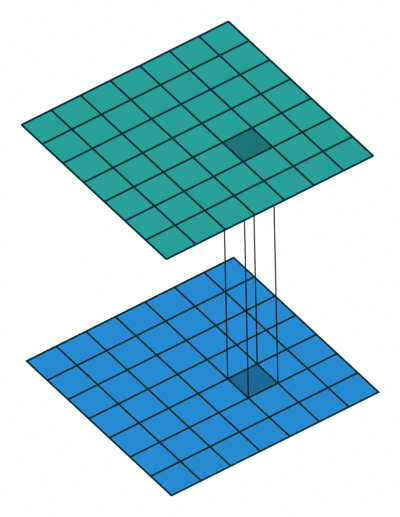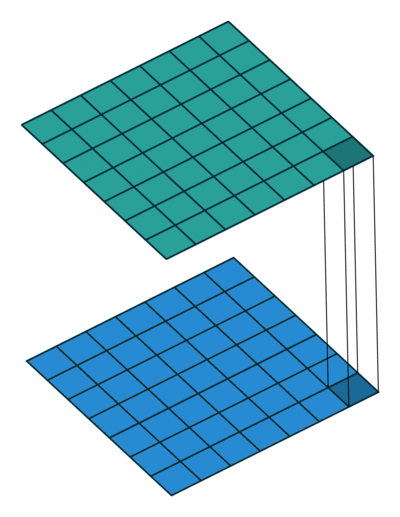
使用1×1卷积核进行卷积的过程如上图,它就是在卷积过程中采用大小为1×1的滤波器。如果神经网络的当前一层和下一层都只有一个信道,也就是 nC=1 n C = 1 ,那么采用1×1卷积核起不到什么作用的。但是当它们分别为有 m m 和 n n 个信道时,采用1×1卷积核就可以起到跨信道聚合的作用,从而降低(或升高)数据的维度,可以达到减少参数的目的。换句话说,1×1的卷积核操作实现的其实就是一个特征数据中的多个Feature Map的线性组合,所以这个方法就可以用来改变特征数据的信道数。
如上面的例子中,用32个大小为1×1×192的滤波器进行卷积,就能使原先数据包含的192个信道压缩为32个。在此注意到,池化能压缩数据的高度( nH n H )及宽度( nW n W ),而1×1卷积核能压缩数据的信道数( nC n C )。
Inception Network
最早的Inception结构的V1版本是由Google的Szegedy 2014年在论文[Going deeper with convolutions]中提出的,它是ILSVRC 2014中取得最好成绩的GoogLeNet中采用的的核心结构。通过不断改进,现在已经衍生有了V4版本。
早期的V1版本的结构借鉴了NIN的设计思路,对网络中的传统卷积层进行了修改,其结构大致如下面的例子中所示:
通常在设计一个卷积网络的结构时,需要考虑卷积过程、池化过程的滤波器的大小,甚至是要不要使用1×1卷积核。在Inception结构中,考虑到多个不同大小的卷积核(滤波器)能够增强网络的适应力,于是分别使用三个大小分别为1×1、3×3、5×5的卷积核进行same卷积,同时再加入了一个same最大池化过程。最后将它们各自得到的结果放在一起,得到了图中一个大小为28×28×256的结果。然而,这种结构中包含的参数数量庞大,对计算资源有着极大的依赖,上面的例子中光是与大小为5×5的滤波器进行卷积的过程就会产生1亿多个参数!
在其中的过程中,再加入1×1卷积能有效地对输出进行降维。如上图中所示,中间的一层就像是一个沙漏的瓶颈部分,所以这一层有时被称为瓶颈层(Bottleneck Layer)。通过1×1卷积,最后产生参数数量有1240万左右,相比起原来的1亿多要小了许多。
在论文中提出的整个Inception模型结构如下:
在一个卷积网络中加入多个这种模型,就构成了一个Inception网络,也就是GoogLeNet:
其中还包含一些额外的最大池化层用来聚合特征,以及最后的全连接层。此外还可以从中间层的一些Inception结构中直接进行输出(图中没有画出),也就是中间的隐藏层也可以直接用来参与特征的计算及结果预测,这样能起到调整的作用,防止过拟合的发生。
Inception模型后续有人提出了V2、V3、V4的改进,以及引入残差网络的版本,这些变体都源自于这个V1版本。
最后,值得一提的是,Inception这个名字来自于电影《盗命空间》,用其中”We need to go deeper”这个梗,表明作者建立更深层次更加强悍的神经网络的决心!
其他注意点
在建立一个卷积神经网络时,可以从参考Github等网站上其他人建立过的相关模型,必要时可以直接拿来根据拥有的数据量大小进行前面介绍过的迁移学习,从而减轻一些工作负担。
当收集到的图像数据较少时,可以采用优化神经网络中讲过的数据扩增法,对现有的图像数据进行翻转、扭曲、放大、裁剪,甚至是改变颜色等方法来增加训练数据量。
参考资料
- 吴恩达-卷积神经网络-网易云课堂
- Andrew Ng-Convolutional Neural Networks-Coursera
- deeplearning.ai
- 池化-ufldl
- LeNet-5官网
- 梯度消失、梯度爆炸-csdn
- 残差resnet网络原理详解-csdn
- 关于CNN中1×1卷积核和Network in Network的理解-csdn
- GoogLeNet 之 Inception(V1-V4)-csdn
- 课程代码与资料-GitHub
注:本文涉及的图片及资料均整理翻译自Andrew Ng的Deep Learning系列课程,版权归其所有。翻译整理水平有限,如有不妥的地方欢迎指出。
更新历史:
* 2017.12.10 完成初稿
* 2018.02.13 调整部分内容
原文链接